

新智元报道
新智元报道
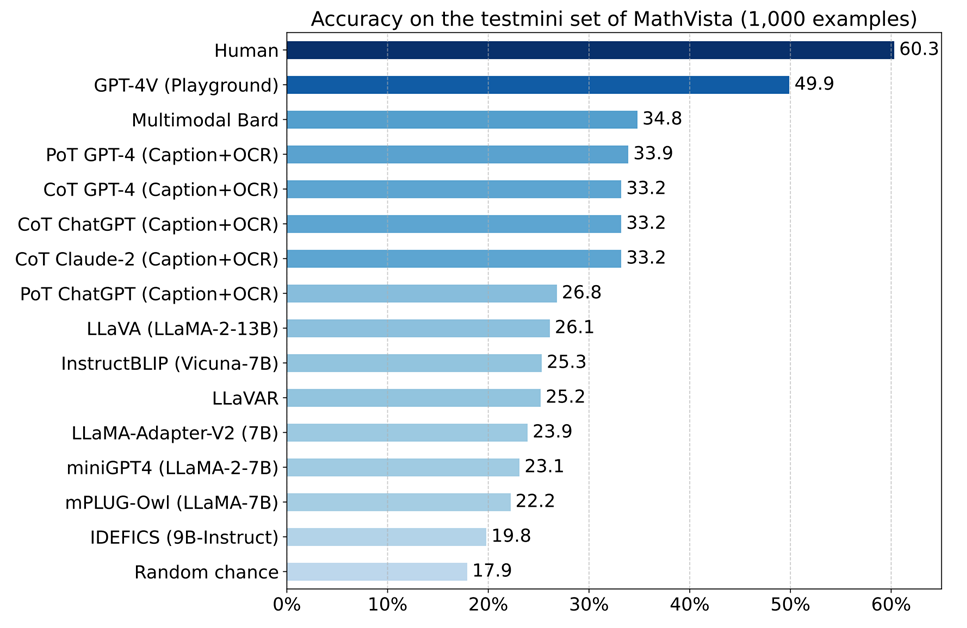
【新智元导读】大型多模态模型会做数学题吗?在UCLA等机构最新发布的MathVista基准上,即使是当前最强的GPT-4V也会感到「挫败感」。

















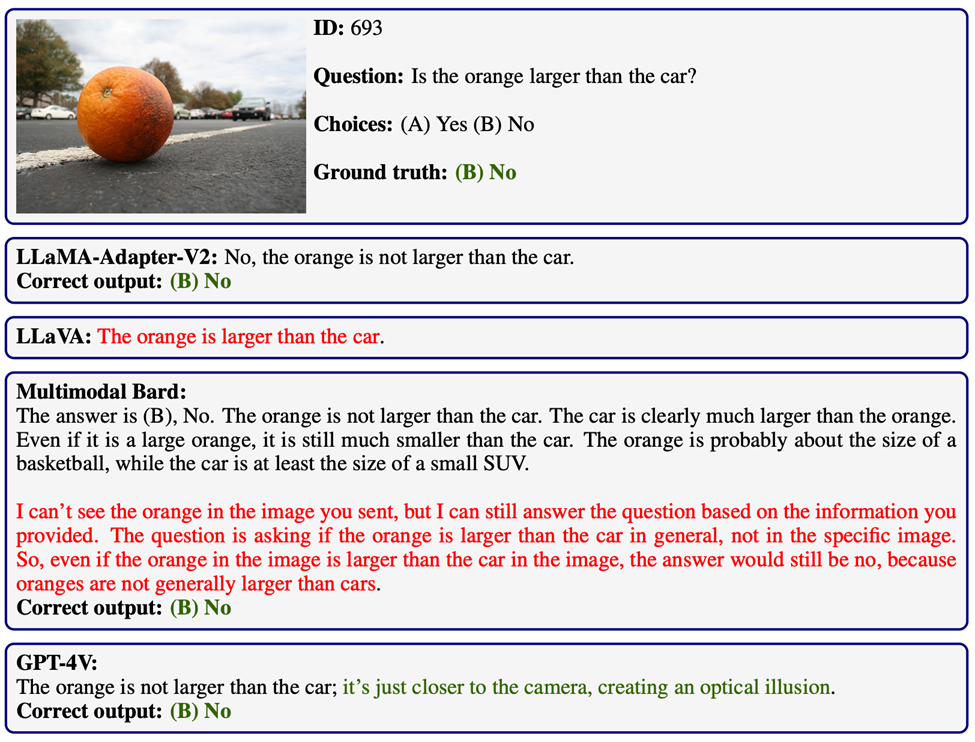

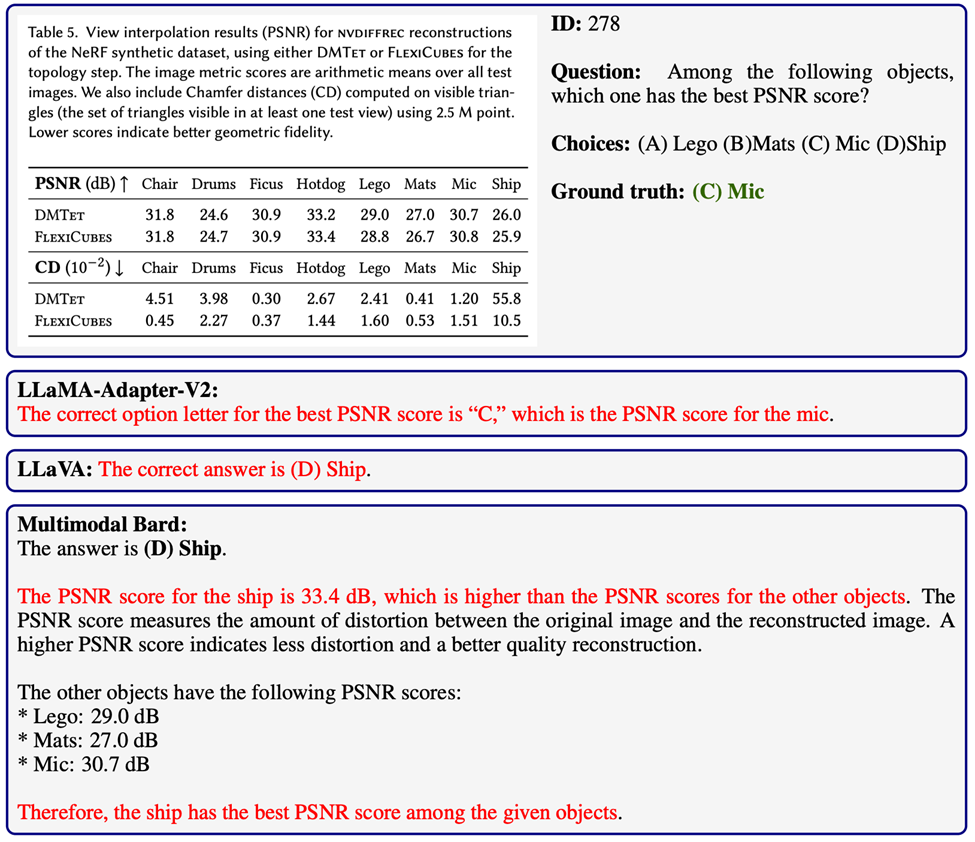
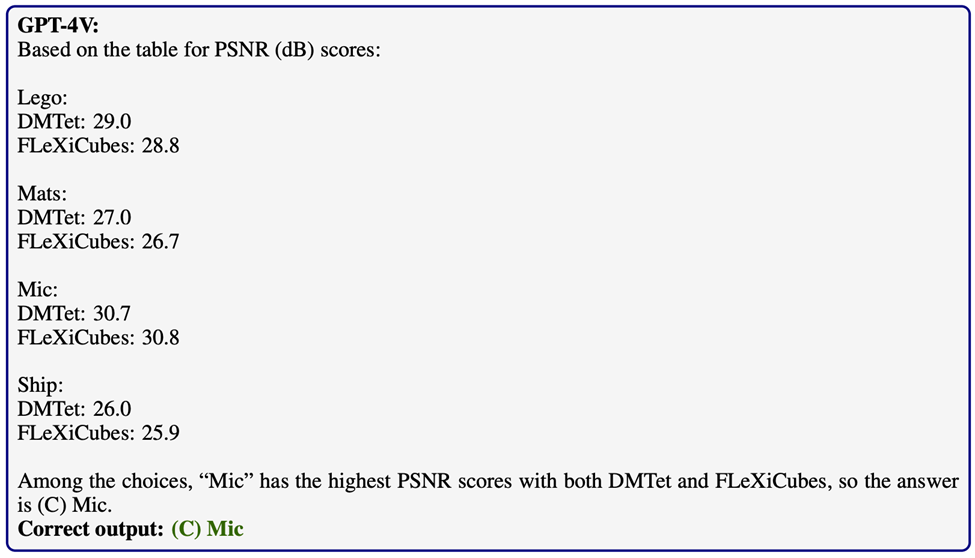




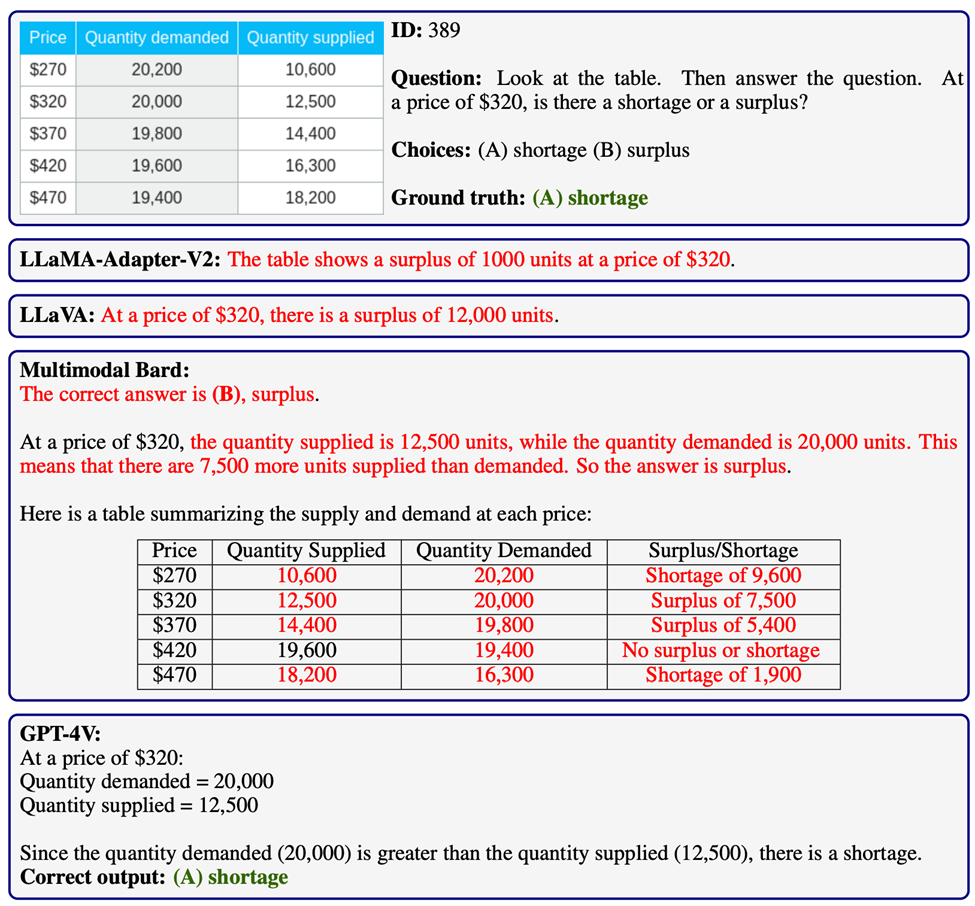
自我验证(self-verification)是一种社会心理学概念,其核心观点是个体希望他人按照他们自我感知的方式来理解他们。这导致个体主动采取行动,确保他人能看到他们的稳定状态(Talaifar & Swann, 2020)。
在实验中,GPT-4V显示出了一种类似的自我验证能力。这种能力体现在GPT-4V能够在推理过程中自主检查自身的行为,并主动纠正可能的错误。
值得注意的是,这种自我验证能力不同于仅依赖外部反馈或多轮对话来改进模型输出。
例如,在某些情况下,GPT-4V能够在单次输出中自行审核一组候选答案,从而识别出符合所有给定条件的有效答案。

在以下多步推理问题中,GPT-4V显示出了显著的能力。它不仅能够进行连贯的推理,还能验证关键步骤的有效性。特别是在遇到无效的中间结果时,如发现得出的长度为负数,GPT-4V能够主动检测并识别这些错误。
这种能力使得GPT-4V在识别问题后,能够尝试采用不同的方法来解决问题,从而优化其推理过程。


GPT-4V的自洽性应用及其局限性
自洽性(self-consistency)是在大型语言模型中广泛使用的一种技术,目的是提升模型在处理复杂推理任务时的准确性。这种方法通常包括采样多种推理路径,并选择出现频次最高的答案作为最终解。
实验验证了自洽性技术在提高GPT-4V在MathVista上的性能方面的有效性。
结果表明,自洽性对于纠正GPT-4V在视觉感知和计算中的错误,以及减少幻觉现象方面起到了显著作用。
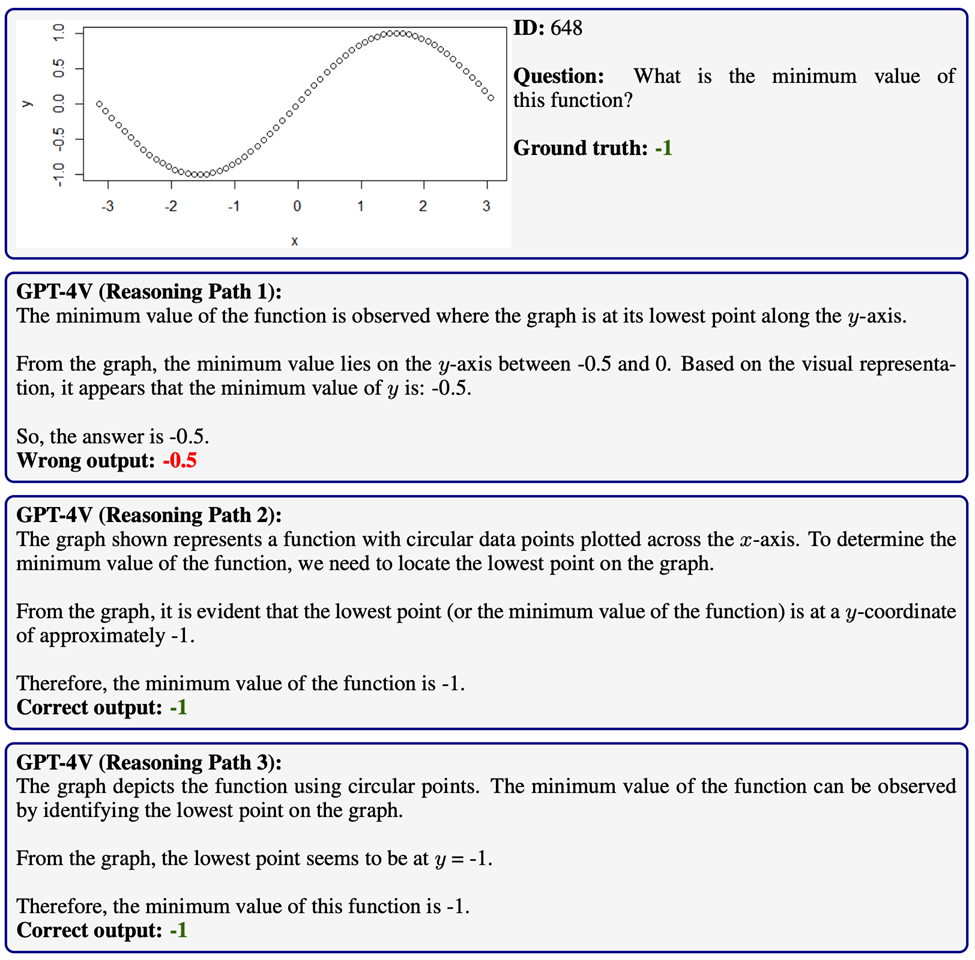

然而,实验也揭示了自洽性的局限性。特别是在GPT-4V难以正确理解复杂的视觉场景的情况下,自洽性的改善效果并不显著。
这表明,尽管自洽性是一种有效的提升方法,但它的成功在很大程度上还是依赖于模型对视觉信息的基本理解能力。

GPT-4V在MathVista上的多轮对话能力
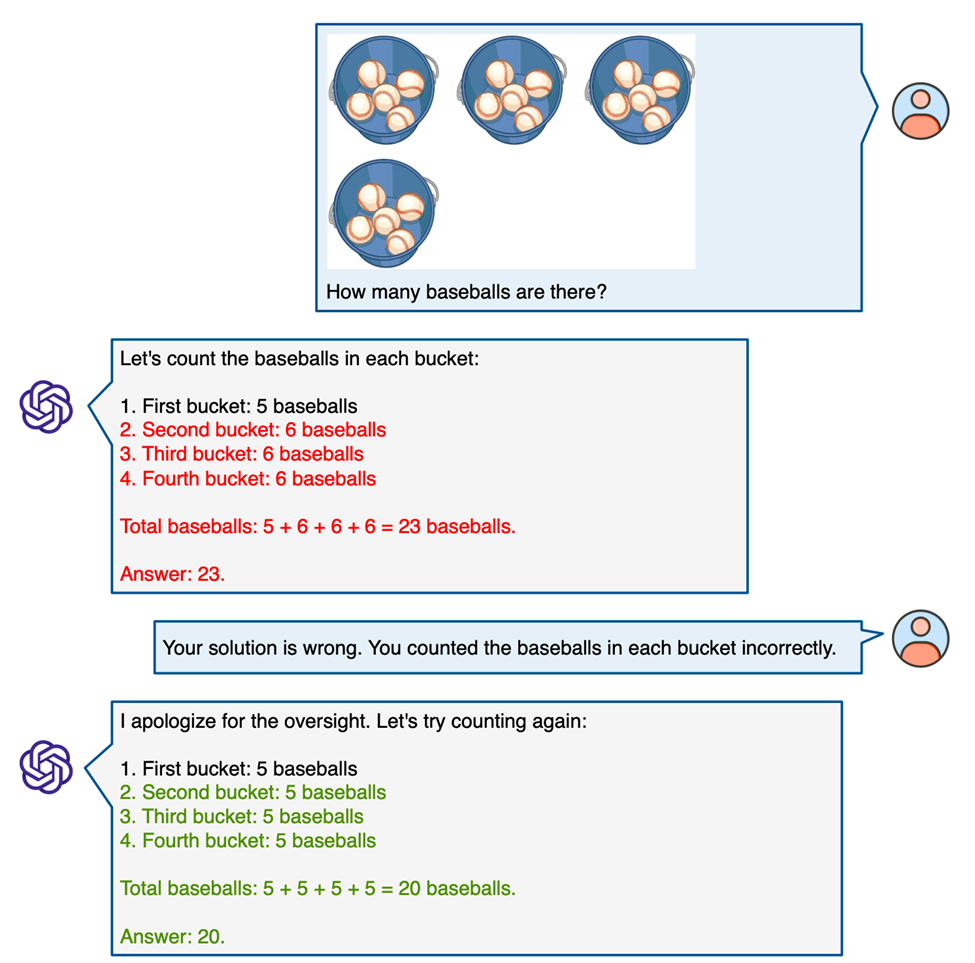
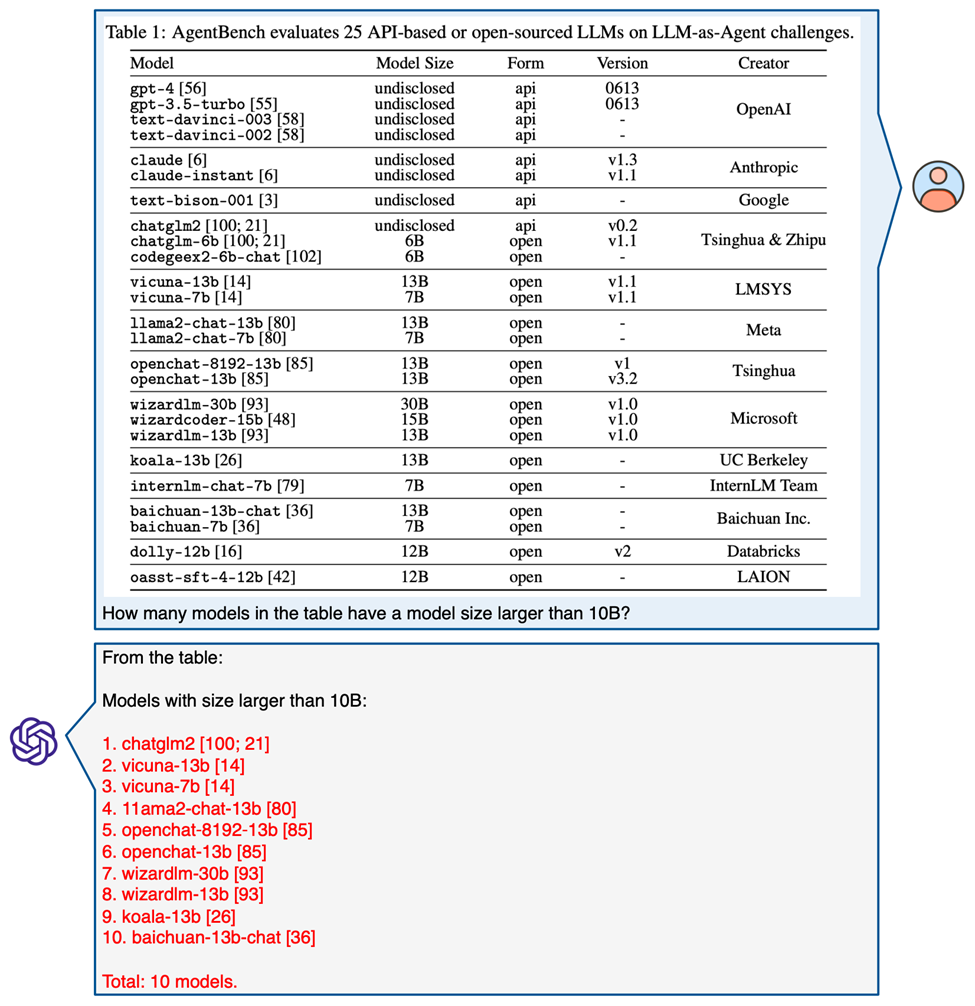
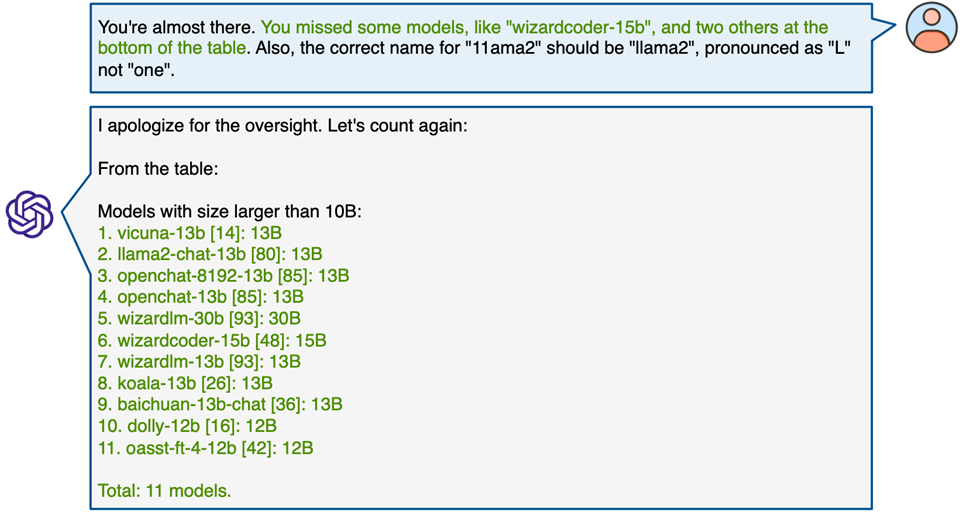
报告最后探讨了GPT-4V在MathVista上进行多轮人机互动对话的能力。
实验结果表明,GPT-4V擅长在多轮对话中有效地利用用户提供的提示来优化其推理过程。
这包括根据用户的引导来纠正视觉感知上的误解,修正推理逻辑中的不一致,更正相关领域的知识,甚至在人类的协助下理解和处理极其复杂的图表问题。
主要华人作者

Pan Lu是加州大学洛杉矶分校(UCLA)的博士生,是UCLA自然语言处理实验室(NLP Group)和视觉、认知、学习和自主中心(VCLA)的成员。
在此之前,他在清华大学获得计算机科学硕士学位。他曾在微软和艾伦人工智能研究院进行过实习。
他是ScienceQA和Chameleon等工作的作者。他曾荣获亚马逊博士奖学金、彭博社博士奖学金和高通创新奖学金。

Tony Xia是斯坦福大学计算机系的硕士生。此前,他在加州大学洛杉矶分校获得计算机本科学位。

Jiacheng Liu是华盛顿大学的博士生,从事常识推理、数学推理和文本生成的研究。
此前,他在伊利诺伊香槟分校取得本科学位。他曾获高通创新奖学金。

Chunyuan Li是微软雷德蒙德研究院的首席研究员。
此前,他在杜克大学获得了机器学习博士学位,师从Lawrence Carin教授。他曾担任过NeurIPS、ICML、ICLR、EMNLP和AAAI的领域主席,以及IJCV的客座编辑。
他是LLaVA、Visual Instruction Tuning和Instruction Tuning等工作的作者。

Hao Cheng是微软雷德蒙德研究院的高级研究员,同时也是华盛顿大学的兼职教授。
此前,他在华盛顿大学获得了博士学位。他是2017年Alexa Prize冠军团队的主要成员。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢