

本文总结了NeurIPS 2023大会上与自然语言处理相关的20篇精彩论文。通过这些论文,作者主要观察到了LLM的六个主要趋势,这些论文涉及重新思考LLM的基本假设,并为其内在运作提供了新的见解和观点。
作者 | Sebastian Ruder
OneFlow编译
翻译|宛子琳、杨婷
NeurIPS 2023于12月10日至16日在新奥尔良举行,可以说是今年规模最大的人工智能会议。该会议共接收了3586篇论文,这些论文已经可在线阅读。
在这份简报中,我将探讨自己关注的20篇与自然语言处理(NLP)有关的论文,重点关注oral和spotlight论文。以下是我观察到的主要趋势:
NeurIPS上的大多数NLP工作都与语言大模型(LLM)相关。虽然也有一些不采用LLM或使用不同设置的论文(例如下文提到的“基于实时反馈的指令跟随持续学习”),但论文的总体背景仍在LLM的框架内。
使用合成设置分析LLM属性的做法越来越普遍。这是因为运行许多不同的预训练实验在计算上是不可行的。研究的属性范围涵盖了从上下文学习,使用全局统计学习以及思维链(chain-of-thought)推理的涌现。
基于人类偏好对齐模型引起了广泛关注。论文特别关注改进RLHF和研究模型与特定人格特征、信念对齐的问题。
对上下文学习的全面理解仍然有待研究。论文研究了上下文学习的不同方面,例如它在训练期间是否持续存在,以及采用贝叶斯视角。
使用当前模型进行推理(Reasoning)仍然具有挑战性。论文侧重于改进在不同类型的推理任务中的性能,包括实用推理(pragmatic reasoning)、基于图的推理、算法推理、组合推理和基于规划的推理。
更多地使用外部工具来提高LLM的推理能力。这些工具包括外部验证器和代码执行模块等。
(需要注意的是,这些论文中提出的一些方法,比如DPO和QLoRA,已成功应用于LLM。)
1
重新思考LLM
这是我最喜欢的话题之一,因为这些论文鼓励我们重新思考关于LLM的基本假设,并为它们的内在运作提供了新的见解和视角。
词汇不变语言模型(Lexinvariant Language Models)
论文:https://openreview.net/forum?id=NiQTy0NW1L
本文提到,词元与嵌入之间的一一映射是LLM自最初的神经语言模型论文(https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf)以来一直没有改变的一个基本特征。该论文研究了语言建模是否也可以使用“lexinvariant”模型进行语言建模,即没有固定的词元嵌入,而是对每个序列分配相同概率的词汇排列。[1] 这似乎是一个强限制,但它可以作为一种有效的归纳偏好(inductive bias),用于恢复替代密码(通过MLP探测器)和上下文符号操作。
在实践中,词元使用随机高斯向量进行编码和采样,以确保相同的词元在一个序列内具有相同的表示,而在不同序列间具有不同的表示。虽然这种方法主要是出于理论兴趣,但通过仅对一些词元使用随机嵌入作为正则化,改善了某些BIG-bench任务的结果。
2
从人类反馈中学习
鉴于各种预训练LLM的激增,研究人员和从业者越来越关注LLM pipeline中的下一步改进:从人类反馈中学习。这对于最大化下游任务的性能以及LLM的对齐都非常重要。
直接偏好优化:你的语言模型其实是一个奖励模型
论文:https://openreview.net/pdf?id=HPuSIXJaa9
人类反馈的强化学习(RLHF)是更新LLM以与目标偏好对齐的首选方法,但相当复杂(需要首先训练奖励模型,然后根据奖励模型对LLM进行强化学习),并且可能会不稳定。这篇论文提出了直接偏好优化(DPO),可以通过对偏好数据进行简单的基于分类的目标优化来达到相同的目标,而无需进行任何强化学习!目标的一个重要组成部分是动态的针对每个示例的重要性权重。DPO有潜力使LLM与人类偏好更加无缝对齐,因此对安全研究至关重要。
细粒度的人类反馈为语言模型训练提供更好的奖励
论文:https://openreview.net/forum?id=CSbGXyCswu
本文解决了RLHF的另一个局限性,即无法对生成响应的错误部分提供更为细致的反馈。论文提出了细粒度RLHF,其中:a)使用了一个密集奖励模型(对每个输出句子进行奖励,而不是整个输出),b)结合了多个用于不同反馈的奖励模型。他们在模型的去毒化处理和长篇问答方面进行了实验,发现相比于RLHF和有监督微调,细粒度RLHF有所改进。重要的是,由于为RLHF提供人类偏好判断是一个复杂的标注任务,提供更细粒度的反馈实际上并不需要更多时间。我们预计,将会看到更多尝试在不同粒度上使用各种奖励模型的方法。
基于实时反馈的指令跟随持续学习
论文:https://openreview.net/forum?id=ez6Cb0ZGzG
这篇论文解决了在协作的3D世界环境中的人类反馈的持续学习的问题。他们展示了一种简单的方法:使用上下文Bandit算法来通过二进制奖励更新模型的策略。在多达11轮以上的训练和部署中,指令执行的准确率从66.7%提高到82.1%。
实验结果显示,在这一情景中,反馈数据提供了与监督数据相似数量的学习信号。尽管他们的研究设置不同于标准的基于文本的情境,但展示了遵循指令的智能体(instruction-following agent)如何持续地从人类反馈中学习的潜力。在未来,我们可能会看到更多更具表达力的反馈方式,比如自然语言。
3
LLM对齐
为确保LLM的最大效用,将其与特定的指南、安全政策、个性特征和与给定下游环境相关的信念对齐至关重要。为达到这一目标,我们首先需要了解LLM已经编码了哪些倾向,然后制定相应的方法来适当地引导它们。
评估和诱导预训练语言模型的个性
论文:https://openreview.net/forum?id=I9xE1Jsjfx
本文提出,根据心理学已知的五大人格特质来评估LLM的个性。在现有问卷的基础上,他们创建了多项选择问答示例,其中LLM必须选择有多准确地描述类似“你喜欢帮助他人”这样的陈述。每个陈述都与一个人格特征相关联。关键在于,模型在特定特质上的得分高低并不重要,更重要的是它是否表现出一致的个性,即是否对与该特质相关的所有问题做出类似的响应。目前,只有较大规模的模型展现出与人类相似的个性特征。因此更好地理解个性特质何时出现,以及如何在较小的模型中编码一致的个性,这将是一个有趣的研究方向。
上下文模拟揭示语言大模型的优势和偏见
论文:https://openreview.net/forum?id=CbsJ53LdKc
本文指出,有很多关于要求LLM模仿领域专家(例如“你是一位专业程序员”等)能够提高模型能力的经验性证据。该论文研究了在不同任务中进行的上下文模仿,并发现模仿领域专家的LLM表现确实比模仿非领域专家的LLM要好。模仿还可用于检测隐性偏见。例如,在描述汽车方面,让LLM模仿男性比被提示为女性做得更好(基于CLIP的能力,使用生成的类别描述将图像与一个类别相匹配)。总体而言,模仿是分析LLM的有效工具,但当用于(系统)提示时可能会强化偏见。
评估嵌入在语言大模型中的道德信仰
论文:https://openreview.net/forum?id=O06z2G18me
本文研究了在高歧义(“我应该撒一个善意的谎言吗?”)和低歧义情境(“我应该在路上停下来礼让行人吗?”)中,LLM如何编码道德信仰。研究评估了28个不同的LLM,并发现:a)在明确的情境中,大多数模型与常识相一致,而在歧义情况下,大多数模型表达出不确定性;b)模型对问题措辞敏感;c)一些模型在歧义情境中表现出明确的偏好,而闭源模型具有类似的偏好。虽然这种评估依赖于一种启发式的将输出序列映射到行动的方法,但这些数据对于进一步研究LLM的道德信仰非常有用。
4
LLM预训练
预训练是LLM pipeline中计算最为计算密集的部分,因此在较大范围内进行研究更加困难。然而,诸如新的规模定律(scaling law)等创新有助于改进我们对预训练的理解,并指导未来的训练过程。
扩展数据受限的语言模型
论文:https://openreview.net/pdf?id=j5BuTrEj35
本文研究了在线文本数量受限情况下的规模规律,与Hoffmann等人(2022年)关于无重复数据的规模规律形成了对比。作者观察到,在重复数据上进行最多4轮的训练表现与在唯一数据上进行训练的表现相似。然而,随着重复次数的增加,额外训练的价值迅速降低。此外,通过将预训练数据与代码相结合,可以显著增加预训练数据的规模。总的来说,每当我们没有无限量的预训练数据时,应该选择规模更小的模型进行更多轮(最多4轮)的训练。
5
LLM微调
用反向传播微调语言模型的成本很高,因此这些论文提出了替代方法使微调更加高效,可以使用高效参数的微调方法或者不计算梯度(零阶优化,zeroth-order optimization)。
QLoRA: 高效微调量化语言模型
论文:https://openreview.net/pdf?id=OUIFPHEgJU
本文提出了QLoRA,这是LoRA的一种更节省内存(但速度较慢)的版本,它使用了多种优化技巧来节省内存。作者训练了一个新模型Guanaco,仅在单个GPU上进行24小时的微调,在Vicuna基准上的表现优于先前模型。总的来说,QLoRA能够减少微调LLM的GPU内存需求。与此同时,他们还开发了可以取得类似结果的其他微调方法,如4位LoRA量化。
仅使用前向传递微调语言模型
论文:https://openreview.net/pdf?id=Vota6rFhBQ
本文提出了一种高效内存的零阶优化器(Memory-Efficient Zeroth-Order Optimizer,简称MeZO),作为经典零阶优化器的更高效内存版本。零阶优化器利用损失值差异来估计梯度。
在实际操作中,该方法在几个任务上实现了与微调相似的性能,但需要多100倍的优化步骤(单次迭代更快)。然而,令人惊讶的是,这种零阶优化首次使用就能在非常大的模型上起作用,显示出这些模型的鲁棒性,同时也为未来研究提供了一个有趣的方向。
6
涌现能力和上下文学习
语言大模型的某些能力,如上下文学习和计算推理似乎只存在于较大规模的模型中。目前尚不清楚这些能力在训练过程中是如何获得的,以及哪些具体的性质导致了它们的出现,这些疑问激励着人们继续深入研究这一领域。
语言大模型的涌现能力是幻觉吗?
论文:https://openreview.net/pdf?id=ITw9edRDlD
涌现能力是只出现在大模型而不出现在更小模型中的一种难以预测的能力。该论文认为,与模型的规模行为无关,涌现能力主要是评估所使用的度量标准选择的结果。具体而言,非线性和不连续的度量标准可能导致模型性能出现急剧而难以预测的变化。
事实上,作者发现,在先前观察到涌现行为的算术任务中,如果将准确度改为连续度量标准,性能反而会平稳提升,不再出现急剧变化。因此,尽管涌现能力可能仍然存在,但它们应该得到适当控制,研究人员应该考虑所选择的度量标准与模型之间的交互情况。
Transformer上下文学习中涌现能力的暂时性
论文:https://arxiv.org/abs/2311.08360
Chan等人(2022年)先前已表明,语言数据的分布特性(具体而言是“burstiness”和高度倾斜的分布)在语言大模型中上下文学习(ICL)的涌现中起着重要作用。以前的研究通常假设一旦ICL能力被获取,模型就会在学习中保留这种能力。
然而,这篇论文使用了Omniglot,这是一个合成图像的少样本数据集,这时候ICL出现涌现行为,但随着损失的持续减少,涌现随后消失。另一方面,L2正则化似乎有助于模型保持其ICL能力。然而,目前尚不清楚ICL是如何涌现的,以及LLM在真实自然语言数据上进行预训练时是否可以观察到这种短暂性。
LLM逐步思考的原因:从经验的局部性看推理的涌现
论文:https://openreview.net/pdf?id=rcXXNFVlEn
本文采用合成设置,研究了在LLM中思维链推理(Wei等人,2022年)为什么以及如何能够生效。与Chan等人(2022年)的研究类似,他们研究了预训练数据的分布特性。结果显示,在训练数据是局部结构化的情况下,思维链推理才是有用的。换言之,当训练数据中的示例涉及到与自然语言密切相关的主题时,这种推理方式才能够发挥作用,而这在自然语言中是非常普遍的情况。
研究者发现,思维链推理之所以具有帮助,是因为它能够逐步建立和连接在训练过程中频繁观察到的局部统计依赖关系。然而,仍然不清楚思维链推理在训练过程中是如何出现的,以及它在最有用的下游任务中具有哪些属性。
语言大模型是潜变量模型:解释和寻找上下文学习的良好示例
论文:https://arxiv.org/abs/2301.11916
本文将语言大模型中的上下文学习框架视为主题建模,其中生成的词元受潜在主题(概念)变量的条件约束,该变量捕捉了格式和任务信息。为了使这一过程在计算上更加高效,该研究使用了一个较小的语言模型,通过在完整演示数据上进行提示调整来学习潜在概念。
然后,他们选择在经过提示调整的模型下具有最高概率的示例作为上下文学习的演示,这相对于其他选择基准有所改进。这是进一步的数据点,证明了基于任务的潜在概念示例是有用的演示数据。然而,这可能并不是完整的图景,因此探讨这种表述与其他数据相似性和多样性度量之间的关系将是一个有趣的研究方向。
Transformer的诞生:从记忆视角出发
论文:https://openreview.net/forum?id=3X2EbBLNsk
这项研究调研了在上下文学习以及在合成设置中使用一般知识的能力。实验设置包括由一个二元语言模型生成的序列,其中一些二元组需要局部上下文来推断,另一些则需要全局统计信息。研究发现,双层Transformer(而不是单层Transformer)发展出了一种归纳头,包括两个注意力头构成的“电路(circuit)”,用于预测上下文中的二元组。然后,他们冻结了一些层来研究模型的训练动态,发现模型首先学习全局二元组,归纳头以自上而下的方式学习适当的记忆。总体而言,这篇论文进一步揭示了语言模型中如何出现上下文学习的过程。
7
推理
规划和序列决策对于大模型的广泛应用至关重要。本文研究了语言大模型是否能够为常识性的规划任务制定简单的计划,但仅使用LLM时,即使是最出色的LLM生成的计划也只有12%可以直接执行。然而,当与一个自动规划算法(automated planning algorithm)结合使用时,这个算法可以识别并删除LLM生成的计划中的错误,使LLM的性能明显优于使用随机或空白的初始计划。
LLM的计划也可以通过基于外部验证器反馈的提示进行改进。然而,当行动名称难以理解且不容易通过常识推断时,LLM的优势会消失,表明其缺乏抽象推理能力。总的来说,虽然LLM生成的初始计划可以作为一个起点,但目前其规划能力主要在与外部工具结合使用时表现最佳。
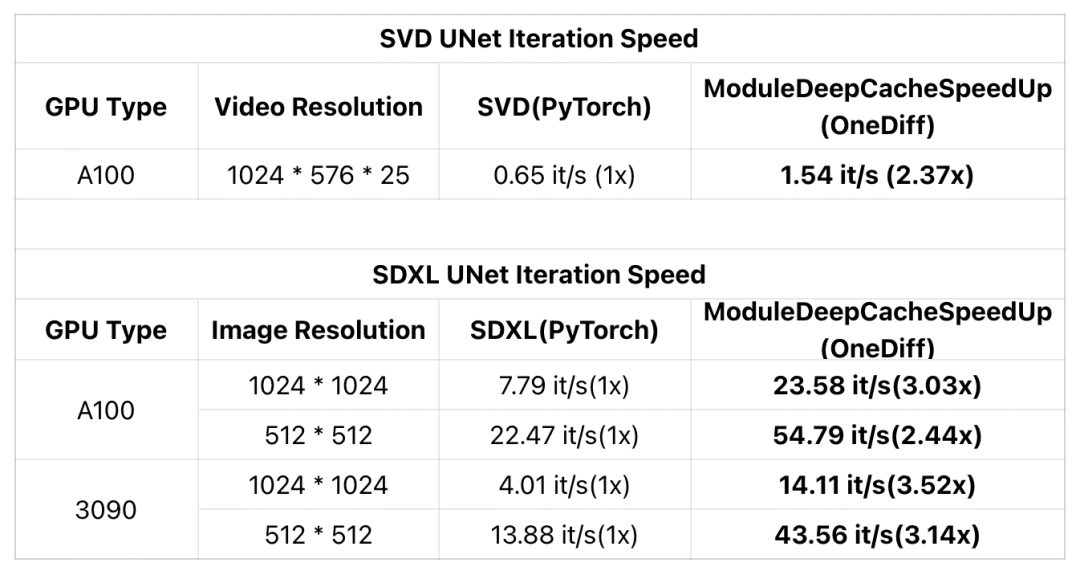
近期,DeepCache为加速扩散模型提供了一种新的免训练、几乎无损的范式。现在,OneDiff引入了一个名为ModuleDeepCacheSpeedup的新ComfyUI Node(已编译的DeepCache模块), 让SDXL在RTX 3090上的迭代速度提升3.5倍,在A100上提升3倍。
此外,OneDiff的ModuleDeepCacheSpeedup还支持SVD (Stable Video Diffusion)加速,确保视频质量几乎无损,并在A100上将迭代速度提高了2倍以上。
示例:
1. https://github.com/Oneflow-Inc/onediff/pull/426
2. https://github.com/Oneflow-Inc/onediff/pull/438
使用指南:https://github.com/Oneflow-Inc/onediff/tree/main/onediff_comfy_nodes#installation-guide
其他人都在看
试用OneFlow: github.com/Oneflow-Inc/oneflow/

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢