
今天是2023年12月1日,星期五,12月第一天,北京,天气晴。
今天我们来看看AIDD2023(https://aidd.vip/dhrc-sz2023)中有关知识图谱与行业问答上的一些有趣的分享,供大家一起参考。
一、知识检索增强范式、拷问、评估与选型
同济大学王昊奋老师的《知识增强大模型:垂域落地的最后一公里》 报告中,很有启发性地介绍了知识增强大模型的一些思考,特别棒,择其中几个有趣的点,分享给大家。
1、RAG vs Fine-tuning
RAG和微调Fine-tuning上可以直接进行对比,涵盖从知识更新、训练数据的要求、可解释性、可扩展性、耗时以及外部知识利用等多方面。

例如,在知识更新上,RAG可以直接更新检索知识库,适合动态数据环境,而微调需要重新微调训练,保持更新需要大量资源。在外部知识利用上,RAG擅长利用外部资源,适合文档或其他结构化 /非结构化数据库,微调方式需要构造监督数据集以内化外部知识,不适用频繁更改的数据源。
在可解释性上,RAG通常可以追溯到特定数据源的答案,从而提供更高等级的可解释性和可溯源性,微调finetune就像黑匣子,并不总是清楚模型为何会做出这样的反应,相对较低的可解释。
因此,RAG适用的情况主要包括数据长尾分布、知识更新频繁、回答需要验证追溯、领域专业化知识以及数据隐私保护等场景。
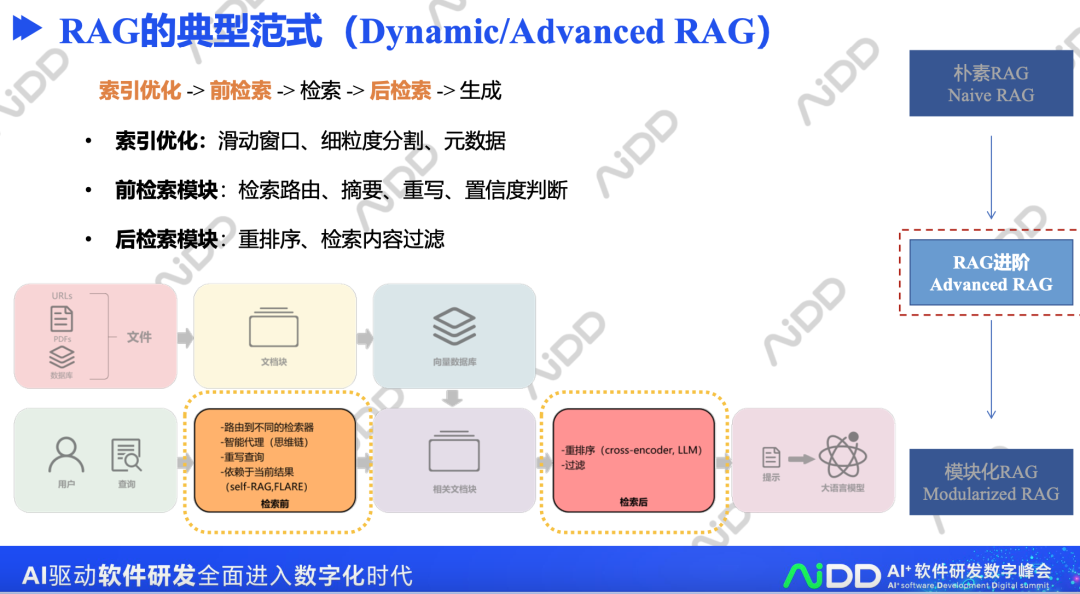
2、RAG的典型范式(Dynamic/AdvancedRAG)
标准的RAG实现方式包括索引优化->前检索->检索->后检索->生成。
其中,每个模块都有优化的方向,例如:
•索引优化:滑动窗口、细粒度分割、元数据
•前检索模块:检索路由、摘要、重写、置信度判断
•后检索模块:重排序、检索内容过滤
3、RAG的三大灵魂拷问
当然,在具体实践时,RAG还涉及到几个经典文本,包括检索什么?、什么时候检索?以及怎么使用检索的结果?等多个阶段,也包括在什么阶段增强?、检索器和生成器的选择等多个问题。
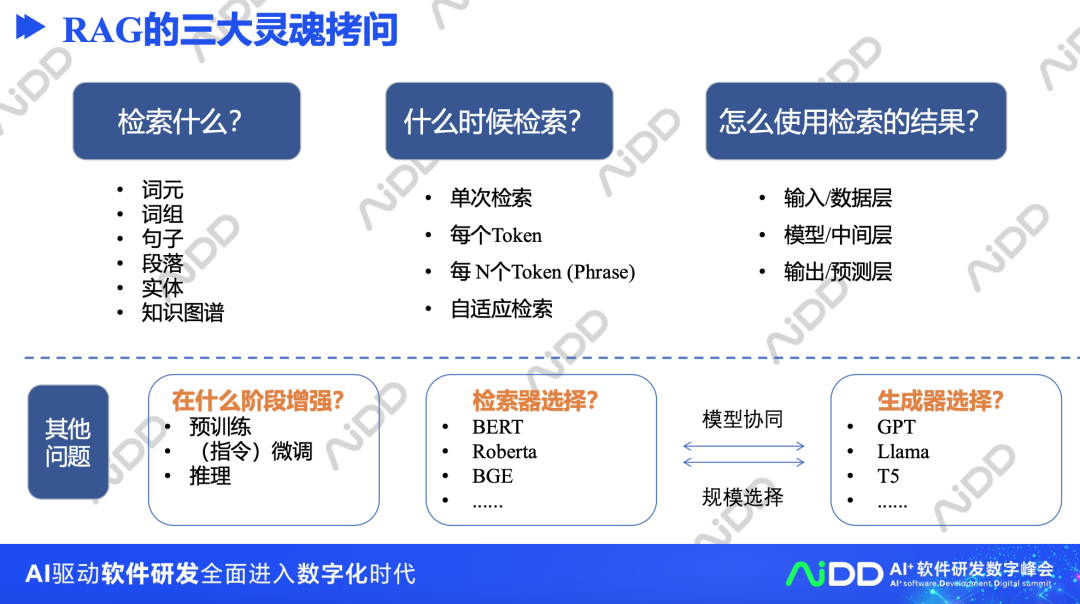
例如,可以检索词组、句子、段落、实体、知识图谱。
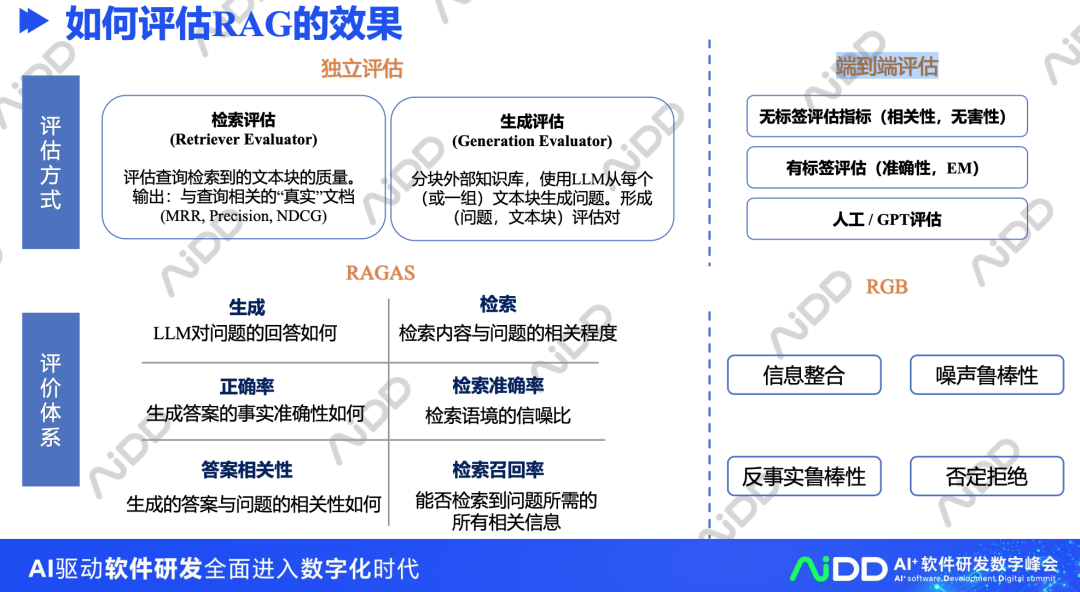
4、如何评估RAG的效果
如何进行RAG效果的评估,也是一个有趣的方向。可以使用检索评估、生成评估,也可以使用端到端评估。
5、RAG现有技术栈选择
当前RAG在技术栈上已经有许多公开的方案,例如,LangChain、LlamaIndex、FlowiseAI以及AutoGen。
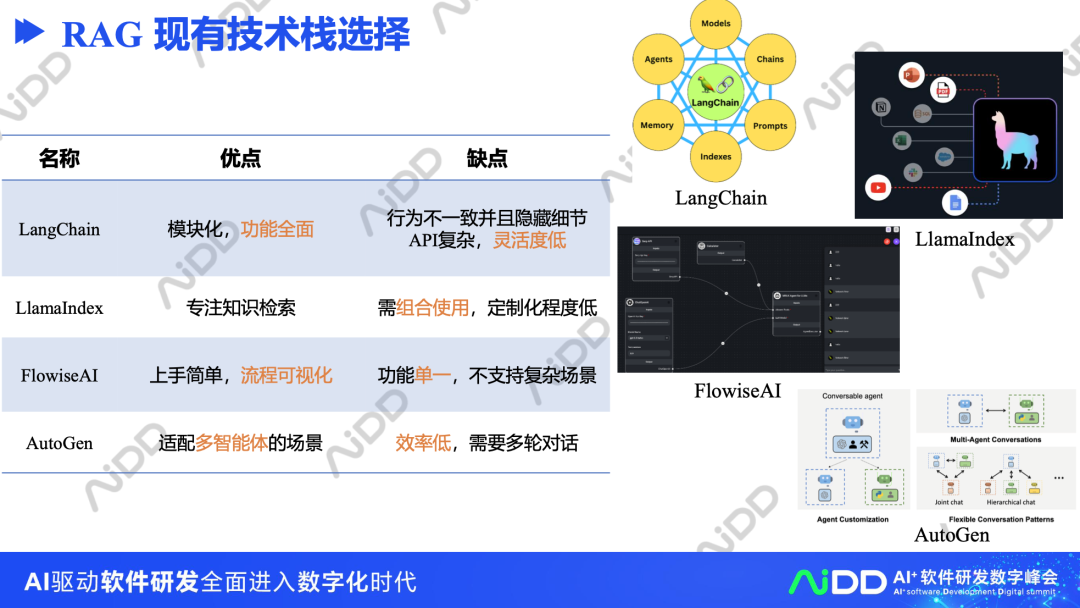
但是在具体选型的时候,可以额外关注这些方案的优缺点。例如,langchain模块化,功能全面,AutoGen适配多智能体的场景,FlowiseAI上手简单,流程可视化。但AutoGen效率低,需要多轮对话,FlowiseAI功能单一,不支持复杂场景。
二、再看知识库增强问答挑战及与知识图谱的结合
刘焕勇老师做的报告《KG+LLM在行业知识问答场景的应用》中介绍了大模型结合知识图谱在行业问答中的一些探索工作。
其中:知识库增强问答在实际落地中存在的问题、利用KG进行问题补全和校验以及在生成推理阶段量化不确定性三个点比较有趣,也供大家参考。
1、知识库增强问答在实际落地中存在的问题
首先,版面复杂多样。涵盖各类pdf、扫描件、图片等多种复杂文件类型; 需针对页眉页脚、分栏、列表、跨页等多样化信息进行版面解析;需结合OCR能力,一旦上线,会很慢。
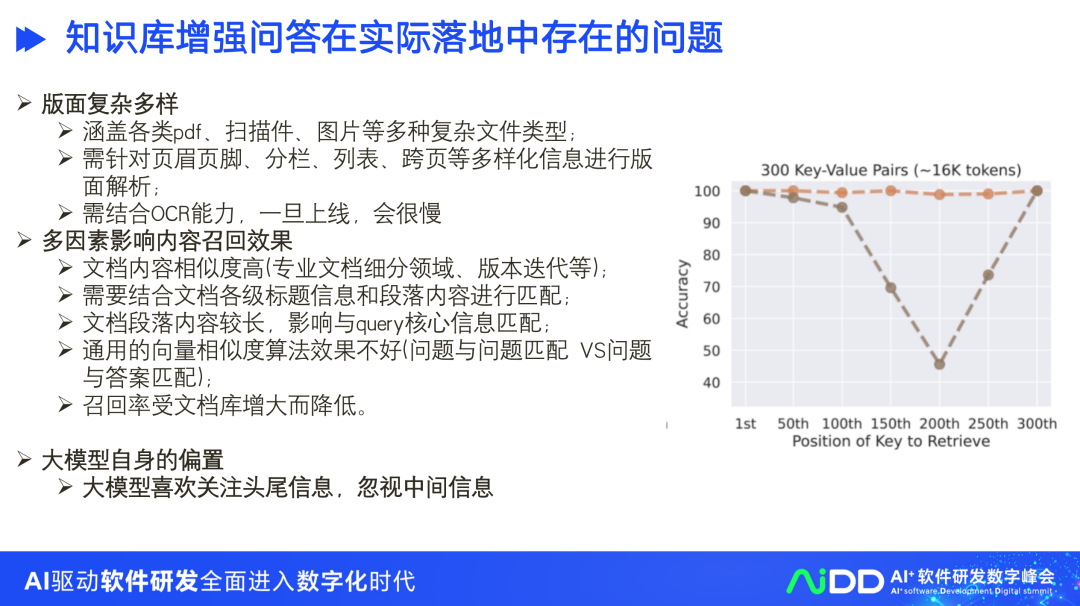
其次,多因素影响内容召回效果。文档内容相似度高(专业文档细分领域、版本迭代等);需要结合文档各级标题信息和段落内容进行匹配;文档段落内容较长,影响与query核心信息匹配;通用的向量相似度算法效果不好(问题与问题匹配 VS问题与答案匹配);召回率受文档库增大而降低。
秋后,大模型自身的偏置,大模型喜欢关注头尾信息,忽视中间信息
2、利用KG进行问题补全和校验
我们可以使用知识图谱增强大模型的问答效果,在意图识别阶段、Prompt组装阶段以及结果封装阶段都可以做。
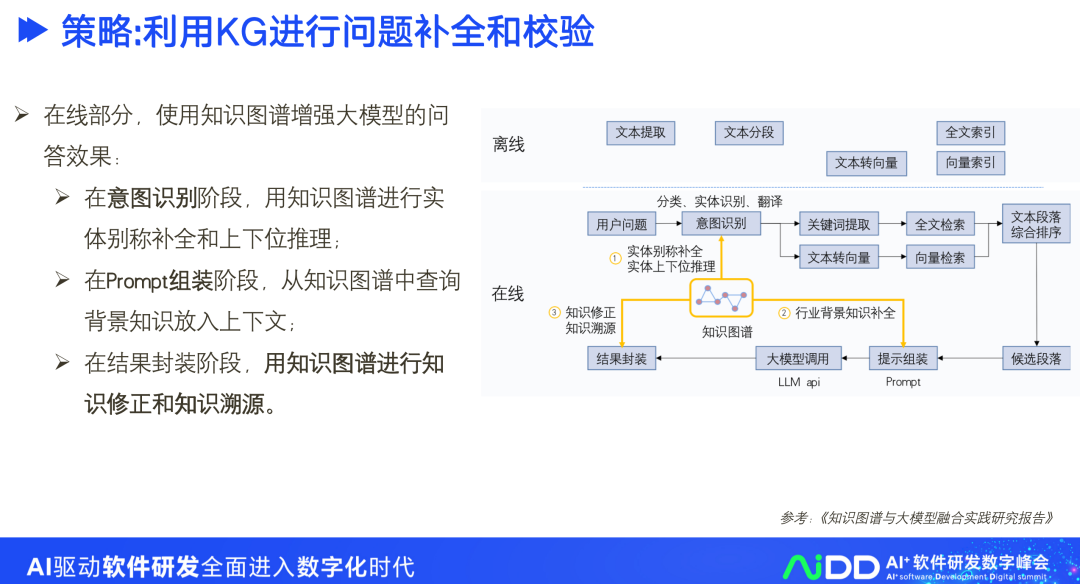
在意图识别阶段,用知识图谱进行实体别称补全和上下位推理;
在Prompt组装阶段,从知识图谱中查询背景知识放入上下文;
在结果封装阶段,用知识图谱进行知识修正和知识溯源。
3、在生成推理阶段量化不确定性
不确定性是推理过程中保护和减少幻觉的重要指标。通常,它指的是模型结果的置信度。不确定性可以帮助用户确定何时信 任LLM。只要能准确描述LLM响应的不确定性,用户就能过滤或纠正LLM的高不确定性声明,因为这类声明更容易是捏造的。

基于Logit的估计。这是一种基于对数的方法,它需要获取模型的对数,通常通过计算令牌级概率或熵来确定不确定性。其次是基于口头估计:直接要求LLM表达其不确定度,例如使用以下提示:"请回答并提供您的置信度分数(从0到100)"。这种方法之所以有效, 是因为当地语言学家的语言表达能力和服从指令的能力很强。也可以使用思维链提示来加强这种方法。
基于一致性估计。这种方法基于这样一个假设:当LLMs犹豫不决并对事实产生幻觉时,他们很可能会对同一问题做出逻辑上不一致的回答。使用BERTScore、基于QA的指标和n-gram指标进行计算,并将这些方法结合起来能产生最佳结果。直接利用额外的LLM来 判断两个LLM反应在相同语境下是否存在逻辑矛盾,可以采用另一种LLM来修正两个反应中这种自相矛盾的幻觉。
多agent互动。多个LLM(也称为代理)独立提出建议,并就各自的回应进行协作辩论,以达成单一共识。
参考文献
1、王昊奋,《知识增强大模型:垂域落地的最后一公里》,AIDD2023.
2、刘焕勇,《KG+LLM在行业知识问答场景的应用》,AIDD2023.
3、https://mp.weixin.qq.com/s/jyFFWaJwAMpapUxT0uA9tQ
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢