
【论文标题】CompRess: Self-Supervised Learning by Compressing Representations 【作者团队】Soroush Abbasi Koohpayegani,Ajinkya Tejankar,Hamed Pirsiavash 【发表时间】2020/10/28 【论文链接】https://arxiv.org/pdf/2010.14713.pdf 【代码链接】https://github.com/UMBCvision/CompRess
【推荐理由】 本文已被 NeurIPS 2020 接收,作者将知识蒸馏技术与自监督学习方法有机结合,使自监督 AlexNet 模型首次在 ImageNet 分类任务上取得了优于监督学习模型的性能。
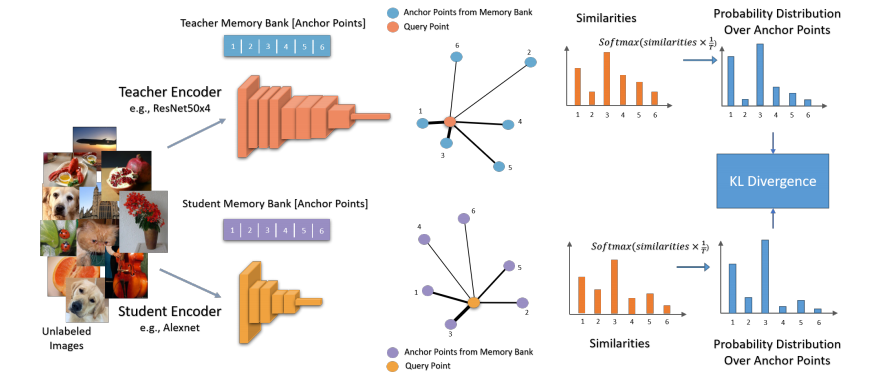
作为一种旨在利用无标签数据学习高质量数据表征的方法,自监督学习近期受到了大量研究人员的关注。近期的研究工作表明,较大的模型能比较小的模型更多地受益于自监督学习。因此,对于较大的模型而言,监督学习和自监督学习之间的性能差异被大大地缩小了。在本文中,作者并没有涉及新的前置任务,而是提出了一种能够将已学习好的深度自监督模型(教师网络)压缩为较小的模型(学生网络)的模型压缩方法。作者通过对学生模型进行训练,使其能够在教师网路嵌入空间中学习到数据点之间的相对相似度。以 AlexNet 为例,本文提出的方法性能优于包括全监督方法在内的所有方法:在 ImageNet 线性评估任务上,本文提出的方法准确率为 59.0%,对比基线的准确率为 56.5%;在最近邻评估任务上,本文提出的方法的准确率为 50.7%,对比基线的准确率为 41.4%。据我们所知,这是自监督 AlexNet 模型首次在 ImageNet 分类任务上取得了优于监督学习模型的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢