
上海科大&阿里巴巴达摩院 | 结构化知识蒸馏 【论文标题】Structural Knowledge Distillation 【作者团队】Xinyu Wang, Yong Jiang, Zhaohui Yan, Zixia Jia, Nguyen Bach, Tao Wang, Zhongqiang Huang, Fei Huang, Kewei Tu 【发表时间】2020/10/10 【论文链接】https://arxiv.org/pdf/2010.05010.pdf
【推荐理由】 本文提出了一种新的结构化知识蒸馏方法,致力于解决目标输出空间呈指数级大小而难以计算和优化的问题。
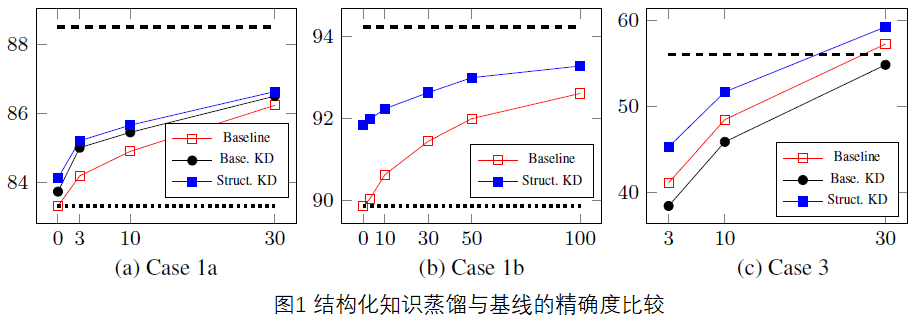
知识蒸馏(Knowledge Distillation ,KD)是一种通过学生模型(小模型)模仿教师模型(大模型)的输出概率分布来训练学生模型的技术。典型的KD目标函数是教师模型和学生模型预测的输出分布之间的交叉熵。但当对结构化预测进行知识蒸馏时,一个主要的挑战是输出空间的大小是指数级的,这导致交叉熵目标难以计算。以前的结构化KD方法要么选择在局部决策或子结构上进行KD,要么求助于目标的top-K近似。基于此本文提出,KD目标可以通过学生对输出结构评分函数的分解来实现。本文导出了结构KD目标的分解形式,将该方法应用于四个KD场景。实验结果表明,该方法优于没有KD的基线和以前的KD方法。在无标记数据的情况下,该方法甚至可以促进学生在零样本跨语言迁移方面的表现优于教师。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢