


喜报!微信AI团队联合北京大学斩获国内首篇 EMNLP 最佳长论文。
在刚刚结束的EMNLP2023,由北京大学和微信AI团队合作的论文“Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning”从4909篇投稿中脱颖而出,斩获EMNLP2023的最佳长论文奖(Best Long Paper Award),这也是EMNLP会议上国内首篇获此殊荣的论文。

在本次的获奖论文中,微信AI和北京大学联合团队深入研究了上下文学习(In-context learning,ICL)的工作机制,发现上下文学习中演示示例的标签词起着 “锚点” 作用,为此提出了一系列方法来提升ICL性能。
关于本次工作的细节,也将在此展开:
一
背景介绍
上下文学习(in-context learning)是一种在大语言模型(LLM)时代相当常用的小样本学习(few-shot learning)方法。它通过向大语言模型提供示例样本(demonstrations)的方式,引导模型完成指定的任务。上下文学习无需参数更新,直观易用,非常契合大语言模型时代的需求。
自然而然地,人们也对大模型为什么能通过上下文学习完成指定任务产生了兴趣。近来,已经有许多工作从不同角度分析了上下文学习。一些工作分析了上下文学习中示例的格式与排列组合对性能的影响,还有一些工作则尝试建立起上下文学习同K近邻算法、梯度下降算法的联系。
本文则是从信息流动的视角出发,提出了分析了上下文学习中模型“以标签为锚”的猜想,通过多组实验从不同角度验证了这一猜想,并利用分析得到的结论提出了对上下文学习的性能改进与错误识别方法。
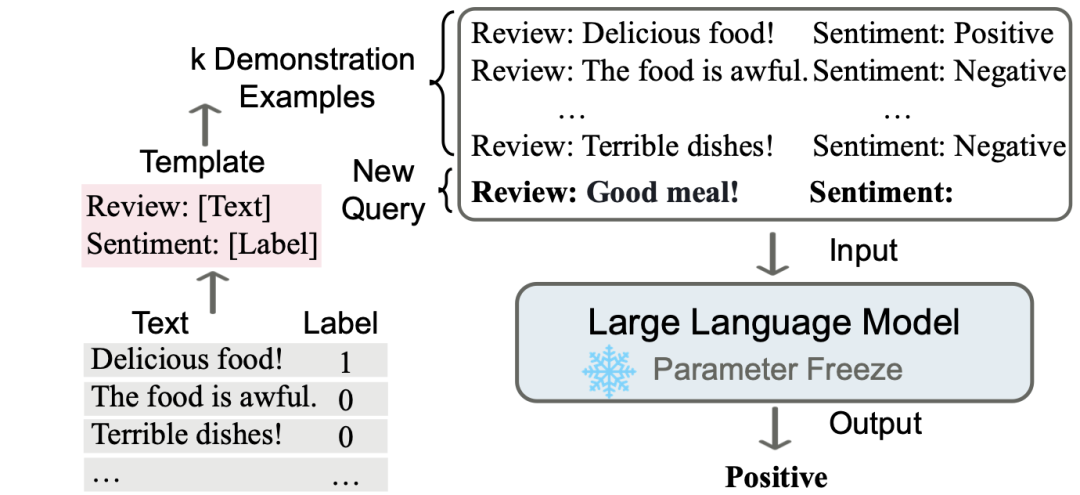
(a) 上下文学习的示意图(A Survey on In-context Learning. Dong et al. 2022)
二
以标签为锚
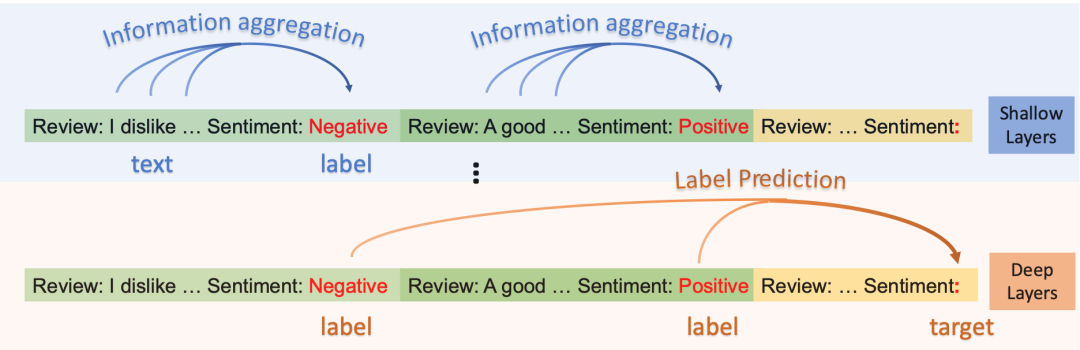
(b) 上下文学习中模型“以标签为锚”
本文尝试分析模型是如何利用读取示例,完成上下文学习中的分类任务的。为此,研究团队从信息流动的角度,尝试剖析上下文学习的过程中,模型的各层是如何抽取、聚集信息的y。通过一系列假设、观察与实验,得出了如下的分析结论(Information Flow with Labels as Anchors):
由于示例中的标签位置在这一过程中起到了关键作用,研究团队形象地称其为“锚点(anchor)”。在下面的章节,将为大家介绍研究团队是如何验证这一结论的,以及这一结论有怎样的潜在应用。
三
验证实验
实验1:
Saliency Score for Information Flow
显著性(saliency)是一种基于梯度来衡量特定输入或参数的重要性的指标。考虑到在模型处理文本的过程中,不同token间的信息流动是通过注意力机制来实现的,研究团队用第i个token到第j个token的注意力权重对应的显著性指标来表示从第i个token到第j个token的信息流动的重要性:
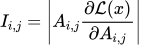
研究团队测量了信息聚合流、结果预测流的显著性指标 (在每层中对所有注意力头求和,对两个流中含有的token对(i,j)取平均),并和信息流动的平均水平(即所有注意力权重的显著性
(在每层中对所有注意力头求和,对两个流中含有的token对(i,j)取平均),并和信息流动的平均水平(即所有注意力权重的显著性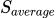 的平均值)相对比:
的平均值)相对比:
(c) 不同信息流动在不同层的显著性值,具体实验设定见论文2.1节
可以看到,在浅层,信息聚合流占主导,在深层,结果预测流占主导。也就是说,模型在浅层,将示例文本的信息聚合到标签处,并在深层进一步利用标签处聚集的信息完成指定的任务。
实验2:
Shallow Layers: Information Aggregation
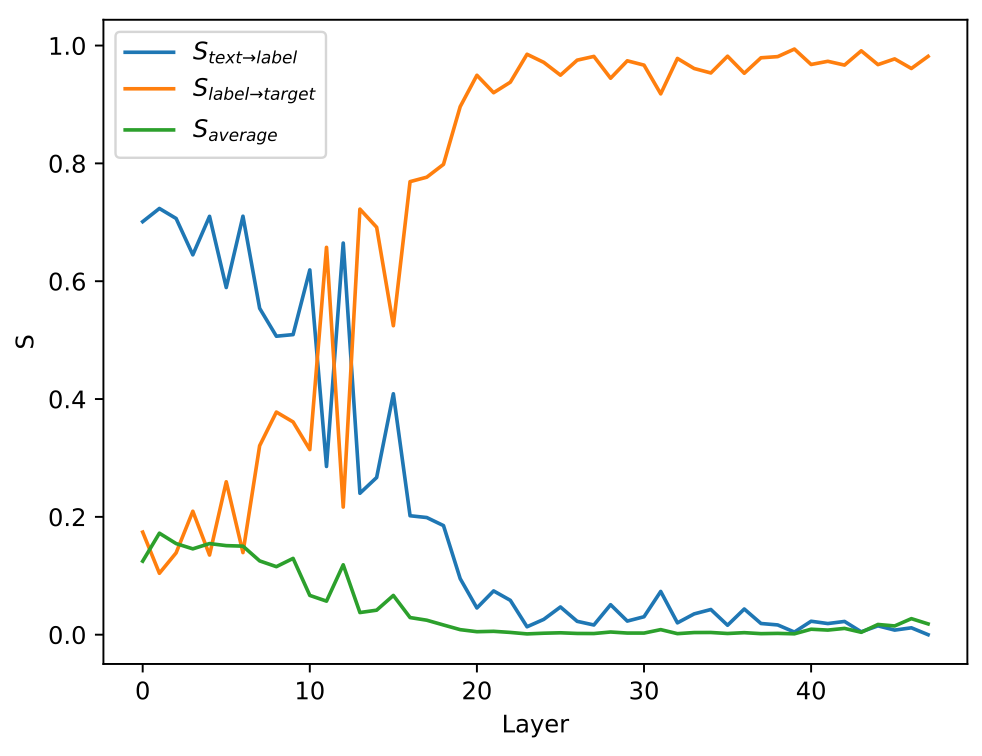
为了验证信息聚合流的存在及其重要性,研究团队还设计了阻断信息聚合流的实验,通过将相应的注意力值置为0来起到阻断信息流动的作用。具体地,团队比较了在浅层/深层阻断信息向标签的聚集(Label Words (first) / Label Words (last)),以及在浅层/深层阻断信息向非标签词(随机抽取)的聚集(Random (first) / Random (last)) 的结果:
(d) 阻断不同流对模型行为的影响,具体实验设定见论文2.2节
对比这四种阻断方式,可以发现,在浅层阻断信息向标签的聚集,产生的影响最为显著。这证明了在浅层的信息聚合流的重要性。
实验3:
Deep Layers: Information Extraction
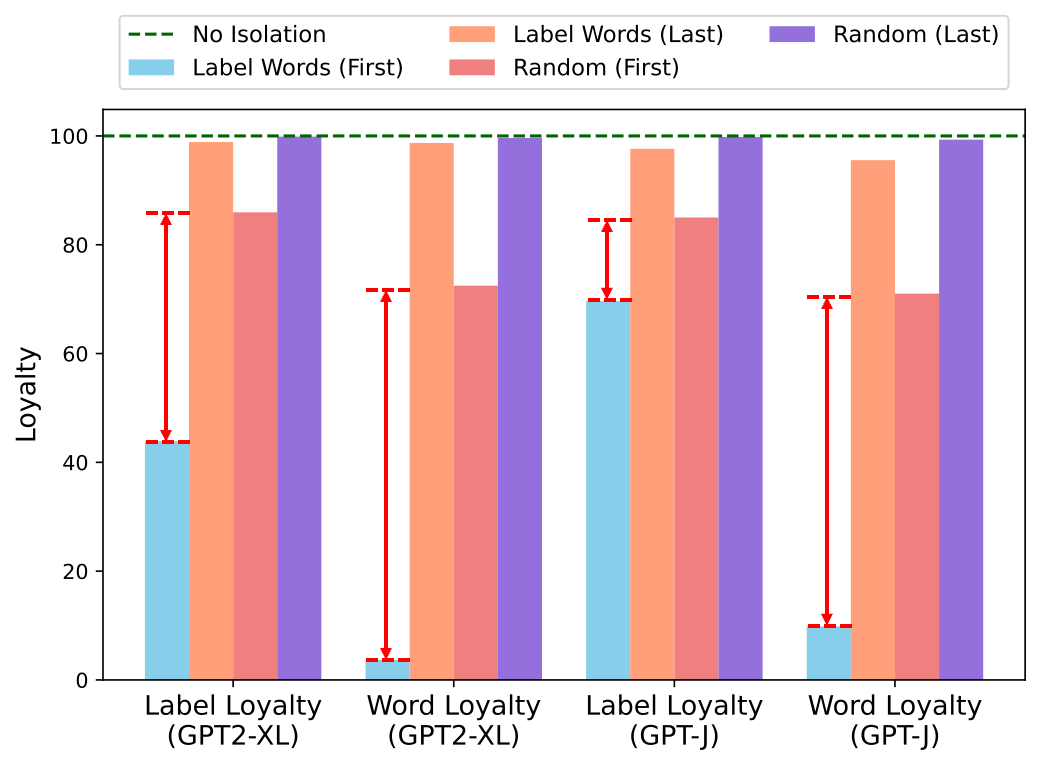
为了验证结果预测流的存在,研究团队度量了标签向待预测位置(target)的注意力权重和模型的预测类别的相关性。对于模型每一层,用AUCROC指标衡量了这一相关性:
(e)标签对应的注意力权重的大小与模型预测类别的相关性,具体实验设定见论文2.3节
图(e)中蓝线即每层的AUCROC值,可以看到,在模型较深的几层,AUCROC很高,接近0.9,说明在这几层标签对应的注意力权重的大小与模型预测类别有很强的相关性。这一现象说明了模型深层结果预测流的存在。
此外,研究团队也根据每层AUCROC的计算了累计值R,它表示了模型到某一层位置分类任务完成的进度:
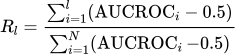
团队在图(e)中用红线绘制出了累计值R。可以发现,在浅层,模型对于分类任务基本没有进展,在深层才开始完成任务。
四
分析结论的应用
在分析、证实了信息聚合流,结果预测流的存在,以及标签的锚点作用后,研究团队进一步探索了利用这些分析结论来提升上下文学习的性能、效率,以及解释上下文学习中的错误的可能性。这些探索一方面能展示分析结论的实用价值,另一方面也能从另一个侧面进一步验证团队的猜想。
应用1:
Anchor Re-weighting
考虑到“结果预测流”的存在,一种自然的想法是,研究者可以通过调整标签到待预测位置的注意力权重的大小,来实现“加权上下文学习”,以促使模型对重要的示例赋予更高的权重,或是消除模型对某些示例的不恰当的偏好。
具体地,可以在标签到待预测位置的注意力权重上乘以一个可学习的参数,以调整不同示例的权重。团队在额外的训练样本上,使用梯度下降优化这些参数,结果如下图所示:

(f)锚点重加权与普通上下文学习的效果比较。具体实验设定见论文3.1节
可以看到,锚点重加权方法能显著提升上下文学习的性能(即使将训练样本加入上下文学习的示例中也是如此,特别的,有些数据集上增加示例反而会导致性能下降,这在之前的论文中亦有提及,可能与示例排列方式等因素造成的偏见(bias)有关)。
从另一个角度看,这一实验也进一步验证了对于“结果预测流”的分析。
应用2:
Anchor-Only Context Compression
考虑到在“信息聚合流”中,示例文本的信息已经聚集到标签位置,一个合理的假设是研究者可以用标签位置的隐层状态代表整个示例(在实践中,团队还附带了格式部分,即图(a)中的"Review:"和"Sentiment:")。通过这种方式,团队将示例的token数大大压缩,从而能加速模型的推理。研究团队称这一方法为 。
。
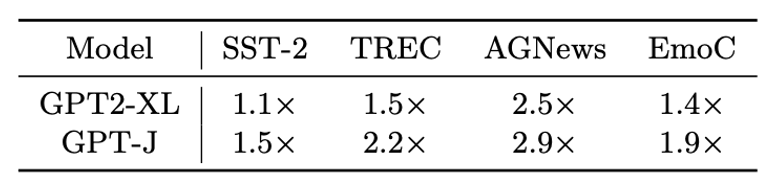
(g)压缩的加速比
研究团队也比较了将示例压缩成相同token数的另外几种方法:
 :把标签的隐层换成其他随机非标签词的隐层;
:把标签的隐层换成其他随机非标签词的隐层;
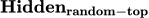 :随机尝试
:随机尝试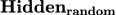 20次,选取标签忠实度(label loyalty,即模型分类结果和压缩前的结果的匹配度)最高的一组;
20次,选取标签忠实度(label loyalty,即模型分类结果和压缩前的结果的匹配度)最高的一组;
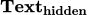 :不输入隐层,而是直接输入标签对应的文本;
:不输入隐层,而是直接输入标签对应的文本;
结果如下图所示:
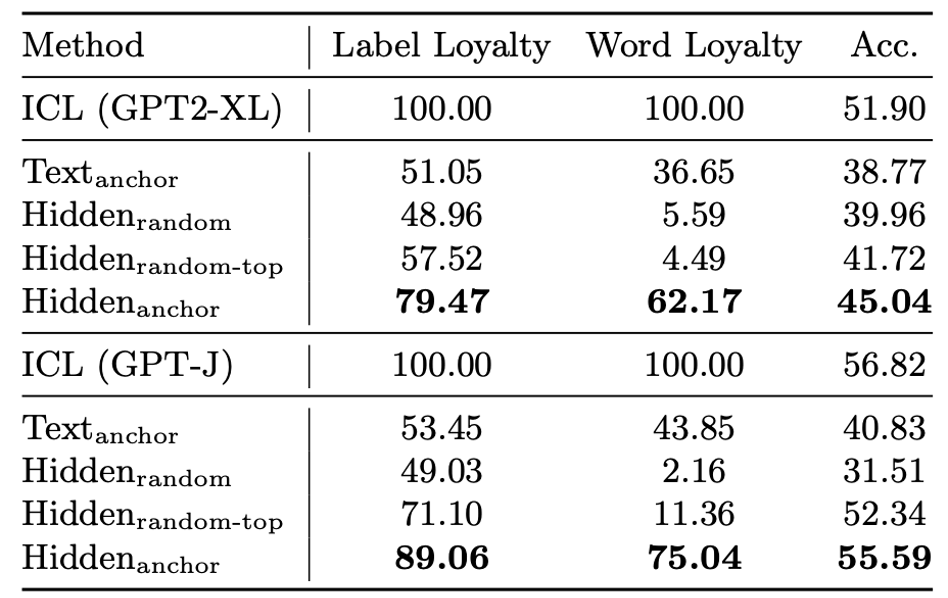
(h) 不同压缩方法的效果对比
可以看到,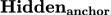 取得了最好的效果。
取得了最好的效果。
此外,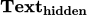 弱于也说明,标签上聚集的示例文本信息是不可或缺的,标签自身的含义不足以辅助模型较好的完成上下文学习;
弱于也说明,标签上聚集的示例文本信息是不可或缺的,标签自身的含义不足以辅助模型较好的完成上下文学习;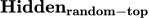 弱于
弱于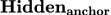 则说明,标签位置的隐层状态比其他token对应的隐层状态蕴含了更多有用的信息。总的来说,这一实验也从另一个侧面证明了标签位置聚集了示例文本的信息。
则说明,标签位置的隐层状态比其他token对应的隐层状态蕴含了更多有用的信息。总的来说,这一实验也从另一个侧面证明了标签位置聚集了示例文本的信息。
应用3:
Anchor Distances for Error Diagnosis
由于标签直观重要的锚点作用,和“结果预测流”中标签对应的注意力值和模型分类结果的抢相关性,一个直观的猜测是,一旦标签位置的隐层状态相似,模型就容易混淆两个类。或者说,模型混淆两个类的一个原因是标签对应的隐层状态的相似性。
具体地,研究团队用标签对应的键向量之间的距离来衡量标签的相似性(更具体的介绍可参见论文3.3节),以预测模型对两个类的混淆程度,而真实的混淆程度则用AUCROC来衡量。研究团队可视化了这两个指标得到的混淆矩阵,发现他们在混淆较严重的类别上(图中为Description-Entity, Entity-Abbreviation, Description-Abbreviation)匹配地比较好:
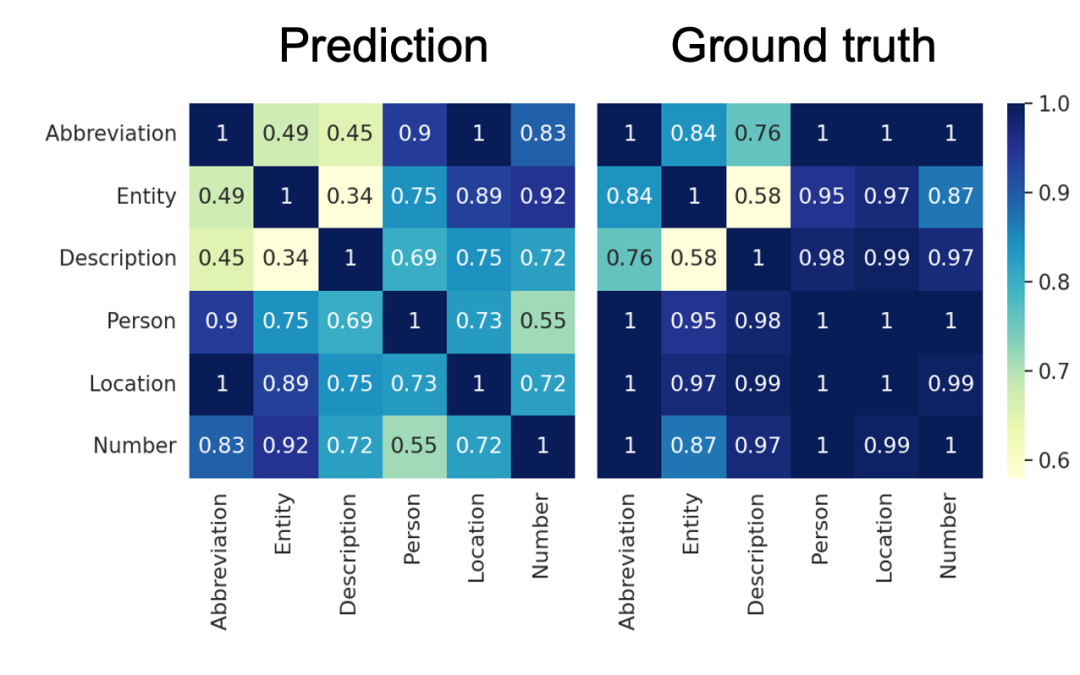
(j)基于锚点距离的混淆矩阵和真实混淆矩阵。具体实验设定见论文3.3节
这一实验说明,研究团队的方法有一定的诊断上下文学习中出现的错误的能力。
五
总结
研究团队的工作从信息流动的角度,分析了模型采用上下文学习范式完成分类任务时的内在机制。通过多组实验,团队验证了标签的“锚点”作用,包括浅层的“信息聚合流”、深层的“结果预测流”。
同时,研究团队也探索了这些分析结论在提升上下文学习准确率、加速上下文学习、解释上下文学习中的错误这几个方面的潜在应用。
六
存在局限&未来方向
研究团队的分析基于信息流动视角,提出了标签的“锚点”作用,对上下文学习作出了较完备合理的分析。不过,团队的分析主要注重于分类任务。生成任务的情况仍有待进一步的探索和验证。对于一些上下文学习的变种,如思维链(chain-of-thought)上,模型是否表现出类似的模式,也是值得进一步探索的问题。
EMNLP 全称为Conference on Empirical Methods in Natural Language Processing,由国际计算语言学会ACL组织每年举办一次,为自然语言处理领域最具影响力的国际会议之一。本届EMNLP2023会议共接收4909篇投稿,主会录用论文1047篇,录用率21.3%。其中,包含斩获最佳长论文奖的论文在内,微信AI团队有8篇文章被选中,以下为入选的8篇文章的标题及作者:
微信AI团队在EMNLP2023的表现充分展示了其在AI领域的专业实力,除了本次 EMNLP2023 Best Paper (Long) Award,近年来团队成员参与的研究工作已经获得了多个重要奖项,包括RecSys2023 Best Paper (Short) Award, ACL2019 Best Paper (Long) Award等。

往期优质文章推荐
往期推荐

DataFun

点个在看你最好看
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢