
在大模型的工程实践中,我们会发现它有一些局限性,这对我们的落地产生了很大的挑战。今天我们来探讨一下这些局限性以及相应解决方案。
一、大模型的局限性
幻觉问题:LLM 文本生成的底层原理是基于概率的 token by token 的形式,因此会不可避免地产生“一本正经的胡说八道”的情况。
知识盲点于实时性:大模型通过预训练获得通用语言能力,但不具备专业领域的知识。对某些专业问题无法做出准确回答。有些知识不停的有更新,大模型需要在训练和微调时才能灌入新知识。
记忆力有限:大语言模型参数量虽然很大,但仍然无法记住大量具体的事实知识。容易在需要记忆的任务上表现不佳。
时效性问题:大语言模型的规模越大,大模型训练的成本越高,周期也就越长。那么具有时效性的数据也就无法参与训练,所以也就无法直接回答时效性相关的问题,例如“帮我推荐几部热映的电影?”。
数据安全问题:通用大语言模型没有企业内部数据和用户数据,那么企业想要在保证安全的前提下使用大语言模型,最好的方式就是把数据全部放在本地,企业数据的业务计算全部在本地完成。而在线的大模型仅仅完成一个归纳的功能。
无用户建模:大语言模型没有建模特定用户的能力,对不同用户给出同样的反应和回复,无法进行个性化的对话。
我们今天会基于上面的LLM的局限性,探讨向量化和RAG的一套解决方案的理论供大家学习和参考。好了,我们先来聊聊数据向量化的问题。
二、数据向量化
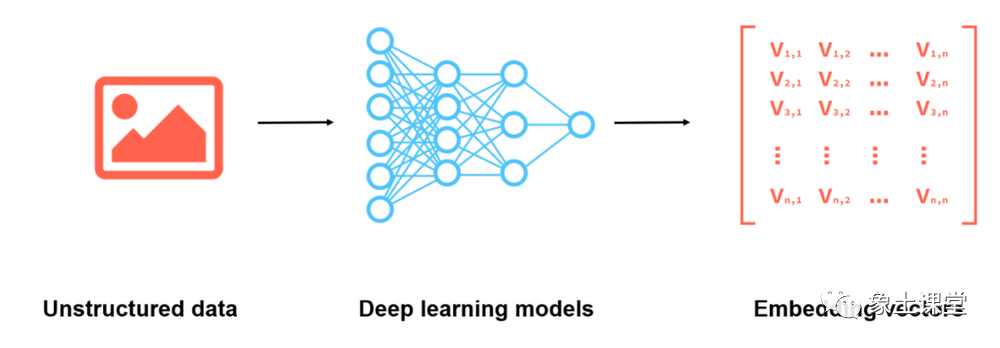
为了储存非结构化数据,我们需要对其进行编码为向量表示,但原始的向量通常高度稀疏,这对计算机的计算和处理不利,Embedding 的主要作用是就将高维的稀疏向量转化为稠密向量以方便对模型进一步处理。具体而言,假设我们将如下字典通过 One-hot 编码。那么我们就可以用矩阵来表示“乐土科技”这个短语:
[000001]
[000010]
[000100]
[001000]
向量化可以基于传统的NLP的方法有:Word2vec:GloVe(Global Vectors for Word Representation)、FastText。但今天我们来介绍一种新的方式通过大模型(Embedding model)来完成数据向量化。
三、RAG(检索增强生成)技术
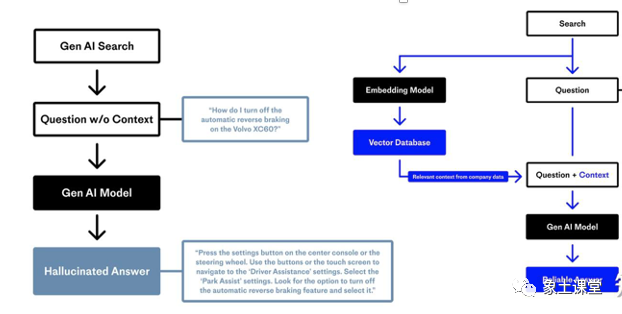
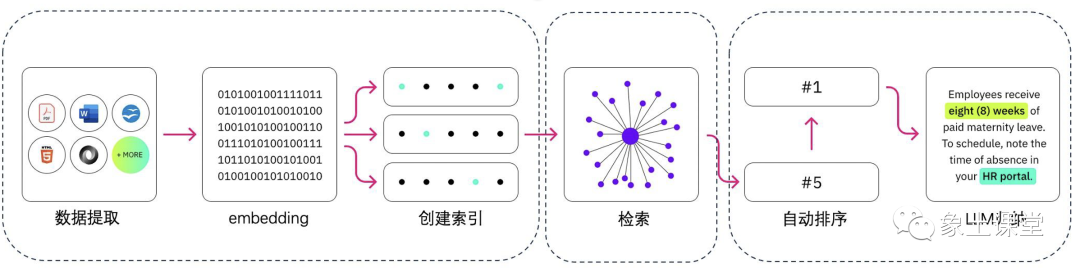
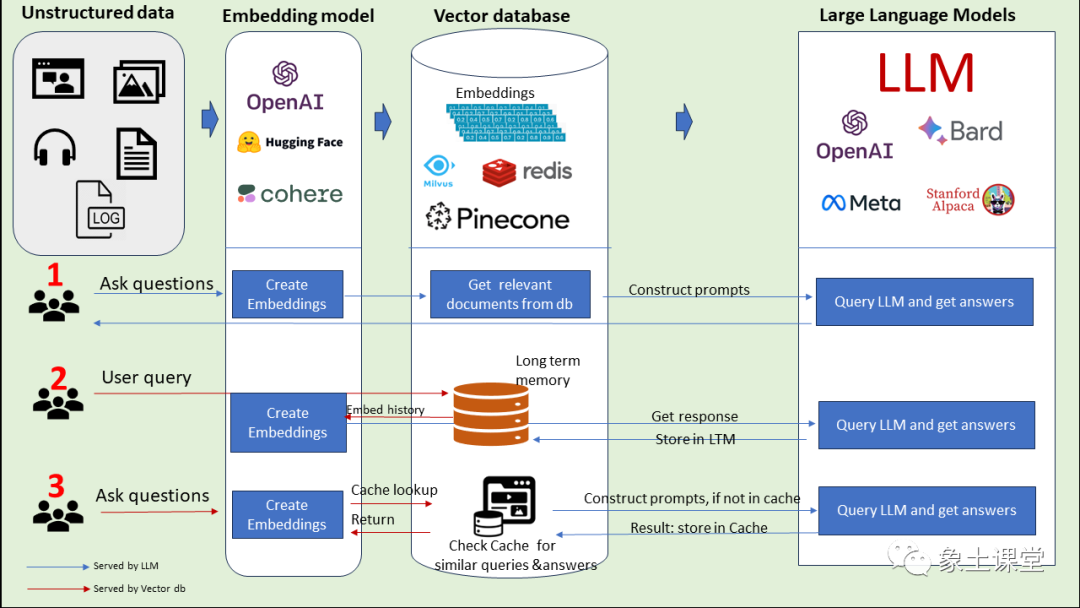
模式一:非结构化数据通过Embedding Model把非结构化数据进行embedding存到向量数据库中,然后形成Construct Prompts给到LLM。LLM返回结果给到用户。
模式二:用户提出问题,下一步把问题通过Embedding Model向量化,然后保存到长时记忆数据库(向量数据库)中,然后调用LLM完成问题的回答,接下来将大模型的回答存到长时记忆数据库中,最后返回给用户。
模式三:用户问问题,下一步把问题通过Embedding Model向量化,然后从Cache中(向量数据库)查询类似的问题和答案,返回给用户。如果没有命中,则去和LLM交互。然后把LLM的回答存到Cache中,最后把回答返回给用户。
四、RAG-优势、劣势和替代方案
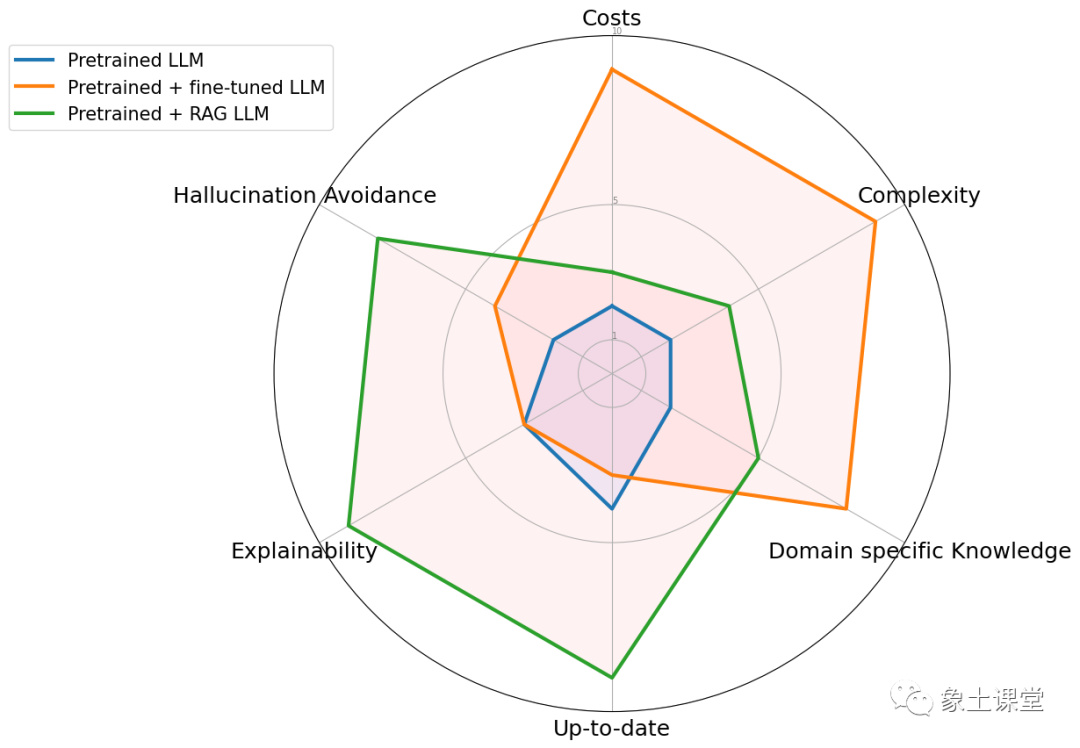
与预训练或微调基础模型等传统方法相比,RAG 提供了一种经济高效的替代方法。RAG 从根本上增强了大语言模型在响应特定提示时直接访问特定数据的能力。为了说明 RAG 与其他方法的区别,请看下图。雷达图具体比较了三种不同的方法:预训练大语言模型、预训练 + 微调 LLM 、预训练 + RAG LLM。
《向量化、RAG、Agent技术课程》
超越大语言模型的局限,开发智能外部大脑
课程亮点
l学习如何让大模型拥有专业知识和记忆能力;
l学习通过向量化连接外部知识;
l掌握检索增强生成RAG技术;
l掌握langchain、MemGPT、Autogen工具的使用方法;
l掌握Agent技术;
l学习构建prompt、设计复杂流程、链接矢量数据库;
课程形式
录播课学习,共计5.3课时。
课程目录
第1节 大模型的局限性
第2节 数据的处理和利用
第3节 向量化基本概念
第4节 文本向量化
第5节 使用语言模型向量化
第6节 RAG检索增强生成
第7节 RAG工作原理
第8节 RAG优势劣势和替代方案
第9节 LangChain-架构
第10节 LangChain-核心组件
第11节 langchain[加载器、文档、文本分割、向量化数据库]
第12节 自定义prompt
第13节 langchain使用本地向量化模型
第14节 LangChain-百川大模型-本地向量化
第15节 langchain-agent
第16节 LangChain-实现SalesGPT架构
第17节 LangChain-实现SalesGPT代码讲解
第18节 LangChain-SalesGPT示例运行讲解
第19节 Autogen是什么
第20节 Autogen运行讲解
第21节 MemGPT
第22节 Autogen+MemGPT介绍
第23节 Autogen+MemGPT运行讲解
第24节 RAG的挑战
第25节 多向量搜索器
第26节 向量化模型的再训练
第27节 Self-RAG介绍
第28节 Self-RAG代码运行讲解
感兴趣的朋友请加老师微信咨询。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢