

<section data-tool="mdnice编辑器" data-website="https://www.mdnice.com" style="font-size: 16px;color: black;padding-right: 10px;padding-left: 10px;line-height: 1.6;letter-spacing: 0px;word-break: break-word;text-align: left;counter-reset: counterh1 0 counterh2 0 counterh3 0;font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, " pingfang="" sc",="" cambria,="" cochin,="" georgia,="" times,="" "times="" new="" roman",="" serif;"="">
今天给大家分享的是ICLR 2024投稿论文:"NExT-GPT: ANY-TO-ANY MULTIMODAL LLM"。什么是人类级AI?作者认为,能够像人类一样感知多模态信息,并通过推断和决策输出多模态信息,是人类级AI需要具备的能力。尽管近段时间多模态大语言模型(MM-LLMs)取得了较大进展,但它们大多仅在输入端以多模态输入内容,却无法在输出端以多模态生成内容。因此,本文提出了一种任意多模态语言模型框架NExT-GPT,能够接受和生成文本、图像、视频和音频等多种模态的内容,为实现人类级AI提供可能。
Part1
尽管近段时间多模态大语言模型(MM-LLMs)取得了较大进展,但它们大多仅在输入端以多模态输入内容,却无法在输出端以多模态生成内容。为了填补这一空白,本文提出了一种任意多模态语言模型框架NExT-GPT,能够接受和生成文本、图像、视频和音频等多种模态的内容。通过连接已经训练好的编码器和解码器,NExT-GPT只需对某些投影层进行少量参数(1%)的调整即可,这不仅有利于降低训练成本,还能方便地扩展到更多潜在模态。此外,本文还引入了模态切换指令调整(MosIT)和高质量数据集,使NExT-GPT具备复杂的跨模态语义理解和内容生成能力。本文的研究展示了构建能够建模通用模态的统一人工智能Agent的潜力,为实现更接近人类的人工智能研究提供可能。
Part2
NExT-GPT的模型框架如下:
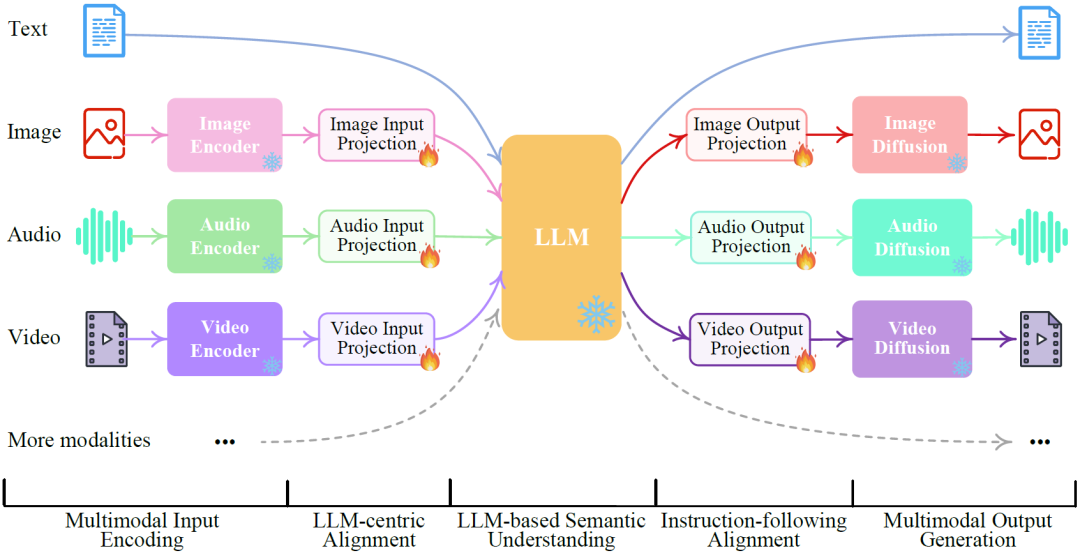
如图所示,多模态的Encoder、Decoder模块,及核心的LLM模块均采用现有的开源模型并将其冻结。此外,作者为每一个模态设置了对应的投影层(Projection),并训练该投影层。 上述轻量级对齐技术旨在在模型内部获得较好的多模态表示。对于本文提出的NExT-GPT模型,作者希望其能忠实地遵循和理解用户的指令并生成所需的多模态输出。因此,作者采用指令调优方法达到上述目的。具体而言,作者首先通过真实的问答过程,构建5K条真实的高质量的多模态输入输出数据集MosIT。接着,对于用户每一次的输入指令,将LLM生产的输出和真实注释计算损失,并采用基于LoRA的方法更新LLM参数。此外,对于解码端投影层,作者在此阶段也进行微调:将Projection层投影的X模态指令和真实描述生成的指令计算损失。
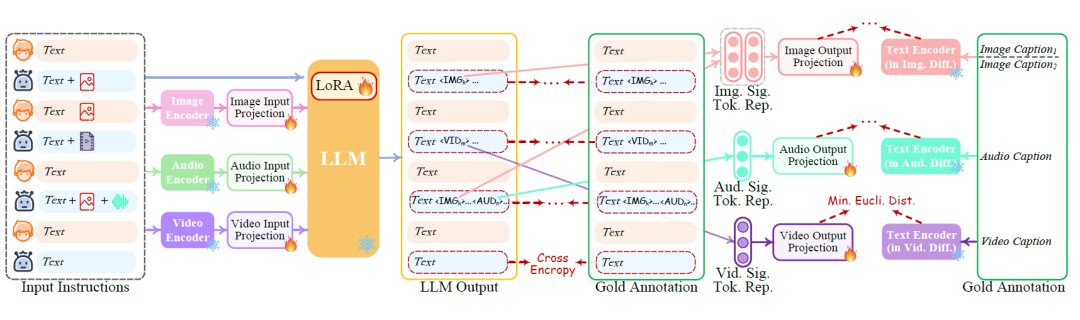
Part3
针对多模态的输入输出,作者在三个任务上进行实验。

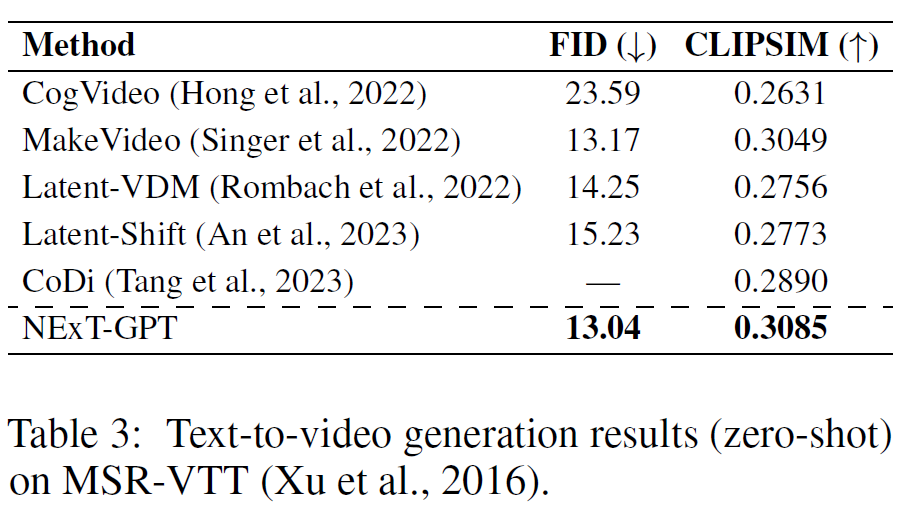
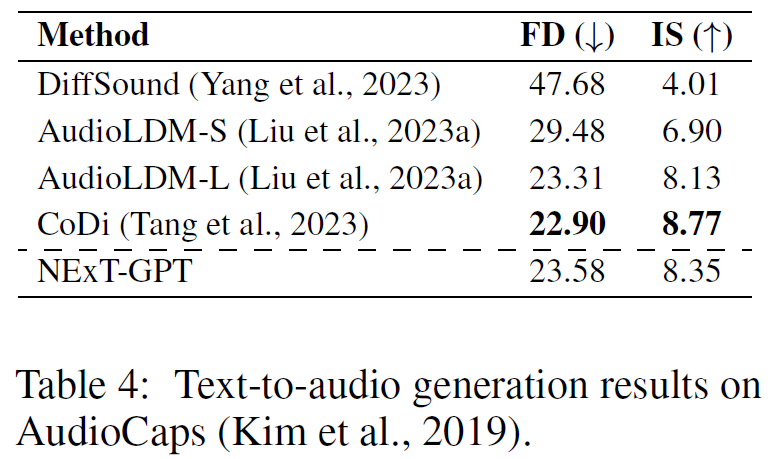
FID表示生成图像与真实图像的距离(↓);CLIPSIM代表生成视频和文本描述的相似性(↑);FD代表生成音频与参考音频的距离(↓);IS:生成音频的清晰度和多样性(↑)。结果表明,NExT-GPT在文本到X模态的生成任务上具有较优效果。
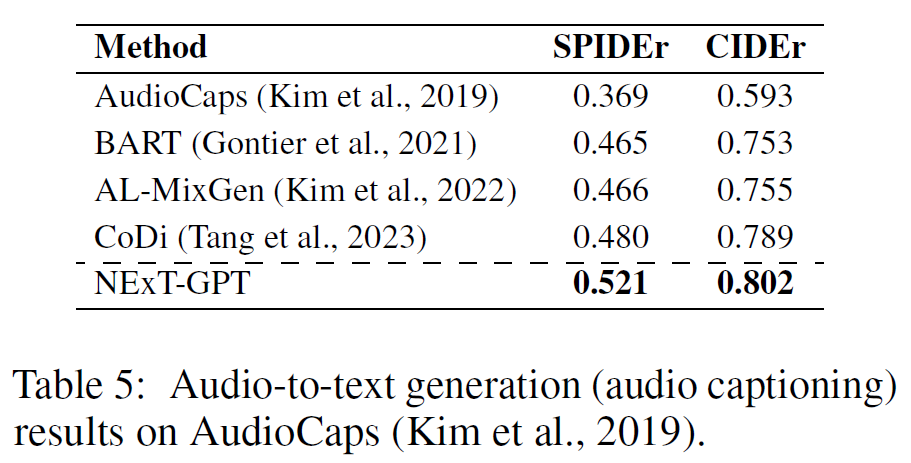
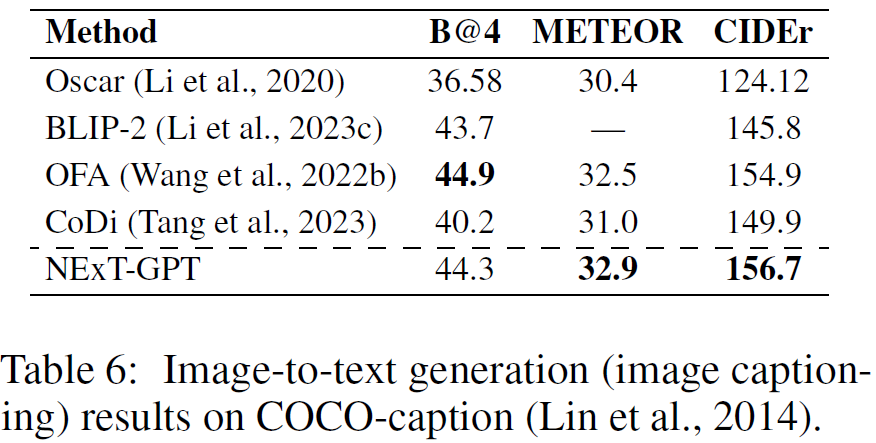
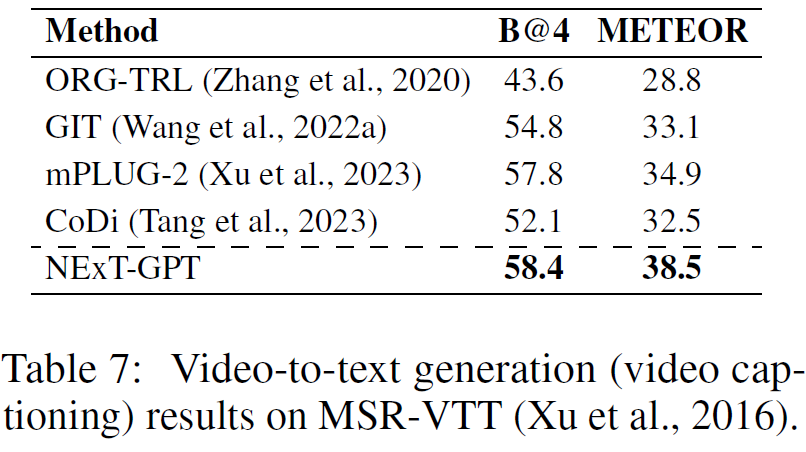
SPIDEr, CIDEr, B@4, METEOR均表示生成句子与参考句子的相似度(↑)。结果表明,NExT-GPT在X模态到文本的生成任务上具有较优效果。
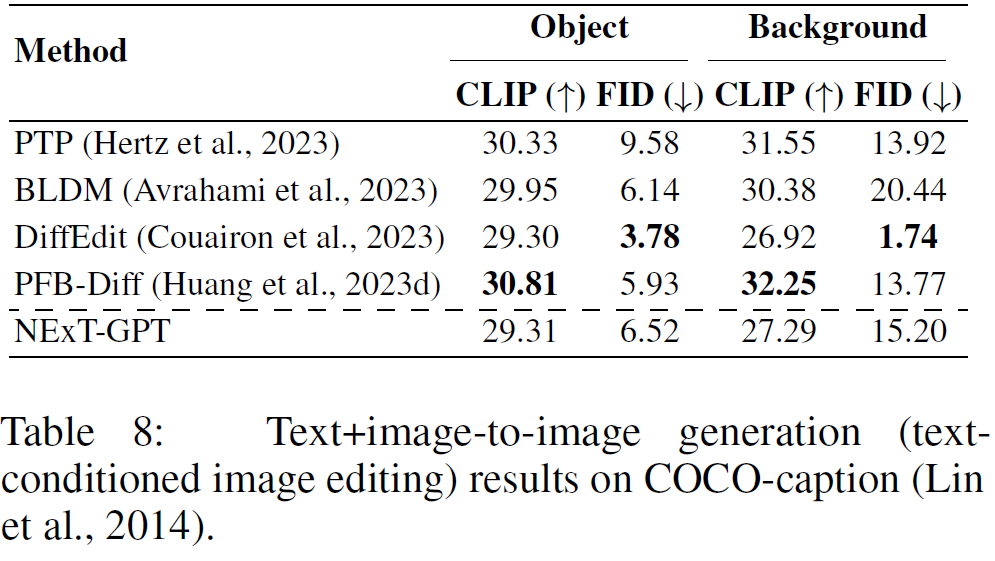
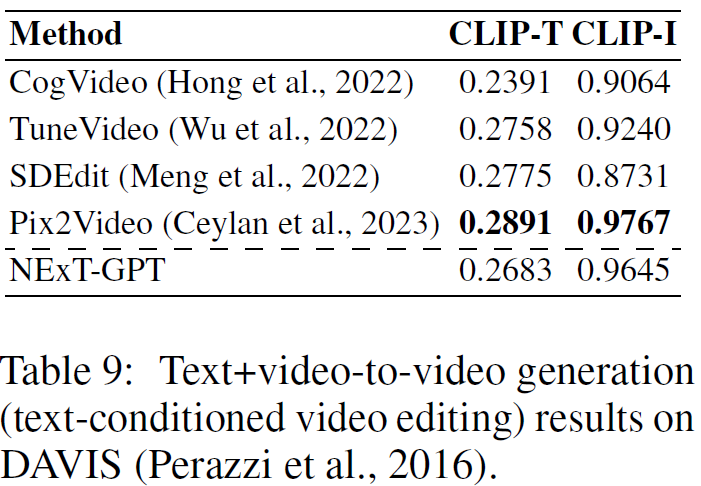
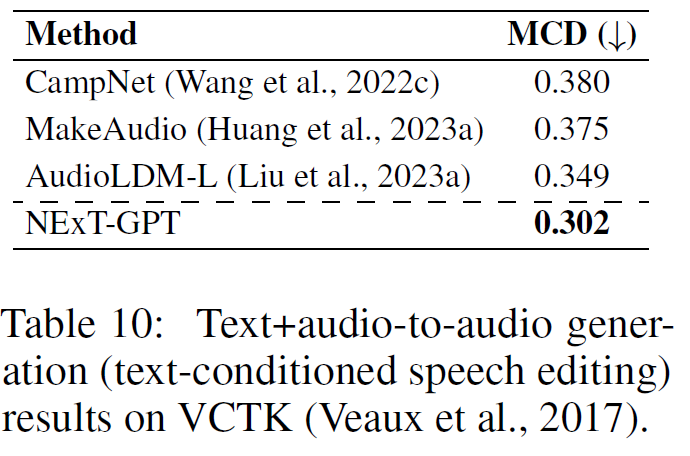
CLIP, CLIP -T代表生成图像与文本描述的相似性(↑);CLIP -I代表生成图像与参考图像的相似性(↑);MCD代表生成语音和参考语音之间的距离(↓)。结果表明,NExT-GPT在X模态到文本的生成任务上具有较优效果。
Part4
本文介绍了一种全能的任意多模态大语言模型NExT-GPT,能够理解和生成文本、图像、视频和音频等多种输入输出组合。作者在该模型中引入了轻量级对齐学习技术,实现了有效的语义对齐。此外,作者还提供了高质量的多模态指令调整数据集MosIT,帮助模型实现人类般的跨模态内容理解和指令推理。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢