
今天是2023年12月11日,星期一,北京,初雪。
我们在之前的文章中有介绍过longbench评测,其中有多文档QA这一任务。
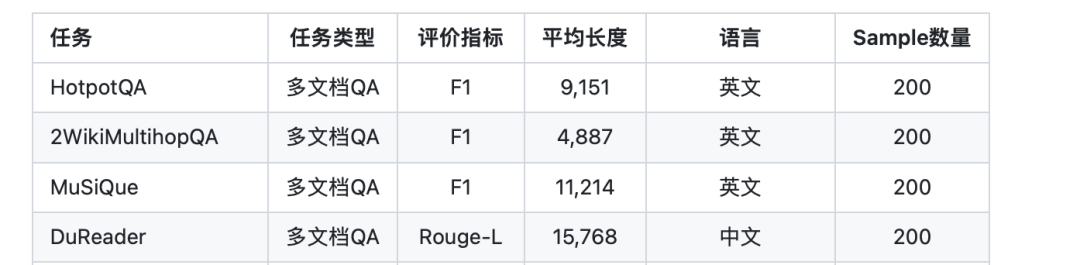
最近看到的一个工作,《Knowledge Graph Prompting for Multi-Document Question Answering》(地址:https://arxiv.org/pdf/2308.11730.pdf),提出了一种知识图谱提示(KGP)方法,用于在多文档问题解答(MD-QA)中制定正确的LLM提示上下文,其中利用知识图谱来组织、选择上下文,具有一定的参考意义。
而最近,也出现了LLM Visualization大模型网络结构可视化的工作,其对于我们了解GPT的结构,也很有帮助,大家也可看看。
一、LLM Visualization大模型网络结构可视化
大模型网络结构可视化,可以动态地增强我们对大模型网络结构的认识,最近的一个项目,地址:https://bbycroft.net/llm,以GPT2、GPT-3、nano-gpt等模型,从embedding、layer norm, self attention, projection, mlp, tranformer, softmax以及ouput等各个模型进行了解构,很有趣。
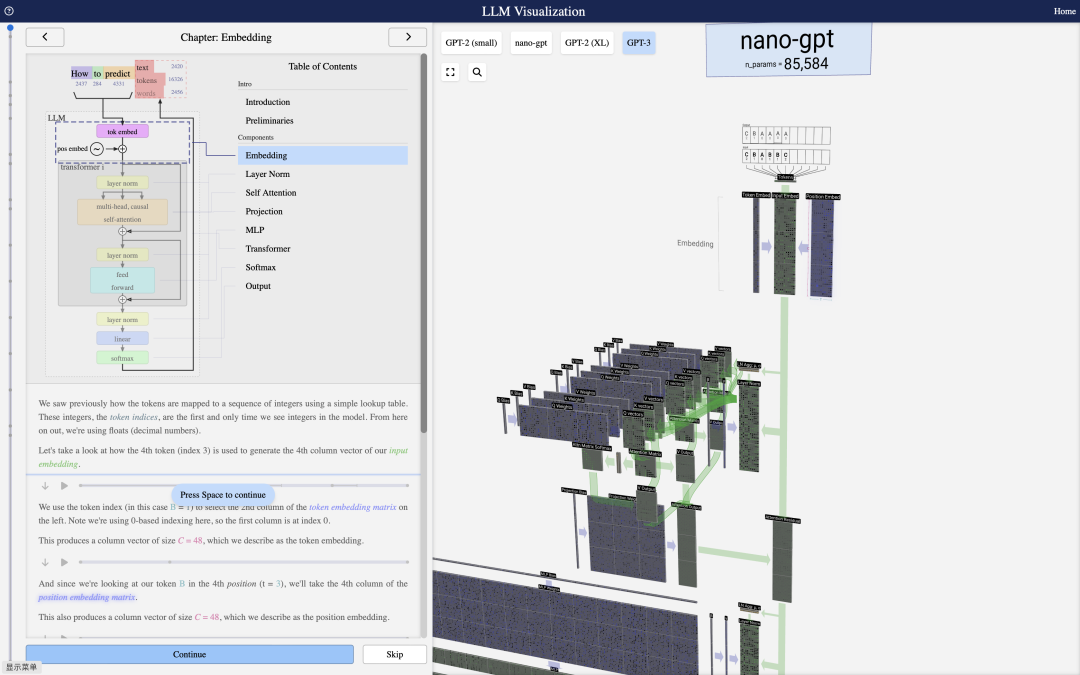
通过交互,可以很知道数据流之间的流转。
二、知识图谱prompt用于多文档问答
大型语言模型(LLM)的"预训练、提示、预测"范式在开放域问题解答(OD-QA)中取得了显著的成功。
然而,很少有人在多文档问题解答(MD-QA)中探索这一范式,因为这项任务要求对不同文档的内容和结构之间的逻辑关联有透彻的了解,MD-QA的主要挑战在于它要求在不同文档中交替检索和推理知识。
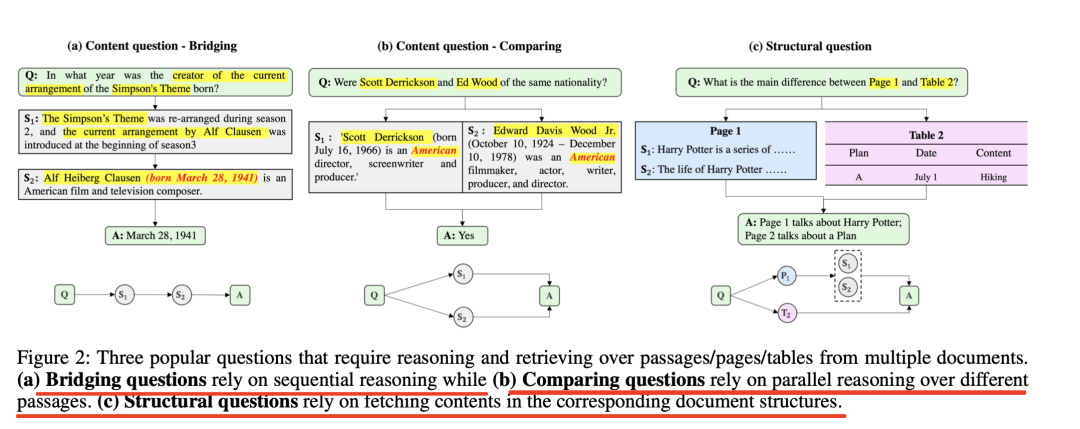
例如,要成功回答图2(a)-(b)中的问题,需要对两个不同文档(在这两个案例中是维基百科页面)中的不同段落进行推理。此外,每个文档本质上都是多模态结构数据(如页面、章节、段落、表格和数字)的汇编,有些问题可能会特别询问某些结构中的内容,这就需要全面掌握这些复杂的文档结构。
图2(c)中的问题询问第1页和第2页之间的区别,如果使用BM25等启发式方法或DPR等深度学习方法,就无法回答这个问题。 最近看到的一个工作,《Knowledge Graph Prompting for Multi-Document Question Answering》(地址:https://arxiv.org/pdf/2308.11730.pdf),提出了一种知识图谱提示(KGP)方法,用于在多文档问题解答(MD-QA)中制定正确的LLM提示上下文。
其大致思想在于:在构建图时,该工作在多个文档上创建一个知识图(KG),图中的节点表示段落或文档结构(如页面/段落),边表示段落之间或文档内部结构关系之间的语义/词汇相似性。
该工作的代码可以参见:https://github.com/YuWVandy/KG-LLM-MDQA。
1、知识图谱构图Knowledge Graph Construction
在知识图谱构图阶段,其大致流程如图所示:
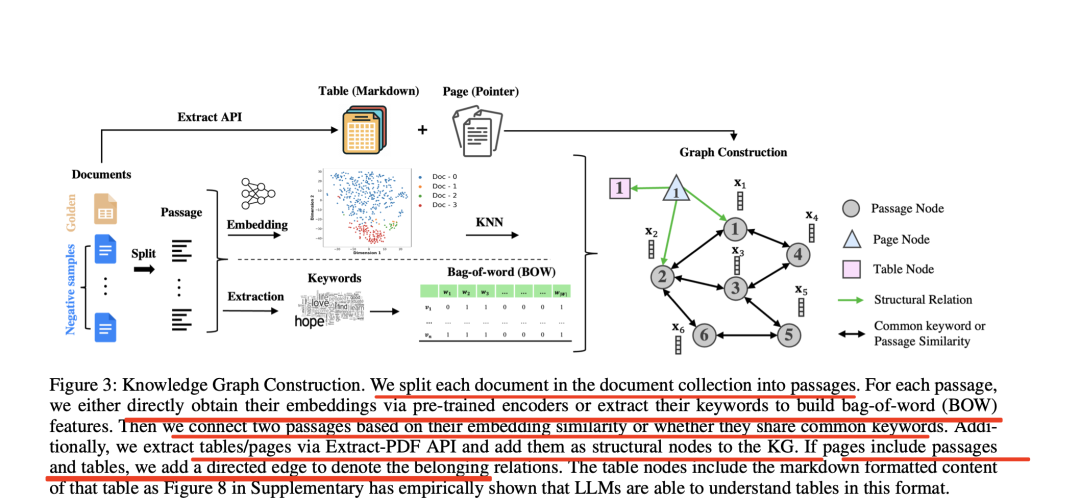
该工作将文档集中的每篇文档分割成不同的段落。
对于每个段落,通过预先训练的编码器直接获取它们的嵌入,要么提取它们的关键词来构建词袋(BOW)特征,然后根据两个段落的嵌入相似度或它们是否有共同的关键词将它们连接起来。
此外,通过Extract-PDFAPI提取表格/页面,并将其作为结构节点添加到KG中。如果页面包含段落和表格,添加有向边来表示归属关系。
表格节点包括该表格的markdown格式内容,LLM能够理解这种格式的表格。

首先是基于TF-IDF的构建方式。 为了根据词性相似性添加边,首先对每篇文档应用TF-IDF关键词抽取法,以过滤掉无意义的词,如辅助动词和冠词,从而减少BOW特征的维数,稀疏化所构建的图,并提高图遍历的效率。此外,还将文档标题添加到提取的关键词集中,因为有些问题的重点是标题。收集从所有文档中提取的关键词,形成关键词空间W,然后将W中具有共同关键词的两个段落连接起来。
其次是,KNN-ST/MDR的构建方式。 为了根据语义相似性添加边缘,可以利用模型为每个节点vi生成段落嵌入Xi,然后计算成对相似性矩阵,构建K近邻图(KNN)。但这些现成的模型通常是在与MD-QA并不相关的任务中训练出来的,可能无法在问题所要求的嵌入相似性中充分囊括必要的逻辑关联。所以,该工作采用了MDR的训练策略,通过根据先前的支持事实预测后续的支持事实来训练句子编码器,从而赋予编码器推理能力。因此,Em-bedding相似性和相应构建的KNN图从根本上概括了不同段落之间必要的逻辑关联。
其三,TAGME的构建方式。 从每个段落中提取维基百科实体,并根据两个段落节点是否共享共同的维基百科实体来构建图。除了段落节点,还通过Extract-PDF提取文档结构,进一步将结构节点添加到图中。页面节点的特征是页码,我们会从页码向该页面的句子/表格节点添加有向边。
2、LM引导的图遍历LM-guided Graph Traverser
实现自适应图遍历的一个自然解决方案是对候选节点进行排序,也就是对已经访问过的节点的邻居进行排序,从而确定下一步要访问的节点。最直接的方法是应用基于启发式的模糊匹配或基于嵌入的相似性排序,但这两种方法都无法捕捉到已遍历路径与待访问节点之间的内在逻辑关系。
该工作对语言模型进行微调,以引导图的遍历走向下一个最有希望的段落,从而根据已访问的段落接近问题。
如图4所示:
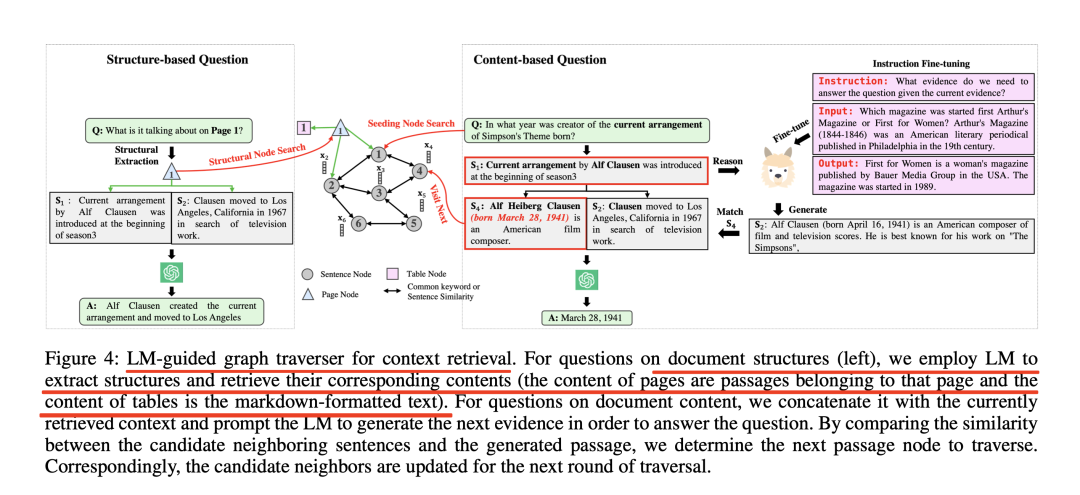
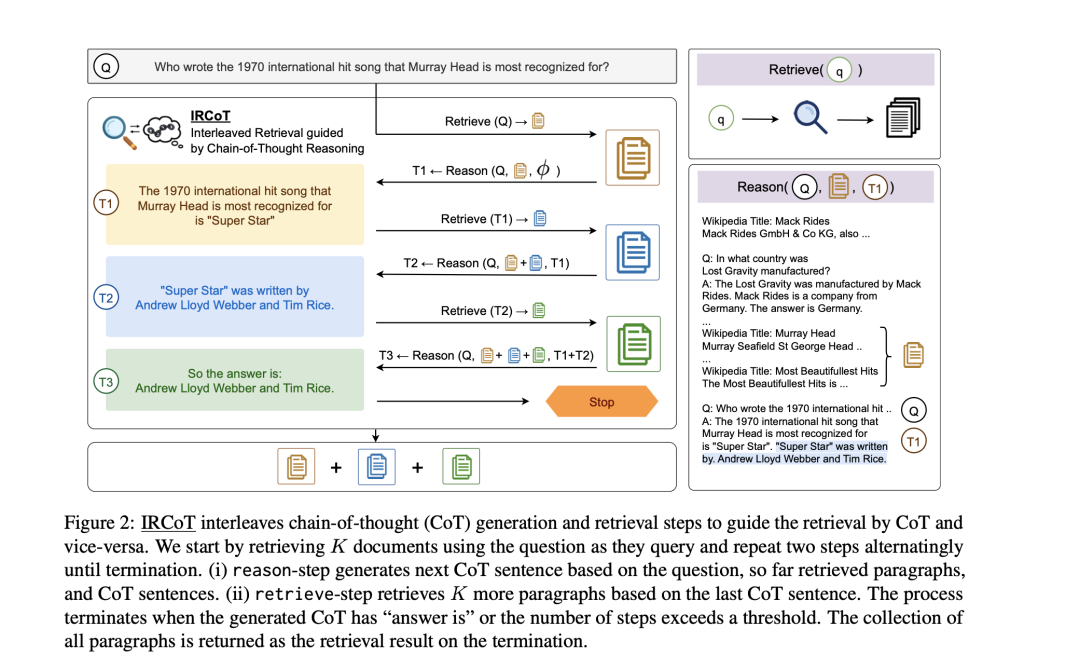
在图4中,问题是"当前《Simp-son'sTheme》编曲的创作者是哪一年出生的?
首先,使用TF-IDF搜索来初始化段落节点1:AlfHeibergClausen(生于1941年3月28日),美国电影作曲家。随后,在当前检索到的上下文(节点1)前加上问题,并提示LM生成下一个接近问题所需的证据。
由于通过指令微调增强了LM的推理能力,因此它有望识别问题与当前检索上下文之间的逻辑关联。因此,它可以预测保持逻辑连贯性的后续段落,尽管其中可能包含事实错误,例如,"AlfClausen(生于1941年4月16日)是一位美国电影和电视配乐作曲家。
为了纠正这一潜在的事实错误,从候选邻接中选择与LM生成的内容匹配度最高的节点,在本例中,节点4"AlfHeibergClausen(生于1941年3月28日)是一位美国电影作曲家"。由于该文本直接来源于文档,因此从本质上确保了信息的有效性。然后,提示LLMs和检索到的上下文节点1和节点4,以获得答案。
此外,对于询问文档结构的问题,会提取文档结构名称,并在KG中找到其对应的结构节点。对于表格节点,会检索其markdown格式的内容;对于页面节点,会遍历其单跳(one-hop)邻居并获取属于该页面的段落。
进一步对该方案进行形式化,可以总结为:
给定一个询问文档内容的问题q,LM引导的图遍历器会对之前访问过的节点/检索到的段落{sk}jk=0进行推理,然后生成下一个段落sj+1如下:
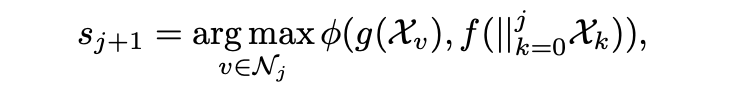
其中,||j k=0Xk连接了之前检索到的段落/访问过的节点的文本信息。
对于f的选择,一种方法是采用仅编码器模型,如Roberta-base,g将是另一种编码器模型,φ(-)是测量嵌入相似性的内积。另一种方法是采用编码器-解码器模型,如T5,g是一个身份函数,φ(-)用于测量文本相似性。
为了减轻幻觉问题并增强LMs的推理能力,进一步对f进行了指令微调,根据之前的支持事实预测下一个支持事实,从而将原本编码在其预训练参数中的常识性知识与指令微调后增强的推理能力结合起来。
在访问了根据公式(1)从候选邻居队列中选出的得分最高的节点后,候选邻居队列通过添加这些新访问节点的邻居进行更新。
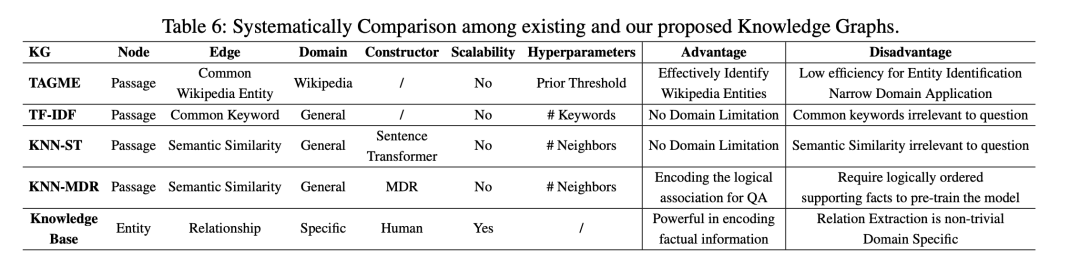
3、几种构图方式的对比
表6显示了现有知识图谱与我们提出的知识图谱的系统性比较
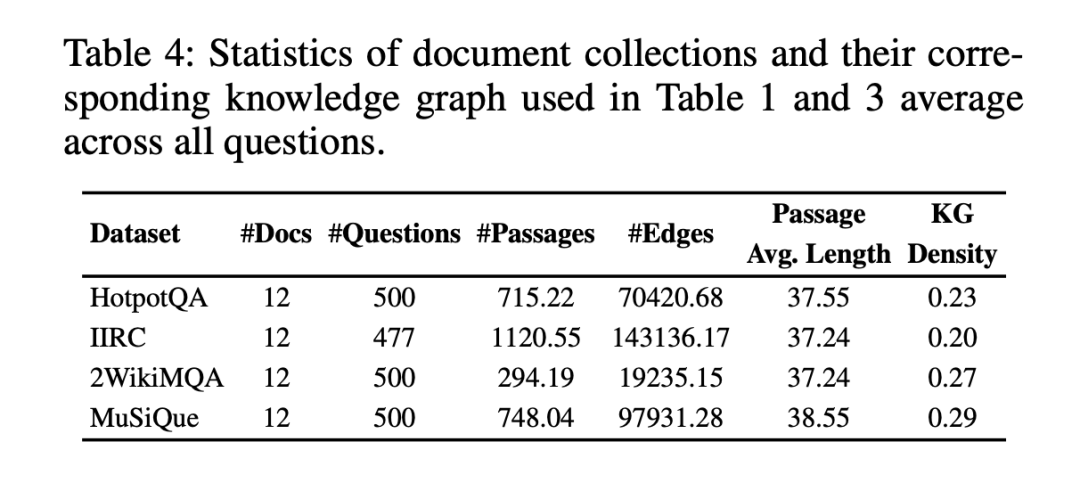
并针对HotpotQA, IIRC, WikiMHop, and Musique等几个数据集进行构建。
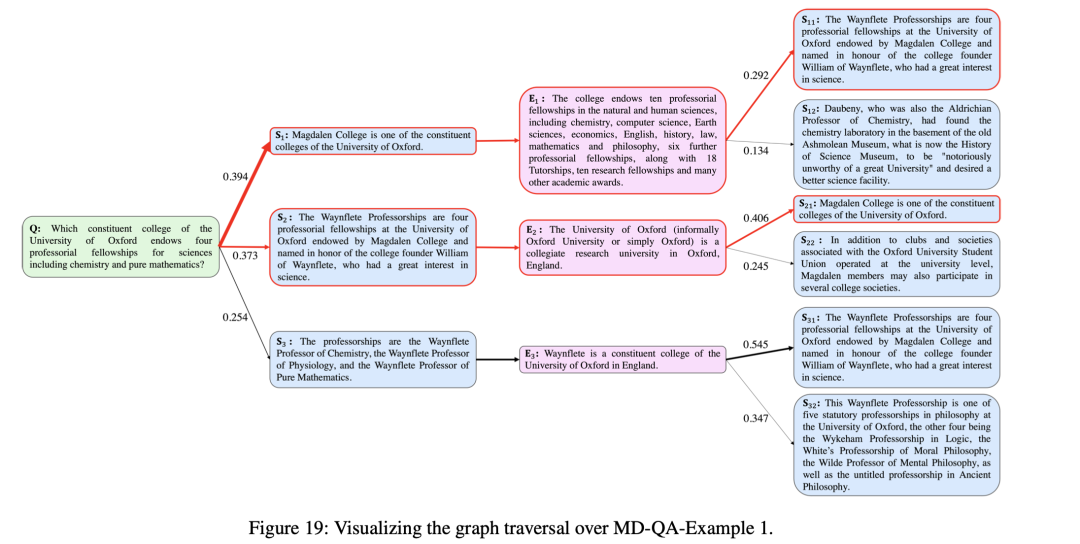
可以进一步看看几个图遍历的例子:
以及最终检索得到的prompt形式:

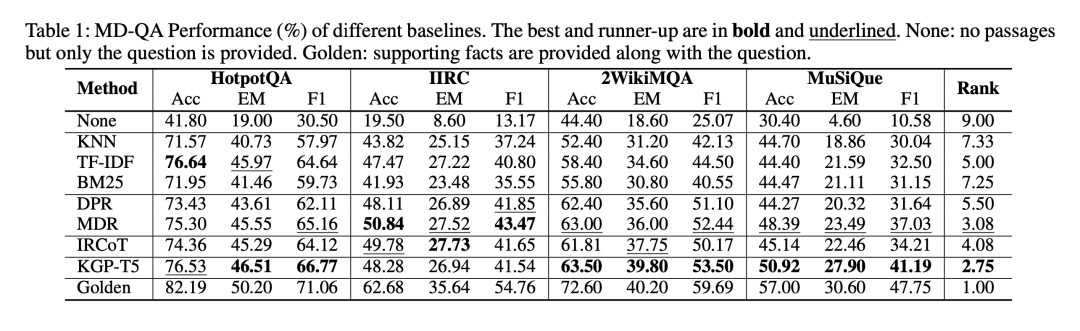
在最终评测上,将KGP与三类检索基线进行了比较。第一类是基于启发式的检索,包括带有模糊搜索的KNN、TF-IDF和BM25。第二类是基于深度学习的检索器,包括DPR和MDR。第三类是基于提示的检索器,包括IRCoT。对于KGP,根据其LM引导图检索器研究了三种变体:KGP-T5、KGP-LLaMA和KGP-MDR,分别使用T5(编码器-解码器)、LLaMA(仅解码器)和MDR(仅编码器)作为公式(1)中的f。
其中:
KNN使用句子转换器变体"multi-qa-MiniLM-L6-cos-v1"来获取段落嵌入,因为该变体已在来自不同来源的215M个(问题、答案)对上进行过训练。然后,我们根据嵌入相似度选出前15个段落,根据模糊匹配选出前15个段落。
MDR使用以内积为评分函数的波束搜索来对段落进行排序。将搜索深度限制为2,因为在HotpotQA中回答问题最多需要2跳的推理步骤。在第一跳检索中,将段落数量设定为15个,对于每个段落,在第二轮中再检索3个段落,这样总共会产生45对段落。然后,根据第一跳和第二跳检索得分的乘积对这45个段落对进行排序,并选出前30个段落对作为最终上下文。
IRCoT没有直接使用原始的IR-CoT代码,而是根据问题设置对其进行了修改,用Chat-GPT代替了问题阅读器,对于推理步骤中使用的提示,选择了2个示例进行演示。根据从LLM中生成的推理及其文档页码反复选择前5个段落,并将它们添加到检索到的上下文中。这一块可以参照:https://arxiv.org/pdf/2212.10509.pdf
KGP-T5/LLaMA/MDR分别使用T5-large/LLaMA-7B/MDR作为引导图遍历的LM。对于基于内容的问题,与MDR类似,执行2跳检索,但在每一跳中,只从邻居候选节点中搜索下一个要访问的节点。在第1跳检索中,选择10个段落,在第2跳检索中,选择3个段落,总共形成30条推理路径。
在评估的指标计算上,计算F1和EM来比较LLM的答案和标准答案,对应的结果如下:
总结
本文主要介绍了LLM Visualization大模型网络结构可视化项目以及《Knowledge Graph Prompting for Multi-Document Question Answering》(地址:https://arxiv.org/pdf/2308.11730.pdf)的工作,该方法提出了一种知识图谱提示(KGP)方法,用于在多文档问题解答(MD-QA)中制定正确的LLM提示上下文,其本质上利用了知识图谱的图结构信息。
当然,这个又引来了另一个工作,那就是针对检索场景的prompt构造,我们可以明天再看看IR-CoT的工作。
参考文献
1、https://arxiv.org/pdf/2308.11730.pdf
2、https://bbycroft.net/llm
3、github.com/ZigeW/data_management_LLM
4、github.com/codefuse-ai/codefuse-devops-eval
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢