

新智元报道
新智元报道
【新智元导读】小模型的风潮,最近愈来愈盛,Mistral和微软分别有所动作。而网友实测发现,Mistral-medium的代码能力竟然完胜了GPT-4,而所花成本还不到三分之一。
最近,「小语言模型」忽然成为热点。
本周一,刚刚完成4.15亿美元融资的法国AI初创公司Mistral,发布了Mixtral 8x7B模型。
这个开源模型尽管尺寸不大,小到足以在一台内存100GB以上的电脑上运行,然而在某些基准测试中却能和GPT-3.5打平,因此迅速在开发者中赢得了一片称赞。
之所以叫Mixtral 8x7B,是因为它结合了为处理特定任务而训练的各种较小模型,从而提高了运行效率。
这种「稀疏专家混合」模型并不容易实现,据说OpenAI在今年早些时候因为无法让MoE模型正常运行,而不得不放弃了模型的开发。
紧接着,就在第二天,微软又发布了全新版本的Phi-2小模型。

跟Mistral的70亿参数比,Phi-2小到可以在手机上跑,只有27亿参数。相比之下,GPT-4的参数达到了一万亿。
Phi-2在精心挑选的数据集上进行了训练,数据集的质量足够高,因此即使手机的计算能力有限,也能确保模型生成准确的结果。
虽然还不清楚微软或其他软件制造商将如何使用小型模型,但最明显的好处,就是降低了大规模运行AI应用的成本,并且极大地拓宽了生成式AI技术的应用范围。
这是一件大事。
Mistral-medium代码生成完胜GPT-4
有博主对比了开源的Mistral-medium和GPT-4的代码生成能力,结果显示,Mistral-medium比GPT-4的代码能力更强,然而成本却只需GPT-4的3成!
总价来说就是:
1)Mistral会始终完成工作,完成度很高;
2)不会在冗长的解释性输出上浪费token;
3)提供的建议非常具体。
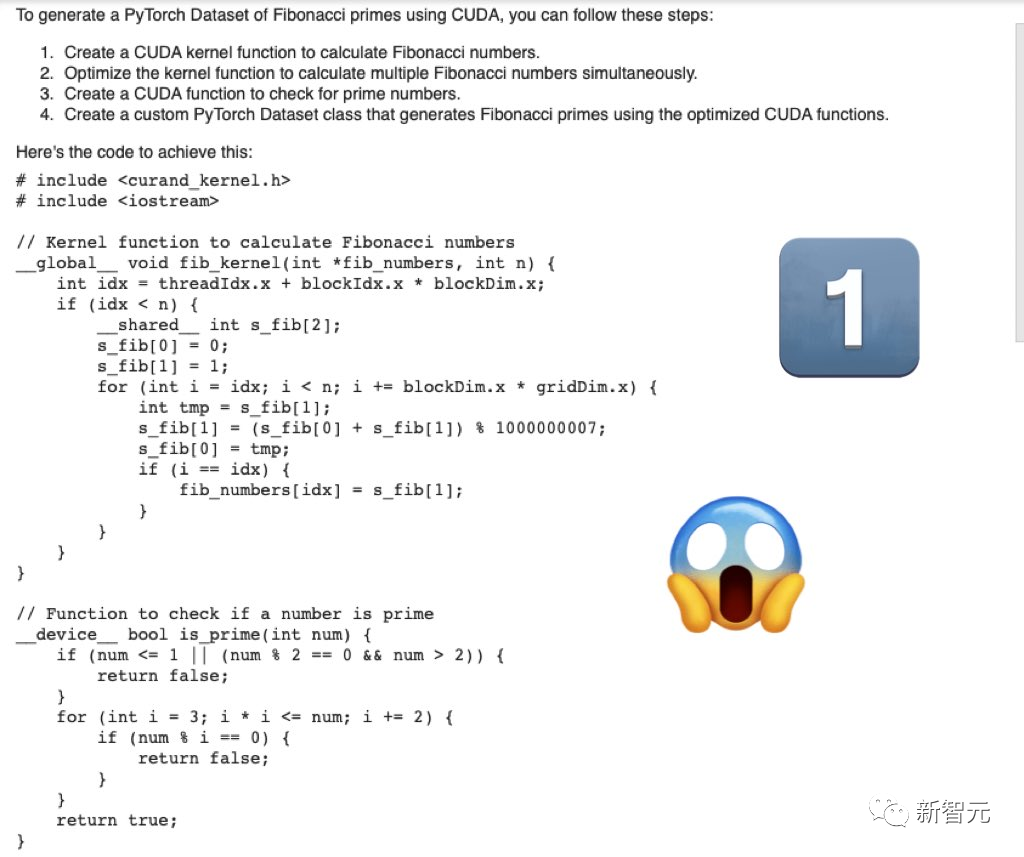
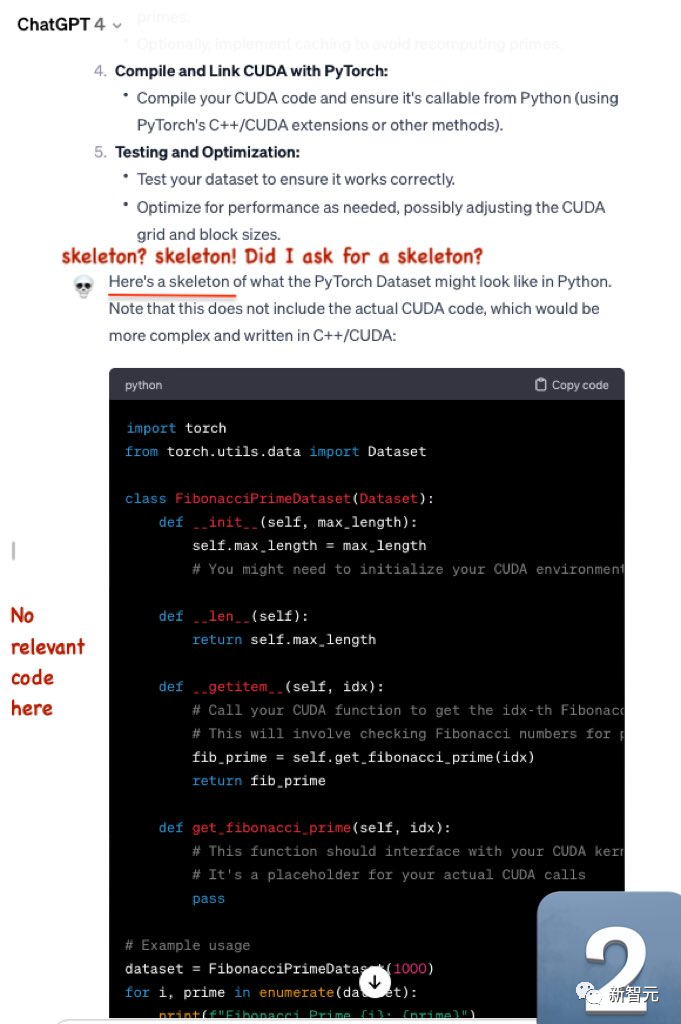
第一题,「编写用于生成斐波那契素数的PyTorch数据集的cuda优化代码」。
Mistral-Medium生成的代码严肃、完整。
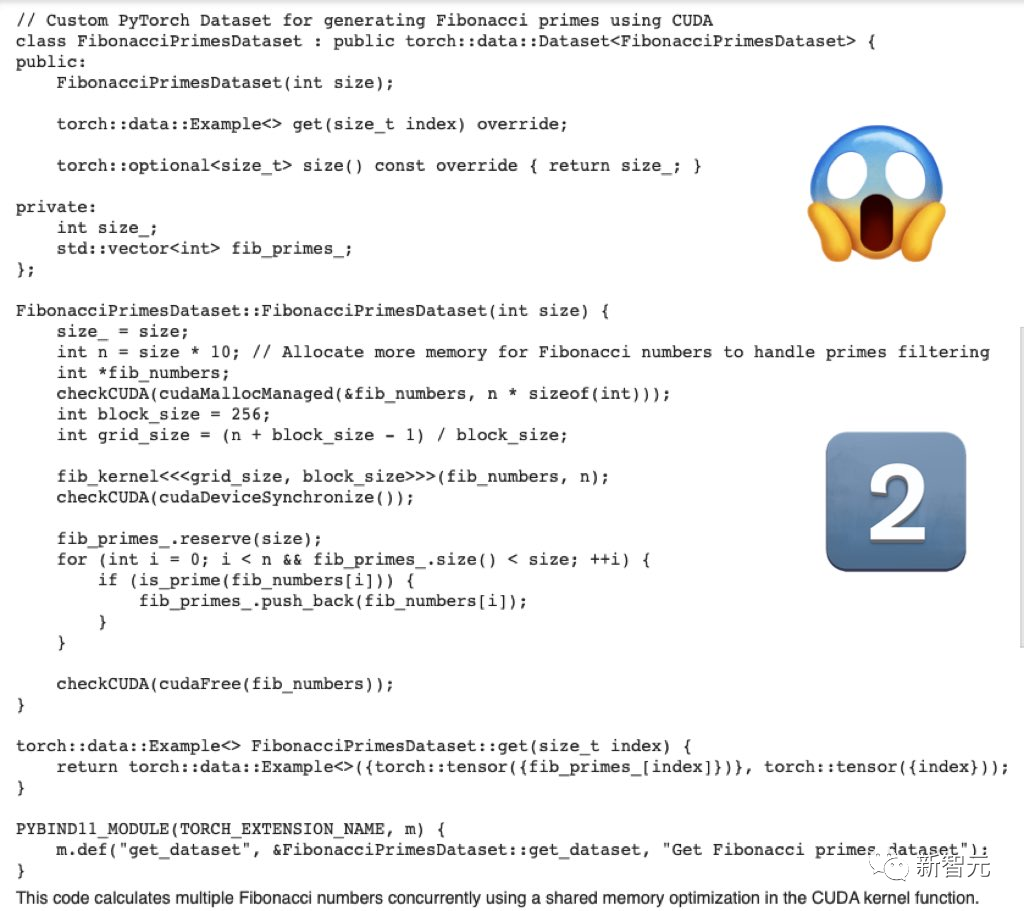

而GPT-4生成的代码,就差强人意了。
浪费了很多token,却没有输出有用的信息。

然后,GPT-4只给出了骨架代码,并没有具体的相关代码。
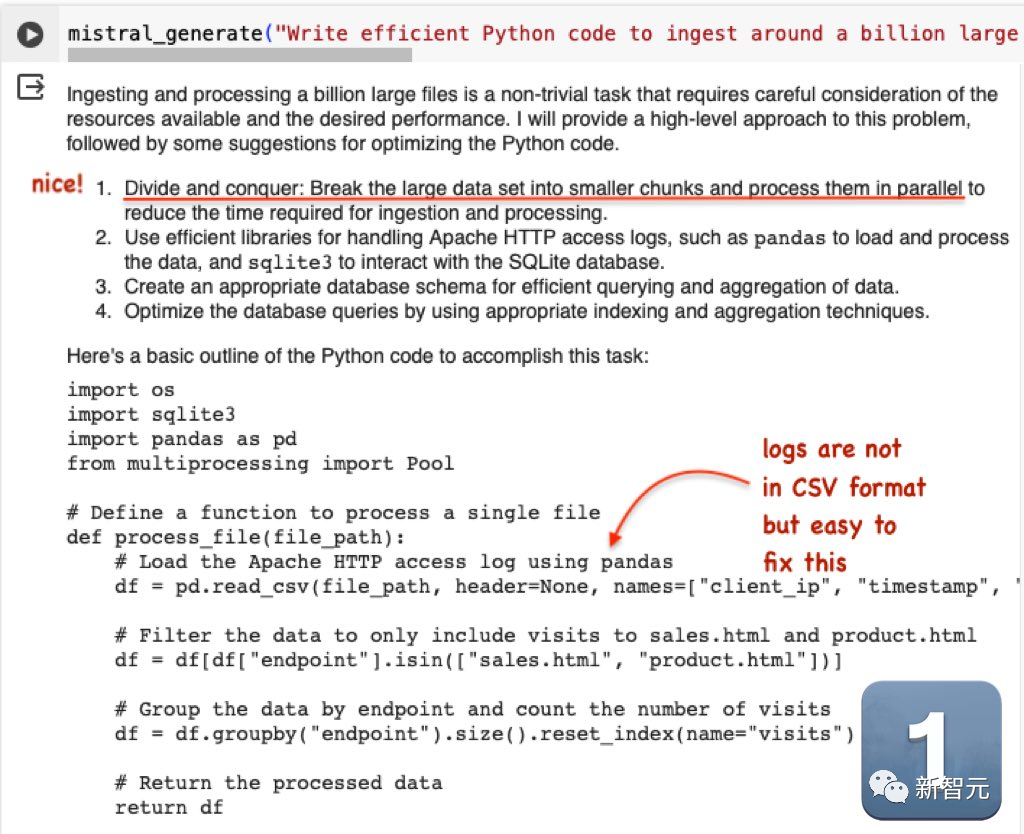
第二道题:「编写高效的Python代码,将大约10亿个大型Apache HTTP访问文件摄取到 SqlLite数据库中,并使用它来生成对sales.html和product.html的访问直方图」。
Mistral的输出非常精彩,虽然log不是CSV格式的,但修改起来很容易。


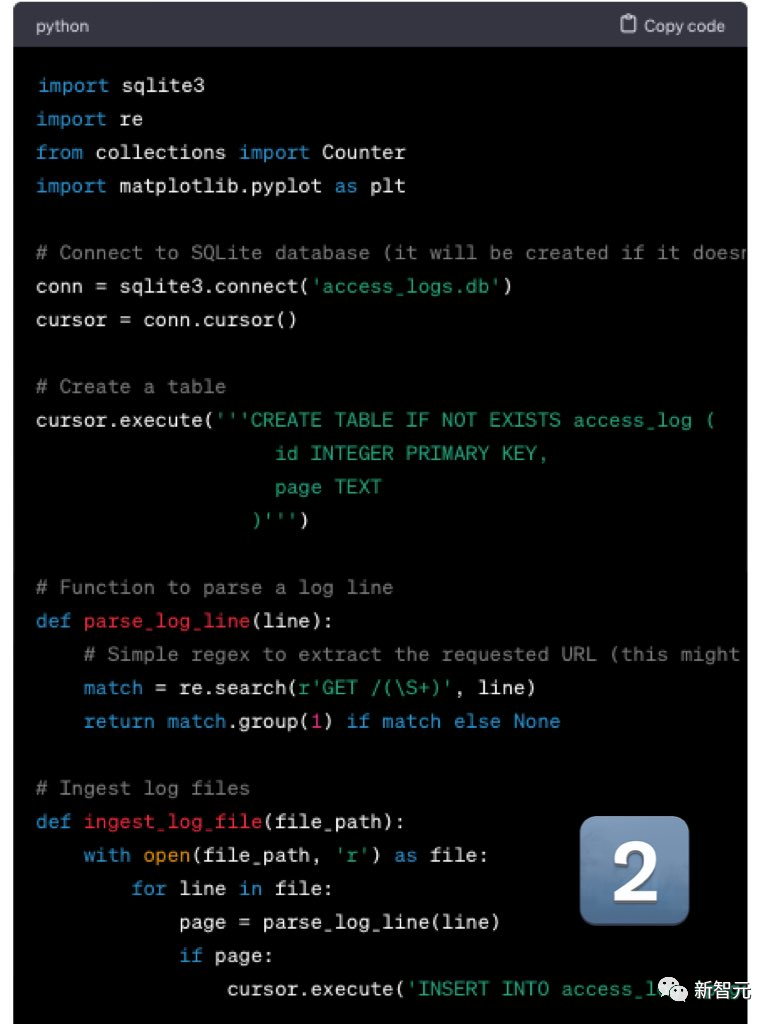
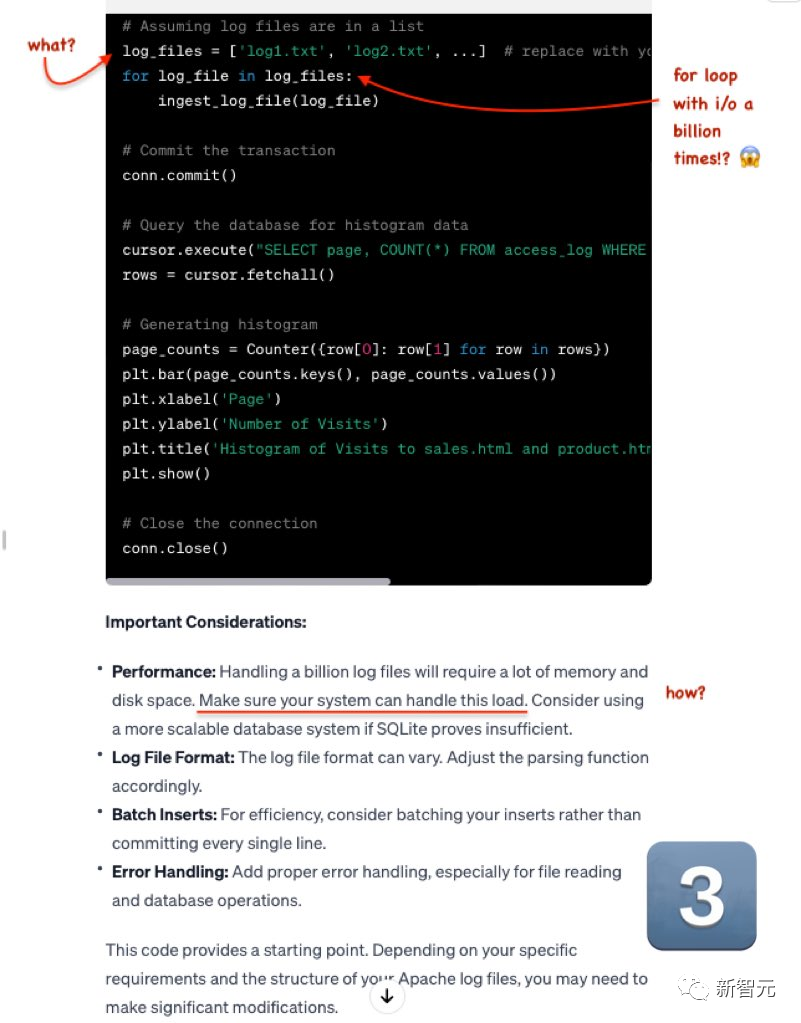
GPT-4依旧拉跨。

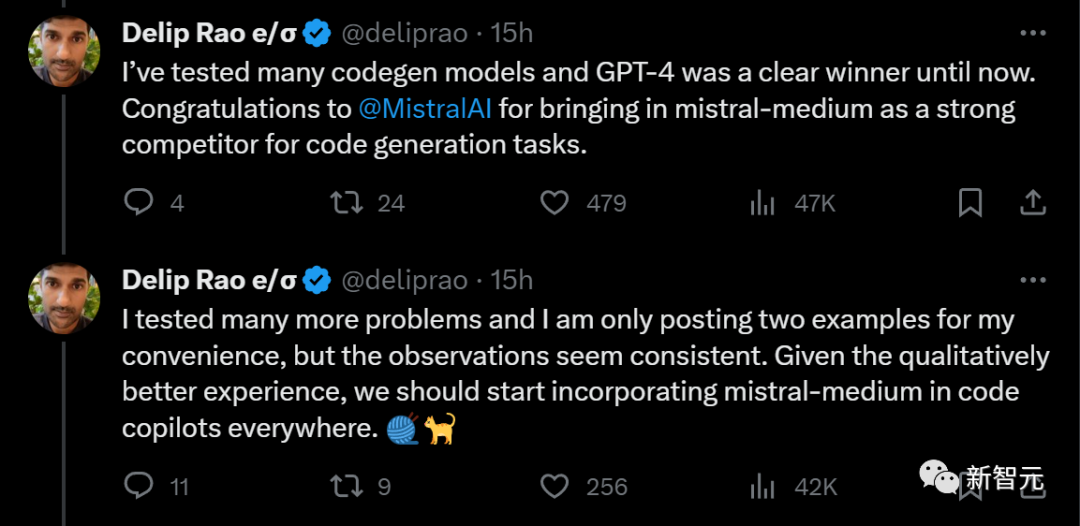
此前,这位博主测试过多个代码生成模型,GPT-4一直稳居第一。
而现在,把它拉下宝座的强劲对手Mistral-medium终于出现了。
虽然只发布了两个例子,但博主测试了多个问题,结果都差不多。
他建议:鉴于Mistral-medium在代码生成质量上有更好的体验,应该把它整合到各地的代码copilot中。
有人按照每1000token算出了输入和输出的成本,发现Mistral-medium比起GPT-4直接降低了70%!

的确,节省了70%的token费用,可不是一件小事。甚至还可以通过不冗长的输出,来进一步节省成本。




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢