
点击下方卡片,关注「集智书童」公众号

学习不同人脸的判别性特征是面识别的重要任务。通过在神经网络中提取人脸特征,可以轻松地衡量不同人脸图像的相似性,从而实现面识别。为了增强神经网络的人脸特征可分性,在训练过程中引入角边界是一种常见做法。
最先进的损失函数CosFace和ArcFace在类别权重之间引入固定边界,以增强人脸特征的类别间分离。由于训练集中样本分布不平衡,不同身份之间的相似性不相等。因此,使用不适当的固定角边界可能导致模型难以收敛或人脸特征不够判别。更符合作者的直觉的是,边界是角自适应的,随着类别间角度的增大而增大。
在本论文中,作者提出了一种名为X2-Softmax的新角边界损失。X2-Softmax损失具有自适应角边界,为不同类别间角度增大的情况下提供增大的角边界。角自适应边界确保模型灵活性,并有效提高了面识别效果。作者在MS1Mv3数据集上使用X2-Softmax损失训练神经网络,并在多个评估基准测试上进行测试,以证明作者损失函数的有效性和优越性。
实验代码和训练好的模型:https://github.com/xujiamu123/X2-Softmax/tree/main
人脸识别在需要身份验证的情况下得到了广泛应用,例如访问控制管理和应用验证服务。
人脸识别有四个步骤:人脸检测、人脸对齐、人脸特征提取和特征比较。人脸特征提取是面识别过程中最重要的任务之一。为了提高面识别的准确性,有必要增强模型提取判别性人脸特征的能力。
提取人脸特征的损失函数通常可以分为两类。一类是成对损失(例如对比损失,三元损失,N对损失),另一类是基于分类的损失(例如softmax损失,CosFace,ArcFace)。然而,使用成对损失进行训练,随着训练数据集中样本对数增加,计算时间将显著增加,冗余样本对可能导致模型缓慢收敛和退化。
softmax损失函数在分类任务中通常被使用,面识别也可以被视为一种分类任务。然而,使用softmax损失提取的人脸特征对于开放的集合面识别问题并不具有足够的判别性。为了增强同一类别内的紧凑性和不同类别间的分离,人们将不同的固定角边界引入softmax损失,如CosFace和ArcFace。虽然人脸特征变得更具有判别性,但选择最优角边界成为了一个新的问题。
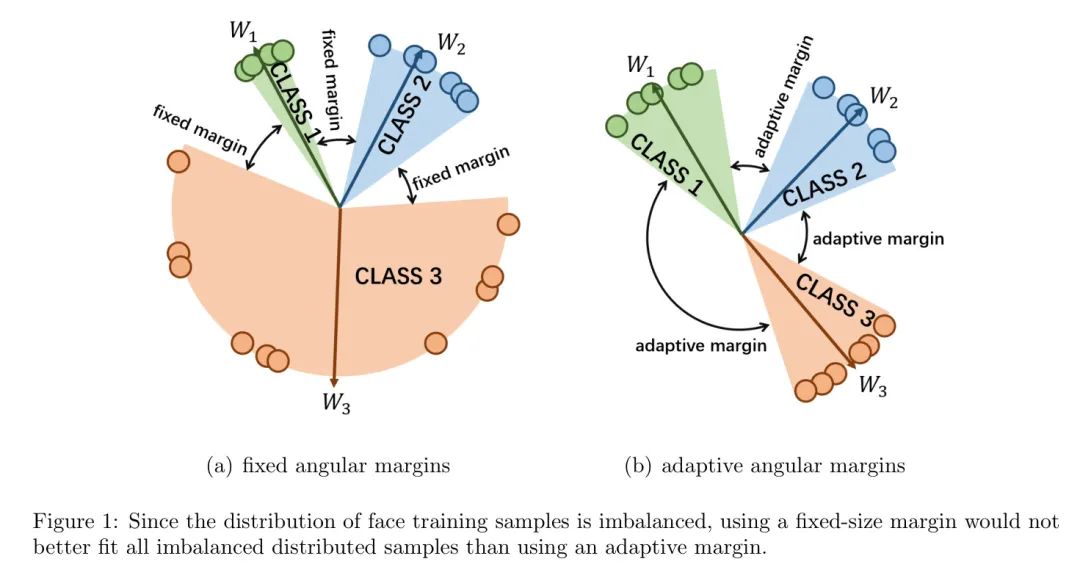
如图1(a)所示,由于训练集中样本分布不均匀,在类别之间添加固定角边界并不合适。如果固定角边界过大,模型将难以收敛。相反,如果固定角边界过小,其对特征分离的贡献最小。此外,使用固定角边界进行训练可能会导致神经网络过拟合。
从实际的角度来看,作者希望边界是自适应的,能够随着不同类别之间的角度变化改变其大小,如图1(b)所示。对于角度较大的两个类别,作者希望它们具有较大的边界,以促进同一类别内紧凑性的增强。对于角度较小的两个类别,作者希望一个适当的边界,它可以增加不同类别间的分离,同时不会使模型难以收敛。
近年来,也有几种具有自适应角边界的损失函数,用于增强提取的人脸特征的同一类别内紧凑性和不同类别间分离。然而,Dyn-ArcFace在最近邻类别之间的距离计算动态角边界。当两个类别之间的距离较小时,Dyn-ArcFace中的角边界将变得很小,对于这些类别与其他类别之间的距离较大的类别几乎没有影响。MagFace中的角边界与特征模块相关,而不是类别间的相似性。它仍然没有解决类别间角度较大时应设置较大边界的这个问题。
在本文中,作者提出了X2-Softmax损失,用二次函数替换了ArcFace损失中的余弦函数。由于X2-Softmax损失是边际自适应的,它可以自动调整不同类别间权重之间的角度来调整角边界。为了证明作者X2-Softmax损失的有效性和优越性,作者在八个不同的测试基准上进行了测试,并将结果与其他损失函数进行了比较。从实验结果来看,X2-Softmax损失在大多数基准上实现了有前景和竞争力的结果。
总之,本文的主要贡献可以总结如下:
本文提出了一种名为X2-Softmax的损失函数。为了解决现有损失函数难以选择理想固定角边界的问题,作者提出了一种自适应角边界损失函数用于人脸识别。与传统损失函数不同,X2-Softmax损失函数具有自适应角边界,可以避免选择一个合适的固定角边界来容纳不同类别分布的差异。
作者将X2-Softmax损失函数在八个不同的测试基准上进行了测试,并获得了有前途的结果,这证明了其有效性和优越性。实验结果表明,X2-Softmax损失函数获得了具有竞争力的性能。
本文的结构如下。在第2节,作者介绍了关于损失函数的现有相关工作。在第3节,作者提出了作者的X2-Softmax损失函数。在第4节,作者介绍了作者的实验设置和实验结果。在第5节,作者将讨论获得的成果并得出结论。
目前,人脸特征提取的主要损失函数有两个方向。一个是成对损失,另一个是基于分类的损失。
基于成对的损失函数直接通过使用样本对来学习人脸特征。对比损失是最直接的一种基于成对的损失函数。它通过确保正样本之间的欧几里得距离小于固定边界来将人脸特征映射到欧几里得空间。类似地,余弦对比损失通过强制样本对之间的余弦距离而不是欧几里得距离来映射人脸特征。三元组损失使用三对 Anchor 样本、其正样本和负样本进行训练。Anchor 样本和其负样本之间的欧几里得距离被强制大于其正样本到 Anchor 点的距离。三元中心损失考虑了 Anchor 点到正类中心和负类中心的欧几里得距离而不是正样本和负样本。
Sohn提出了N对损失来解决收敛速度慢的问题,通过同时学习N-1个负样本。基于成对的损失函数直接将人脸特征嵌入到特征空间中,通过样本对来增强同一类别内紧凑性和不同类别间分离。然而,随着训练集中图像数量的增长,计算时间将显著增加,同时挖掘半硬对变得更困难。此外,用于训练的样本对的选择会影响模型训练的结果。随机取样可能导致大量的冗余训练对,这会导致在训练过程中收敛速度较慢和模型退化,从而进一步降低训练效率。
与成对损失函数不同,基于分类的损失函数通过实现分类任务来提取人脸特征。基于分类的损失函数不会遇到训练数据随着训练集中图像数量的增长而爆炸式增长的问题。softmax损失是一种典型的基于分类的损失函数,广泛用于分类任务。面识别任务也可以被视为一个分类问题,因此softmax损失也常用于面识别。作为最简单的基于分类的损失函数,softmax损失可以压缩同一类别的人脸特征,同时分离不同类别的人脸特征,同时完成分类任务。由于softmax损失并不直接优化人脸特征的提取,因此在面对开放的集合面识别问题时其精度并不足够。为了提高面识别的准确性,一些基于softmax损失的损失函数被衍生出来。
L-Softmax和SphereFace(A-Softmax)通过在softmax损失函数的基础上添加乘法角边界,促进了生成具有较大类间变异的特征。不同之处在于SphereFace同时对最后一层全连接层的权重进行归一化,使得基于角度的分类代替了向量内积的分类。由L-Softmax和SphereFace表示的乘法角边界损失具有陡峭的目标对数曲线,难以收敛,并增加了模型训练的难度。通过归一化权重和面特征,Wang等人提出NormFace以缓解数据不平衡,并直接优化余弦相似度。
AM-Softmax和CosFace提出在余弦空间中添加固定角边界,使得面特征变得更具判别性。与CosFace不同,ArcFace在角空间中添加固定角边界,而不是在余弦空间中。然而,固定角边界的损失训练也存在一些问题。固定角边界决定了神经网络的准确性,但选择理想固定边界的任务并不容易。此外,对于某些类别来说,适合的固定边界对于其他类别来说可能过大或过小,无法收敛。由于训练样本不同类别之间的面特征相似度不一致,因此将具有不同相似度的类别之间的相同角边界添加以增强同一类别内紧凑性和不同类别间分离是不合理的。
Dyn-ArcFace[31]添加了一个动态角边界,它由最近邻类之间的类中心距离确定。作者通过实验证明了动态角边界可以减少训练过程中过拟合的程度。MagFace[34]添加了一个与面部特征模块相关的动态角边界,可以防止模型过拟合噪声和低质量样本。在ElasticFace[38]中,作者认为使用固定边界限制了训练面部识别模型的灵活性。因此,ElasticFace使用动态角边界,这些边界来自高斯分布而不是CosFace和ArcFace损失中的固定边界。ElasticFace+,是ElasticFace的扩展,也提到了它,它根据样本与其他类中心之间的距离将生成的随机边界进行分配。然而,Dyn-ArcFace的动态角边界依赖于最近邻类之间的类中心距离,这限制了增强其他类别间面特征分离的边界大小。MagFace中的角边界由特征模块确定,但仍然没有解决设置较大角边界以增强类别间角度的灵活性问题。在ElasticFace中生成随机值意味着生成的边界可能是冗余的,这会导致不必要的计算。通过排序避免冗余边界生成的ElasticFace+,然而,作者在他们的论文中表明,由于排序边界的训练计算增加太大而无法容忍。
在本文中提出的X2-Softmax损失函数并没有使用固定边界,而是使用该函数本身来获得两个类别权重之间的不同角度边界。这种方法可以绕过在样本分布本身不均匀的情况下选择固定边界的难题。
在本节中,作者将介绍作者的损失函数X2-Softmax,通过其边际自适应性来提高面识别的准确性。
CosFace和ArcFace分别应用了固定角边界在余弦空间和角度空间中,基于softmax损失函数。这两种损失函数可以表示为类似的公式如下:
在式(1)中,CosFace和ArcFace之间的区别在于对数函数。在CosFace中,对数函数如下:
在ArcFace中,对数函数如下:
对于上述公式2和公式3,是损失函数的超参数,它表示余弦空间和角度空间中的边界。
对于简单的二分类问题中的CosFace,假设面特征属于第一类。如果,则将被正确分类为第一类。如果,将被错误分类为第二类。因此,CosFace的决定边界为。对于ArcFace,当时,将被分类为第一类。当时,将被分类为第二类。因此,ArcFace的决定边界为。如果面特征属于第二类,CosFace和ArcFace的决定边界分别为和。由于CosFace和ArcFace的决定边界不重叠,因此存在类别间的角边界,这确保了面特征的类别间分离。上述损失函数的角边界如图2所示。
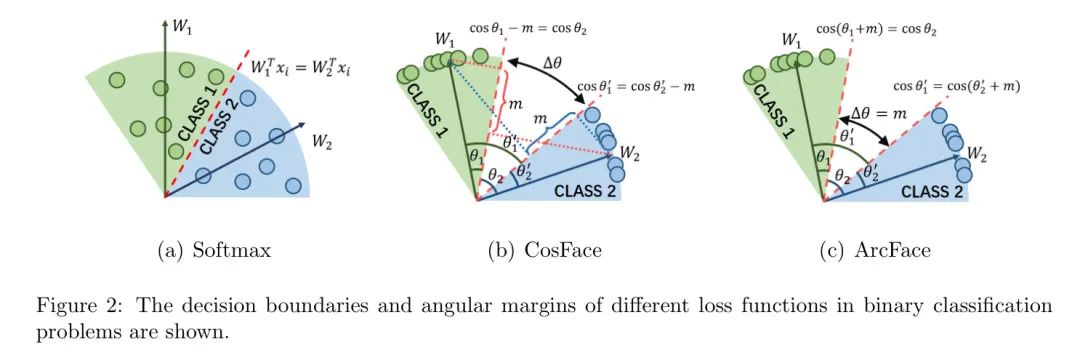
对于softmax损失,由于其角边界为零,因为无论属于哪个类别,决策边界始终为。
对于CosFace,如图2(b)所示,作者已知,和。因此,作者也可以知道和。由于和,作者得到和决策边界之间的间隔。
对于ArcFace,角边界。显然,ArcFace的损失函数超参数决定了固定的角边界。损失函数对对数函数的不同导致不同的角边界。
从前面的部分可以看出,类别间的角边界会影响特征提取。在本论文中,作者提出X2-Softmax损失,它是边际自适应的。
在作者的X2-Softmax损失中,对数函数如下:
在作者的X2-Softmax损失中,,,是超参数。和决定了对数函数曲线顶点的位置,而决定了曲线的开口方向和聚集程度。
余弦函数通常作为传统损失中的对数函数,例如CosFace和ArcFace。事实上,余弦函数的泰勒展开式为:
因此,将对数函数转换为二次函数是一个自然的选择。忽略的高阶项并保留常数和二次项可以避免模型过拟合,同时减少计算量。通过添加一个主项并改变对数函数的参数,可以使边距更具角度自适应性,允许对数曲线有更丰富的调整选项,从而可能增强面特征的同一类别内紧凑性和不同类别间分离。
由于对数函数是二次函数,作者称之为X2-Softmax。X2-Softmax损失函数不使用固定角边界,这使得在面临不同样本分布不平衡的情况下更容易确定边际。
X2-Softmax损失函数的对数函数曲线如图3所示。
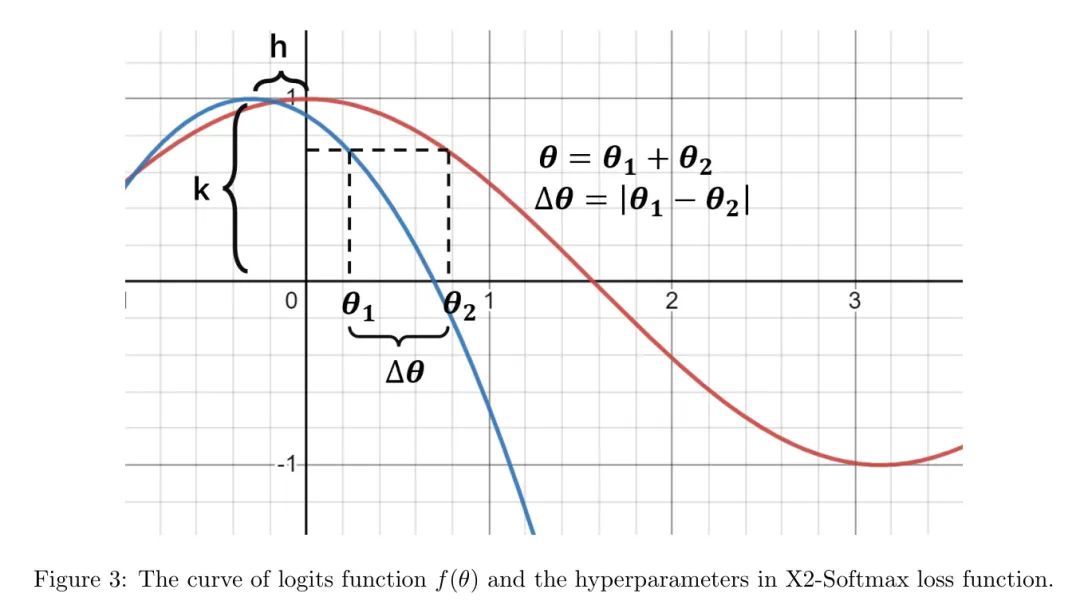
对于二分类问题,当面特征被分类到第一类时,决策边界为。当面特征被分类到第二类时,边界为。如图3所示,两条函数曲线的竖直坐标始终相同。同时,作者假设两个类别的权重角度。权重间的角边界。
从决策边界和公式4,作者可以得到。因此,边际和权重角度如下所示:
根据公式6和公式7,作者在图4(f)中绘制了角度和角边界之间的关系。
从图3和图4(f)中可以看出,当权重角度增加时,角边界同时单调增加。动态生长的角边界避免了固定角边界的问题,较大的边际可以推动面特征向权重聚集。
X2-Softmax损失函数以一种更直观的方式设置边际:权重角度较大的一类会在更大的边际下进行分类。
在这一节中,作者将探讨不同损失函数中权重角度和角边际之间的关系。
对于ArcFace,由于它在角度空间中直接应用了一个固定的加性角边界,角边界由超参数确定。无论不同类别的权重角度大小如何,边际都不会改变。然而,ArcFace并没有考虑两个类之间的实际相似性。如图4(d)所示,显然不合理的是,无论两个类有多么相似,它们总是拥有相同大小的边际。
对于CosFace,由于其在余弦空间中应用了一个固定的边界,两个类别之间的角边界不再是一个固定值,而是随着类别权重之间的角度变化而变化。
然而,请注意第3.1节中的角边界公式和类间权重角度公式。作者绘制了和之间的关系,如图4(e)所示。随着的增加,同时减小。这意味着,对于两个类间相似度较低的类别,角边界会变得更小,从而减少面特征的类别间分离。而对于两个类间相似度较高的类别,即较小时,角边界会变得较大,这可能使模型收敛变得更加困难。
这两个例子都指出了固定角边界的损失函数存在一些缺陷。因此,X2-Softmax损失函数考虑角边界应该是自适应的,并随着权重角度的增大而增大。如作者在第3.2节中提到的,公式6、公式7和图4(f)显示了角度和角边界之间的关系。随着的增大而增大,这与作者的直觉相符。对于两个类更相似的情况,一个合适的角边界有助于模型完成收敛。而对于两个类不太相似的情况,需要分配一个较大的角边界来增强面特征的类别间分离。作者的X2-Softmax函数能够自适应地选择角边界。
上述损失函数的对数函数曲线和角度与边际之间的关系如图4所示。
为了证明作者X2-Softmax损失相对于其他损失函数的优势,作者提供一个简单的玩具例子。
在MS1Mv3中,作者选择了所有超过120张图像的身份,并提取了它们的脸特征。在玩具示例中,作者选择了具有最大方差和最小方差的四个人身份,并在这八个人身份上在ResNet-34上进行训练,并将其映射到二维脸特征空间中。
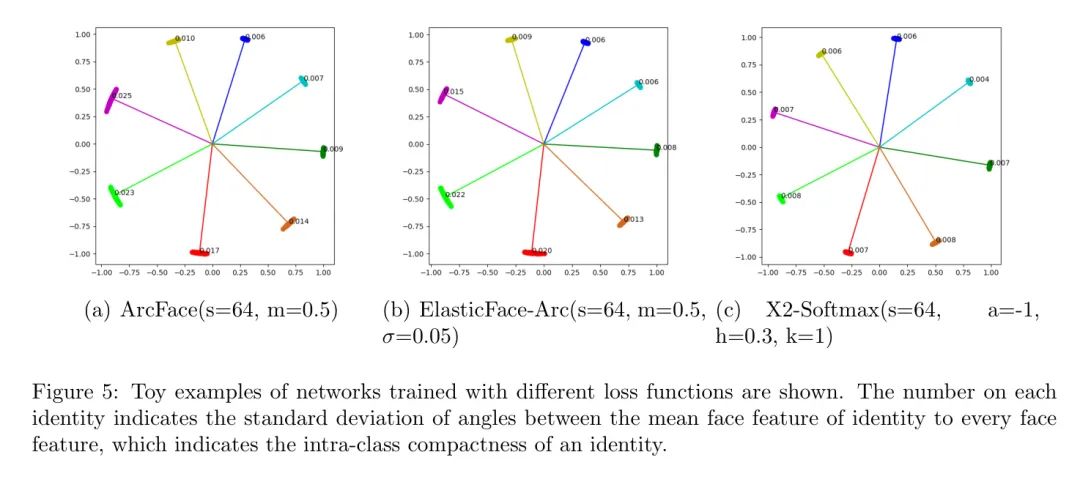
如图5所示,使用不同的损失函数训练八个人身份的face图像被映射到2D脸特征空间中。图中标出了特征与平均特征之间的角度的标准差。从结果中可以看出,X2-Softmax损失的特征标准差较小,这意味着使用X2-Softmax训练的模型提取的特征在每个类别中比其他损失函数更紧凑。
实验设置如下。本文中的实验是通过Pytorch实现的。作者在Windows 10系统上进行了实验,并使用了NVIDIA GeForce RTX 3090进行训练。
本文中用于演示所有实验训练和测试的神经网络模型是ResNet50,它广泛应用于人脸识别解决方案。这些模型使用随机梯度下降(SGD)优化器进行训练,初始学习率为0.02。动量和权重衰减分别设置为0.9和5e-4,批量大小设置为128。总训练迭代次数为1052k。学习率在323k,566k,809k和1011k训练迭代次数时分别乘以0.1。在训练过程中,通过随机水平翻转以概率0.5进行数据增强。用于训练和评估的图像大小为~{}112×112×3,面部特征维度为512。所有用于训练和评估的图像像素值都归一化到-1和1之间。作为常见设置,作者将超参数s设置为64。
本文中使用的训练集是MS1Mv3,它近年来被广泛用于人脸识别解决方案。MS1Mv3基于MS-Celeb-1M数据集,包含约10M张图像和100k个身份。由于原始版本包含大量噪声图像,经RetinaFace预处理后的精化版本包括93k个身份和5.1M张面部图像。
为了展示X2-Softmax损失在面识别上的有效性并与其他损失函数进行比较,作者在八个不同的评估基准上评估训练好的模型。这八个评估基准是:1) 标签在野外(LFW),2) 年龄数据库30(AgeDB-30),3) 年龄在野外(CALFW),4) 年龄在姿势(CPLFW),5) 正面视角的明星(CFP-FP),6) 正面视角的视觉几何组(VGGFace2-FP),7) IARPA Janus基准B(IJB-B),8) IARPA Janus基准C(IJB-C)。对于前六个评估基准,作者报告使用不同损失函数训练的模型在评估上的准确性,以评估X2-Softmax损失的有效性。对于后两个评估基准IJB-B和IJB-C,作者计算了称为在错误接受率(FAR)为1e-4和1e-5的指标。用于训练和评估的不同面部数据集的数量如图1所示。
在本节中,作者将进行超参数研究,以研究X2-Softmax损失中不同超参数的影响。
超参数,和一起决定了X2-Softmax损失中的对数函数曲线,以及对数函数曲线与余弦函数之间的差异。超参数决定了对数函数曲线的开口方向和收敛程度。对数函数应该随着面特征与权重之间的角度增加而减小,因此超参数应设置为负数。随着的绝对值增加,对数函数曲线变得更密集和更陡峭。当的绝对值增加时,角边界增加。对于两个相似度较高且权重角度较小的类别,随着的增加,角边界的增加量大于两个相似度较低且权重角度较大的类别中角边界增加量。
超参数表示对数函数曲线顶点的水平坐标。随着超参数的减小,对数函数曲线向左移动,对数函数曲线与余弦函数曲线之间的差异增加,这意味着角边界同时增加。与变化时边际的影响不同,变化时角边际的影响与两个类别的相似度和角度无关。
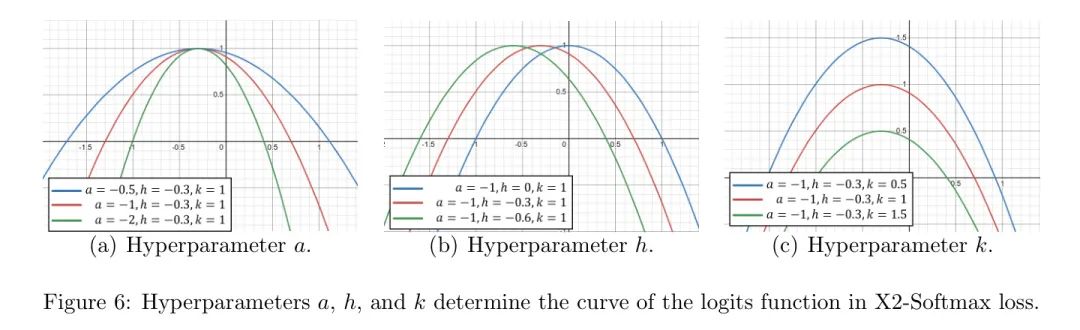
超参数表示对数函数曲线顶点的垂直坐标。随着超参数的减小,角边界增加。由于三个超参数,和影响对数函数曲线和对类之间的角边界,作者对这三个超参数进行了不同的值设置以进行参数化实验。如图6所示,超参数决定了X2-Softmax中对数函数曲线的形状。
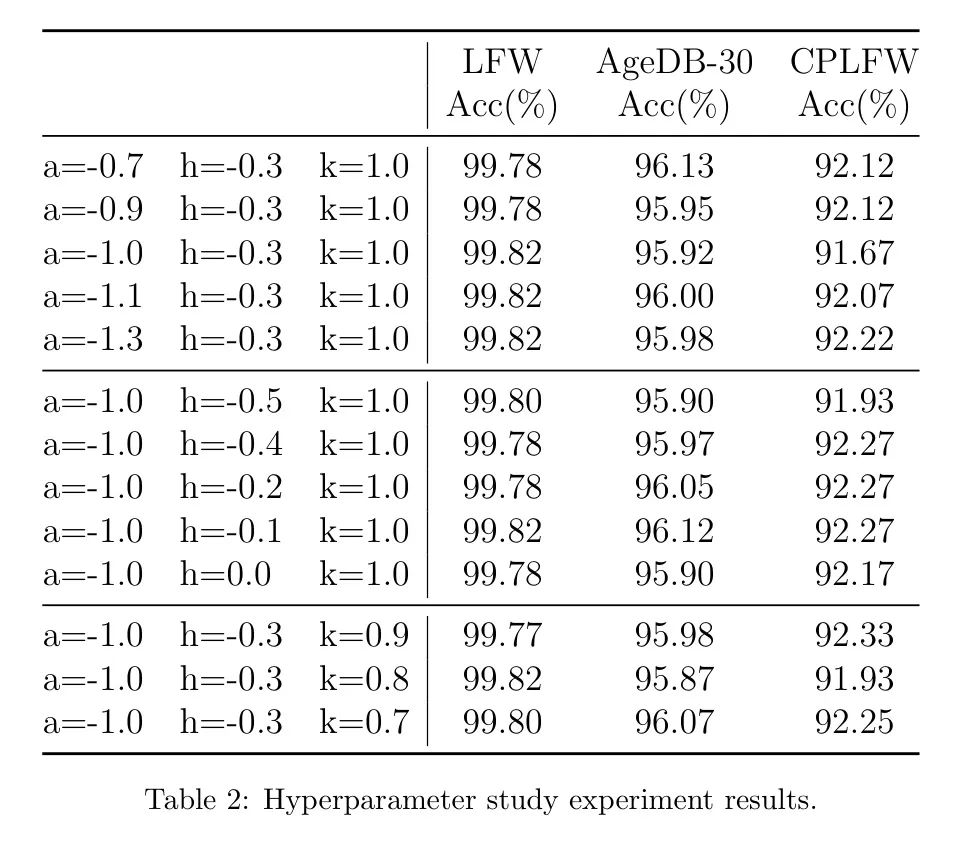
实验结果如表2所示。当超参数,和时,训练好的模型实现了最佳的合成结果。
在本节中,作者将报告在八个评估基准上使用X2-Softmax损失训练模型的结果,并将其与其他损失函数的结果进行比较。
在LFW,CALFW,CPLFW,AgeDB-30,CFP-FP,VGG2-FP上的结果。 表3显示了使用不同损失函数训练的模型在LFW,CALFW,CPLFW,AgeDB-30,CFP-FP,VGG2-FP上的准确率。
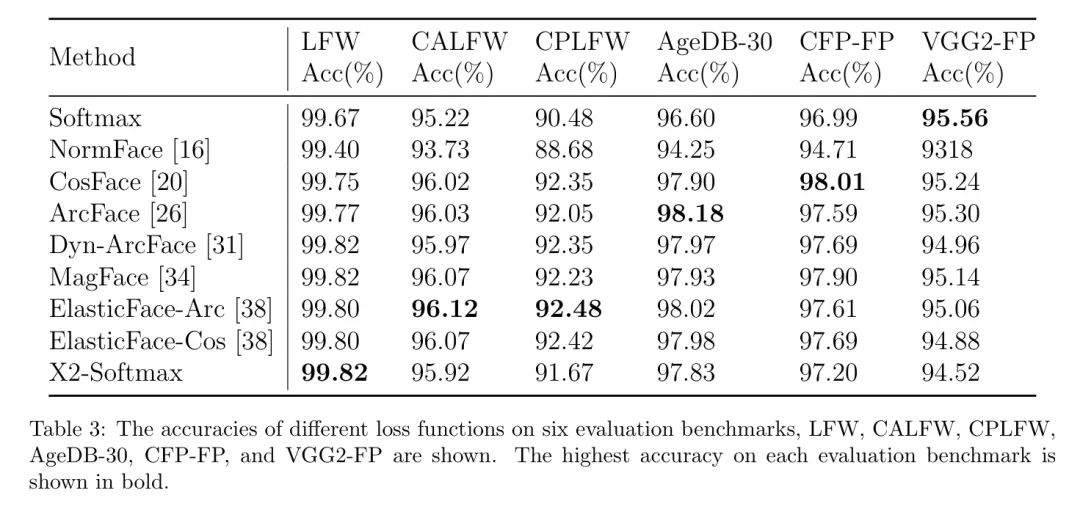
LFW基准在面识别程序中是最广泛使用的,也是最古老的基准之一。在准确率方面,它已经接近饱和。不同评估基准的结果差异主要来自不同的面变化,例如不同的年龄或姿态,例如CALFW和CPLFW基准。在LFW基准上,作者实现了最佳结果,准确率为99.82%。在CALFW和CPLFW基准上,作者的X2-Softmax仍然实现了95.92%和91.67%的准确率,分别接近最佳准确率。
在AgeDB-30基准上,X2-Softmax的准确率为97.83%。在CFP-FP基准上,模型需要匹配正面和侧面人脸,无疑增加了面识别的难度。在这个基准上,CosFace实现了最佳结果,准确率为98.01%,而X2-Softmax损失实现了97.20%的准确率。在VGG2-FP基准上,X2-Softmax的准确率为94.52%。这些评估基准上的准确率都接近饱和。不同损失函数的准确率也很接近,因此仅通过这些几个评估基准无法充分评估。因此,作者还将使用IJB评估基准来比较X2-Softmax与损失函数。
在IJB-B和IJB-C上的结果。 IJB-B和IJB-C是近年来用于面识别的重要评估基准。表4中显示了在这些基准上的结果。如表所示,作者的X2-Softmax损失在四个评估基准中的三个中领先。
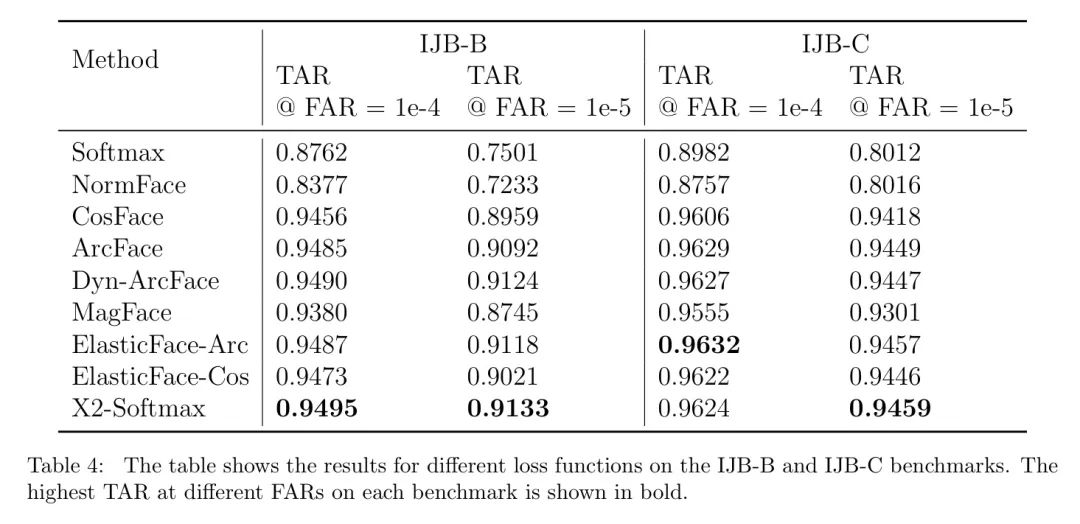
在IJB-B基准上,作者的X2-Softmax在FAR等于1e-4时,TAR达到0.9495,在FAR等于1e-5时,TAR达到0.9133,均领先于其他最先进的损失函数。在IJB-C基准上,当FAR等于1e-4时,X2-Softmax的TAR达到0.9624,稍微落后于其他损失函数;当FAR等于1e-5时,X2-Softmax损失的TAR达到0.9459,仍然领先于其他损失函数。
在IJB-B和IJB-C基准上,作者的X2-Softmax表现良好,并且大多数时候能够优于其他损失函数。这清楚地表明,作者的X2-Softmax损失函数在IJB-B和IJB-C上都提高了性能。
IJB-C正负样本对余弦相似度分布图。 7代表使用不同损失函数训练的ResNet-50网络架构在IJB-C评估基准上正负样本对余弦值分布。红色曲线代表IJB-C中所有正样本对的余弦值分布(约10k),蓝色曲线是随机选择的负样本对的余弦值分布,数量等于正样本对的数量。红色和蓝色曲线重叠部分表示正负样本对的混淆区域。从结果来看,作者的X2-Softmax损失函数的混淆区域更小,表明该损失函数更彻底地将面特征分离。
本文提出了一种简单而有效、高效且自适应边界的面识别损失函数,称为X2-Softmax损失。具体来说,由于该损失函数的边际自适应性,它能够在训练过程中根据两个类别之间的角度应用自适应边际,随着权重角度的增大而增加。同时,该损失函数也避免了寻找适合的超参数。作者对多个数据集进行了测试。实验结果表明,该方法的有效性和优越性得到了证实,对于困难基准的性能也非常 promising。
[1].X2-Softmax: Margin Adaptive Loss Function for Face Recognition

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)





前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢