

关键词:深度神经网络,统计物理,机器学习可解释性


论文题目:A statistical mechanics framework for Bayesian deep neural networks beyond the infinite-width limit 论文来源:Nature Machine Intelligence 论文地址:https://www.nature.com/articles/s42256-023-00767-6 斑图地址:https://pattern.swarma.org/paper/946de568-9df9-11ee-bc79-0242ac17000e
在计算技术进步的推动以及数十年研究的铺垫下,深度学习的发展超过了研究者为之构建坚实理论基础的解释能力。多个研究团队长期努力在基础层面上填补我们理解深度学习的空白。统计物理在这方面取得了深远的成果,并且仍然是一个新的视角和突破的源泉。
尽管深度神经网络在实践中取得了成功,但目前缺乏一个全面的理论框架,可以从训练数据的知识中预测实际相关的分数,如测试准确度。在无限宽度的极限下,每个隐藏层中的单位数![]() (其中
(其中![]() =1,…,L,其中L为网络的深度)远远超过训练示例数P,因此会出现巨大的简化。然而,这种理想化与深度学习实践的现实明显不符。该研究使用统计力学的工具集来克服这些限制,并推导出完全连接的深度神经结构的近似配分函数,它编码了有关训练模型的信息。该计算在热力学极限下进行,其中
=1,…,L,其中L为网络的深度)远远超过训练示例数P,因此会出现巨大的简化。然而,这种理想化与深度学习实践的现实明显不符。该研究使用统计力学的工具集来克服这些限制,并推导出完全连接的深度神经结构的近似配分函数,它编码了有关训练模型的信息。该计算在热力学极限下进行,其中![]() 和P都很大,它们的比率
和P都很大,它们的比率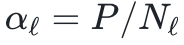 则是有限的。这一进展使我们获得:(1)一个针对具有有限α1的单隐藏层网络的回归任务相关的泛化误差的闭合公式;(2)深度架构的配分函数的近似表达式(通过一个依赖有限数量序参量的有效作用),以及(3)深度神经网络在比例渐近极限下与学生t过程(Student’s t-processes)之间的联系。
则是有限的。这一进展使我们获得:(1)一个针对具有有限α1的单隐藏层网络的回归任务相关的泛化误差的闭合公式;(2)深度架构的配分函数的近似表达式(通过一个依赖有限数量序参量的有效作用),以及(3)深度神经网络在比例渐近极限下与学生t过程(Student’s t-processes)之间的联系。
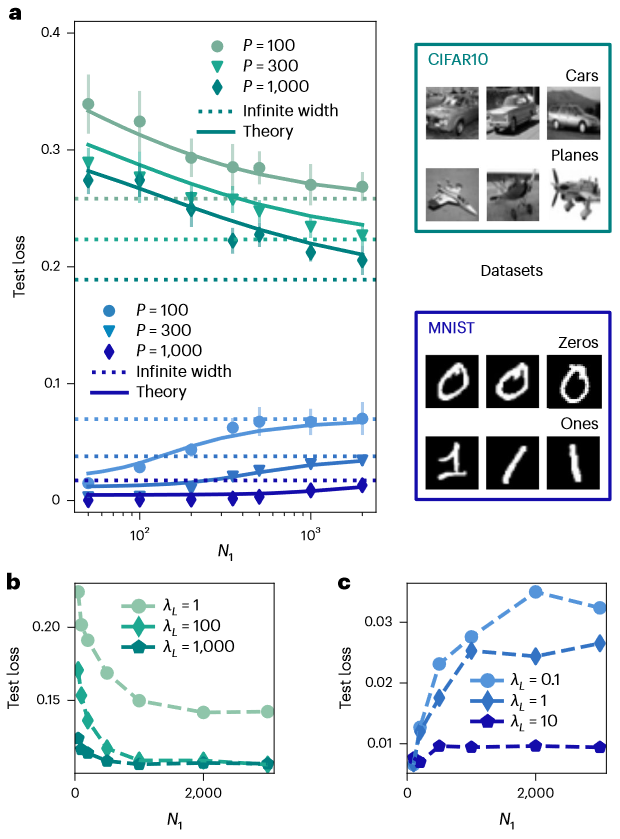
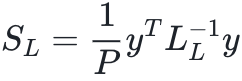 。)时优于无限宽度的预测。b,e,可视化网络不断迭代后的无限宽度NNGP核在不同层的条目(b对应CIFAR10,e对应MNIST)。ReLU NNGP核在不断迭代后趋于零,导致了特征值几乎消失,使得SL最终总是大于1。c,f,基于P=1,000个示例训练的4HL网络的测试损失,不同正则化强度的情况(其中
。)时优于无限宽度的预测。b,e,可视化网络不断迭代后的无限宽度NNGP核在不同层的条目(b对应CIFAR10,e对应MNIST)。ReLU NNGP核在不断迭代后趋于零,导致了特征值几乎消失,使得SL最终总是大于1。c,f,基于P=1,000个示例训练的4HL网络的测试损失,不同正则化强度的情况(其中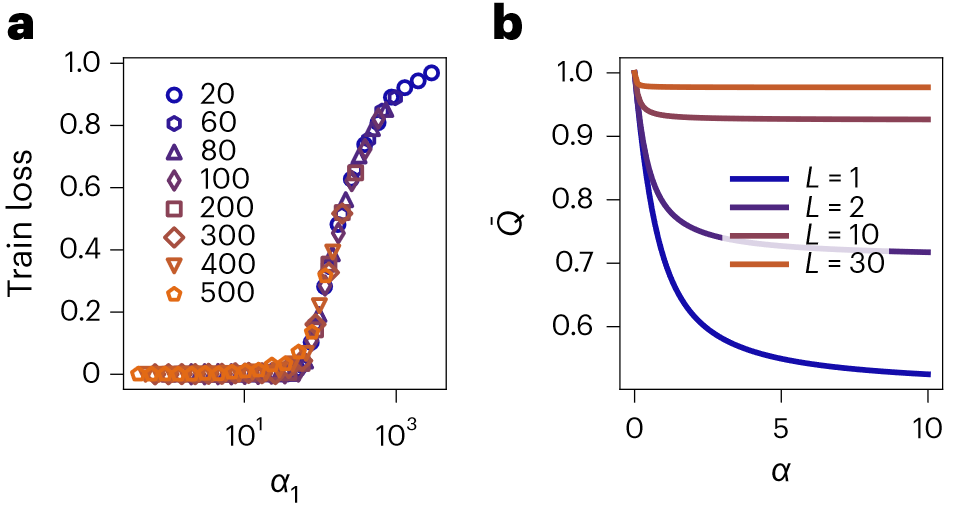
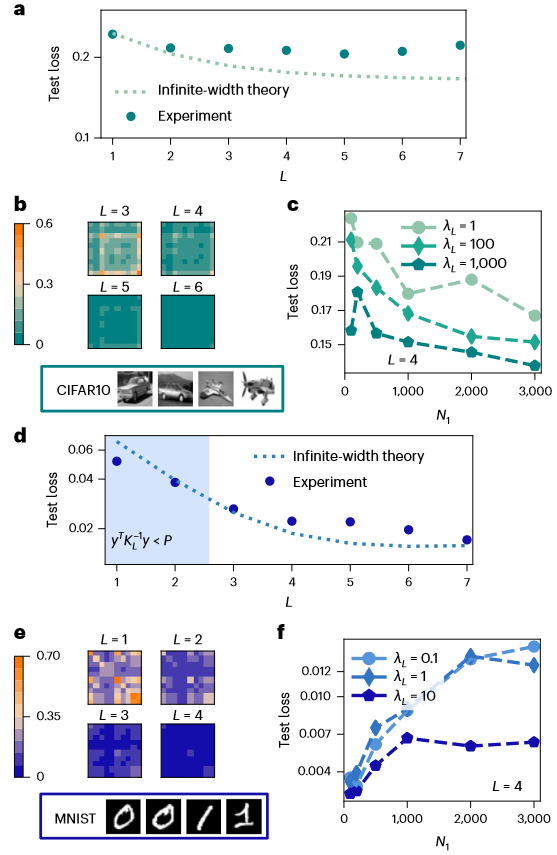
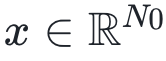 ,其中N0 = 5和标量输出y都是从均值为零、方差为单位的正态分布中采样独立同分布的随机变量)。其中,误差条在数据点内。目前本文理论只描述了训练误差恰好为零的过参数化极限,而无法解释这种普遍现象。b,采用ReLU激活函数在各向同性网络
,其中N0 = 5和标量输出y都是从均值为零、方差为单位的正态分布中采样独立同分布的随机变量)。其中,误差条在数据点内。目前本文理论只描述了训练误差恰好为零的过参数化极限,而无法解释这种普遍现象。b,采用ReLU激活函数在各向同性网络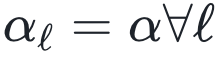 情况下,对于不同的深度L对解
情况下,对于不同的深度L对解神经网络的统计力学课程

课程详情:
推荐阅读
点击“阅读原文”,加入课程
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢