

导读:腾讯新闻20周年特别策划《20年20人20问》,携手全球顶级企业家、思想家、教授、学者一起热问向未来。创新工场董事长、零一万物CEO李开复博士提问:“相比于GPT-4 Turbo、LLaMa 2-70B、Falcon-180B等国外大模型,国产大模型的突围之路在哪里?”本文是鲁为民博士受邀对这个问题的回答 (请查看原文,略有调整)。

OpenAI最近在其DevDay开发者大会上发布的 GPT-4 Turbo 大模型不仅仅是 GPT-4 模型本身的升级,包括训练数据的截止时间更新到2023年4月,最大Context 窗口大小从32K增加到128K,多模态的支持,以及模型的优化让推理成本降低等等;更重要的是其生态系统的建设,特别是通过多种功能的选项,包括GPTs 和Assistants APIs,帮助开发人员在其自己的应用程序中有效地构建类似智能体 (Agents)的体验。
对于AI 的从业者和厂商来说,这一方面是挑战,因为 OpenAI 显著的扩展了其产品和服务的内容和范围,又走到了市场的前面。但另一方面,这也是机会,因为OpenAI 模型升级和新产品发布给人以提示,大家可以结合自身的场景和优势来重新思考并优化各自的大模型AI的技术发展路径。
大模型应用产品和服务的提供形式主要包括模型公有云服务(MaaS)以及私有部署的专有大模型服务,而OpenAI 主要是提供前者。因为我们致力于提供AI平台系统帮助企业级用户增强其 AI 的工程能力并加速AI(特别是大模型) 应用落地进程,我可能更关心大模型在B端市场的应用机会;两种服务形式对B-端用户都有价值。在GPT-4 Turbo 受到广泛关注的情形下,OpenAI 之外包括国产大模型从产品和技术上的突围之路可能在开源大模型应用和智能体 (Agents)。
开源大模型应用
基于Transformer的大模型 AI 快速发展的主要原因一方面是因为大模型从性能上到能力上都具有明显的规模优势,另一方面这类大模型可以灵活处理语言文本之外的图像、视频、和语音等多模态数据。所以我们在讨论中不区分大语言模型 (LLMs) 和 基于Transformer的大模型。

大模型的突围 GPT-4 Turbo 之路之一在于专有大模型的应用。通过对开源基础大模型的场景适配可以高效地打造垂直应用领域的专有模型;像 LLaMA、GLM、BaiChuan 等国内外开源大模型表现不俗。基于开源模型的专有模型和GPT-4这样级别的闭源模型服务在应用当中各有优势:
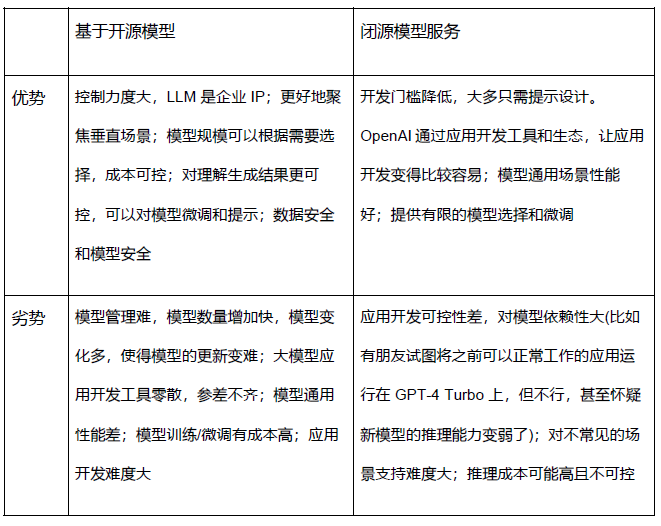
企业AI 是各种大模型最重要的应用场景。像OpenAI 的 GPT-4 ,Google 的Bard和 Anthropic的 Claude 等 MaaS 服务主要适合消费者、开发者和小微B-端用户。而这些服务不能完全满足中大企业和组织等B-端用户的需求,而基于开源大模型的专有模型更适合于中大企业的一些关键业务场景。开源大模型是企业应用的刚需。AI 专有模型正成为企业关键知识产权(IP);专有模型可以帮助企业提高竞争力;也使得企业自主可控安全。基于开源基础大模型的专有模型已成为快速增长的 AI 应用生态的核心力量:
-
企业/垂直大模型应用更多利用的是大模型的语言理解能力,而不是通用 AI 能力;这类应用专注于单一任务场景,对应于中小开源大模型 (数亿到数百亿参数);
-
这类模型是开源 AI 模型生态的最重要的组成部分,也是大多数 AI 从业者关注的领域;而后者是庞大的AI 社区主要组成;
-
谷歌:“我们没有护城河,OpenAI 也没有,开源模型终将赢得这场军备竞赛。”
基于开源模型的专有模型将在企业应用中扮演重要的角色,MaaS也可以成为企业应用的主要补充。可以预期今后的企业应用场景包括混合利用多个专有模型和超大模型MaaS服务;而在这些应用场景当中,智能体(Agents) 将起到核心作用。

(Agents)智能体
Agents被设计成为一种自主完成预设目标的代理或实体以协助人类完成各种各样繁琐的任务。智能体是人工智能应用的一种体现形式。大型语言模型(LLMs)因为其出色的自然语言理解、处理和生成能力,也在很多推理、规划和决策任务上表现出色,展示了许多有前途的方向;特别是LLMs作为智能体的“大脑”是一个很自然的选项。但包括GPT-4 Turbo 在内的大模型仍面临许多挑战,其中比较引人关注的是幻觉 (Hallucination) 问题。LLMs的幻觉体现为“一本正经胡说八道”,自信错误地输出虚假信息;幻觉影响到LLMs输出结果的精确度和实事性,使得对LLMs的广泛应用,特别是B-端应用,构成了严重的挑战。LLMs的幻觉行为很大程度上是由于语言模型本身的特点决定,包括下面的一些因素:
-
语言模型作为概率模型,预测下一个Token是由损失函数导出的概率分布来决定,存在一定的近似和不确定性,因此答案有可能产生误差甚至错误。所以LLMs在数学,推理和编程这类对精确度和确定性有严格要求的任务更有可能出现幻觉问题;比如即使使用GPT-4 加上思维树 (ToT) 都可能不能求解 Game of 24问题。
-
LLMs只能给用户提供有限长度的 Context 窗口,让LLMs不具备基本的长期记忆能力,使得存在于用户历史中的知识和实事有可能被LLMs丢失和忽略;特别是当Agents的决策的时间跨度变长时,其输出结果会大概率产生事实性错误。
但单纯地增加Context 窗口的效果还有待确认。虽然 GPT-4 Turbo 将 Context 的窗口大小提高到原来的4倍,即达到128K, 但最新的某个测试发现这个幻觉问题没有因此完全解决,特别是当Context的Tokens数超过73K后,模型的召回性能就开始变坏。
-
大模型在训练时压缩了大量世界的语义信息,让模型有能力在接触环境时真正理解环境中每一个事物是什么、发挥什么作用以及怎么利用,进而在推理时试图映射到用户的请求。如果答案不在训练数据集内或者没被语言模型捕捉到,语言模型也会猜测一个错误的答案,并产生错误的规划和执行策略,从而可能会导致幻觉。
-
最近普林斯顿大学的一个对GPT-4测试研究表明,幻觉现象更容易产生在LLMs所考虑问题的长尾区域,不论是从事的任务,数据输入,还是目标输出。而这些问题区域往往是LLMs有效实现规划、推理和执行难以避免的。
此外,LLMs还只是被动的静态模型,应用中往往不能很好的将文本与现实世界的实体和概念相关联,即所谓的grounding,也没有足够的记忆,也没有可靠的推理、学习、规划和执行能力; 而保障这些能力是复杂企业应用有效实施必备的条件,所以大模型往往无法直接使用在很多应用场景。
Agents机制是弥补这个问题的可能选项。智能体具有主动性,尤其在与环境的交互、主动规划和执行各种任务方面。基于LLMs的Agents可以通过挖掘LLMs的潜在优势而进一步增强其推理决策能力;特别是使用人工、环境或模型来提供反馈,使得Agents可以具备更深思熟虑和自适应的问题解决机制,超越了LLMs现有技术的局限。一方面Agents能为LLMs核心提供强大的行动能力,真正释放LLMs潜能;而另一方面LLMs 能提供Agents所需要的强大引擎。可以说LLMs 和Agents可以相互成就。
基于 LLM的Agents的应用有很大的想象空间。A16Z在他们的立场性博文 “Emerging Architectures for LLM Applications” 宣称基于LLMs的Agents有望成为 LLM 应用程序架构的核心... 甚至可以接管整个技术栈!OpenAI 显然对基于LLM的Agents也特别重视。在这次产品发布会上,OpenAI一方面帮助用户在GPT-4 Turbo上构建、托管和运行一类定制的Agents,即 GPTs;OpenAI也提供 GPT Builder 让用户通过自然语言的指令来完成 GPTs 的打造;另一方面通过 Assistants APIs ,OpenAI协助开发者围绕GPT-4 Turbo打造相对复杂的Agents;后者通过特定的指令,利用额外的知识,并可以调用模型和工具来执行任务。特别是Assistants API 提供了 Threading (多线程)、Code Interpreter (代码解释器)、 Retrieval (检索) 以及 FunctionCalling (函数调用)等相应的功能,以帮助开发者处理以前必须自己完成的大部分繁重工作,使开发者能够更容易地在GPT-4 Turbo上构建高质量的AI 应用程序。
虽然OpenAI通过这些关于 GPT-4 的升级迈出了基于LLM-Agents 打造应用构想的第一步,但因为上面的各种原因,使得这样的Agents离可靠地支持企业级应用场景还有很大的距离。主要原因包括:
-
GPT-4Turbo这样的通用大模型在其训练数据集中可能没有包含企业的专有数据,因此模型缺乏企业特殊的场景支持的知识和流程,容易在应用中产生精确度和实事性的偏差;
-
利用GPT-4 Turbo 这样的(黑盒子)大模型服务,开发者还需要依赖其提供应用逻辑,包括推理和规划,来设计Agents,缺乏对应用开发和生成结果的控制;
-
GPT Builder和Assistants APIs等这类围绕GPT-4 Turbo LLMs的Agents框架,难以应对复杂的业务逻辑所需要的灵活性、可扩展性和安全性。
所以有必要打造可以更好地支持动态多轮对话更加灵活、可控、可扩展和安全的 Agents 架构,以有效地支持复杂的特别是企业级用户的业务场景和流程。该架构需要使得Agents一方面可以充分利用LLM的包括In-context Prompt Learning (上下文提示学习)在内的学习模式,使其在各个解决问题的环节中呈现必要的便捷性和有效性,另一方面将反馈闭环机有效地制植入到Agents架构核心以提供Agents所需要的持续学习和自我改进的能力。
由于LLMs的能力边界还在快速拓展,LLMs本身和LLM-Agents还在演进中,其有效地应用方式和产品形态仍有待不断地探索。
权益福利:
1、AI 行业、生态和政策等前沿资讯解析;
2、最新 AI 技术包括大模型的技术前沿、工程实践和应用落地交流(社群邀请人数已达上限,可先加小编微信:15937102830)

源于硅谷、扎根中国,上海殷泊信息科技有限公司 (MoPaaS) 是中国领先的人工智能(AI)平台和服务提供商,为用户的数字转型、智能升级和融合创新直接赋能。针对中国AI应用和工程市场的需求,基于自主的智能云平台专利技术,MoPaaS 在业界率先推出新一代开放的AI平台为加速客户AI技术创新和应用落地提供高效的算力优化和规模化AI模型开发、部署和运维 (ModelOps) 能力和服务;特别是针对企业应用场景,提供包括大模型迁移适配、提示工程以及部署推理的端到端 LLMOps方案。MoPaaS AI平台已经服务在工业制造、能源交通、互联网、医疗卫生、金融技术、教学科研、政府等行业超过300家国内外满意的客户的AI技术研发、人才培养和应用落地工程需求。MoPaaS致力打造全方位开放的AI技术和应用生态。MoPaaS 被Forrester评为中国企业级云平台市场的卓越表现者 (Strong Performer)。
END
▼ 往期精选 ▼
1、五个早期的例子告诉你,可以用OpenAI的GPT Builder做什么?
2、大模型时代的智能体 (III):构建基于LLM 的智能体
▼点击下方“阅读原文”!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢