
今天是2023年12月10日,周日,北京,天气阴,很冷。
本文主要讲三件事。
一个是关于RAG中的上下文构造问题。《Compressing Context to Enhance Inference Efficiency of Large Language Models》(地址:https://arxiv.org/pdf/2310.06201.pdf) 提出了一种名为"选择性文本"(Selective Context)的方法,通过识别和修剪输入上下文中的冗余内容,使输入更加紧凑,从而提高LLM的推理效率,这种方法本质上是一种“去停用词”的方案,但通用性不会太强。
一个是RAG长文本任务的数据构造问题。 《Never Lost in the Middle: Improving Large Language Models via Attention Strengthening Question Answering》(地址:https://arxiv.org/abs/2311.09198)中介绍了构造了两个阶段的训练数据来训练Ziya-Reader的方案,其中构造的原理,值得借鉴,尤其是其中的一些文章排序数据集的构造《T2Ranking: A large-scale Chinese Benchmark for Passage Ranking》(地址:https://arxiv.org/pdf/2304.03679.pdf)。
一个是最近一周的大模型开源动向。例如,文章twitter.com/MistralAI/status/1733150512395038967中给出了Mistral打不开源多专家混合模型的消息。 (地址:https://github.com/dzhulgakov/llama-mistral、模型权重:https://huggingface.co/someone13574/mixtral-8x7b-32kseqlen、测试地址:https://replicate.com/nateraw/mixtral-8x7b-32kseqlen)这又势必会掀起国产专家混合模型的下一波飞卷,除此之外,也出现了许多有趣的开源项目。
里面提到的数据构造方式,技术细节,值得我们深入了解,供大家一起思考。
一、基于自信息精简上下文用于大模型推理
代码地址:https://github.com/liyucheng09/Selective_Context
其实现方法很简单,"选择性上下文"(SelectiveContext),目的在于删除给定输入上下文中的冗余内容,从而降低计算成本,并更好地利用LLM中固定的上下文长度。
选择性上下文通过基础语言模型计算的自信息(来评估词汇单位(即词组、短语或句子)的信息量。通过有选择性地保留自信息较高的内容,为LLM处理文本提供了一种更紧凑、更高效的文本表征,而不会影响它们在各种应用中的性能。
1、什么是自信息?
自信息是信息论中的一个基本概念,量化了给定分布的事件所传达的信息量,token的自信息可以定义为负对数似然:
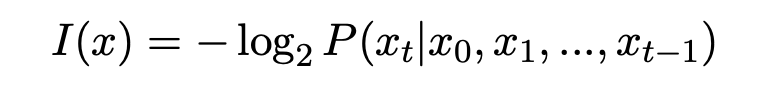
其中,I(x)表示token x的自信息,P(x)表示其输出概率。
在信息论中,自信息衡量了与事件相关的不确定程度;罕见事件传递的信息较多,因此自信息较高,而常见事件传递的信息较少,因此自信息较低。
在语言建模中,自信息可用于评估词汇单位(如词、短语或句子)的信息量。自我信息较低的词汇单位信息量较少,因此更有可能从上下文中推断出来。因此,在LLM推断过程中,可能会将输入的这些部分视为冗余。
此外,自信息属性具备可加性,将一个词性单元中各词块的自信息相加,就能计算出该词性单元的自信息。
具体实现方法如下:
2、采用语言模型,如GPT、OPT或LLaMA,计算每个token的自信息
给定上下文C=x0,x1,...,xn,其中xi表示一个标记符,使用基础语言模型M计算每个标记符xt的自信息:
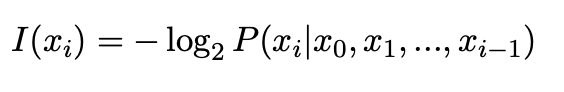
例如,使用gpt2计算自信息:
def _get_self_info_via_gpt2(self, text: str) -> Tuple[List[str], List[float]]:
if self.lang == 'en':
text = f"<|endoftext|>{text}"
elif self.lang == 'zh':
text = f"[CLS]{text}"
with torch.no_grad():
encoding = self.tokenizer(text, add_special_tokens=False, return_tensors='pt')
encoding = encoding.to(self.device)
outputs = self.model(**encoding)
logits = outputs.logits
probs = torch.softmax(logits, dim=-1)
self_info = -torch.log(probs)
input_ids = encoding['input_ids']
input_ids_expaned = input_ids[:, 1:].unsqueeze(-1)
tokens = [self.tokenizer.decode(token_) for token_ in input_ids.squeeze().tolist()[1:]]
return tokens, self_info[:, :-1].gather(-1, input_ids_expaned).squeeze(-1).squeeze(0).tolist()
3、将token及其相应的自信息值合并为词性单元
考虑到如果只在token层面对选择性上下文进行内容过滤,可能会导致上下文非常不连贯。因此,除了在标记层面进行过滤外,还在短语和句子层面进行过滤。
将过滤中的基本单位称为词性单位,词性单位可以是一个标记、一个短语或一个句子。
为了使选择性上下文能够在短语和句子上发挥作用,将标记及其自信息合并为词性单元。
每个词性单元u都由多个token(xt,...,xt+α)组成,可以根据自信息的可加性,通过将各个标记的自信息相加来计算其自信息。
根据自信息的可加性,可以计算出它的自信息:
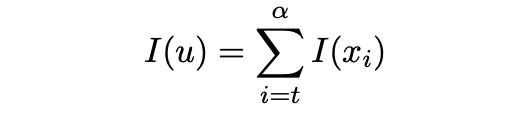
具体地,用NLTK句子标记符号生成器获得句子级词性单元。使用spacy将标记合并为名词短语,不合并动词短语,因为这样可能会产生很长的短语。
这块的代码可以参考:https://spacy.io/api/pipeline-functions#merge_noun_chunks
4、剔除认为最没有必要的内容
这一步没有使用固定的阈值或保留固定数量的前k个词性单元,而是设计了一种基于百分位数的过滤方法来自适应地选择信息量最大的内容。
首先,根据词性单位的自信息值降序排列。然后,计算所有词性单元中自信息值的p百分位数。
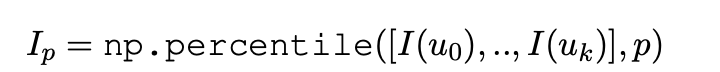
接下来,选择性地保留自信息值大于或等于第p个百分位数的词汇单位,构建一个新的上下文C′:
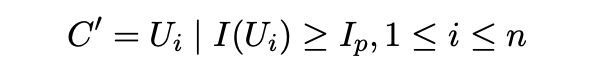
基于百分位数的过滤是一种更灵活的方法,可根据给定上下文中自信息值的分布情况保留信息量最大的内容。
在图2中,以短语为例,将p设为50,即过滤掉一半的短语。在这种情况下,经过选择性上下文处理后的上下文只保留了57.2%的标记,节省了42.7%的上下文长度。

最后,在性能测试上,该工作使用需要处理长上下文的常见数据源(如arXiv论文、新闻报道和长对话)进行了测试,测试的任务包括总结、问题解答和生成回复,取得了不错的效果。不过,缺陷很明显:
该方法在一定程度上受到短语边界检测程序的影响,在实验中使用了spacy提供的名词短语标记化算法,但没有考虑动词短语。其次,在实验部分,使用百分位数来控制剪枝过程。然而,根据具体的任务和语境,最佳的百分位数是不同的。此外,使用这种方法,会很容易造成语义不连贯的问题。
二、再看Ziya-Reader的长文本训练数据构造方案
文章《https://mp.weixin.qq.com/s/VNvbpZ6Zp8huA4MPxdXglg》对ziyareader的工作进行了介绍,感兴趣的可以跟进。
我们重点来关注其数据的构造部分。
指令调整过程分为两个阶段。在第一阶段,将LLM的上下文窗口扩展到8K。在第二阶段,使用ASMQA数据对模型进行了训练,以解决被称为"中间丢失"的注意力(或记忆)失效问题。 中间丢失"。
1、上下文窗口扩展
这个阶段,使用了约30万个精选数据进行SFT。这些数据涵盖了不同类别的任务,包括QA、MRC、角色扮演、写作、编码、翻译、头脑风暴、数学、语言建模(LM)以及文本分类等其他自然语言理解(NLU)任务。然后,除LM任务外,将数据打包成8k窗口大小的多轮对话样式,LM任务计算整个序列的交叉熵损失。
2、ASMQA数据的构造
收集了多文档QA数据,并将其调整为专用的ASMQA数据。
首先,从DuReader2.0数据集和WebCPM中分别筛选出30k个单个答案的事实类样本和20k个样本。DuReader2.0是来自网络文档和社区质量保证的最大中文MRC数据集,包含20万个问题、42万个答案和100万个文档。
为确保数据质量,利用奖励模型对样本进行评分,并以一定的阈值选择其中高质量的部分。奖励模型使用69k人类排名样本对一般任务进行训练。
对于每个样本,除了正样本外,整个集合中的文档都被视为负样本。
由于协作学习对RAG有益,利用相应数据集中的所有文档建立了一个基于嵌入的搜索引擎。
随后,使用该搜索引擎检索包含70%数据的分区中的负样本,并从中随机抽取剩余部分的数据,检索到的负面样本与问题更相关,也更难与正面样本区分开来【也就是常说的难样本】。
接下来,在50%的数据中,对每个样本中的文档进行打乱,以防止正面文档始终位于上下文的开头。
此外,为了提升难样本学习的效果,模型需要知道给定的上下文中哪些更为相关,因此可以借鉴一些passage-ranking的数据集,如下所示:
例如,该工作然从检索基准T2Rank中抽取了25k个样本作为补充,而其中的工作《T2Ranking: A large-scale Chinese Benchmark for Passage Ranking》(地址:https://arxiv.org/pdf/2304.03679.pdf),其是一个文本排序的数据集,构造方式也很有趣,值得看看。
3、T2ranking的构造方式
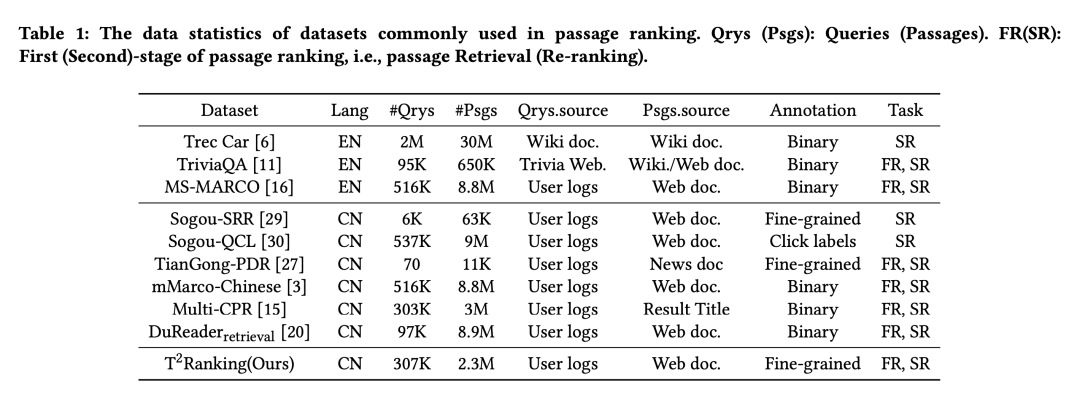
构建T2Ranking的整体流程涉及多个步骤,包括查询采样、文档检索、段落提取和细粒度相关性注释。
在查询采样上。 从搜狗的查询库中抽取真实的用户查询,并进行预处理(如去重、归一化冗余空格和问号),以获得干净的查询数据集。然后,使用意图分析算法过滤掉色情、非询问和资源请求类型的查询,以及可能包含T2Ranking用户信息的查询,以确保数据集只包含高质量、基于问题的查询。
在文档检索环节。 利用搜狗、百度和谷歌等流行搜索引擎在网络内容索引和排序方面的丰富资源和专业知识,为每个查询检索一整套文档。这有助于减少假阴性的问题,因为每个系统都覆盖了网络的不同部分,可以返回不同的相关文档,从而提高了数据集的整体覆盖率。
在段落提取环节。 T2Ranking中的段落构建涉及分段和去重。没有使用启发式方法来分割给定文档中的段落(例如,传统的通过换行来确定段落的开始或结束),而是采用一种基于模型的方法来分割段落,以最大限度地保留每个段落中的完整语义。此外,引入一种基于聚类的技术,以提高注释效率并保持注释查询-段落对的多样性。这种方法能有效去除由特定查询检索到的几乎相同的段落。随后,经过分割和去除重复的段落将被合并到段落集合中,用于T2Ranking。
在精细相关性标注环节。 所有受聘的标注员都是为搜索相关任务提供标注的专家,并且长期从事标注工作。至少有三位标注员为每个查询-段落对提供四级精细标注。具体来说,如果前三位标注者对某一特定配对的标注不一致(三位标注者提供了三个不同的分数),则会要求第四位标注者进行标注。如果所有四位注释者的注释都不一致,那么查询-段落对就会被认为过于模糊,无法确定所需的信息,从而被排除在数据集之外。每个查询-段落对的最终相关性标签由主要投票决定。
相关性标注分成四级:
如在表2中展示了几个例子。细粒度的4级注释可以准确评估段落重新排序任务。值得注意的是,在检索任务中,我们将二级和三级段落视为相关段落,其他段落均视为不相关段落。

0级表示查询内容和段落内容完全不匹配;
1级表示段落与查询相关,但不能满足查询所需的信息需求;
2级表示段落与查询相关,部分满足查询的信息需求;
3级表示段落内容是为满足查询的信息需求而定制的,准确地包含了查询的答案。
此外,还构造了少部分样本,这一部分样本中没有任何相关的正确上下文段落,这部分样本的输出是“根据以上内容,我不知道正确的答案“,这些样本被称为"合成未知样本",用于训练模型,以避免不必要的信任,并识别没有正确文档的情况,这个和我们所说的拒答样本是一类的,这块可以根据dureader字段中的"is impossible"的值来进行选择。
三、最近一周其他几个有趣的一些大模型开源工作
1、Mistral发布了开源的多专家混合模型
文章《twitter.com/MistralAI/status/1733150512395038967》中给出了Mistral打不开源多专家混合模型的消息。
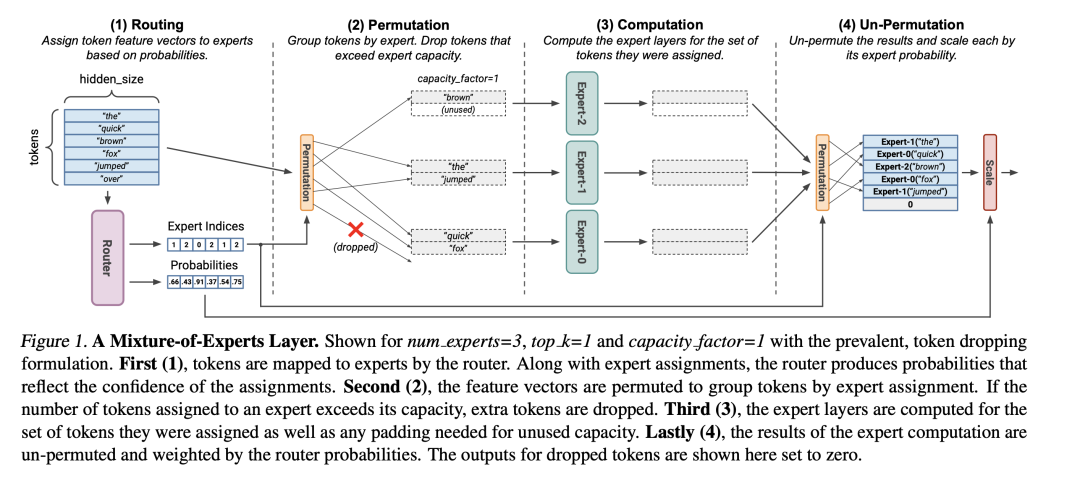
地址:https://github.com/dzhulgakov/llama-mistral
模型权重:https://huggingface.co/someone13574/mixtral-8x7b-32kseqlen
测试地址:https://replicate.com/nateraw/mixtral-8x7b-32kseqlen
2、关于大模型数据工程的一些可读论文集合
开源项目Data Management for LLM综述了大型语言模型的训练数据管理探索相关论文资源列表,包括有关大型语言模型的训练数据管理的资源,包括预训练、数据质量、领域构成等方面的内容:

地址:github.com/ZigeW/data_management_LLM
3、DevOps领域大模型评估数据集
该仓库包含与DevOps和AIOps相关的问题和练习。目前有5977个多项选择题,根据DevOps的通用流程将其归纳为8个模块,覆盖的场景包括日志解析、时序异常检测、时序分类、时序预测和根因分析。

地址:github.com/codefuse-ai/codefuse-devops-eval
总结
本文主要介绍了三个事情:
一个是RAG中的上下文构造问题,《Compressing Context to Enhance Inference Efficiency of Large Language Models》提出了一种名为"选择性文本"(Selective Context)的方法,通过识别和修剪输入上下文中的冗余内容,使输入更加紧凑,从而提高LLM的推理效率,这种方法本质上是一种“去停用词”的方案,但通用性不会太强。
另一个也是跟RAG相关的训练数据构造问题,《Never Lost in the Middle: Improving Large Language Models via Attention Strengthening Question Answering》中介绍了构造了两个阶段的训练数据来训练Ziya-Reader的方案,其中构造的原理,值得借鉴,尤其是其中的一些文章排序数据集的构造《T2Ranking: A large-scale Chinese Benchmark for Passage Ranking》。
第三个事情是最近的一些大模型的动向,如Mistral开源多专家混合模型的消息、关于大模型数据工程的一些可读论文集合、DevOps领域大模型评估数据集,这些都值得关注。
参考文献
1、ttps://arxiv.org/pdf/2304.03679.pdf
2、https://arxiv.org/pdf/2310.06201.pdf
3、github.com/ZigeW/data_management_LLM
4、github.com/codefuse-ai/codefuse-devops-eval
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢