
导读 本文将介绍 Apache Celeborn 的用途、核心设计及其社区现状与发展规划。
1. Celeborn 是什么
2. Celeborn 的社区/用户/生产使用情况
3. Celeborn 未来发展规划
分享嘉宾|周克勇 阿里云 EMR Spark 引擎负责人
编辑整理|刘陈亮
内容校对|李瑶
出品社区|DataFun
Celeborn
是什么
1. 计算引擎中间数据带来的挑战
数据的转换指的是数据发生变化、产生新的数据或者被过滤掉等。具体的实现方式包括算子和 UDF,如常见的 Filter、Project、Aggregation、Join,内置 function,自定义 UDF 等。一种是持久化数据的流转,通常是表数据。一个大数据计算作业从对象存储或分布式存储读取结构化、半结构化或者非结构化的数据,进行各种分布式计算处理,最后写回存储系统,这就是持久化数据的流转。这种数据流转目前主要由湖格式来完成。另一种是中间(临时)数据流转。这里的中间数据指的是大数据计算引擎在执行某个作业的过程中所产生的临时数据,一般是由于内存中放不下溢出到外部存储,在作业完成之后可以安全删除。典型的中间数据有三种:Shuffle 数据、Spill 数据、Cache 数据。Apache Celeborn 正是专注于中间数据的处理,以提高这些数据的流转效率。在 Celeborn 诞生之前,大数据计算引擎在中间数据的处理上存在着诸多挑战。下面以 Shuffle 为例说明。Shuffle 的过程如下图所示: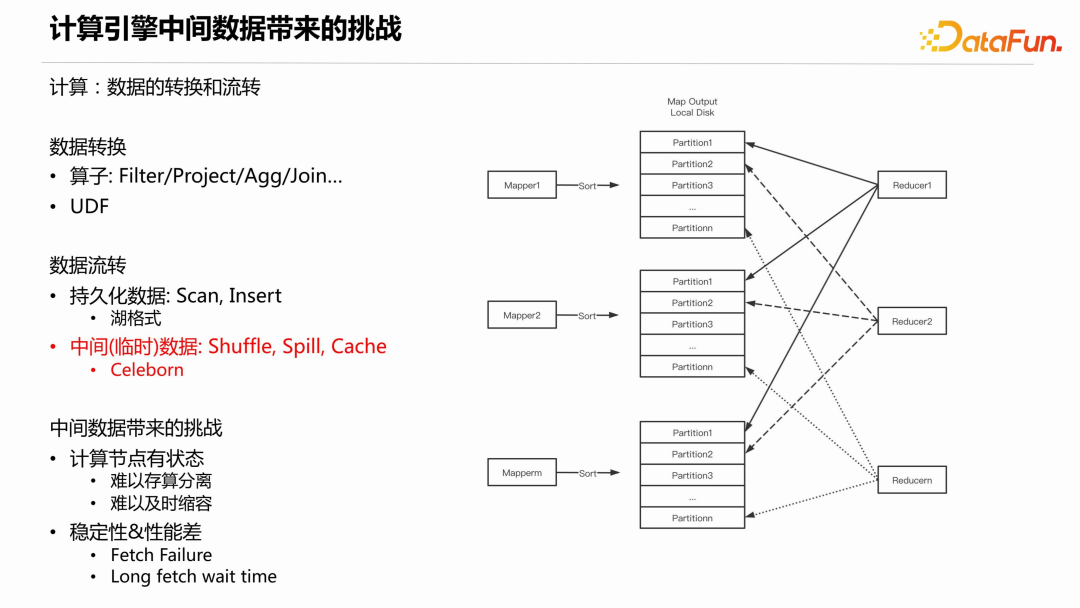
MapTask 将其产生的 shuffle 数据根据 Partition id 做本地排序,当内存不够用时会引入外排,而外排会产生对本地磁盘写放大的问题。最终生成数据文件和 Index 文件。接下来,下游的每个 ReduceTask 会从每个 Shuffle 数据文件中读取 Partition 数据。从单个文件看,假设下游有几千上万个 ReduceTask,就会被读取几千上万次,且每次读取的是随机位置和小的数据量,因此磁盘的 IOPS 会非常大,导致稳定性和性能问题。另外,中间数据存储在本地磁盘,这就要求计算节点有大容量的本地磁盘。现在的数据湖架构或者云原生架构一般采用存算分离,存算分离的好处是根据功能的不同最优化节点(机器)配置,能更好地适应不同的计算负载和存储需求,提高资源利用率。如果计算过程中需要大容量磁盘存储中间数据,就难以存算分离。第二,难以及时缩容,像 Spark 计算引擎,作业在运行过程中可以动态资源伸缩,Executor 处于 idle 一段时间就可以释放,但是如果本地磁盘存储了下游所需的中间数据,那么就无法释放节点,特别是 Spark on K8s 的场景。2. Celeborn 的前世今生
Celeborn 的定位是通过接管中间数据来解决上述问题。在具体介绍 Celeborn 之前,先来看一下其发展历程。
- Celeborn 最早于 2020 年在阿里云内部开发。
- 2021 年 12 月正式对外开源,趣头条和小米成为种子用户。
- 2022 年 10 月发布 0.1 系列,实现生产可用,支持 Spark,使用本地盘存储,采用 Standalone 的方式部署。同年,正式捐赠给了Apache 软件基金会(ASF),并更名为 Celeborn,正式进入 Apache 孵化。
- 2023 年 3 月发布 0.2 系列,是捐赠后的首个版本,支持 K8s 部署,提升了稳定性和性能。
- 2023 年 7 月发布 0.3.0,支持 Flink batch,也支持 Native Spark,在存储层支持把数据存储在 HDFS,并支持优雅升级。
- 2023 年 10 月 13 日,发布了 0.3.1。
截至目前,参与贡献和使用 Celeborn 的企业来自各个行业和海内外。3. 整体架构
下图是 Celeborn 的主要架构,其中蓝色部分是 Celeborn 的组件。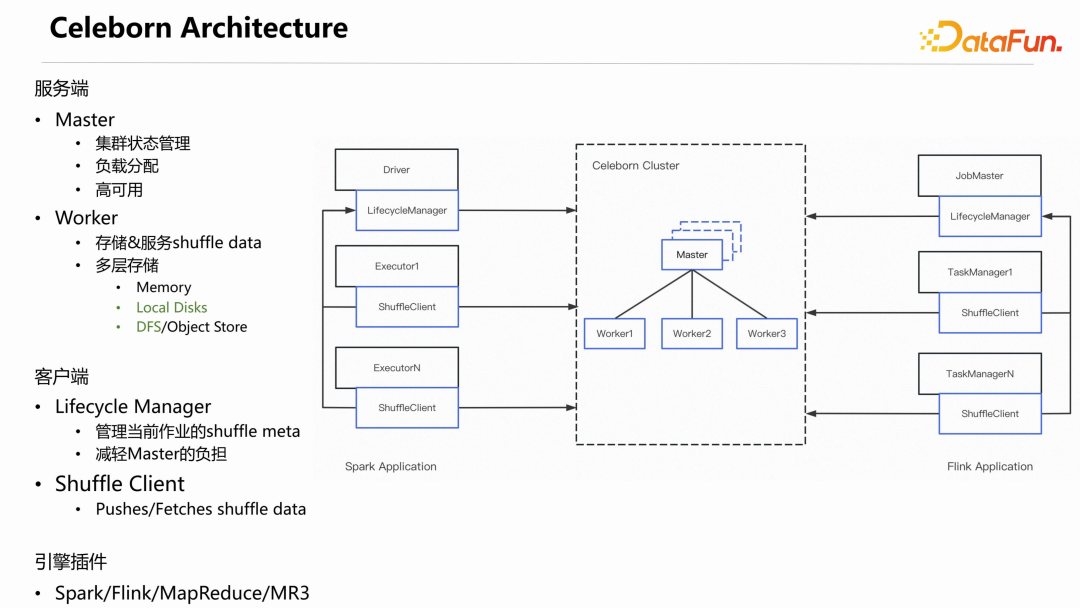
从上图可以看出 Apache Celeborn 是一个 Server-Client 的架构。服务端包括 Master 和 Worker 节点:Master 的主要职责是:管理整个集群的状态;负责负载的分配;同时基于 Raft 实现高可用。Worker 的主要职责是:接收、存储和服务 shuffle 数据。实现了多层存储,目前已经支持 Local Disks 和
DFS ,Memory 正在开发中。Spark和Flink计算引擎分两种角色:一是Driver/JobMaster,负责整个Application 生命周期的管理、作业的调度;另一个是
Executor/TaskManager,实现真正的分布式计算执行。相对应的,Celeborn 也分两部分,一个是 Lifecycle Manager,另一个是 Shuffle
Client。Lifecycle Manager 的职责是管理当前作业的 shuffle metadata,把 shuffle 元数据从 Master 转移到 Celeborn
Application,让 Application 自己管理自己的 shuffle,从而大幅降低 Master 的负载。Shuffle
Client 存在于每一个Executor 或 TaskManager 上,负责具体推送和读取 shuffle 数据。Celeborn 的 Master、Worker、Lifecycle Manager 和 Shuffle Client 是与引擎无关的,没有引入任何引擎的依赖。各计算引擎通过 Shuffle Client 的 API 来集成 Celeborn。目前,Celeborn 社区官方已集成 Spark、Flink 和 MapReduce 三种计算引擎。另外,有公司基于 Shuffle Client 的 API 实现了 MR3 引擎的集成。从上图中可以看到,shuffle 数据不再存储于本地磁盘,而是存储到 Celeborn
cluster 上,这就解除了计算节点对本地磁盘的依赖。而稳定性和性能问题,Celeborn 是通过 Partition 的聚合来解决的。4. 核心设计
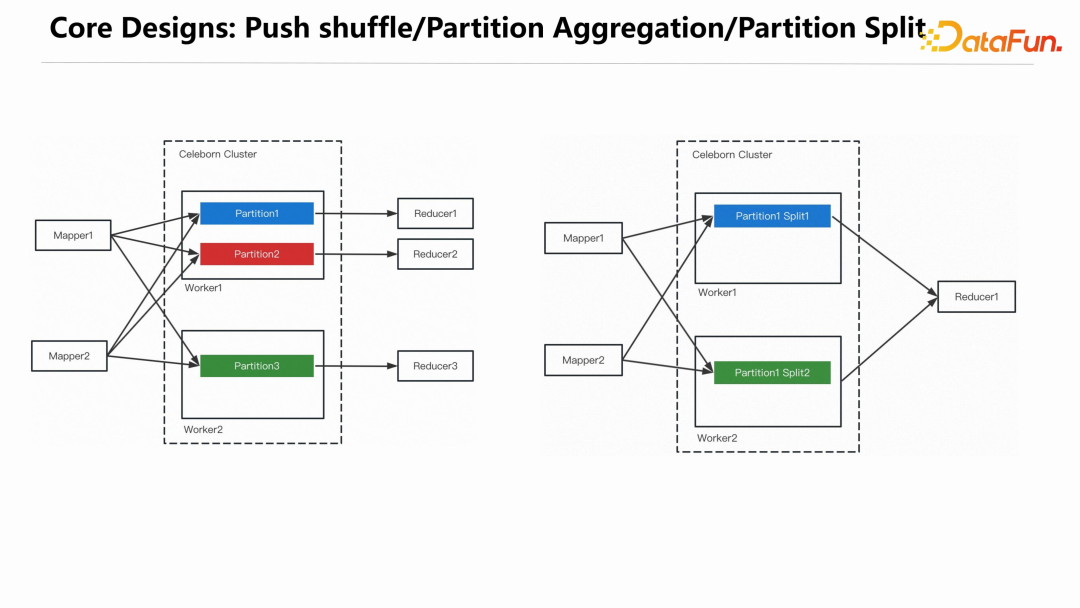
MapTask在推送数据时,把属于同一个Partition的数据都推给同一个 CelebornWorker,Worker 把接收到的数据聚合之后写入磁盘,这样一个 Reducer 只需要从一个 Worker 上读取相应的 Partition 文件即可。经过聚合后在shuffle read 阶段,网络连接数变成了 n,单个文件被读取数就变成了 1,从而很好地解决了磁盘 IOPS 的问题。单个 Partition 文件过大时,可能会对磁盘造成过大的压力,系统会检测每个 Partition 文件的大小,如果超过预设的阈值,会对 Partition 做切分,Partiton 切分相关信息会存储到 Lifecycle Manager 上,不会造成 Reduce 丢失数据。下图展示了使用 Celeborn 之后 shuffle 的生命周期。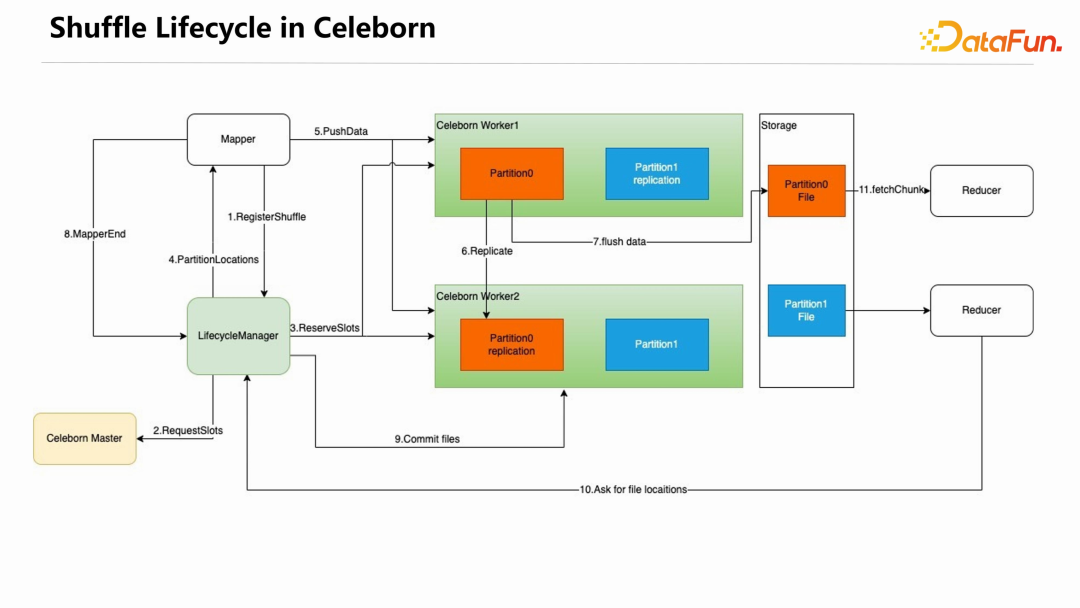
首先,MapTask 在第一次需要写 shuffle 数据时,向 Lifecycle Manager 发起 RegisterShuffle 请求,Lifecycle Manager 向 Celeborn Master 发起RequestSlots 请求,Master 选择一部分 Worker 为当前的 shuffle 请求服务。Lifecycle Manager 向这些 Worker 发起 ReserveSlots 请求,这些 Worker 会做相应的准备工作。接下来,Lifecycle Manager 会把 PartitionLocations 信息返回给 MapTask,MapTask 就可以持续往这些 Worker 推送 shuffle 数据。Worker 接收到 shuffle 数据后在内存中缓存,如果开启了多副本,会在两个 Worker 做数据冗余。单个 Partition 数据在内存中超过默认的 256k 时,就会 Append 到 Partition 文件中。每个 MapTask 结束时会向 Lifecycle Manager 发送 MapperEnd,当所有 MapTask 都结束之后,Lifecycle Manager 向所有服务本次shuffle 的 Worker 发送 Commit
files 请求,Worker 会把尚未 flush 的内存数据 flush 到磁盘。至此,就完成了整个 shuffle
write 的过程。ReduceTask 在启动时向 Lifecycle Manager 获取属于自己的 PartitionLocations 信息,然后向相应的 Worker 读取数据。Celeborn 的另一个核心设计点是容错和保证精准一次。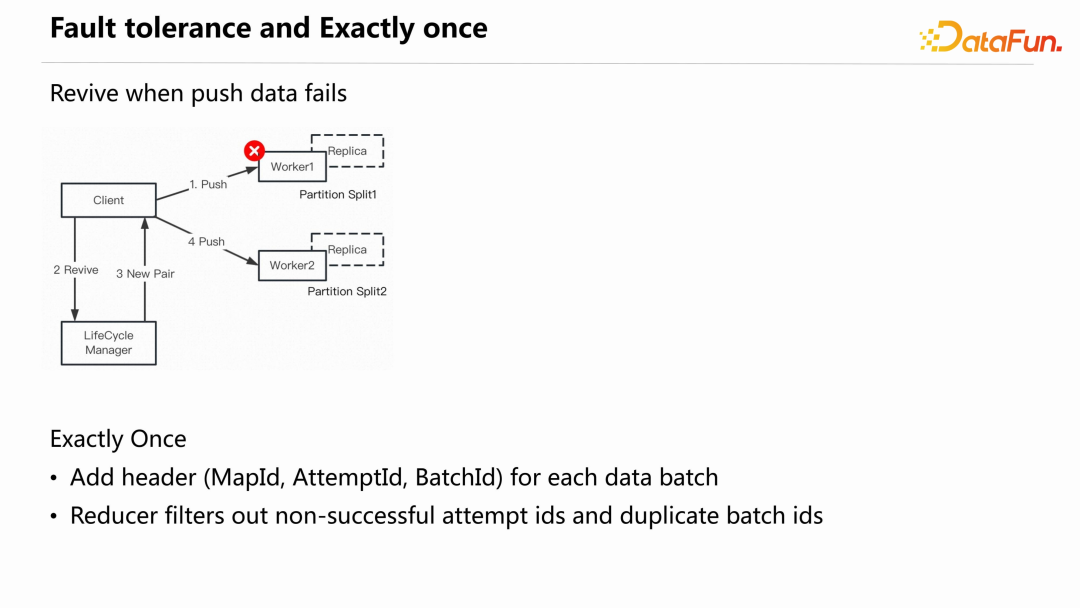
Celeborn 中最高频的是 Push data,当其失败时,Celeborn 不会认为这个Worker 失败了,之前推送的数据就丢失了,而是认为当前推送临时出问题,后面的推送会尝试申请新的 Worker,继续往新 Worker 推送。检测数据是否丢失则是在Commit
files 阶段完成,Lifecycle Manager 既往之前失败的 Worker 发送 commit 请求、也会往新的 Worker 上发送 commit 请求,只有当两个 Pair 至少都有一个副本 commit 成功,才会判定当前数据没有丢失。另一个问题是,假设 Client 认为数据推送失败了,重新申请 Worker 推送数据,但实际上 Worker 成功接收数据,并且 commit 成功了。这时需要一个机制来保证精准一次推送,Celeborn 是通过在每一个推送数据的 batch 上添加三元组 header(MapId、AttemptId和BatchId)保证不会有数据重复。Reducer 在读取数据时会过滤掉非 successful
attempt id 的数据和重复的 batch id 数据。ShuffleClient 提供了 API 帮助计算引擎集成 Celeborn,主要包括以下四个 API:
registerShuffle 会包含在 pushData 的实现里,引擎只需要创建 ShuffleClient 实例,调用 pushData 即可。shuffle write 阶段,除了 pushData,还需一个 mapperEnd API,告知 Celeborn shuffle write 完成。
在 shuffle read 阶段,只有一个 readPartition 接口,Celeborn 会返回一个InputStream 对象,计算引擎接收这个 InputStream 完成后续工作。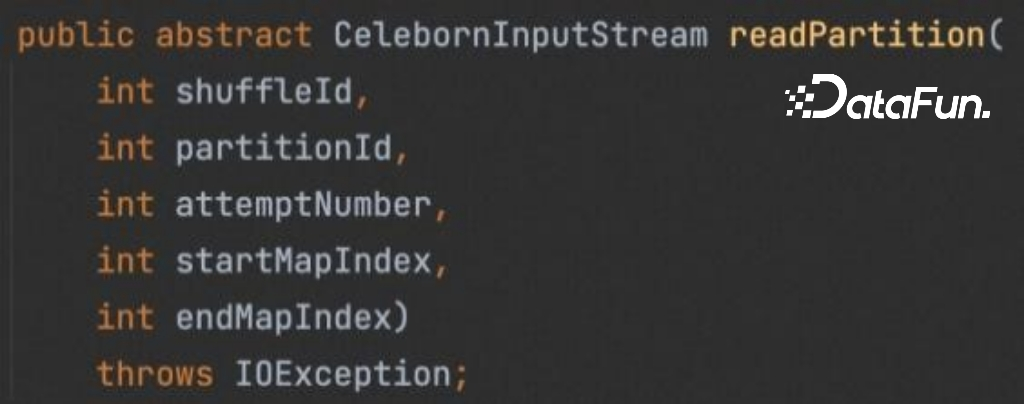
当计算引擎认为一个 shuffle 已经完全结束,后续也不会再使用,可以调用 unregisterShuffle 通知 Celeborn 该 shuffle 生命周期结束。
除了上面介绍的一些核心设计,Celeborn 还具有如下特性,这里不做展开介绍。- 滚动升级:升级时不影响当前正在运行的作业,下线时也不需要等待长尾作业的完成。
下图是 Celeborn 0.3.0 发布时做的一个纯 shuffle 作业的对比测试结果,对比的是 Spark 原生的 External Shuffle Service (ESS) 和 Celeborn 0.2.1 版本。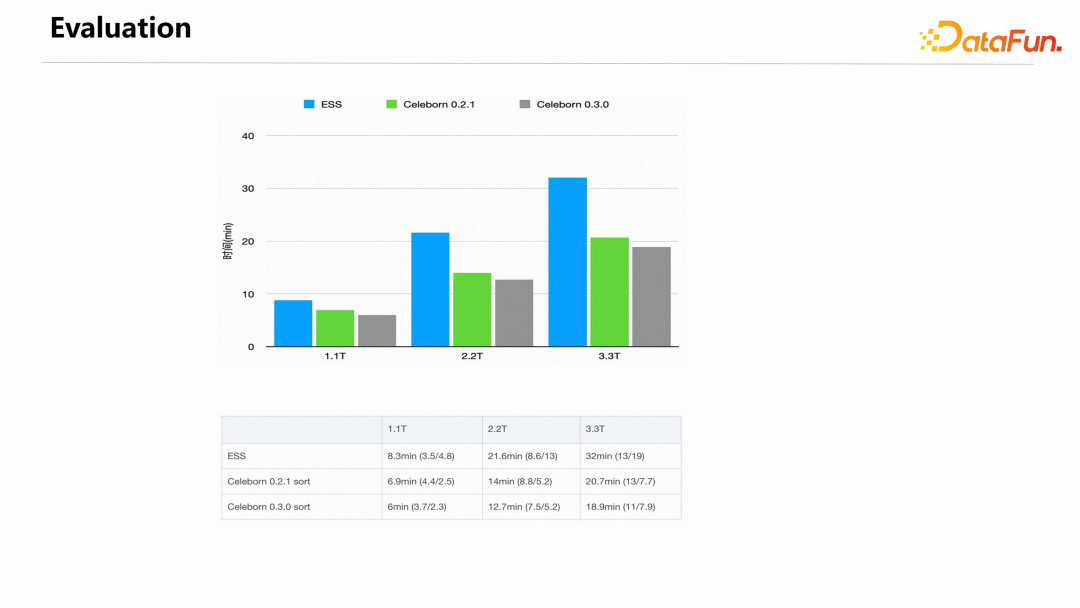
可以看到 Celeborn 在性能上优于 ESS,且规模越大,优势越明显。同时 0.3.0 版本比 0.2.1 版本的性能也有提升。对比 ESS,Celeborn 的优势主要在 shuffle read 阶段,这与前面介绍的稳定性和性能主要在于 shuffle read 时的非常低效的 IO 模式一致。shuffle write 阶段,Celeborn 需要通过一层网络,而 ESS 直接写本地文件。但 Celeborn 最新版本在 shuffle write 过程相对于 ESS 并没有明显的性能降低。1. Celeborn 多元社区
Celeborn 于 2022 年 10 月捐赠给 Apache 软件基金会,随后(2022-10-18)进入孵化器,经过一年的发展,Celeborn 已经变成一个多元的社区。- 7 位 PPMC,除了阿里,还有两位分别来自网易和 Shopee。一位是来自 Shopee的朱夷 @Angerszhuuuu,是第一个大规模使用 Celeborn 的用户,踩了很多坑,对 Celeborn 的发展做出了很多贡献;另一位是来自网易的潘成(Cheng
Pan),也是一位非常重要的 PMC。后面还会有更多 PMC 加入 Celeborn 社区。
- 6 位 Committers,其中三位来自阿里之外。
2. Celeborn 用户场景
目前用户使用 Celeborn 的方式有三种:混部、独立部署、完全存算分离。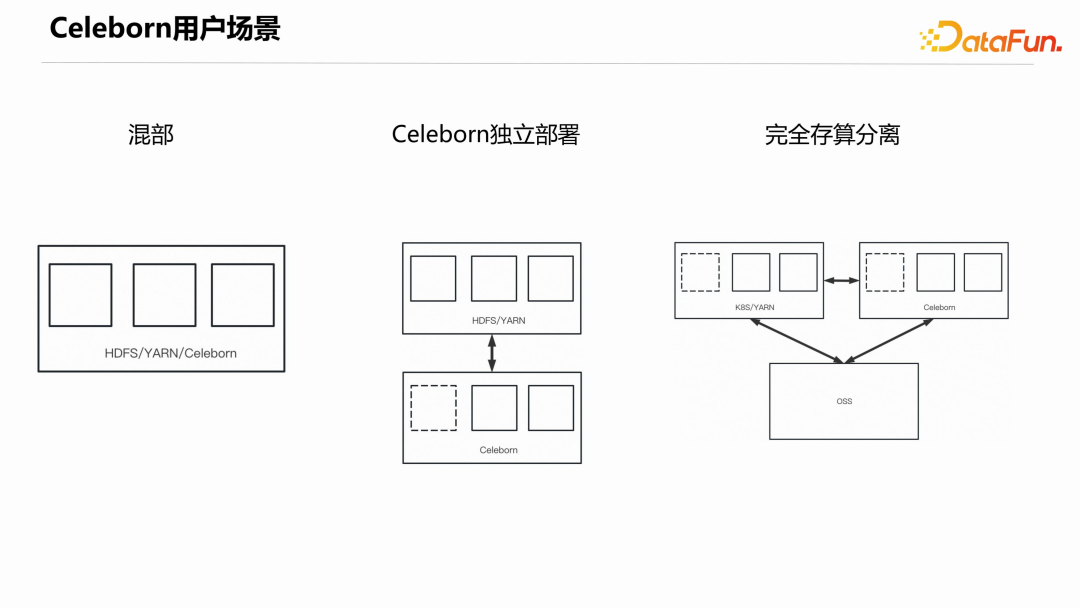
- 混部:把 Celeborn 集群跟现有的 HDFS/YARN 集群部署在一起。这种一般是已经存在 HADOOP 集群,又不想或基于成本考虑不能对集群进行升级改造,则可以把 Celeborn 直接部署在原集群上。
- Celeborn 独立部署:这种方式的好处是可以把 shuffle 相关的 IO 跟 HDFS 的 IO 隔离开来,能够有效提升稳定性。
- 完全存算分离:这种方式是把计算集群、Celeborn 集群、存储集群完全分开,三方集群都可以很方便地进行扩展,能得到很好的性价比。
下图展示了阿里和其他用户的 Celeborn 真实生产场景的情况,一些大用户的 Celeborn 集群每天服务的 shuffle 数据总量达到若干个 PB、数万个作业,单 Shuffle 数据达到数百 T。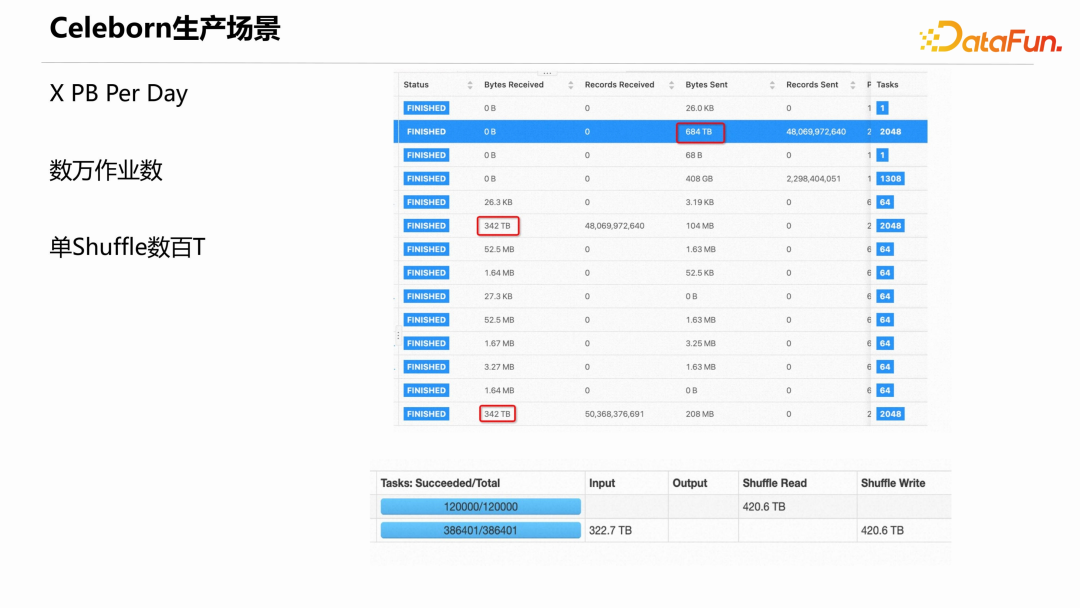
4. Celeborn 用户反馈
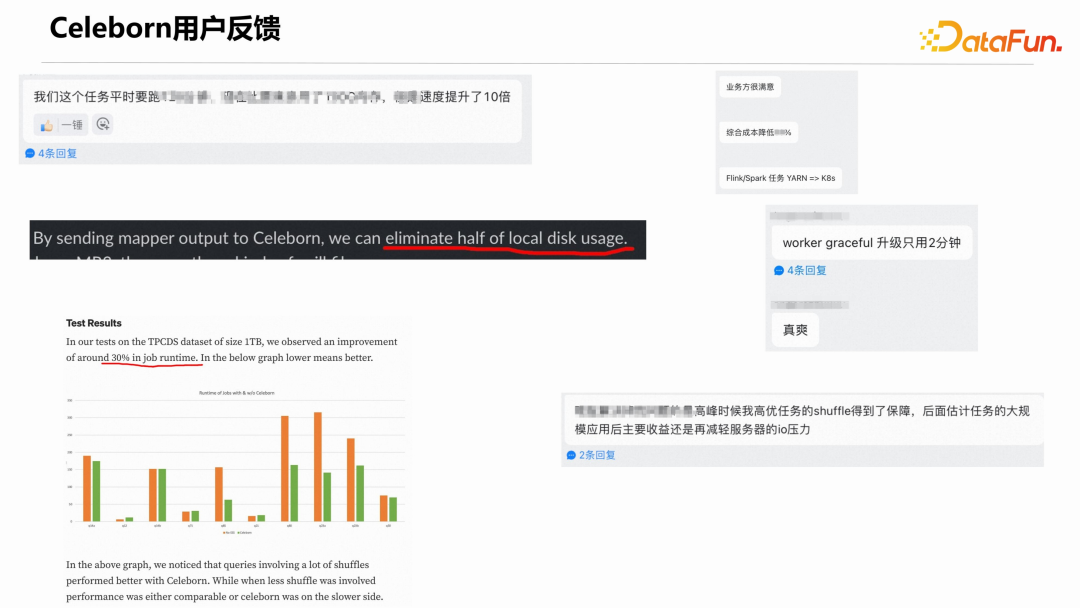
当然也有一些问题反馈,针对问题反馈,社区会积极解决。5. Celeborn 与其他社区
接下来介绍 Celeborn 跟其他社区或项目的结合情况。首先是 Kyuubi 和 Celeborn 的结合使用。Kyuubi 是网易开源的一个很优秀的开源项目。阿里云的 EMR 产品较早的时候就引入了 Kyuubi,用户在创建 EMR 集群时可以直接选择 Kyuubi 组件。
同时,网易通过 Kyuubi + Celeborn 在内部一些生产场景有效提升了性价比。Kyuubi 社区和 Celeborn 社区联系紧密。Kyuubi 的一些 PM 和 Committers 也在为 Celeborn 社区做贡献。双方都希望 Kyuubi 联合 Celeborn 将来能做出更广为大众接受的云原生方案。Spark 社区近年来一直希望能做出一个 Photon 的翻版组件。Databricks 的 Photon 是一个高效的 Native SQL 执行引擎,不开源。Gluten 就是做这样一件事情的产品,它将 Velox、ClickHouse 等 Native 的 SQL 执行引擎通过友好的方式集成到 Spark 里面。Gluten 还提供了高效的 Columnar Shuffle 机制,下图是 Gluten Columnar Shuffle 的示意图。 Gluten 采用高效的设计让 RecordBatch 数据结构有比较高效的 shuffle 性能,但是其在 shuffle 的数据传输上沿用了 Spark External Shuffle Service 的方式,因此也存在前面介绍的各种问题。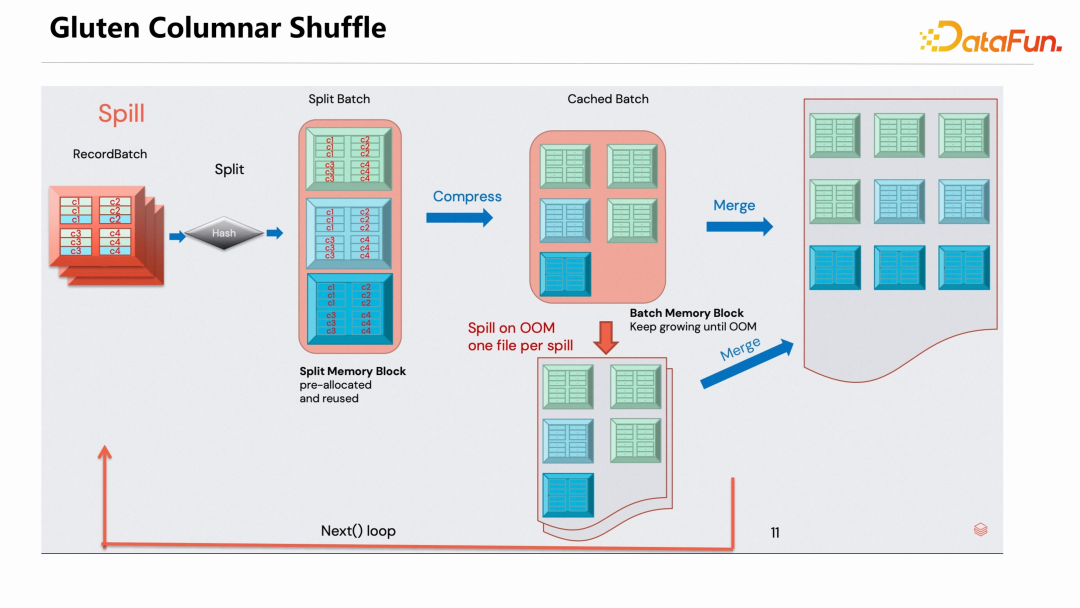
为解决 shuffle 数据上的问题,过去一段时间,Gluten 社区和 Celeborn 社区做了很好的联合,把 Celeborn 集成到了 Gluten 里面。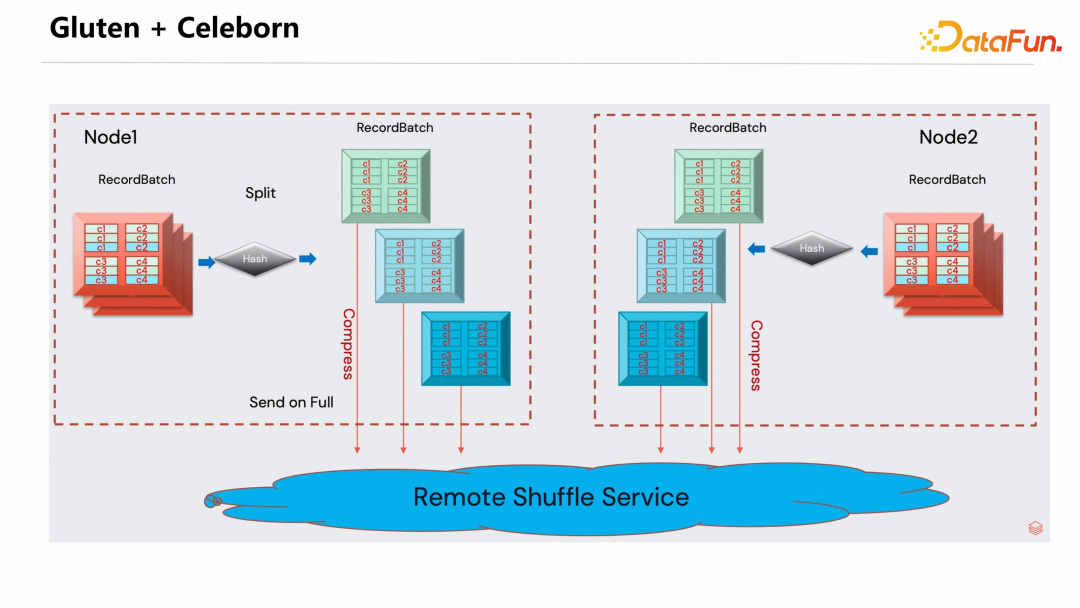
编译 Gluten 时指定 RSS Profile,就会默认使用 Celeborn 的 Client 接管 shuffle 数据。实现方式是在 Gluten 的 Native Partitioner 引入了 Celeborn 的 SDK,在推送和读取 shuffle 数据时,通过 Celeborn SDK 连接 Celeborn Cluster。要说明的一点是,Celeborn 的引入与 Gluten 本身的 Native Partitoner 是正交关系,并不是替代关系。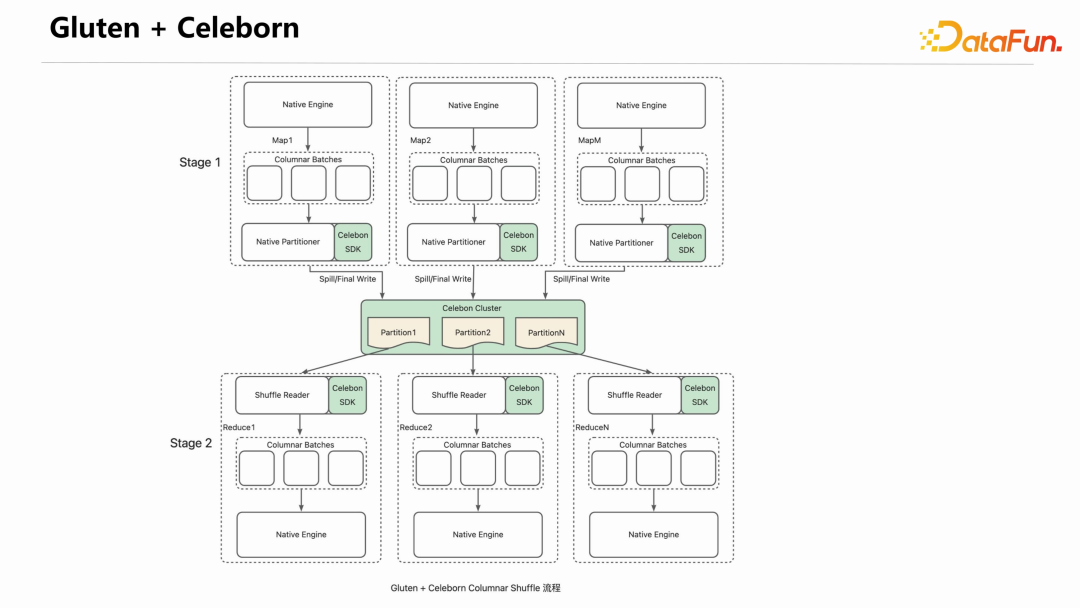
MR3 是一个韩国教授团队通过 API 自发的集成 Celeborn,社区也帮助 MR3 团队解决了很多问题。MR3 + Celeborn 已完成第一个 Release 版本的发布。
Celeborn 未来发展规划
1. 社区
希望有更多 PPMC、Committer 和 Contributor 能够加入社区,大家一起把社区做好,也希望社区更多元化,有更多公司的同事加入社区。大家可以顺手点个 star https://github.com/apache/incubator-celeborn2. 用户
3. Feature 规划
- 对接更多的引擎,比如:Tez/Trino/Ray/...
- 实现认证和安全隔离,Linkedin 团队已在开发中
- 实现 C++ SDK,使得在集成 Ray 和 Native 时更加顺畅
Apache Celeborn (Incubating) 的发起人。
内容中包含的图片若涉及版权问题,请及时与我们联系删除








评论
沙发等你来抢