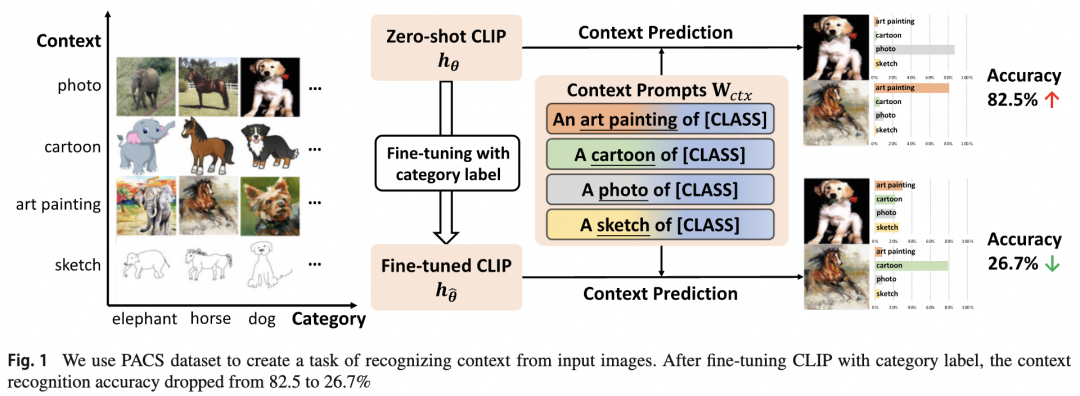
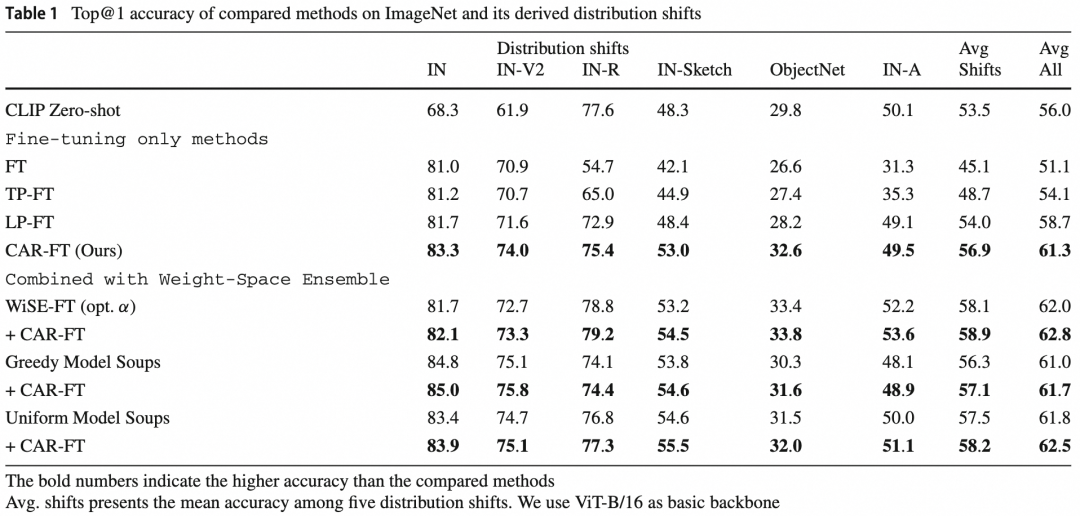
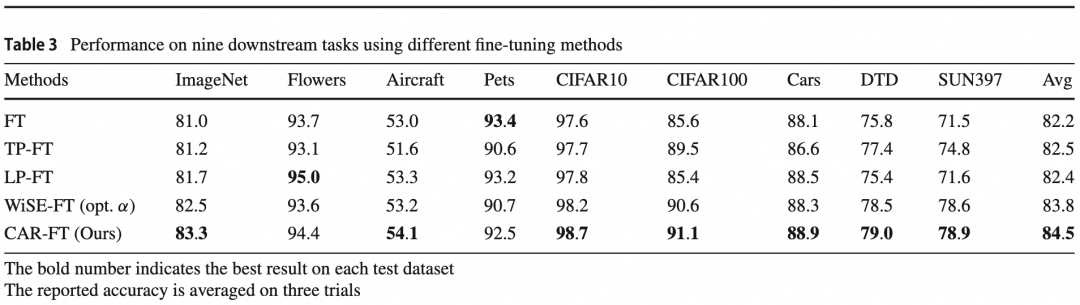
近日,AAIG产出的《基于上下文感知的鲁棒微调》论文被IJCV顶刊录用!IJCV(计算机视觉国际期刊) 一般刊登的是关于信息科学与工程领域以及广泛普遍关心的重大技术进步的文章。视觉AI近年涌现了对抗样本,分布外泛化性等多方面问题,为了构建安全可靠鲁棒的视觉智能,为业务保驾护航,AAIG一直致力于鲁棒视觉识别的研究和落地,近期提出的基于上下文感知的鲁棒微调,大幅提升了预训练模型在下游应用中的鲁棒性和泛化性。https://link.springer.com/article/10.1007/s11263-023-01951-2🎈什么是任务无关的图像上下文?其对视觉的识别影响如何?🎈预训练模型通过微调迁移到下游任务上,泛化性和鲁棒性发生什么变化?🎈如何更科学地微调预训练模型?将预训练模型的强大泛化能力无损的带到下游任务上?识别图像中的物体是人工智能领域老生常谈的话题,也是一个非常成熟的研究领域。现如今,封闭域上的视觉图像识别技术已经发展到很高的水平,媲美甚至超越人类水准。但在开放域上,视觉技术达到的效果还远未满足实际要求,视觉应用仅限于一些特定的场景(如人脸识别,证件照OCR等),一旦到更加复杂的环境下(如自动驾驶,智能机器人等)纯视觉的方案往往不够鲁棒。本文主要探讨在开放数据域下的图像分类泛化性和鲁棒性。在开放数据域下,与目标无关的图像上下文通常有很大变化,如图1,假设分类任务关注狗,马,船三类目标的识别,但是现实世界中狗可能处于复杂多变的环境下,如第一列所示:[沙滩上]的狗,[正在进食]的狗,[笼子里]的狗,[雪地里]的狗等等。这个例子中,[]里的描述即图像上下文,他们与任务无关,但会影响视觉识别的结果。早期的图像识别模型只关注任务相关的目标,并不学习图像包含的上下文信息,这导致模型对于图像上下文的泛化特别差。但随着图文对比学习技术的提出,如今的图像识别不仅可学到目标概念,还可从丰富的文本注释中学到图像上下文概念。例如首个图文对比预训练模型CLIP在PACS数据集上,不仅可以区分目标类别,还可以82.5%的准确率区分不同的图像上下文(图2)。图文对比学习预训练大大提升了模型在复杂上下文下的泛化性和鲁棒性,为开放域下的通用视觉识别提供了可能。图2. CLIP预训练模型微调前后上下文感知能力的变化即使CLIP针对复杂图像上下文有很好的鲁棒性,但其本质上还是通能模型,在特定任务上的效果很难与全监督训练的专业模型媲美。一种业界常用的方法是将CLIP通能模型通过下游有监督微调,迁移到特定任务上,这种预训练+微调的范式也是AI应用的标准流程。然而以往的研究表明,端到端的下游微调会破坏预训练模型表征的泛化性。这种泛化性的破坏一部分归因于微调前后CLIP对无关上下文感知能力的变化。如图2,微调前后CLIP模型对上下文感知的能力从82.5%降到了26.7%,说明传统的微调技术确实会损害上下文感知,间接的破坏泛化性。为了解决该问题,我们提出了一种新的微调方法,称为上下文感知的鲁棒微调(CAR-FT)。图3. 传统的微调方法和基于上下文感知的鲁棒微调(CAR-FT)方法对比在介绍方法之前,需要了解图文对比预训练模型在处理图像分类问题上的常见做法,分别是:零样本分类和下游微调分类。
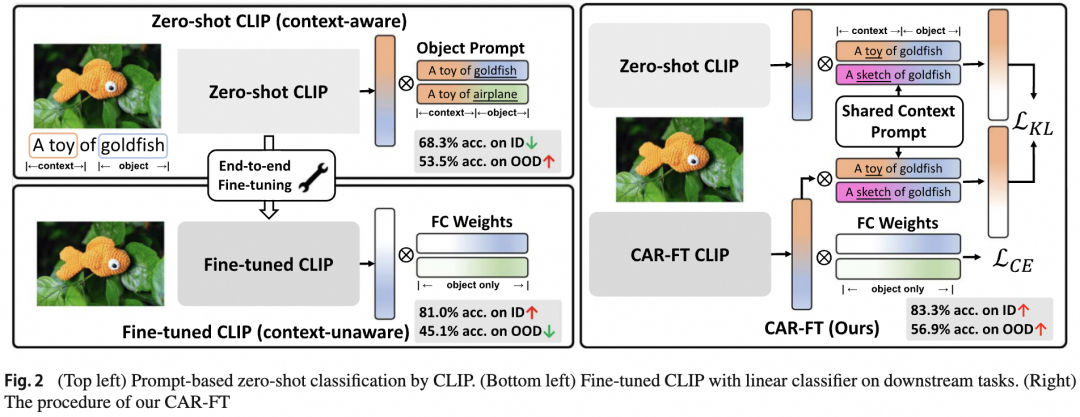
CLIP等图文对比预训练模型通常可通过构造prompt进行零样本分类,如图3左上,先定义分类任务中目标名词的描述,通过CLIP分别提取表征后,计算这些名词描述与图片的相似度,取最大相似度对应名词即为分类的结果。这个过程不需要构造训练样本以及额外微调CLIP模型,直接复用CLIP预训练参数即可,因此被称为零样本分类。CLIP-B零样本分类可在ImageNet测试集上取得68.3%的分类准确率,同时在复杂上下文的测试集上得到53.5%的泛化性。
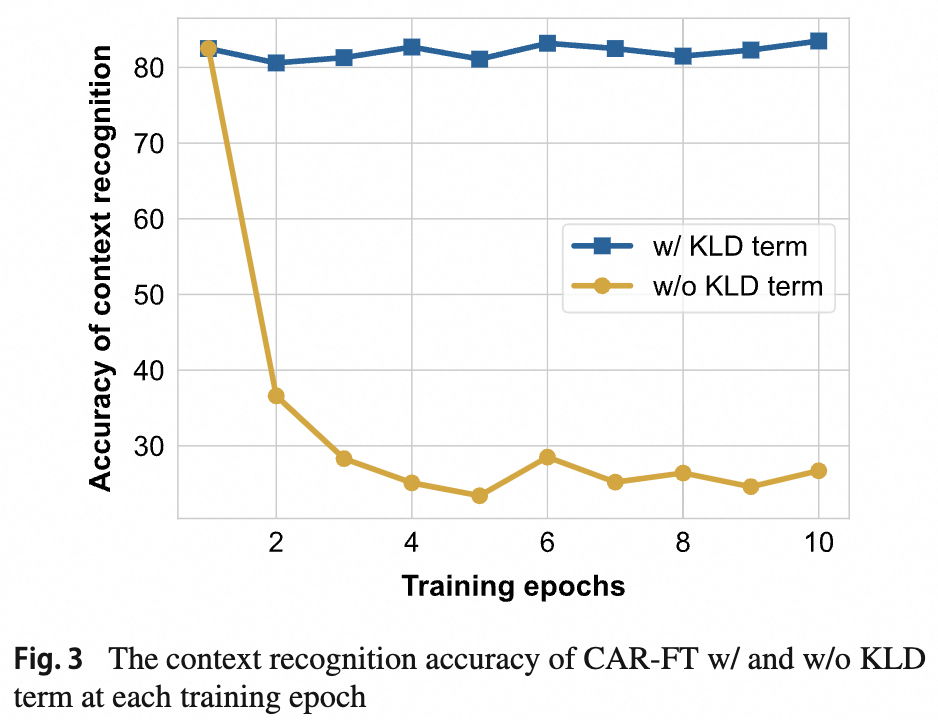
下游微调分类不利用图文对比的特性,而是直接用有监督数据微调参数。如图3右下,用ImageNet有监督数据端到端微调后,模型的分类准确率大幅上升到81.0%,但泛化性下降了。在背景中提到,下游微调后泛化性的降低一部分归因于微调后CLIP对无关上下文感知能力的下降,因此本文通过约束维持CLIP在下游微调过程中的上下文感知能力来间接的缓解泛化性下降。具体的,上下文感知的鲁棒微调(CAR-FT)首先会维护一份原始预训练参数的拷贝,同时构建一些预定义的上下文prompt,如[卡通]狗,[素描]狗,[玩具]狗等,[]中的内容即为图像上下文名词描述。在微调过程中,除了优化分类损失项外,还增加了一个上下文感知约束项。上下文感知约束项的计算需要训练图像首先通过原始预训练模型拷贝,以零样本分类的方式,求得图片和不同上下文prompt之间的相似度作为参考上下文概率分布,同样的方式经过微调模型后可得到预测上下文概率分布,通过在参考上下文概率分布和预测上下文概率分布间加KLD约束项,使得微调模型在优化分类的同时学习预训练模型的上下文感知能力。如图4,增加KLD约束项后,微调模型的上下文感知能力一直维持在较高水平,同时发现经过CAR-FT微调的模型在准确率和泛化性上同时得到了提升,在ImageNet上取得83.3%的准确率,以及56.9%的上下文泛化性。
其一, 本文经验性的探究了预训练模型的图像上下文感知能力,并发现微调后图像上下文感知能力的下降,间接的导致泛化性的下降。其二,提出了一种新的微调范式CAR-FT,通过使微调后的模型维持其上下文感知能力,同时提升微调后的准确率和泛化性。为了验证CAR-FT的通用性,实验选取了包括ImageNet在内的9个下游任务数据集进行对比,同时也在域泛化(Domain Generalization, DG)领域上验证了算法的先进性。在ImageNet数据集和5个复杂上下文测试集上,我们对比了包括传统微调(FT)在内的3种微调方法,并同时取得最高的准确率和泛化性。同时CAR-FT还可与WiSE-FT和Model Soups相结合,通过模型权重插值的方式进一步提升效果。除了大规模ImageNet分类任务,我们还在另外8个规模数据集上,如CIFAR-10等进行了对比,结果显示在多数场景下,CAR-FT优于之前的微调方法,取得更好的准确率。在域泛化任务上的效果验证,我们选取了DomainBed测试基准,其中包括PACS,VLCS,OfficeHome等5个数据集,并对比了之前的域泛化方法MIRO,EoA,DPL等,结果显示我们的方法在综合效果上取得了最先进的效果。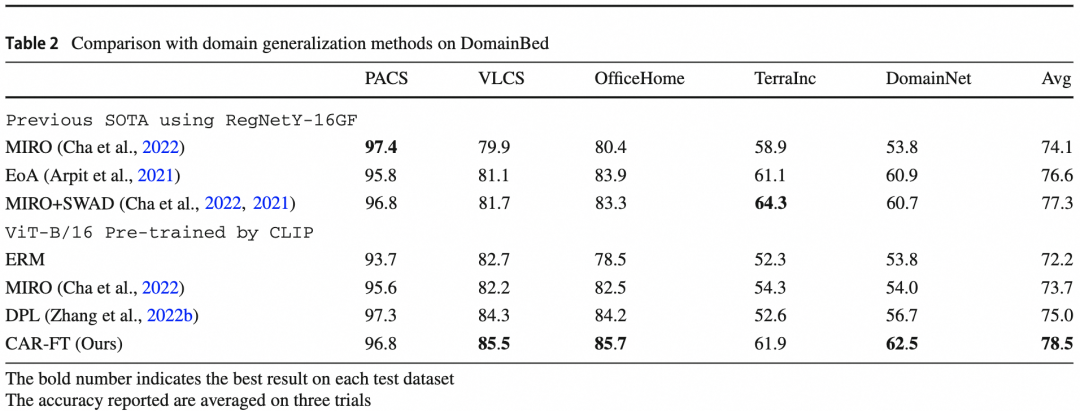
阿里巴巴人工智能治理与可持续发展研究中心近期在KDD、ICASSP、CVPR、SIGIR、ICCV、TPAMI等等顶会上有诸多斩获,本公众号将持续更新录用论文,也欢迎各位更多同学、专家加入我们或一起合作共创,共同在攀登科技高峰的征程上,不断获得原创性突破、创新性成果💪
📖2023生成式人工智能治理系列丛书
内容中包含的图片若涉及版权问题,请及时与我们联系删除














评论
沙发等你来抢