
【论文标题】MMFT-BERT: Multimodal Fusion Transformer with BERT Encodings for Visual Question Answering 【作者团队】Aisha Urooj Khan, Amir Mazaheri, Niels Da Vitoria Lobo, Mubarak Shah 【发表时间】2020/10/27 【论文链接】https://arxiv.org/pdf/2010.14095.pdf 【代码链接】 https://github.com/aurooj/MMFT-BERT
【推荐理由】本文收录于EMNLP2020 Findings。文章提出了MMFT-BERT(具有BERT编码的多模态融合transformer),用于解决视觉问答(VQA)问题,同时该模型能对多个输入模态进行单独和组合处理。
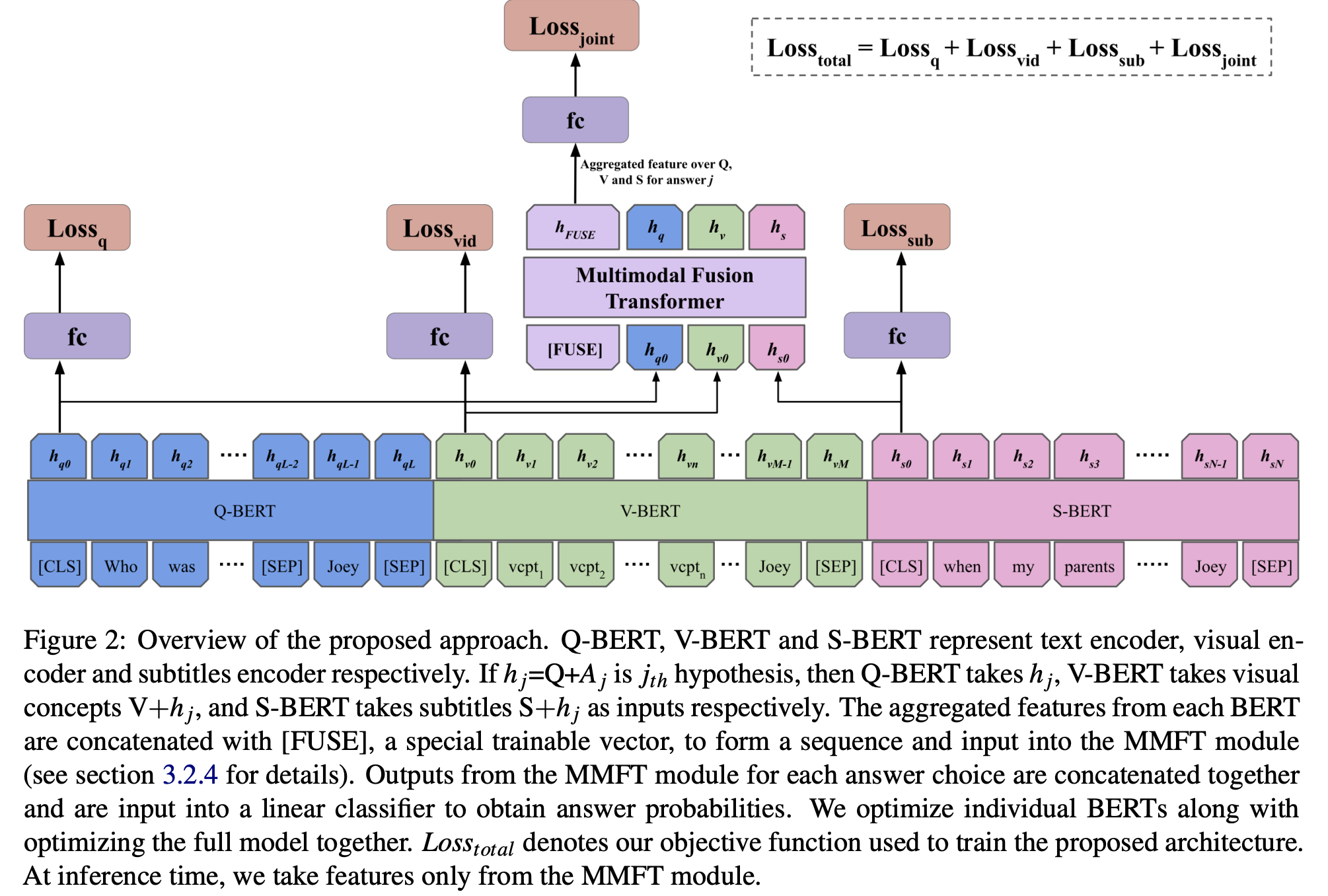
该模型得益于处理多模式数据(视频和文本)的过程,这些数据分别采用BERT编码,并使用基于Transformer的新颖融合方法将它们融合在一起。同时,将不同的模态源分解成不同的BERT实例,这些实例具有相似的架构,但是权值是可变的。最终模型在TVQA数据集上取得了SOTA效果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢