

极市导读
对于视觉 Transformer,将其 Self-Attention 中的 Softmax 操作替换为 ReLU/序列长度 (seqlen) 之后,性能的下降问题有所缓解。本文在 ImageNet-21K 上训练了从 Small 级别到 Large 级别的视觉 Transformer,证明了 ReLU-attention 可以在缩放性上接近或者匹配 Softmax-attention 的性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 在 ViT 中使用 ReLU 取代 Softmax
(来自 Google DeepMind)
1.1 ReLU-attention 的新发现
1.2 去掉 Softmax 的相关工作
1.3 ReLU-attention 方法
1.4 实验结果
1.5 qk-norm 实验结果
1.6 添加 gate 的影响
太长不看版
本文的研究结论是:对于视觉 Transformer,将其 Self-Attention 中的 Softmax 操作替换为 ReLU/序列长度 (seqlen) 之后,性能的下降问题有所缓解。本文在 ImageNet-21K 上训练了从 Small 级别到 Large 级别的视觉 Transformer,证明了 ReLU-attention 可以在缩放性上接近或者匹配 Softmax-attention 的性能。
1 在 ViT 中使用 ReLU 取代 Softmax
论文名称: Replacing softmax with ReLU in Vision Transformers (Arxiv 2023)
论文地址:
https//arxiv.org/pdf/2309.08586.pdf
1.1 ReLU-attention 的新发现
Transformer 架构[1]在现代机器学习中无处不在。Attention 是 Transformer 的核心组件,包括一个 Softmax 操作,它在 token 上产生概率分布。Softmax 操作涉及到内部的计算所有输入的指数之和,它的计算代价相当昂贵,使得 Transformer 架构的并行化具有挑战性[2]。
本文作者探索了 Softmax 操作的 Point-wise 的替代方案,该操作不一定输出概率分布。本文的核心贡献是观察到:ReLU/序列长度(seqlen) ,可以在缩放性方面接近或匹配传统的 Softmax 操作。这一结果为并行化提供了新的机会,因为 ReLU-attention 相比传统的 Softmax-attention 可以使用更少的 gather 操作在序列长度维度实现并行化。
1.2 去掉 Softmax 的相关工作
替换 Softmax 的研究:
ReLU 和 squared ReLU:[3][4]把 Softmax 替换成了 ReLU,[5]把 Softmax 替换成了 squared ReLU。但是这些方法不会除以序列长度,本文通过实验发现对于达到与 Softmax 相当的准确度很重要。 [6]仍然需要对序列长度轴进行归一化,以确保注意力权重之和为1,这依然需要 gather。
去掉激活函数的研究:
[7][8][9] 去掉了激活函数,使得 Attention 变成了线性复杂度。因为对于线性注意力,矩阵乘法的顺序可以从 切换到 ,这就可以把计算复杂度从 变为 ,其中, 是 query, key 和 value, 是序列长度。这个技术对于长序列长度很有用。但是这会降低模型性能。
1.3 ReLU-attention 方法
在进行 Self-attention 的操作时,首先计算注意力权重:

式中, 是 Softmax 操作,然后是计算输出:

ReLU-attention
本文观察到, relu 是有效替代 的方法。
Scaled point-wise attention
本文研究的是更为广义的 ReLU-attention 版本: 。其中, , relu, relu , gelu, softplus, identity, relu6, sigmoid 。
实验结果如图1所示,基本上当 接近 1 时,观察到最好的结果。 没有明确的最佳非线性,因此作者在主要实验中使用 ReLU 的速度。
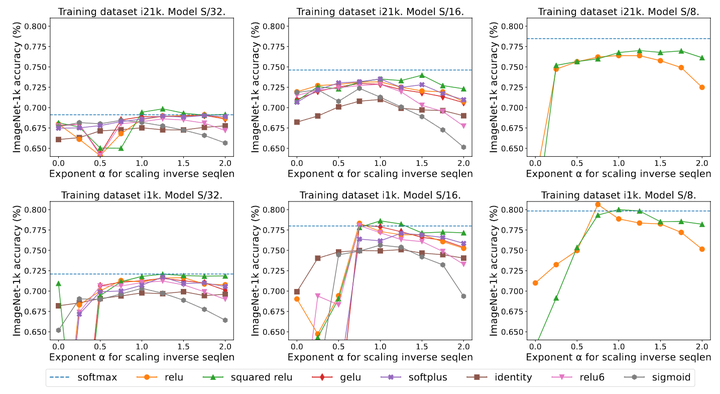
Sequence length scaling
本文观察到,通过对序列长度 进行缩放有利于高精度。作者这里给出了一些简要的分析性的动机:
Transformer 一般是设计为 Softmax 注意力机制,其中 。这意味着 。虽然这不太可能是一个必要条件,但是 relu 的确可以确保 在初始化时是 。
1.4 实验结果
作者在 ImageNet-21K 上训练了 30 Epochs,在 ImageNet-1K 上训练了 300 Epochs。作者使用了 ViT-22B[10]中提出的 qk-norm 技术,因为这个技术被验证在扩大视觉模型时有益于优化稳定性,但是作者发现在本文量级的模型这一技术没那么重要。
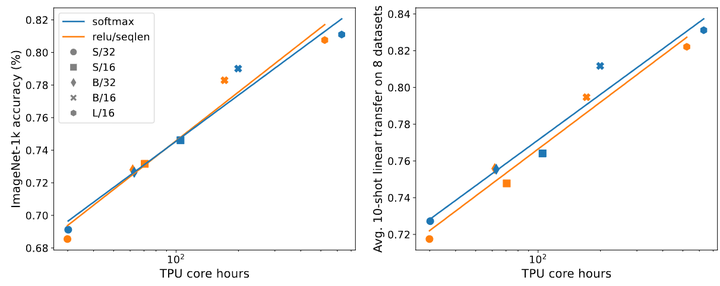
如下图2所示说明了 ReLU-attention 与 ImageNet-21K 训练的 Softmax-attention 的缩放趋势相匹配。x 轴表示实验所需的总 core hours。ReLU-attention 的优势是能够以比 Softmax-attention 以更少的 gather 操作对序列长度维度进行并行化。
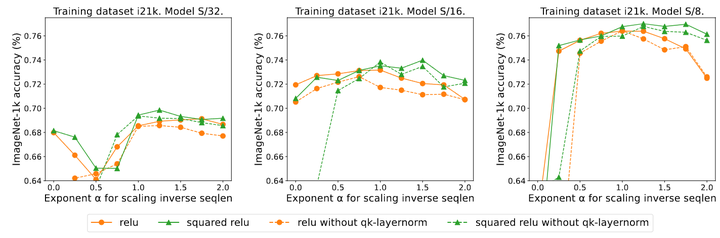
1.5 qk-norm 实验结果
本文主要实验使用了 qk-norm,其中 query 和 key 在计算注意力权重之前通过 LayerNorm 传递,作者发现有必要在扩大模型大小时防止不稳定性。如图3所示是 qk-layernorm 的实验结果。结果表明,qk-norm 对这些模型没有很大的影响。
1.6 添加 gate 的影响
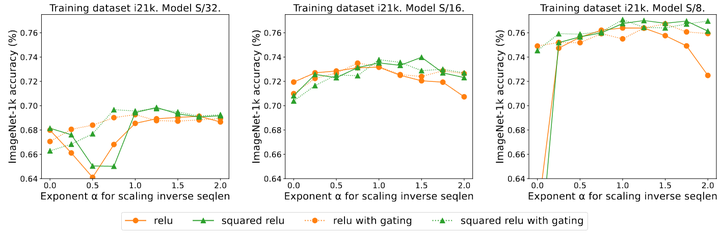
[11]这个工作删除了 Softmax 之后,添加了一个门控单元,并且不按序列长度缩放。具体而言,在门控注意力单元中,通过额外的投影层产生输出,该输出在输出映射之前与注意力的结果做 Element-wise 的乘法。
如图4所示是添加 gate 的影响实验结果。作者研究了 gate 的存在是否消除了序列长度缩放的需要。总体而言,作者观察到无论有没有 gate 的存在,使用序列长度缩放都实现了最佳精度。注意到对于带有 ReLU 的 S/8 模型,添加 gate 操作将实验所需的 core hour 增加了大约 9.3%。
参考
1.Attention is All you Need
2.FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
3.A Study on ReLU and Softmax in Transformer
4.Infinite attention: NNGP and NTK for deep attention networks
5.Transformer Quality in Linear Time
6.Robust Training of Neural Networks using Scale Invariant Architectures
7.Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
8.SOFT: Softmax-free Transformer with Linear Complexity
9.SimA: Simple Softmax-free Attention for Vision Transformers
10.Scaling Vision Transformers to 22 Billion Parameters
11.Transformer Quality in Linear Time
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢