
01 作者简介
谢怡,网易有道高级大数据开发工程师,目前主要参与实时计算和湖仓一体方向的研发。
王涛,网易资深平台开发工程师,主要从事大数据和湖仓平台建设。
02 业务背景
有道的数据层架构可分为离线和实时两部分,离线计算主要采用Hive、Spark,采用批处理的方式定时调度。实时部分采用 Flink+Doris(版本 0.14.0)构建实时数仓,用于处理实时埋点日志、业务库变更数据。ODS 层数据源为 Kafka 埋点日志、数据库业务数据,DWD、DWS层数据通过Flink计算引擎加工,写入 Doris 中。同时将 Doris 数据定时同步至 Hive,用于离线调度计算。该架构存在如下问题:
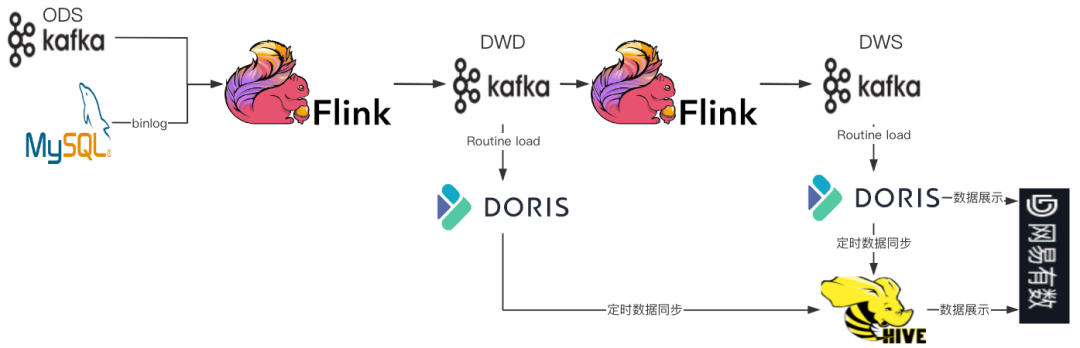
结合上述问题,有道希望从 Hive 升级为湖仓一体方案,支持流批读写,统一数据存储。并基于 Spark/Trino/Hive ETL 搭建分钟/小时级近实时数仓,降低开发和运维成本,在绝大多数场景下替换 Doris 的分钟级数仓场景,减少数据库数据同步成本,有效降本增效。
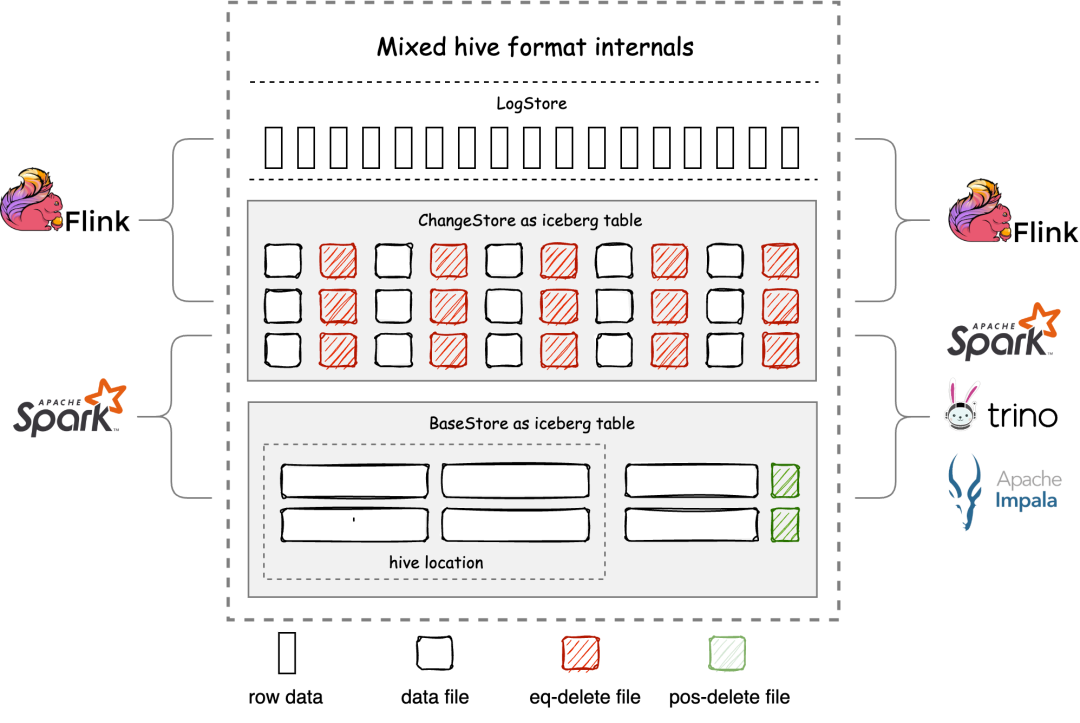
schema、partition、types 与 Hive format 保持一致。 使用 Hive connector 将 Mixed Hive 表当成 Hive 表来读写。 可以将 Hive 表原地升级为 Mixed Hive 表,升级过程没有数据重写和迁移,秒级响应。 具备湖仓一体的特性,包括基于主键 upsert,流式读写,ACID,time travel 等功能。
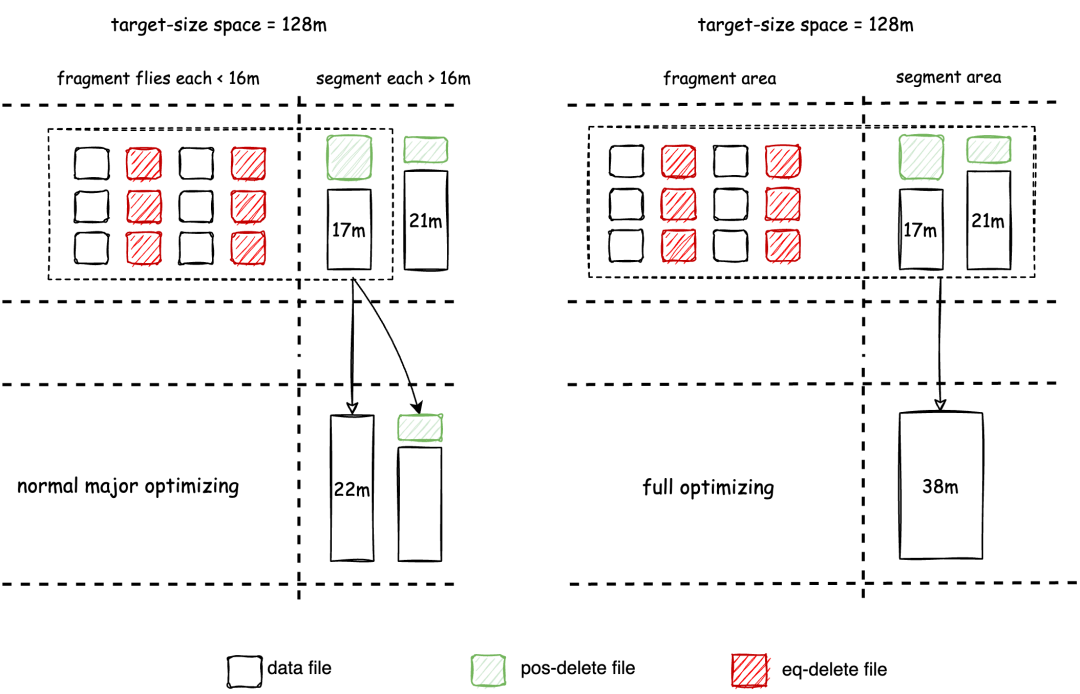
Fragment File:碎片文件,默认配置下小于 16 MB 的文件,此类文件需要及时得合并成更大的文件,以提升读取性能。
Segment File:默认配置下大于 16MB 的文件,此类文件已经具备一定的大小,但还不到理想的 128MB。
数据链路改造

1.开发方式上,贴源层的数据导入从 Flink SQL 方式改造成基于实时数据湖平台,业务通过简单的交互即可完成 Hive 升级和入湖链路的构建。
2.通过数据传输定时同步数据库到 Hive 的链路,改造成实时 Mixed Hive format 表,数据时效性提升的同时,也提前了离线 workflow 基线,数据产出时间大大提前。
3.Amoro 替换 Doirs,降低数据链路的复杂度,做到存储的流批统一,提高了稳定性。
4.数据查询端,通过直接查询 Mixed Hive format 表实现数据时效性的提升,数据报表时效性可以达到分钟级;原来查询 Hive 的报表链路时效性可以提升到小时级。
实时数据湖平台共建
为了屏蔽底层存储变更对于业务开发的学习成本, 网易杭研基于 Amoro 在内部提供了实时数据湖开发平台,封装了从 Hive 表升级到构建数据入湖全流程,帮助用户一站式完成开发和运维,降低用户的使用门槛和成本。
Hive 表升级到 Mixed Hive 表,包含主键配置、分区键配置。
创建源端到 Mixed Hive 表的入湖任务, 支持数据库 cdc 入湖、日志入湖。
基于NDC(网易数据运河) 打通从源端数据库 binlog 直接输出到 Mixed Hive 表全增量入湖链路。
支持配置日志 kakfa 到 Mixed Hive 表的实时入湖链路。
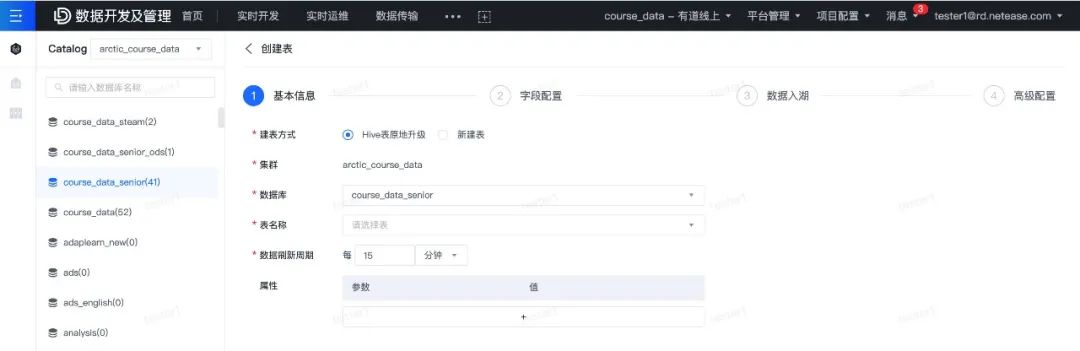
通过实时数据湖平台实现 Flink 入湖、用户编写 Spark/Trino sql 实现 DWD、DWS 层的 ETL 加工,构建分钟、小时级近实时数仓,极大降低了用户的开发成本。并且该方案存储流批统一的特点,也降低了用户数据开发和数据修复的成本。同时,Amoro 全量/增量 Flink流式读取的特性,也可以满足对时效性要求更高的流式处理场景。
在开源 Amoro 和杭研实时数据湖平台之上,有道也深度参与了社区贡献和平台共建,包括:
贡献 Mixed Format 支持 ORC 格式,解决 Amoro 只支持 Parquet 格式 Hive表的限制,避免 ORC 到 Parquet 表的拷贝才能升级的流程, 预计节省冗余存储20TB存储。
搭建 Amoro 平台监控体系、自动运维优化,保障线上表质量、数据时效性、集群稳定性。
Trino 引擎查询 Amoro 支持 Hadoop-proxy,基于有道 HDFS ranger 实现权限管理。
多项 Amoro Optimizer 优化以提高 Optimizer 稳定性,如:Flink Optimizer任务重试上报 AMS。
多项实时数据湖平台优化以提升可靠性和用户体验,如:实时数据湖平台支持 Amoro 高可用。
查询优化
目前有道主要使用 MPP 引擎 Trino 对 Mixed Hive 表进行分钟级时效性的 OLAP 查询。在大多数场景下,默认的查询性能符合要求。对于查询响应要求较高的一些场景,发现 Mixed Hive 查询性能达不到业务要求,并且比其它业务环境的查询性能差。Amoro 和有道同学分析 Trino 的查询 profile 和 底层HDFS 性能,发现了三个优化点,优化后 Mixed Hive 表的查询性能提升明显,查询耗时下降了92%,基本接近 Hive 静态数据查询,并且已经可以满足业务的要求。三个优化如下:
1.对 Query Plan 阶段,Amoro 改写了原本的 Plan 逻辑,将需要用来判断数据是否被删除的 Sequence Number 直接从一次多线程的 Plan 中获取,减少了之前单独使用一个额外的单线程 Plan 去获取该变量的开销。
2.对于数据倾斜的问题,Amoro 对 delete 文件开销较小但文件数量较多的任务进行了更细粒度的拆分,通过提高并行度,性能提升 50%。
3.有道对 HDFS 的优化,在分析过程中发现通过 Router 访问的 RPC 响应时长 .95 达到262ms, 远超正常集群的5ms 以内,通过将 HDFS 访问切到直连 HDFS集群,rpc 响应时间降为 .95 耗时 15ms,Mixed Hive 表平均查询耗时下降 83.3%。
另外,在可以降低时效性要求的场景,直接查询 Mixed Hive 的 BaseStore 也可达到分钟级的时效性,查询性能更好,可以与 Hive 查询静态数据相当。
应用情况
2023年初,Amoro 在有道开始上线应用,目前线上表数量 500+ 张、100+ TB 存储、日存储增量200GB/天,Spark/Trino 日均查询量 6000+,覆盖有道 10+ 业务部门,在续报、投放等多个场景落地了分钟级近实时数仓,并且通过 Amoro 托管的数据自优化功能,有效避免数仓业务中的小文件问题,达到持续降本提效的效果。
在替换 Doris 的实践上, 有道词典已经完成了 Amoro 替换 Doris,下掉了 Doris 集群的节点。有道精品课也逐步以 Amoro 替代 Doris,预计明年上半年完成替换。
在构建近实时数仓实践上,三个业务部门已经完成了基于 Amoro 搭建近实时数仓,整条链路的延迟最低可达 3mins。同时,实时增量写 Mixed Hive 表替代传统的全量数据传输任务,提前了离线 workflow 基线,ADS 表产出时间最快可提前 6 小时。
业务收益上,数据产出效率由 T+1 提升到小时级/分钟级, 实现更快更有效的决策分析(投放、销售策略等),为有道多个部门带来了成本降低或效率提升,比如词典社区视频播放时长提升10%, 点击率提升4.6%。
05 社区贡献
在 Amoro 开源社区,有道已有 13 个 PR 合并,包括:
Mix Table Format 支持 ORC 文件格式
Flink DDL 支持计算列和 Watermark
Trino 引擎支持 hadoop-proxy
支持 HTTP 请求创建 optimizer group
删表操作优化
Flink Optimizer failover 重试上报 AMS
06 未来规划

往期推荐

点个
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢