导读本文将分享小红书推搜场景下,全 GPU 化建设过程中的模型服务、GPU 优化等相关工作。
主要包括以下几大部分:
1. 前言
2. 背景
3. 模型服务
4. GPU 优化实践
分享嘉宾|杜泽宇 小红书 商业化引擎团队负责人
编辑整理|王丽颖
内容校对|李瑶
出品社区|DataFun
近年来,机器学习领域的视频、图像、文本和推广搜等应用不断发展,其模型计算量和参数量远远超过了 CPU 摩尔定律的增长速度。在此背景下,GPU 的算力发展和大模型的发展不谋而合。很多公司都在结合 GPU 的算力发展,探索出适合自己的机器学习问题解决方案。与其他公司类似,小红书各个场景中的模型也在不断变大,而 CPU 的发展跟不上其所需的算力。因此,我们在 21 年时开始进行推广搜模型的 GPU 化改造,以提升推理性能和效率。在迁移过程中,我们也面临一些困难,比如如何把之前 CPU架构的工作平滑迁到 GPU 架构上;如何结合小红书的业务场景和在线架构发展出自己的解决方案等。同时我们需要做到降本增效,帮助模型持续迭代。背景

在介绍具体实践之前,先来介绍一下小红书的应用场景。小红书 APP 主页包括推荐页、搜索页,这些页面还包括了广告成分。其中精排 CTR model、CVR model、相关性 model 以及部分排序场景、召回场景都会用到一些 GPU。目前精排场景已经全部迁移到 GPU 推理,而精排的主要目的是将 CTR、CVR 或者其他多个目标估计准确。从计算参数量来说,小红书的计算规模从 21 年初到 22 年底扩大了很多。以推荐场景为例,每个请求要花 400 亿的 Flops,整个参数量达到了千亿量级。模型服务
1. 模型特点

在 22 年底 ChatGpt 类模型提出之前,工业界或者推搜类公司,暂时还没有特别大的 Dense 模型的应用场景。因此,在 22 年底之前,小红书主要模型的大参数量主要是进行充分稀疏化。具体而言,以推荐主模型为例,有大量参数需要与 ID 类型进行交叉:比如小红书笔记与用户城市交叉,小红书笔记与用户 ID 交叉等,构建特征 Embedding 则成为参数稀疏化过程。整个稀疏化因为笛卡尔积问题,参数量可以达到 TB 千亿或者万亿级别,很多头部公司达到了万亿乃至十万亿的参数量。但考虑到成本以及 CTR 模型收益的局限性,我们并没有把 Dense 部分计算量做得非常大。Dense 部分计算基本控制在 10GB 以内,也就是一张显卡能容纳的状态。不过由于场景的不同,也会存在其他的差异之处。例如,在线场景,除了有计算量的限制,还存在高并发、延迟等限制。2. 训练&推理框架

我们在使用 GPU 的时候,主要分为两大类模型,一类是推搜广类模型,包括前面介绍的稀疏 CTR 类模型,它们有自己的推理框架和训练框架;而另一类模型包括CV、NLP 类模型,是基于 PyTorch 技术栈搭建的,有另外独立的训练推理框架演进。CTR 类大规模技术化模型是 TB 级的模型。下面分别介绍推理和训练部分。推理框架部分,2020 年之前小红书使用的是 TensorFlow 技术栈,采用TensorFlow Serving 作为基础推理框架,并在此开源框架基础上进行自研。TensorFlow Serving 的特点是托管了很多模型生命周期的管理,外围存在大量组件。但是,TensorFlow Serving 自身也有一些额外开销,尤其是它存在浪费的内存拷贝。原始 TensorFlow 底层的 API,是基于 CTensor 进 TensorFlow 的图引擎,但 TensorFlow Serving 为了抽象接口,在最外面用 Proto 封装了一层 TensorProto 结构来响应请求。因此,我们在 20 年时进行了优化,把外层的TensorProto 去掉,不直接依赖于 TensorFlow
Serving,而是直接基于底层的 CTensor API 也就是 CPI 搭建了自己的 Lambda Service 推理框架。在后续的迭代中继续集成了图调度器,编译优化等技术。针对训练框架部分,同样在 20 年之前,小红书没有大规模的稀疏训练框架,我们在 20 年初搭建完毕后,搜推广场景的训练框架统一到以 TensorFlow 为底层基础的自研 Worker & Ps 训练框架。同时我们也自研了自己的算子等。后来为了解决升级 GPU 后,block 在 CPU、IO 等存在的问题,我们对此自研训练框架进行了多轮技术升级。3. 机器特性

机器特性方面,小红书没有自建机房,所有机器采购自云厂商。但能够采购的机器型号有限,无法定制,包括定制带宽、定制内存、定制卡数等等。因此在技术选型时,需要根据可采购到的机器型号做出最优化的架构选择。4. GPU 特性
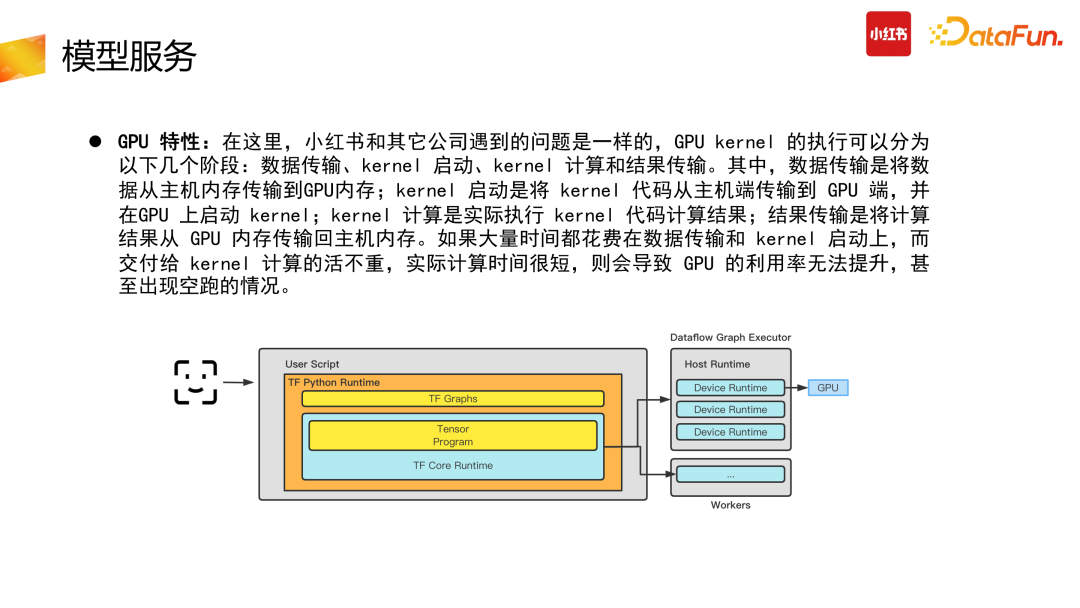
针对 GPU 特性问题,小红书与其他公司遇到的问题是一样的,GPU Kernel 执行分为几个阶段:数据传输、Kernel 启动、Kernel 计算与结果传输。首先数据需要从主机内存传到 GPU 内存,Kernel 启动需要将 Kernel 代码从主机端传到 GPU 端,并在 GPU 上启动 Kernel,Kernel 执行计算结果后,将结果从 GPU 传输到主机端。整个过程有传输、计算、传输的三段过程,如果大量时间都花在数据传输与 Kernel 启动上,则会导致 GPU 利用率较低,甚至出现跑空的情况。GPU 优化实践
针对上述问题,小红书提出了以下具体的实践优化方案。1. 系统优化

首先针对系统优化中的物理机优化方面。前面介绍到,我们采购的是云厂商机器,云厂商的机器为了屏蔽硬件的复杂性,做了大量的虚拟化。虚拟化本身是好的,在K8S 生态下面可以让应用具有弹性,屏蔽掉硬件细节。但虚拟化会导致性能变差,硬件速度跟不上 GPU 速度。因此,我们与云厂商针对以下几点进行了合作,降低虚拟化中间过程。①中断隔离:把 GPU 的中断单独分离开来,比如 Agent 隔离、其他中断隔离等,主要目的是减少虚机的抖动。②内核版本升级:用于提高 GPU 驱动系统的兼容性和性能。③指令透传:将 GPU 的指令直接透传到物理设备上,加速 GPU 计算速度。以上几点整体基于物理机的系统优化可以提升 1%-2% 的性能。
由于我们采购的 CPU 是 AMD 的,存在 NUMA 的问题:在线阶段跨 NUMA 访问内存的时间远高于 CPU 直接访问本地内存的时间。因此我们在使用过程中对Pod 进行了 NUMA 绑定,绑定后的 Pod 不需要跨 NUMA 内存申请与节点调用,提高了 CPU 与 GPU 之间的数据传输速度,减少了 CPU 阶段的内存消耗。CPU 阶段速度变快,可以给后面 GPU Inference 留更多的时间。
第三部分的系统优化也是非常通用的。随着 CPU 的发展,不同机型支持的指令集不同,因此 Kernel 实现时,不同机型会存在大量不同的定义。为了解决这个问题,我们针对不同机型的指令集做了交叉编译,需要找到 Kernel 对应机型的最优实现,打开对应的编译指令。以我们采购的阿里云的英特尔 8163 加两张 A10 的机型为例,我们根据该机型的特点定制了它的编译指令集,因此针对该机型,我们的 Runtime 换掉了它可执行 Runtime 的 Binary。系统阶段的编译指令优化,可以带来约 10% 的性能提升。2. 计算优化

计算优化方面,仍然是围绕前面的核心问题:GPU 运行速度快,CPU 内存访问跟不上的时候如何解决。CPU 访存较多,内存 page fault 频率较高,会导致 CPU 资源浪费、latency 高的问题。Latency 高时,在线推理阶段可能会出现超时问题。同时,在线推理服务中,单次请求的 batch size 较小,单个服务的并发规模大,上千规模的 QPS 单次请求较小的 batch,无法充分利用 GPU 的算力,会导致原始 TensorFlow 中,单个 Cuda Stream launch kernel 成为瓶颈,此时推理场景下的 GPU 利用率只有 50%。此外,对于小模型场景,Dense 部分较为简单,数据传输到 GPU 上推理计算再传输回 CPU 上的成本比直接 CPU 计算还要高,较为不划算。因此,面对不同的场景,我们需要解决这两个问题:Page
fault 、Latency 较高,Batch 约束问题。(1)针对内存 page fault 频率高的问题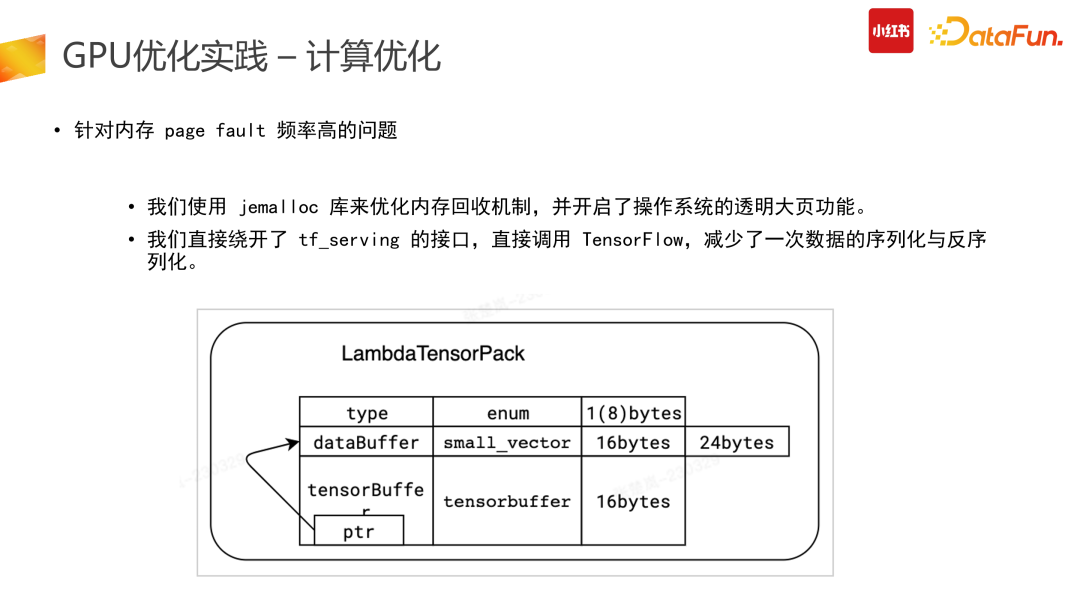
首先,针对内存 page fault 较高的问题,有两个解决思路。一是在引擎侧优化数据结构。把 Tensor 数据结构给到图调度引擎之前,需要减少额外开销,做到零拷贝,也就是把用户侧的请求数据直接搬到图引擎的输入。因此需要针对 TensorFlow 底层 CPI 定制数据结构,该定制化的数据结构接请求侧,直接传到底层图引擎,降低成本开销。二是在操作系统层面开启透明大页功能减少 page fault。同时我们也使用了 jemalloc 库,通过把垃圾回收时间设长、不断调整到最优状态来降低额外开销,解决 page
fault 高的问题,。(2)针对 TensorFlow 单 Cuda
Stream 的问题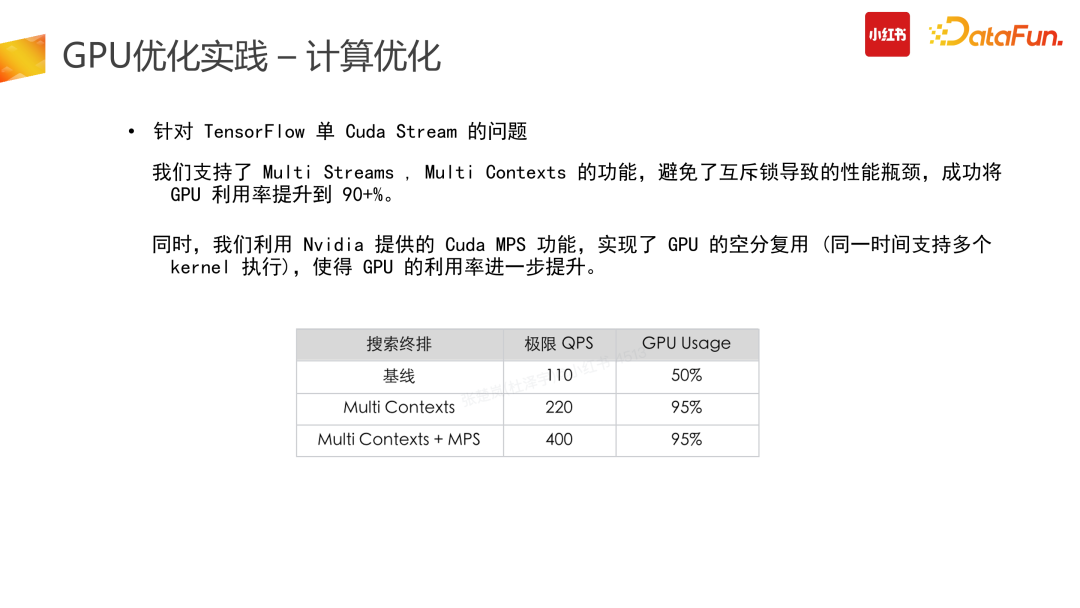
此外,针对 TensorFlow 单 Cuda Stream 问题,我们支持了 Multi Cuda Streams、Multi Contexts 的功能,可以避免互斥锁的性能瓶颈,提高并发率与 GPU 利用率。同时,针对 GPU 多卡并发使用时存在的问题,我们利用了 Nivida 提供的 Cuda MPS 功能,实现了 GPU 的空分复用。原本在使用 Nvidia 进行 Cuda 运算时,正常情况下一个时刻只能运行一个 Context(一个 CPU 进程下进行 Cuda 程序调用时,GPU 端申请资源与数据的唯一单位)。但如果有些卡支持Hyper-Q 功能,则可以开启 Nvidia 的 MPS 服务,实现 GPU 的空分复用(同一时间支持多个 Cuda 执行)来进一步提高 GPU 利用率。但空分复用可能会导致进程故障隔离问题,因此,GPU 的空分复用建议是在相对固定的场景下开启,比如推搜等具体场景、计算任务固定的情况下使用。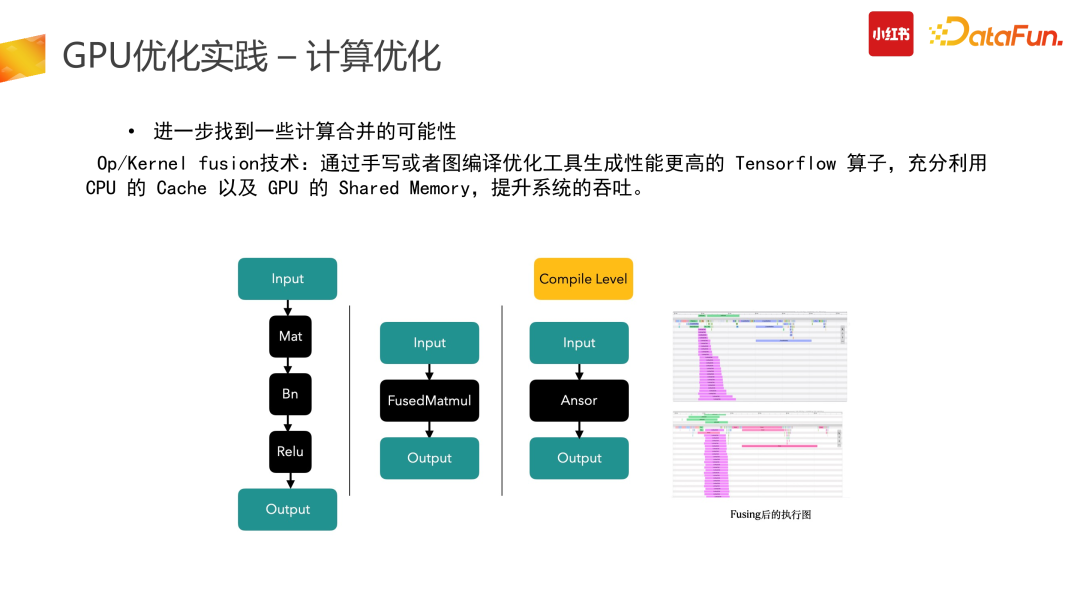
计算优化的第三部分是在整个计算过程中找到一些计算合并的可能性。除了 Kernel 级别可以进行 fusion,上游 Op 级别也可以进行 fusion 合并。我们通过手写或者图编译优化工具生成了性能更高的 Tensorflow 算子。如 Mat 加 Bn 与 Relu 的计算,可以用一个优化后的 FusedMatmul 算子实现相同的功能。集成了 Compile 级别的优化之后可以把算子重新编译,用新的算子执行来降低它的计算开销。在右图所示的我们的一个场景中,核心计算成本可以降到 50%。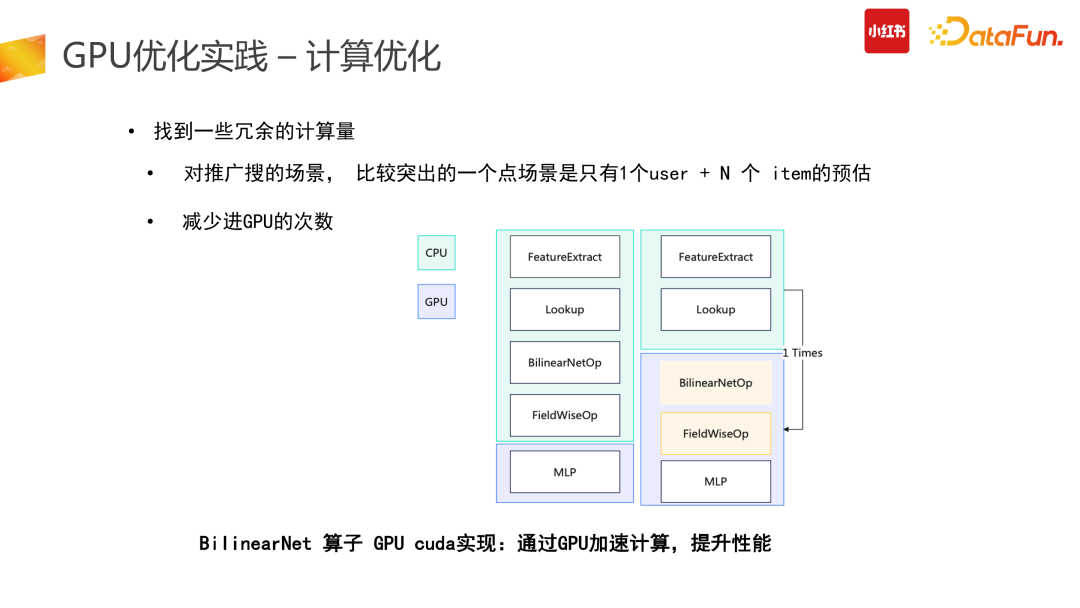
计算优化的一个较为明智的思路是找到冗余的计算量进行优化。推搜类的 CTR 模型存在了大量的冗余计算:推搜场景较为突出的特点是 1 个 user + N 个 item 的预估,而 Tensor 结构在原始计算 input 阶段需要展平,也就是 user 侧计算从数据侧会拆分成 N 份,而这部分计算是冗余的。第二个冗余是在使用原始 TensorFlow API 搭建整个 graph 时,一次请求数据会多次进GPU 计算处理,会有部分计算在 CPU 结束后传给 GPU,而这部分是不够高效的。因此我们在此进行了算子合并、优化推导,利用 CUDA 的 API 统一实现,让一次请求只进一次 GPU,减少多次进 GPU 的冗余计算功能。此外,还可以计算前置,减少冗余计算。比如在产出模型时,需要对变量算子进行冻结,把变量算子转换成常量算子,具体举例来说,在图冻结过程中,有+1+2 计算,可以静态地直接转换成 +3。图冻结化在产出中让整个计算使用率下降了 12%,非常有效。合并计算部分我们需要尽量做到用 GPU 的 CUDA 实现,减少外部数据计算完再进 GPU 的拷贝问题,会带来较高的性能提升。
在线推理阶段没必要用到 A100 这种特别贵的卡,可以用 A10 替换 T4,提升了 1.5 倍的性能,但只花了 1.2 倍的钱。未来我们还会考虑在线使用 A30 等机型进行推理。同时,随着硬件厂商的版本迭代,我们也会直接去换更好的硬件,取得线上的成本收益。但换了硬件后,前置放在 CPU 上的计算部分会更加鸡肋,总会存在一些 Vlookup 特征,合并交叉哈希计算等不适合在 GPU 上处理。这时候则需要推进到第三步,也就是我们会浪费一些时延,把前面 CPU 计算部分拆分出去。Inference 架构会变为请求先经过 CPU 计算,后进行 GPU 在线推理。后面随着硬件 GPU 不断升级,CPU 实在跟不上的情况下,则会继续拆分。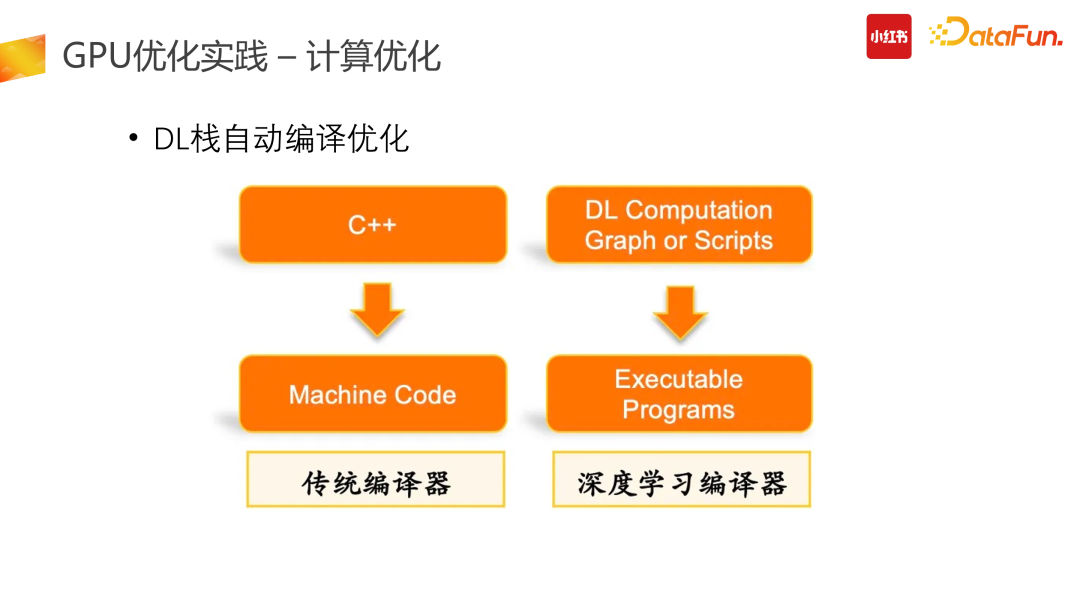
我们核心用的是阿里开源的 BladeDISC 以及 TensorFlow 官方的 XLA 技术栈。阿里的 Blade 框架在 MRI 基础上支持了动态 Shark 的深度学习编译功能。传统编译器,以 C++ 来说,具体的 C++ code 会通过编译优化编译成机器指令,也就是 Machine code 被机器对应的系统运行。在深度学习 ML 编译器里,需要把图编译成 DL 技术栈,找一层中间实现。比如说 MLIR,基于这个中间层表达去编译出硬件上最终的执行态,这个硬件态是 GPU 上真正的 Kernel 的执行计算。这部分我们集成了 blade、XLA 技术栈,取得了非常大的收益。在这里要特别安利一下 Blade 框架,它给我们带来了很好的效果,它也是 Apache 2.0 开源的,所有公司都可以使用。3. 训练优化

训练与推理遇到的问题会有一点差别,训练是没有 latency 约束的,不要求在多少毫秒内返回;但它吞吐更大,希望能够拉取更多的数据。数据 Embedding Layer 过程能够在 IO 阶段完成,同时做到后向梯度反传成本尽量低。把更多的时间和数据传给 GPU 计算。在这个过程中,我们遇到了如下问题。首先是数据 IO 问题,原始 TF 的训练数据是基于 TFRecord 行存的,也就是数据展平后放在了一行,这会导致 IO 非常大。因此我们首先把 input 数据行转列,降低 IO 的拉取数据维度。对于一些可枚举的特征 input 如城市、ID 等,通过行转列后,IO 拉取数据维度的规模则会大幅下降。数据行转列存储之后,训练框架需要对应进行升级,适配列存场景。同时列存与行存有较大的数据分布差异,行存的打散会较好,因此,列存的时候尽量要做到列存,然后恢复数据分布,进 worker 进行训练,然后再进 GPU 进行处理。拉取完数据后,需要进行数据的前向 lookup。我们为了提高 GPU 的利用率,较为激进地做了完全 prefetch 化,可以解决训练过程中,因 CPU 侧 lookup 阻塞造成的训练等待。但此种更新变成了全异步更新,存在更新带差,影响效果的稳定性,需要机制设计进行强保障。在后向我们也进行了升级,如解绑了训练对反向更新本身的依赖,升级了 Lookup 反向更新异步策略,对数据梯度进行了累计更新:下一个 batch 训练梯度更新时,本次更新则可以写入。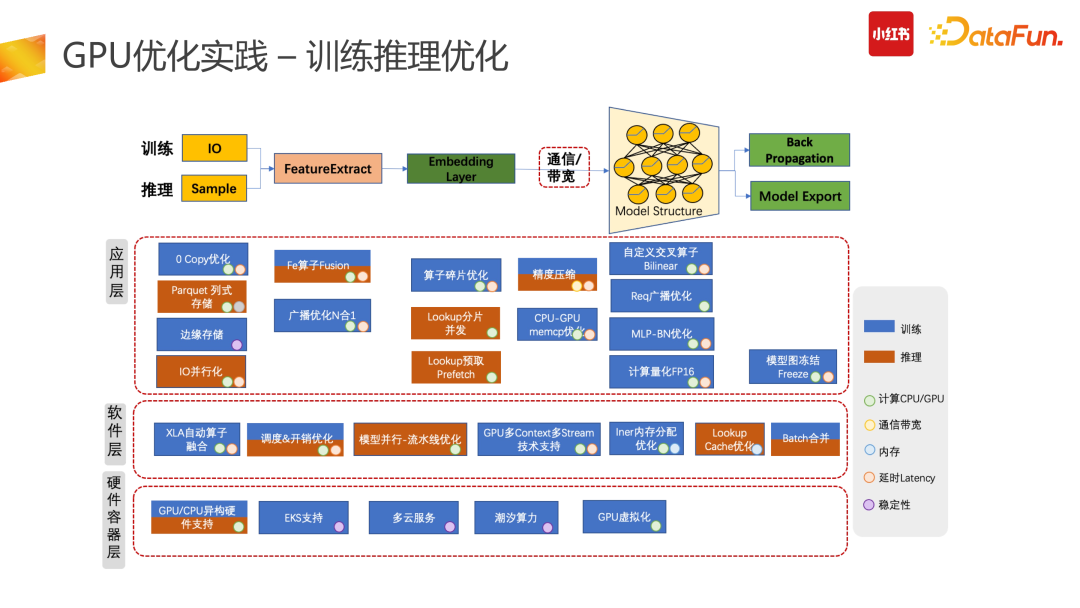
我们整个机器学习是基于训练和推理的应用层实现的,主要包括应用层、软件层、硬件容器层。图中列了我们从 21 年到 22 年所做的工作,每个工作有自己独立的约束与应用场景。如果大家有做相似的推搜大模型,存在没有尝试过的方向,可以参考其中的内容。举例来说,如精度压缩,可以用 Float 16 或者 Int 8 等更低级别的精度。但在实际的使用场景中,存在着对效果影响把控的问题。因此,我们使用精度压缩时,更多的是做白盒,也就是在导出模型时,并非对所有层都进行降精度,而是挑选进 GPU 的部分来降精度,同时精度下降程度要通过后面的优化逻辑确保整个 AUC 或者实际指标无损,也就是在白盒情况下合理选择精度压缩。4. 未来

最后介绍一下小红书整个机器学习引擎未来的演进方向。对于稀疏大模型训练部分,我们会做几件事情:一是在训练端会区分不同的参数规模,对于特别小的参数规模,我们会 HPC 化,尽量放在一台机器内搞定,不产生额外的开销。对于达到 1TB 级别参数量的,我们会使用 A100+全高速互联。对于特别大参数量,达到几十 TB 或者几百 TB 的,我们会做基建通信,采用小 GPU(A10)+ 基建通信的能力来实现。对于推理方面,未来我们会升级哈希、多级缓存以及模型的轻量化技术。同时我们也会跟着 Nvidia 的升级节奏,更新整个驱动、硬件的版本。最后为了优化整个公司的迭代效率,我们后续会做拖拽式、画布式的一站式机器学习平台。同时也会做 DSL 化的特征管理,把特征管控升级成抽象算子处理。2016 年毕业于华东师范大学计算机系,16~18 年任百度商业化 feed 流工程师, 2018 年加入小红书, 成为小红书机器学习引擎工程师, 主要负责:推理引擎、特征引擎, 从 2021 年开始到 2022 年底, 通过不断优化,小红书推理计算算力增加 30 倍,关键用户指标提升 10%+ ,同时累积节约集群资源 50%+。2023至今为小红书商业化引擎团队负责人, 主要负责: 商业化在线引擎, 结合业务打造算力引擎。
内容中包含的图片若涉及版权问题,请及时与我们联系删除











评论
沙发等你来抢