


作者:Juncheng Li
类型:2023年博士论文
学校:Carnegie Mellon University(美国卡内基梅隆大学)
下载链接:
链接: https://pan.baidu.com/s/1dMXmHdAxrpwhuicITwDkpA?pwd=52ia
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
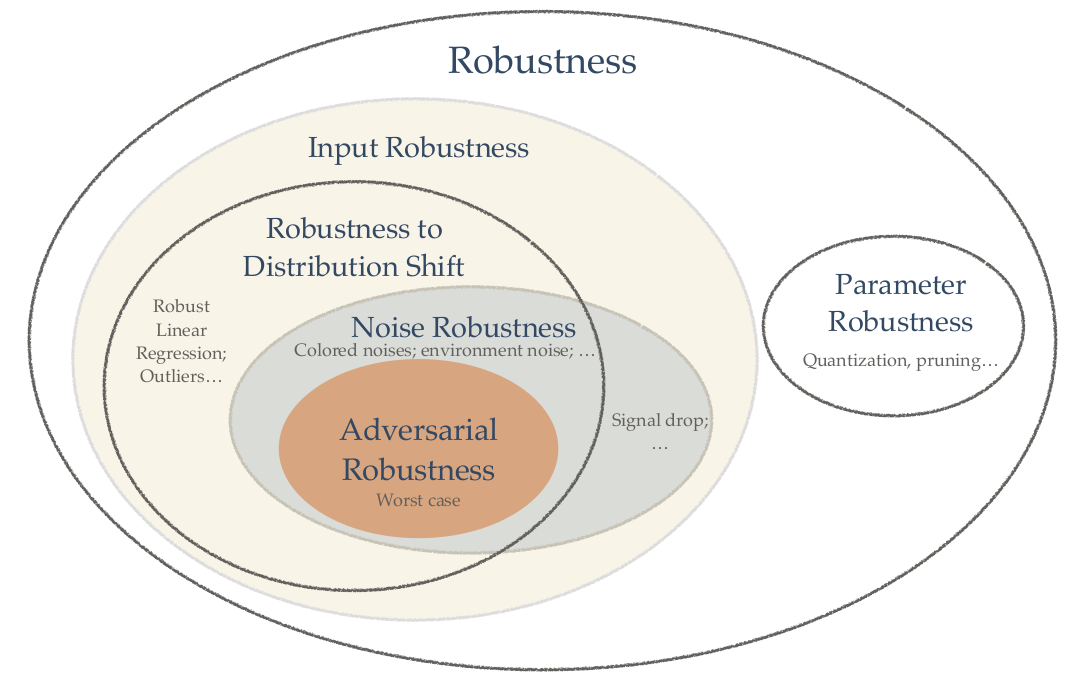 鲁棒性类别
鲁棒性类别
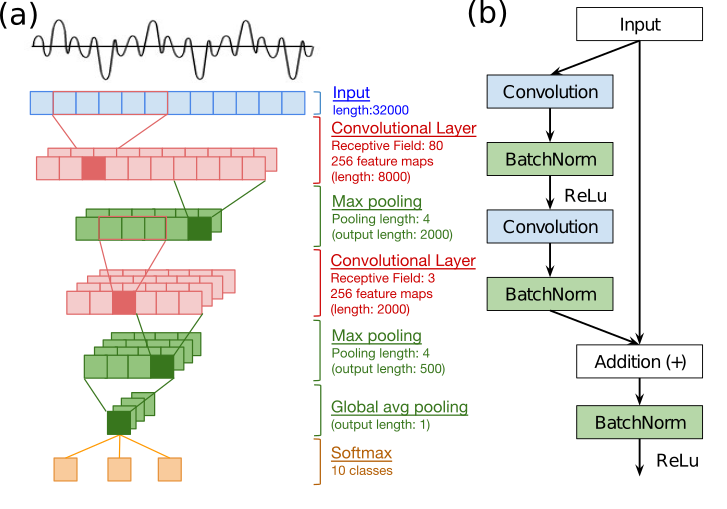 (a) M3的模型架构。(b) M34-res 中使用的残差块(Res-Block)。
(a) M3的模型架构。(b) M34-res 中使用的残差块(Res-Block)。
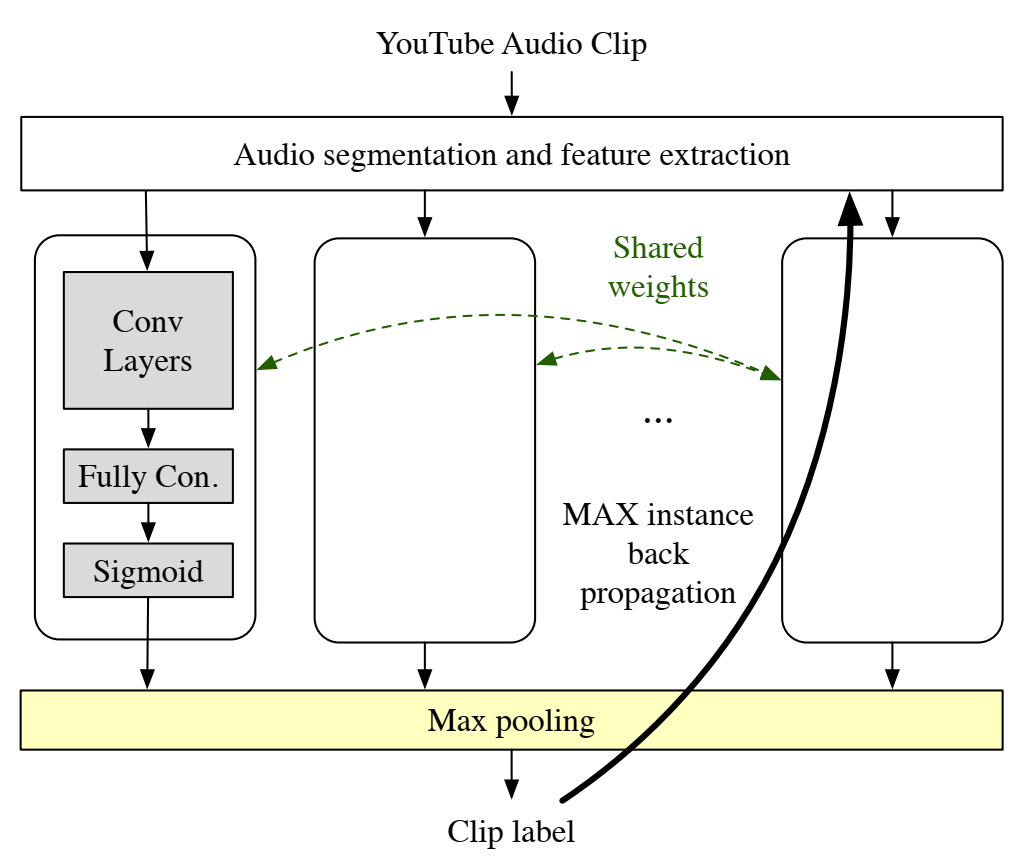 使用 CNN 的 MIL 架构。在最大池化情况下,反向传播是沿着每个类的 MAX 实例执行的。对于其他池化函数将遍历所有块。
使用 CNN 的 MIL 架构。在最大池化情况下,反向传播是沿着每个类的 MAX 实例执行的。对于其他池化函数将遍历所有块。
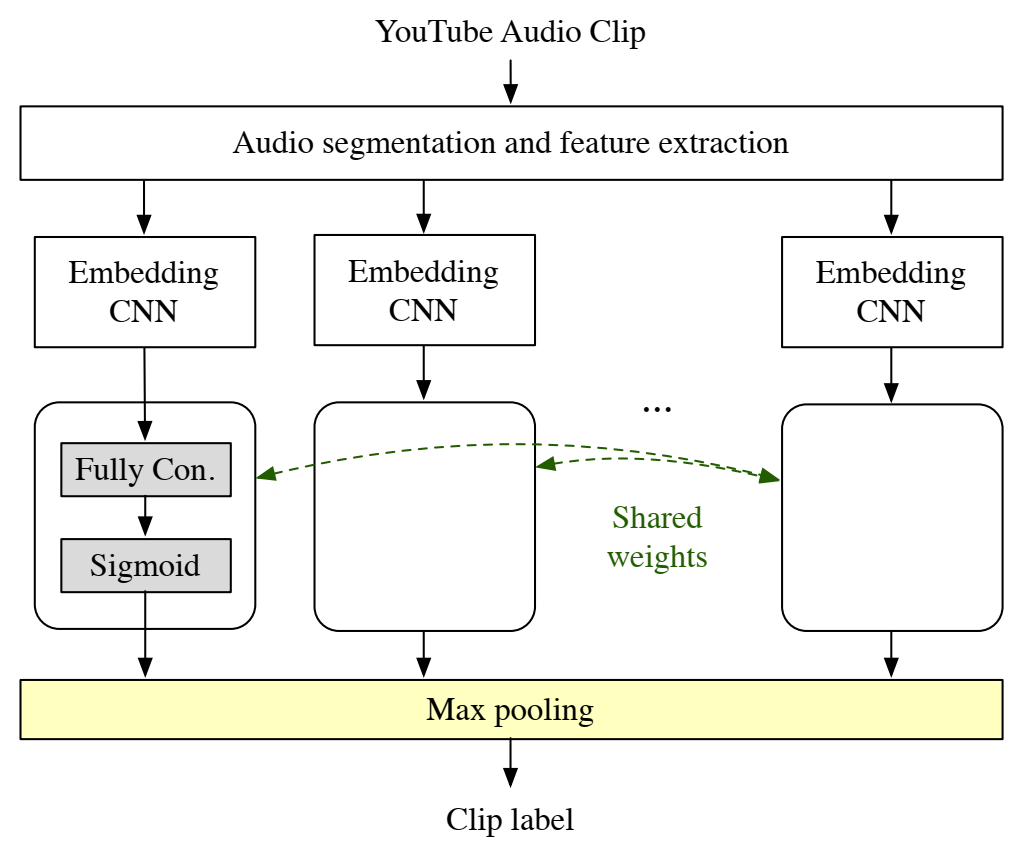 使用音频嵌入的 MIL 架构。
使用音频嵌入的 MIL 架构。
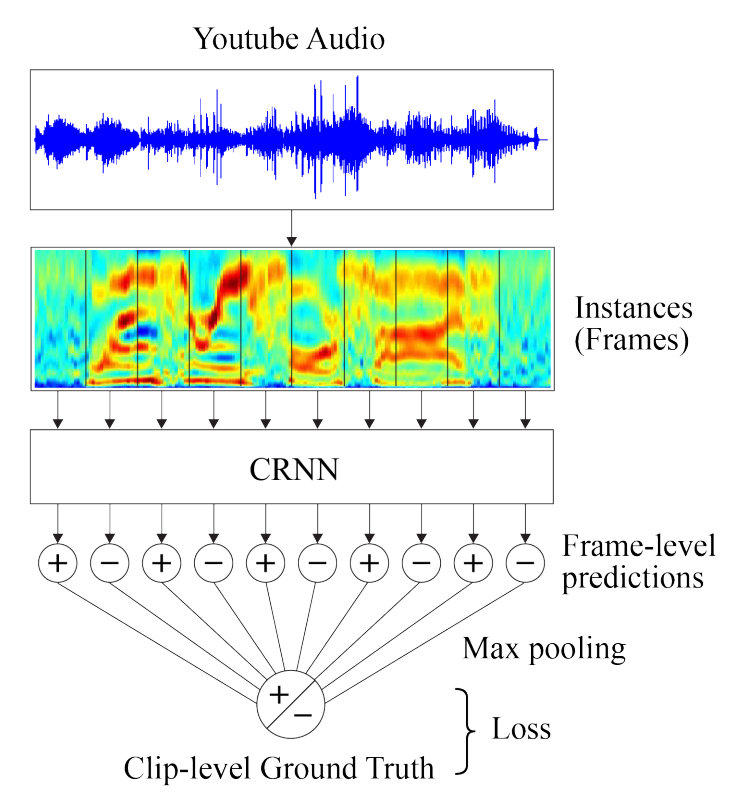 这里注意,每一帧只有正向和负向预测。
这里注意,每一帧只有正向和负向预测。
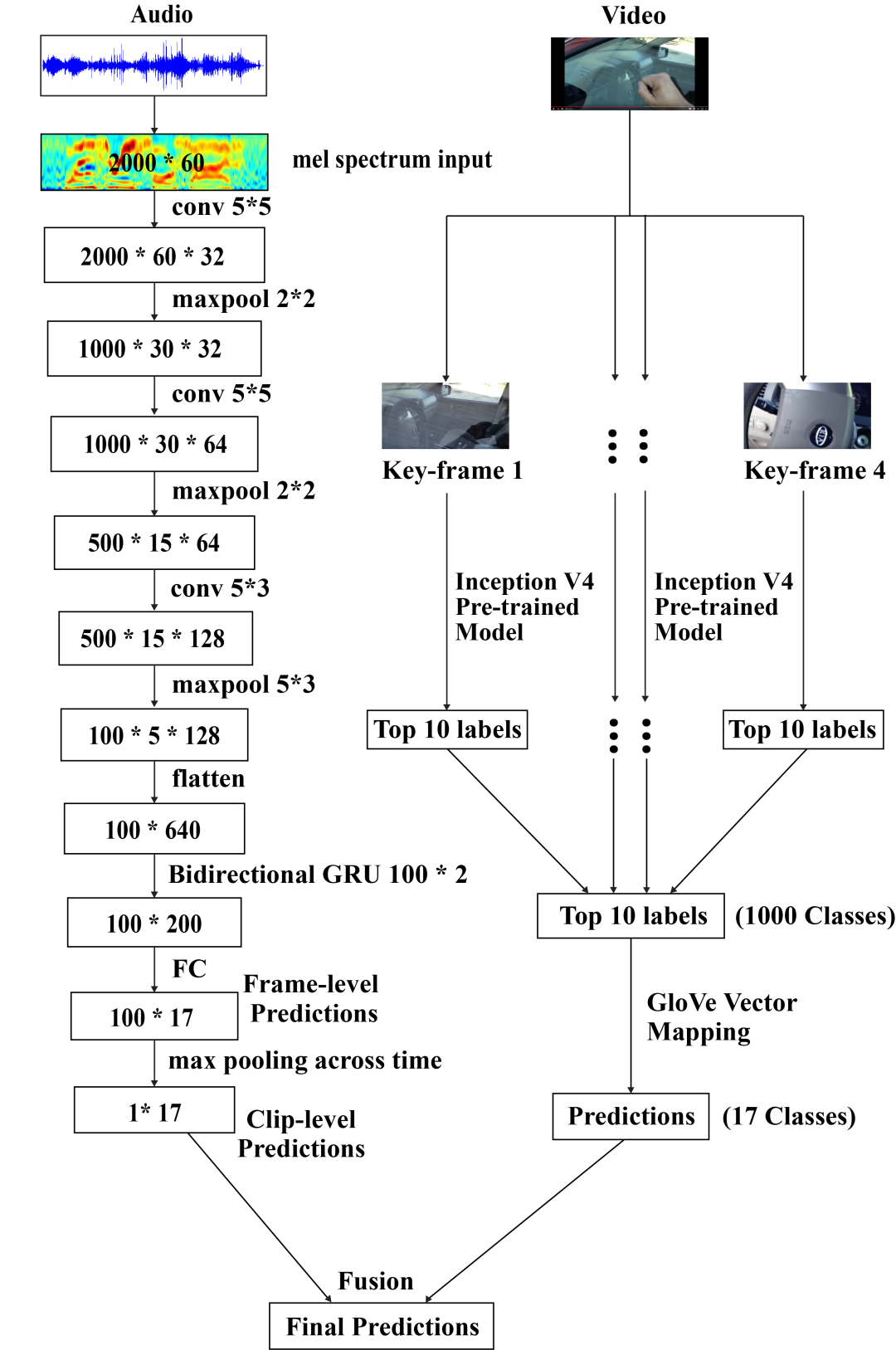 我们提出的多模型框架的框图。这里请注意,音频和视频瓶颈特征都包含动态。
我们提出的多模型框架的框图。这里请注意,音频和视频瓶颈特征都包含动态。
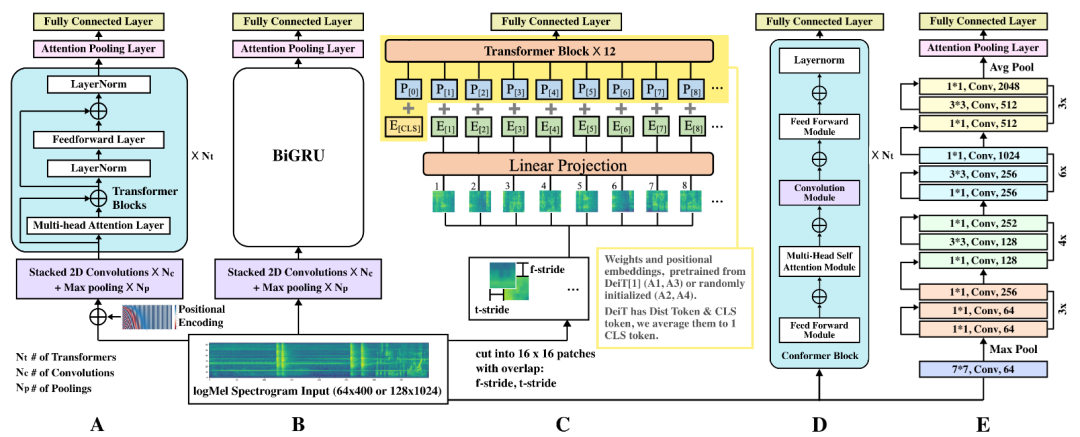 (A): CNN+Transformer (B): TALNet(CRNN) (C): AST/DeiT(ViT) (D): Conformer (E): ResNet
(A): CNN+Transformer (B): TALNet(CRNN) (C): AST/DeiT(ViT) (D): Conformer (E): ResNet
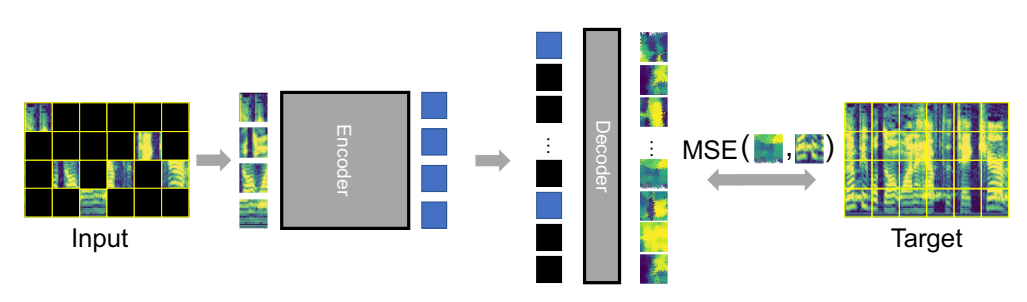 录音首先被转换成频谱图并分割成补丁。我们嵌入补丁并屏蔽掉很大的子集(80%)。然后编码器对可见的(20%)补丁嵌入进行操作。最后,解码器处理顺序恢复的嵌入和掩码标记以重建输入。Audio-MAE 正在最小化重建和输入频谱图的屏蔽部分的均方误差 (MSE)。
录音首先被转换成频谱图并分割成补丁。我们嵌入补丁并屏蔽掉很大的子集(80%)。然后编码器对可见的(20%)补丁嵌入进行操作。最后,解码器处理顺序恢复的嵌入和掩码标记以重建输入。Audio-MAE 正在最小化重建和输入频谱图的屏蔽部分的均方误差 (MSE)。
 Audio-MAE 在梅尔频谱图上的掩模策略。
Audio-MAE 在梅尔频谱图上的掩模策略。
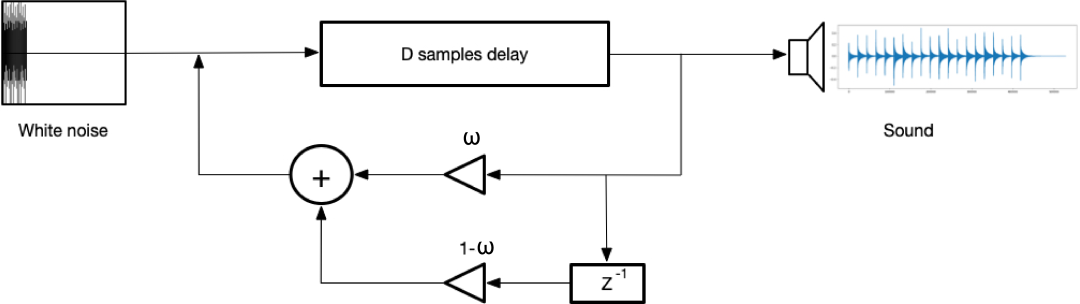 具有一零低通滤波器近似的弦乐器。合成过程首先生成一个短的激励𝐷长度波形。然后它被迭代地输入滤波器以产生声音。
具有一零低通滤波器近似的弦乐器。合成过程首先生成一个短的激励𝐷长度波形。然后它被迭代地输入滤波器以产生声音。
 视频-文本检索任务的说明:给定文本查询,根据视频描述文本的程度从数据库中检索视频并对其进行排名,反之亦然。
视频-文本检索任务的说明:给定文本查询,根据视频描述文本的程度从数据库中检索视频并对其进行排名,反之亦然。
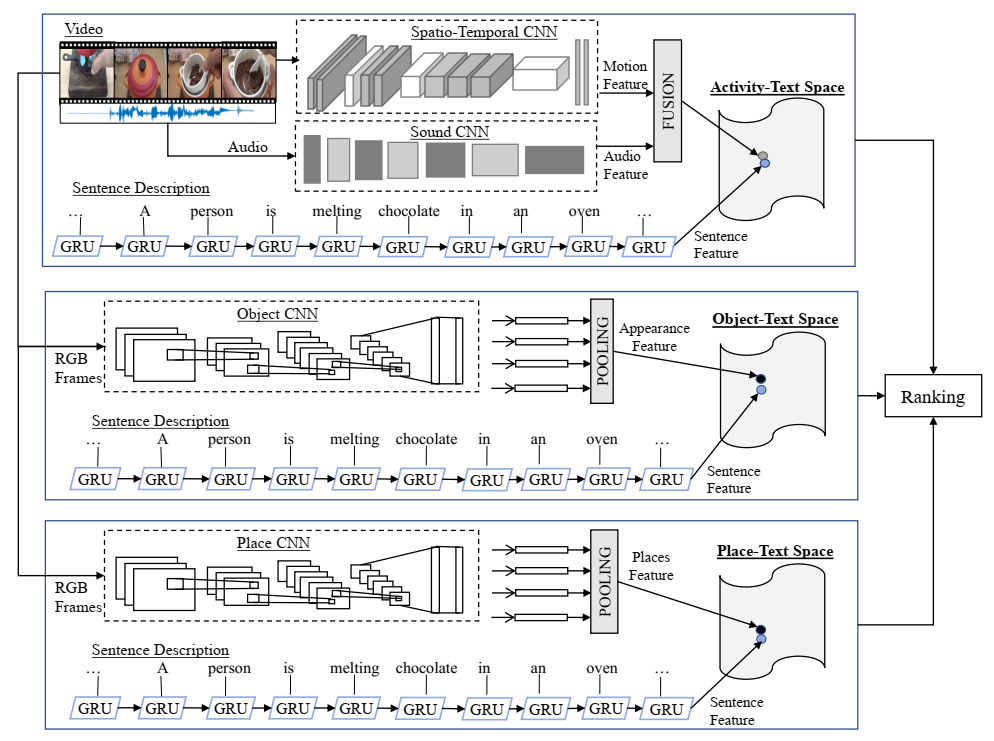 我们建议学习三个联合视频文本嵌入网络。一种模型学习文本特征和视觉对象特征之间的联合空间(对象文本空间)。另一个模型学习文本特征和活动特征之间的联合空间(活动-文本空间)。类似地,还有第三个模型,它学习场景特征和文本特征之间的联合空间(Place-Text Space)。在这里,对象-文本空间是解决与视频中的人物相关的歧义性的专家,而活动-文本空间是检索正在发生的活动的专家,而地点-文本空间是解决与视频中的位置相关的歧义性的专家 。给定一个查询句子,我们在所有三个嵌入空间中计算该句子与整个数据集中每个视频的相似度分数,并使用分数融合作为最终检索结果。
我们建议学习三个联合视频文本嵌入网络。一种模型学习文本特征和视觉对象特征之间的联合空间(对象文本空间)。另一个模型学习文本特征和活动特征之间的联合空间(活动-文本空间)。类似地,还有第三个模型,它学习场景特征和文本特征之间的联合空间(Place-Text Space)。在这里,对象-文本空间是解决与视频中的人物相关的歧义性的专家,而活动-文本空间是检索正在发生的活动的专家,而地点-文本空间是解决与视频中的位置相关的歧义性的专家 。给定一个查询句子,我们在所有三个嵌入空间中计算该句子与整个数据集中每个视频的相似度分数,并使用分数融合作为最终检索结果。
 括号中的值是排名最高的真实标题的排名。Ground Truth (GT) 是来自 ground-truth 字幕的样本。在所有方法中,对象文本(ResNet152 作为视频特征)和活动文本(I3D 作为视频特征)是使用单个视频文本空间进行检索的系统。我们还报告了融合系统的结果,其中三个视频文本空间(对象文本、活动文本和地点文本)用于检索。
括号中的值是排名最高的真实标题的排名。Ground Truth (GT) 是来自 ground-truth 字幕的样本。在所有方法中,对象文本(ResNet152 作为视频特征)和活动文本(I3D 作为视频特征)是使用单个视频文本空间进行检索的系统。我们还报告了融合系统的结果,其中三个视频文本空间(对象文本、活动文本和地点文本)用于检索。
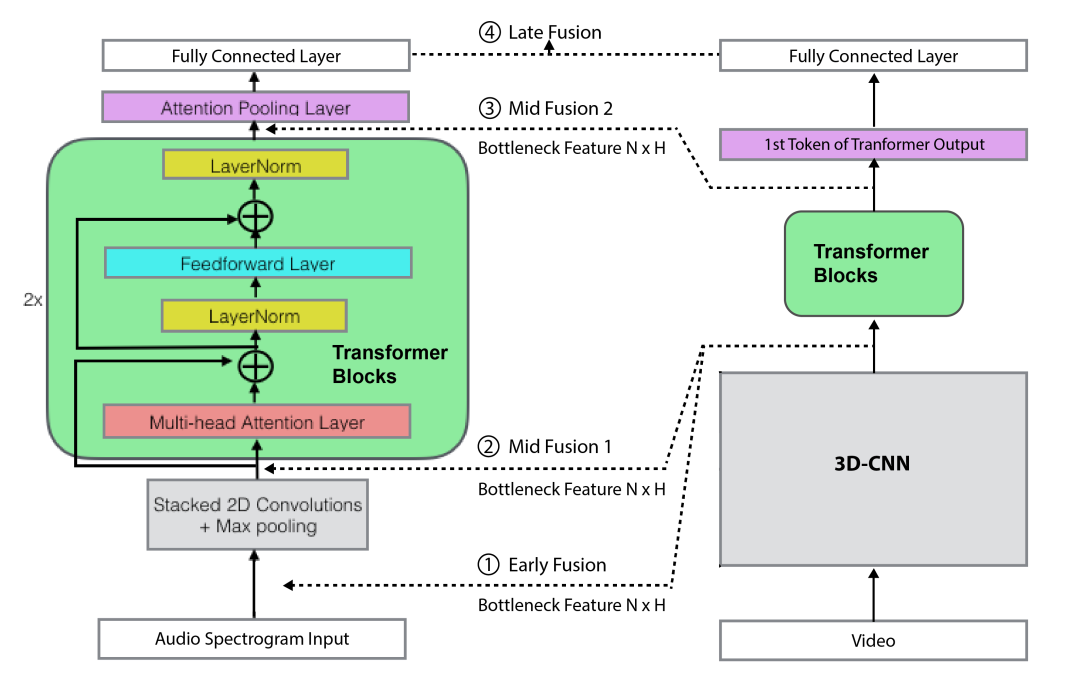 卷积自注意力网络的总体架构和研究的不同多模态融合策略。
卷积自注意力网络的总体架构和研究的不同多模态融合策略。
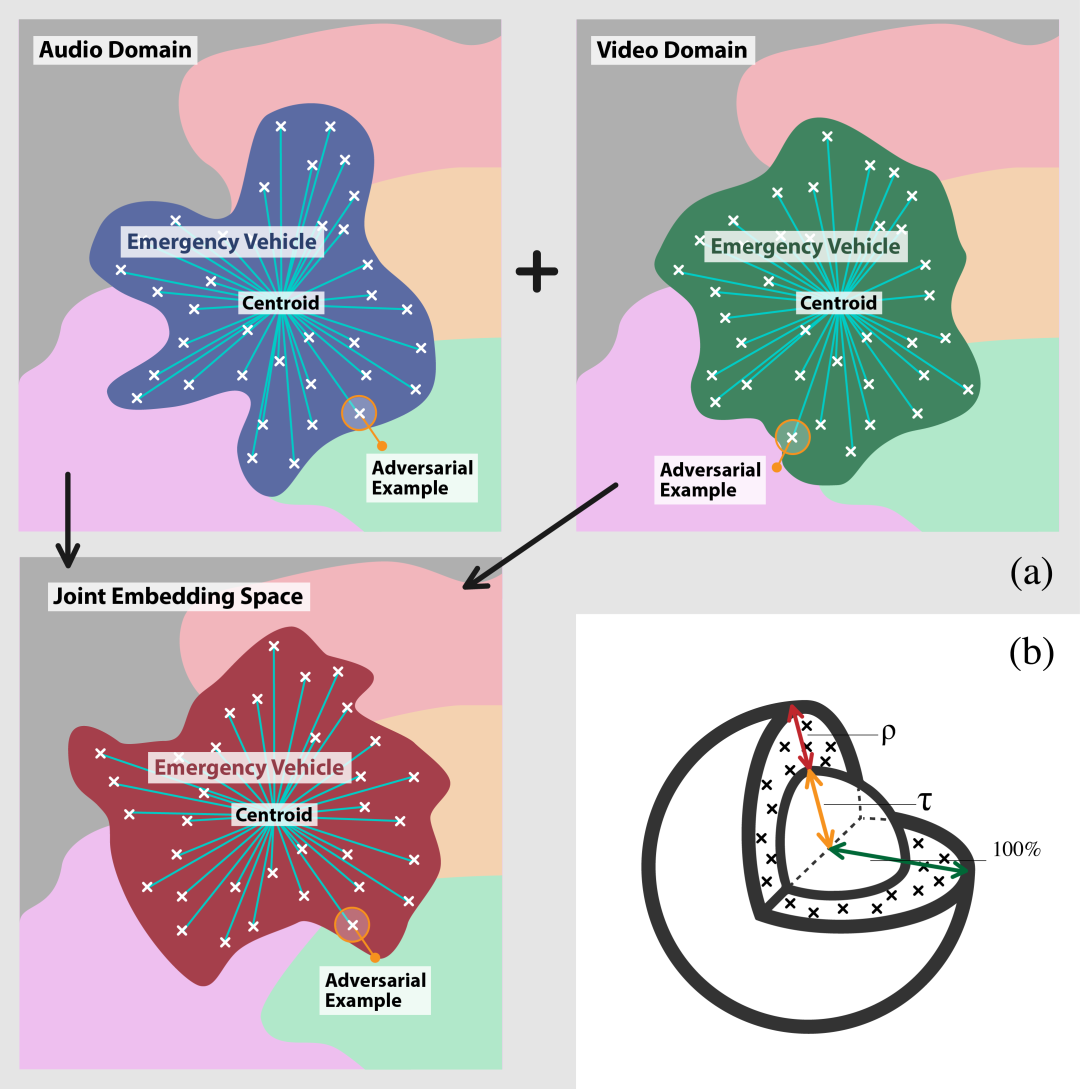 (a) 多模态融合的图示。(b) 基于质心的密度度量 𝜌_𝑐^(𝑅_𝜏,𝑝) 的图示。
(a) 多模态融合的图示。(b) 基于质心的密度度量 𝜌_𝑐^(𝑅_𝜏,𝑝) 的图示。
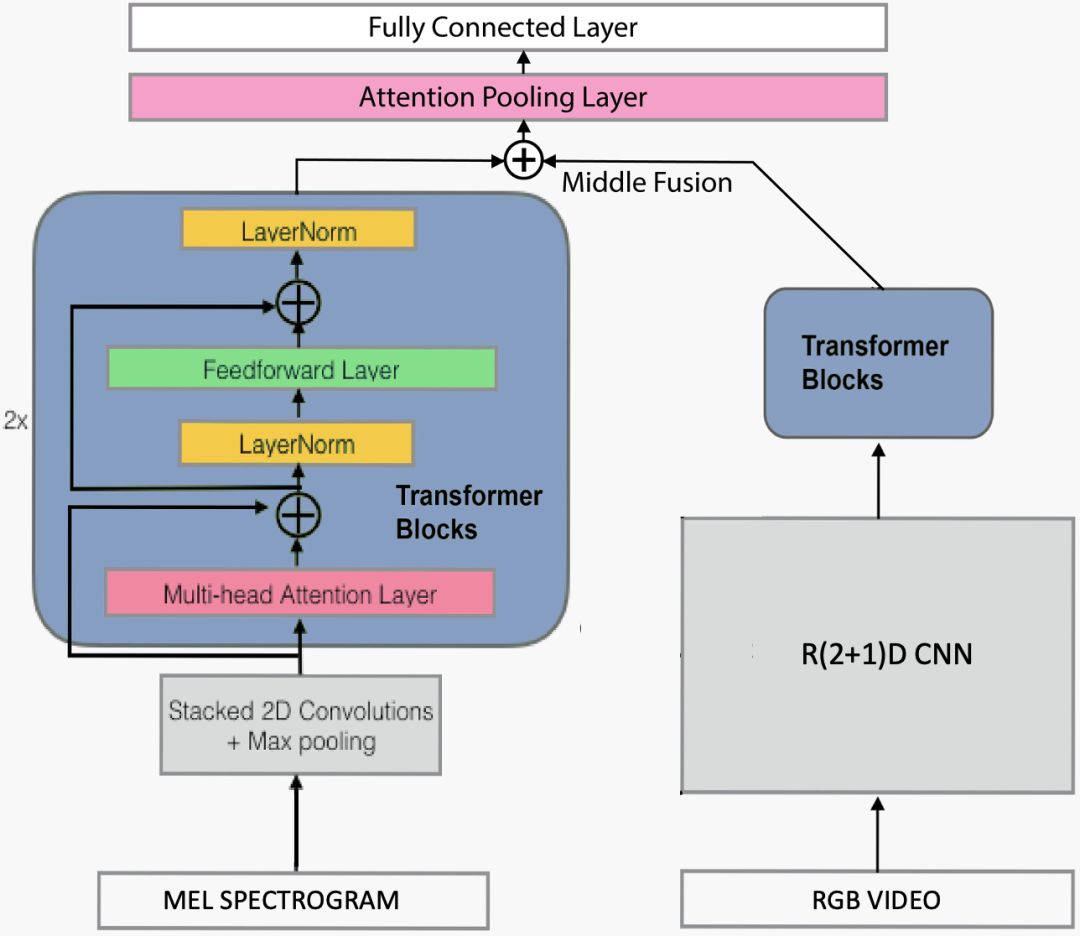 整体架构,音频分支(左)采用Convolution self-attention架构,视频分支在右边。中间融合涉及串联步骤。
整体架构,音频分支(左)采用Convolution self-attention架构,视频分支在右边。中间融合涉及串联步骤。
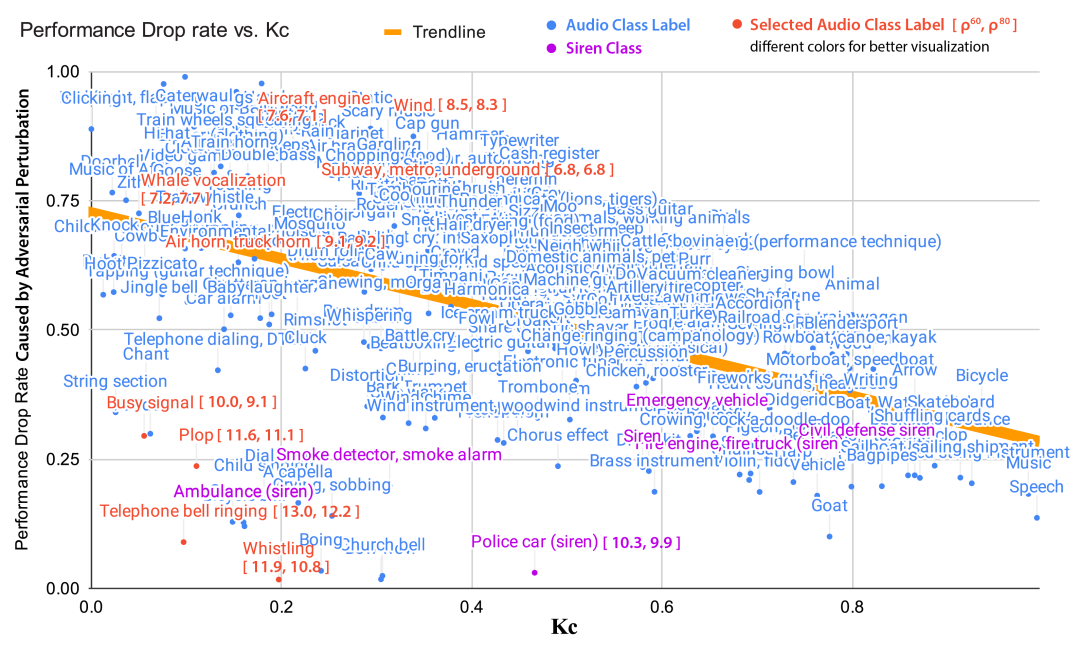 AudioSet 中所有音频类的性能下降率% VS 凸性 (𝜅𝑐)。由于空间限制,密度𝜌_𝑐^(𝑅,𝑝) 部分显示。
AudioSet 中所有音频类的性能下降率% VS 凸性 (𝜅𝑐)。由于空间限制,密度𝜌_𝑐^(𝑅,𝑝) 部分显示。
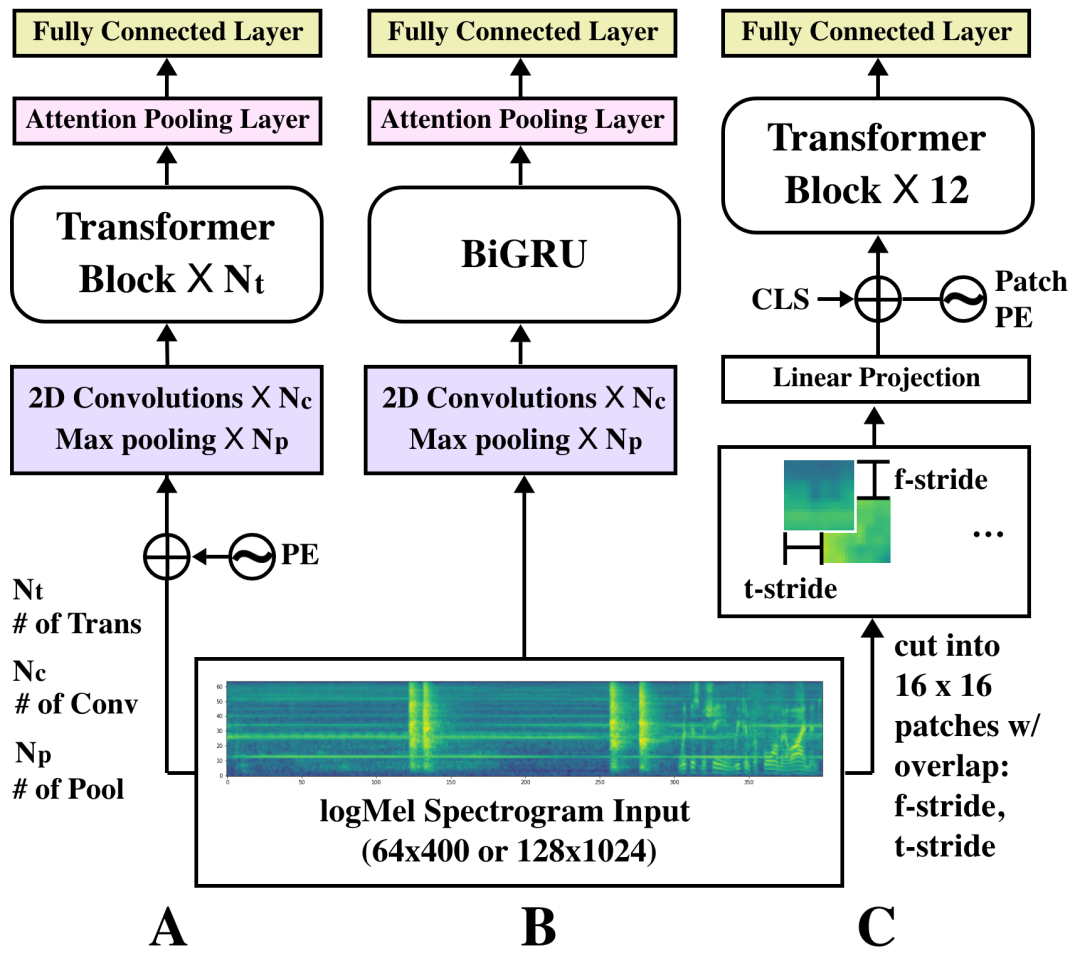 (A): CNN+Transformer, (B): CRNN (C): ViT. PE: positional encoding; 𝑁𝑡 = 2, 𝑁𝑐 = 10, 𝑁𝑝 = 5, f-stride=t-stride= 8
(A): CNN+Transformer, (B): CRNN (C): ViT. PE: positional encoding; 𝑁𝑡 = 2, 𝑁𝑐 = 10, 𝑁𝑝 = 5, f-stride=t-stride= 8
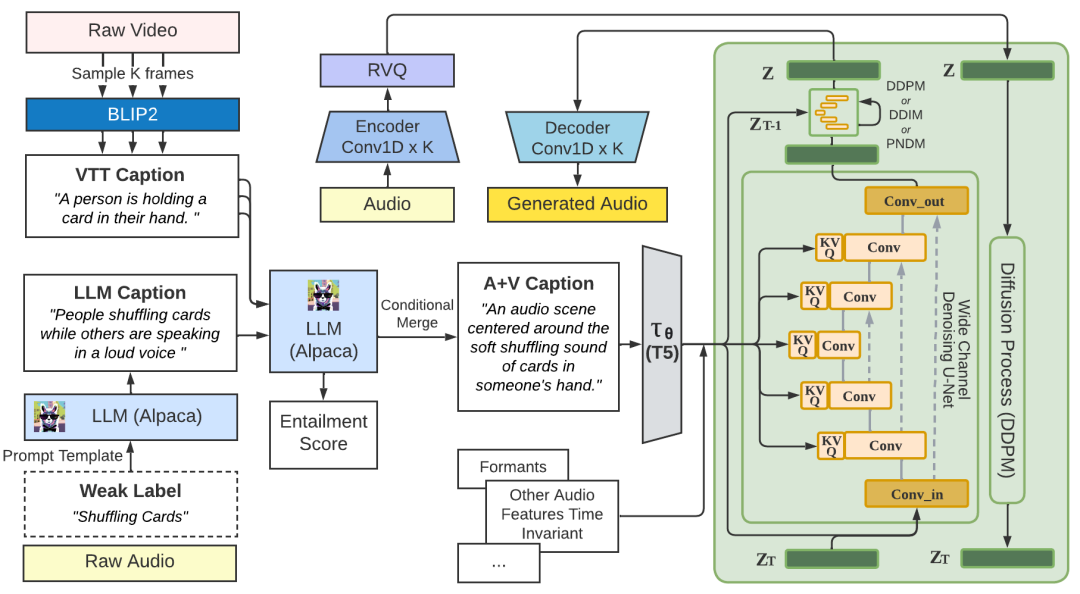 BLIP2、T5、Conv_in 和 Conv_out 层修改为 128 个通道。音频编码器、解码器和残差矢量量化 (RVQ) 层由 Encodec 进行预训练。
BLIP2、T5、Conv_in 和 Conv_out 层修改为 128 个通道。音频编码器、解码器和残差矢量量化 (RVQ) 层由 Encodec 进行预训练。
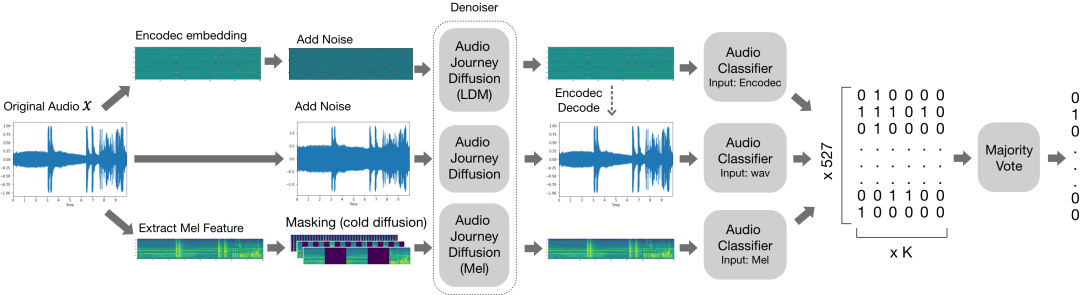 扩散作为去噪平滑,我们利用 3 种不同类型的音频旅程模型来防御噪声,包括对抗性扰动、有色噪声和遮挡。
扩散作为去噪平滑,我们利用 3 种不同类型的音频旅程模型来防御噪声,包括对抗性扰动、有色噪声和遮挡。
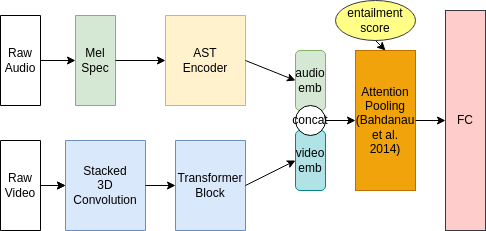
蕴涵分数惩罚注意力池层的注意力分数
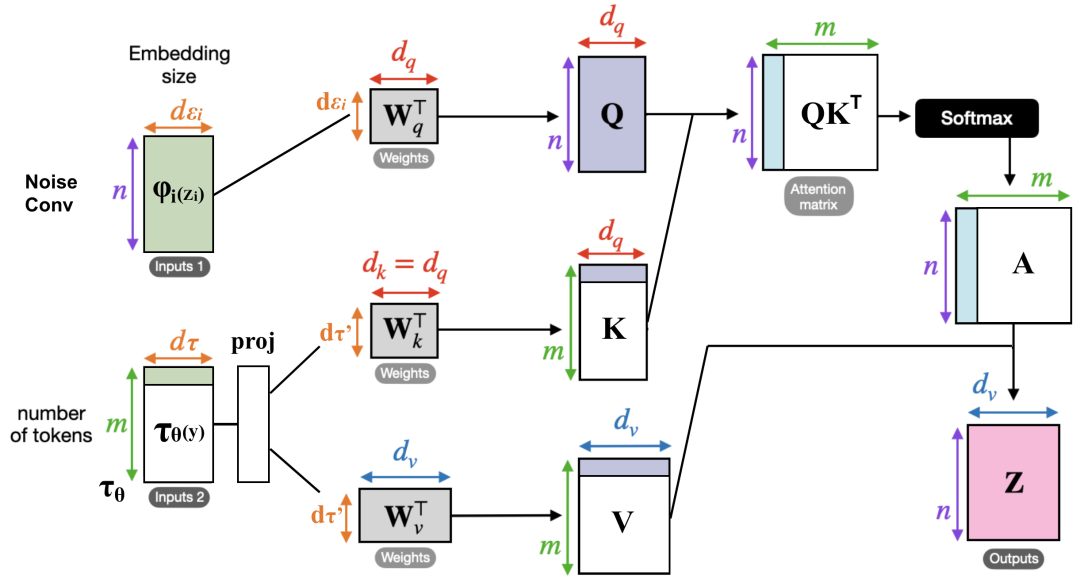 掩蔽场景下交叉注意力机制的图示,白色部分表示掩蔽。
掩蔽场景下交叉注意力机制的图示,白色部分表示掩蔽。





微信群 公众号


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢