

新智元报道
新智元报道
【新智元导读】最近由UCSC的研究人员发表论文,证明大模型的零样本或者少样本能力,几乎都是来源于对于训练数据的记忆。
昨天,一篇系统性地研究了GPT-4为什么会「降智」的论文,引发了AI圈的广泛讨论。
随着大家对GPT-4使用得越来越频繁,用户每过一段时间都会集中反应,GPT-4好像又变笨了。

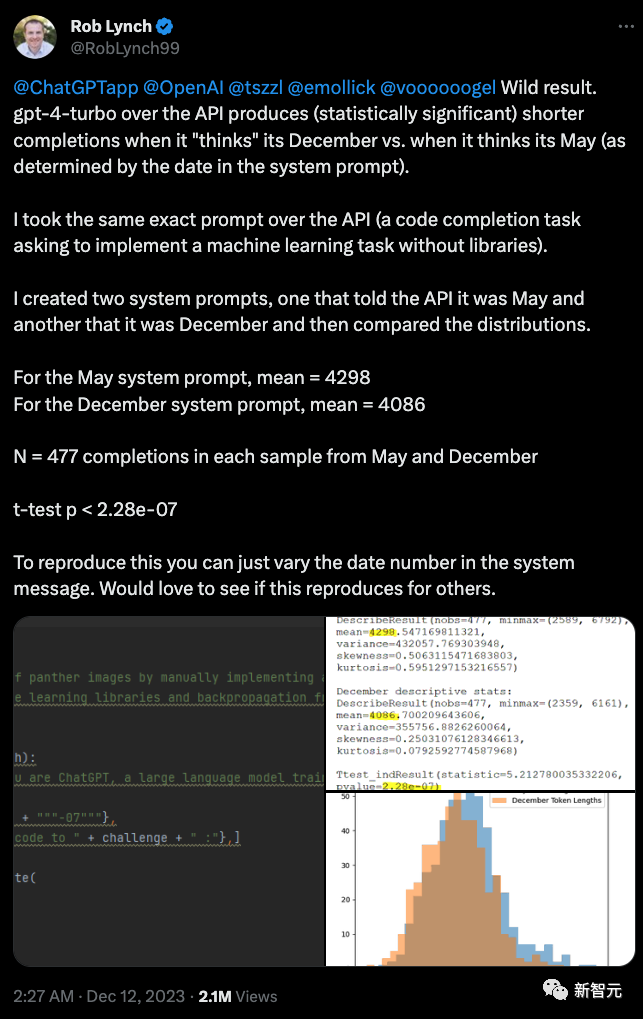
最近的情况是,如果用户不小心和GPT-4说现在是12月份,GPT-4的输出的内容就会明显变少。
有一位用户专门做了一个测试,分别告诉GPT-4现在是5月份和12月份,然后对比输出结果,发现12月份的结果比5月份差了不少。
大家讨论都觉得是说GPT-4会给自己放寒假,看到12月份就不想干活了。
但是如果放在这篇论文中来看,作者认为,最主要的原因是大模型有一个现在看来几乎是无解的缺陷——缺乏持续学习和进化能力。

论文地址:https://arxiv.org/abs/2312.16337
我们发现在LLM在训练数据创建日期之前的数据集上的表现,要明显好于在训练日期之后发布的数据集的表现。
不论是零样本还是多样本的测试中,LLM都会呈现出这种情况。
论文还指出,LLM在他们以前真正「见过」的任务上表现良好,而在新任务上表现不佳,根本原因还是因为只是记住了答案,而没有办法有效地获得新知识和理解。
而造成这种表现差别如此巨大的原因,就在于「任务污染」。

在上表中,作者发现可以从GPT-3模型中都能提取任务示例,并且从davinci到GPT-3.5-turbo的每个新版本中,提取的训练示例数量都在增加,与GPT-3系列模型在这些任务上的零样本性能提高密切相关。
说白了,之所以模型在截止时间之前的数据集测试表现良好,是因为训练数据中已经包含了数据集中的问题。
这充分说明了GPT-3系列各个版本在这些任务上的性能增强是由任务污染导致的。
对于那些不存在任务污染证据的分类任务,大型语言模型很少能在零样本和少样本设置下显著优于简单多数基准。
在上表中,研究人员也列出对于51个后训练数据收集且无提取任务示例的模型/数据集组合中,只有1个组合的模型能在零样本或少样本设置下显著优于多数基准。
这说明一旦没有任务污染的可能性,LLM的零样本和少样本表现其实并不突出。
网友们看了之后悲观地表示:目前很难构建能够持续适应且不会对已编码的过去知识和新知识造成灾难性干扰的机器学习模型。

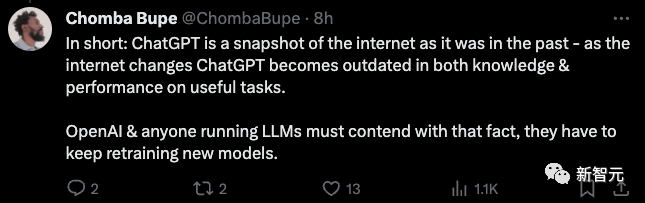
ChatGPT是过去互联网的快照 - 随着互联网的变化,ChatGPT 在有用任务的知识和性能方面都变得过时了。
OpenAI和大模型公司都必须面对这样一个事实——他们必须不断重新训练新模型。
也许,这就某种程度上为什么没过一段时间,人们就会发现ChatGPT又变笨了,也许只是因为你不断地在用新问题考它,它的真实水品慢慢地被暴露出来了。
测试模型
研究人员针对12个模型进行了测试:
5个OpenAI发布的GPT模型,7个开源的LLM。

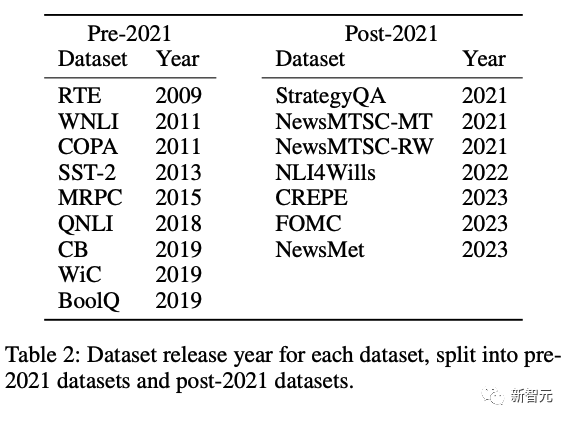
针对这些模型,他们选取了两组刚好卡在模型训练时间前后的数据集进行了测试。
测试方法
时序分析
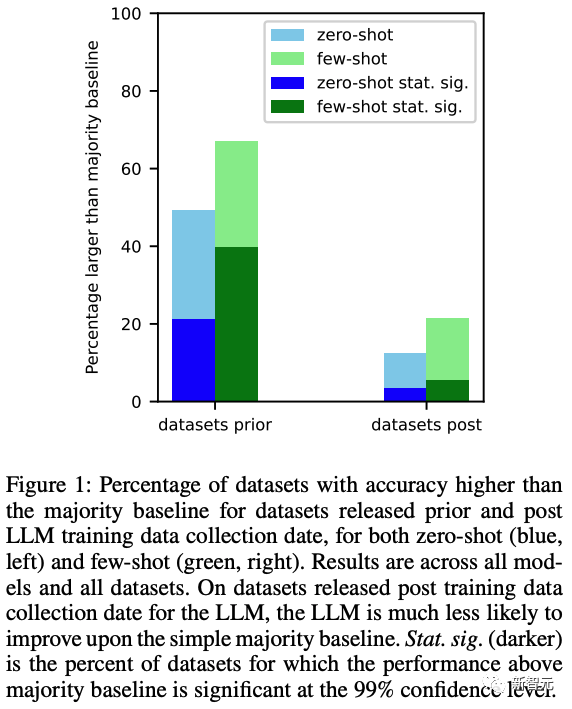
然后研究人员分别测试了不同模型在相同两组数据集上的表现。从结果可以明显看出,在模型数据训练截止日期之后发布的数据集,零样本和多样本性能明显要差了很多。
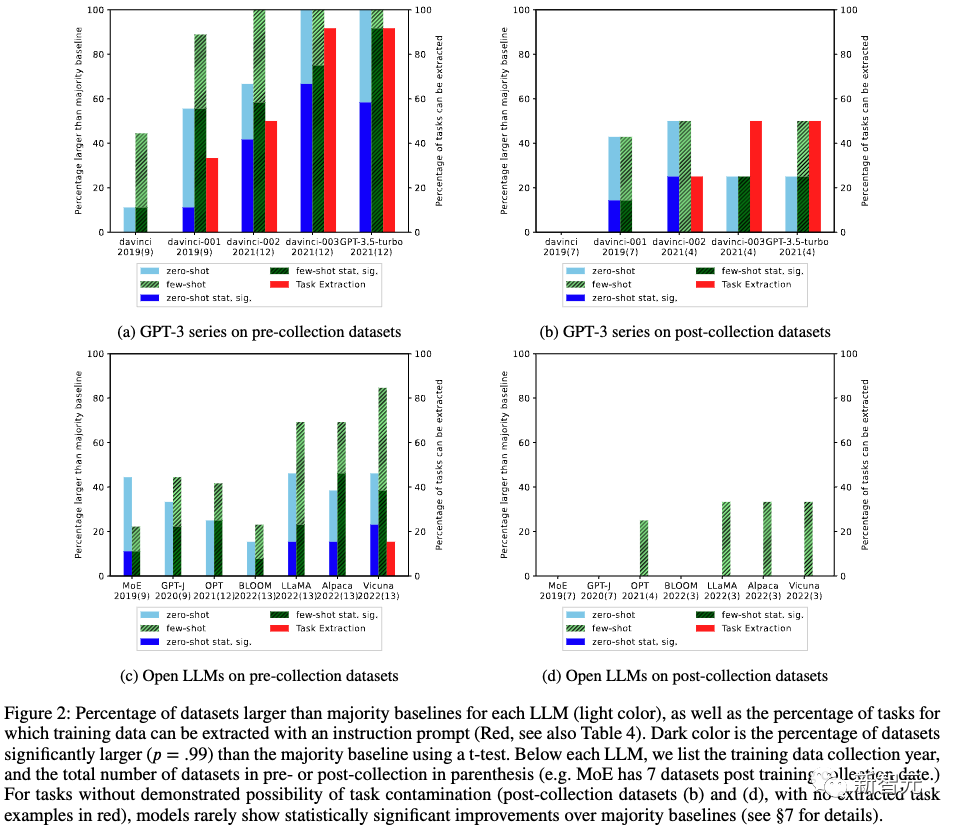
对于12个模型和16个数据集,研究人员进行了192个模型/数据集组合。
在这些组合中,136 个数据集在 LLM 培训数据收集日期之前发布(收集前),56 个数据集在之后发布(收集后)。对于这两个集合,我们计算模型击败大多数基线(零样本和少样本)的模型/数据集组合的百分比。
结果如下图 1 所示。我们发现,对于在创建 LLM 之前发布的数据集,LLM 更有可能在零和少数样本设置上击败多数基线。
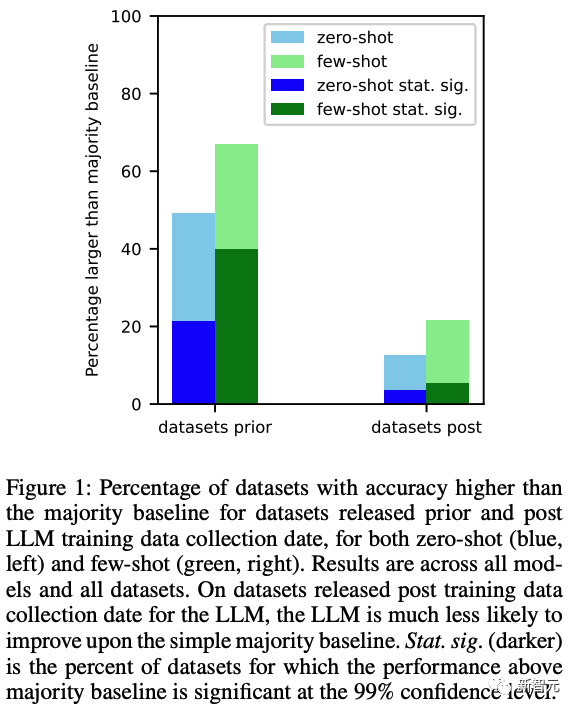
针对单个的LLM,进一步发现:
针对每个LLM单独进行测试。结果如上图2所示。这样的趋势在具有全范围日期的模型中保持不变,进一步表明数据集的绝对日期不是主要因素,而是日期数据集相对于法学硕士训练数据收集日期的变化是更重要的因素。
任务示例提取分析
如果LLM能够生成与测试数据中的示例完全匹配的示例,则证明LLM在训练期间已经看到了该任务的测试集。
研究人员采用类似的方法来测试任务污染。他们不尝试生成测试数据,而是提示模型生成训练示例,因为对于零次或少次评估,模型不应在任何任务示例上进行训练。
如果LLM可以根据提示生成训练示例,这就是任务污染的证据。
下表4显示了所有模型中所有任务的任务示例提取结果。

进一步研究人员还发现,对于没有被证明存在任务污染可能性的任务,LLM很少表现出比大多数基线具有统计显着性的改进。
在上表4中,对于收集后且没有提取任务示例的 51 个模型/数据集组合,51 个模型/数据集组合中只有 1 个(即 2%)在零样本或少样本设置的情况下表现出相对于大多数基线的统计显着改进。
成员推理分析
为了进一步检查训练数据污染的影响,研究人员应用了成员推理攻击来检查模型生成的内容是否与数据集中的示例完全匹配。
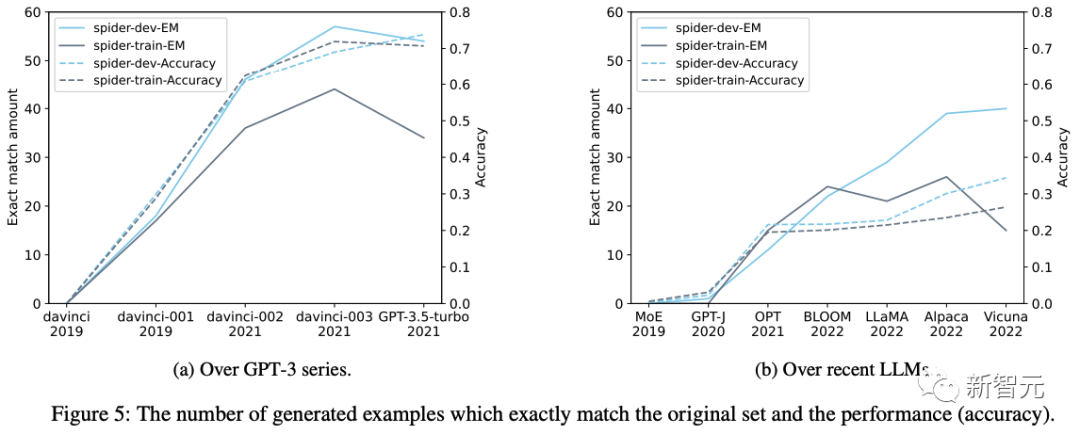
上图5a和图5b分别显示了GPT-3系列版本和最新开源 LLM 的采样训练集和完整开发集生成的示例有多少是完全相同的。
因为数据库模式(atabase schemas )不在零样本提示中,因此如果模型可以生成与训练或开发数据中完全相同的表名或字段名,则一定存在污染。
如图5所示,精确匹配生成的示例数量随着时间的推移而增加,这表明Spider上的任务污染程度正在增加。
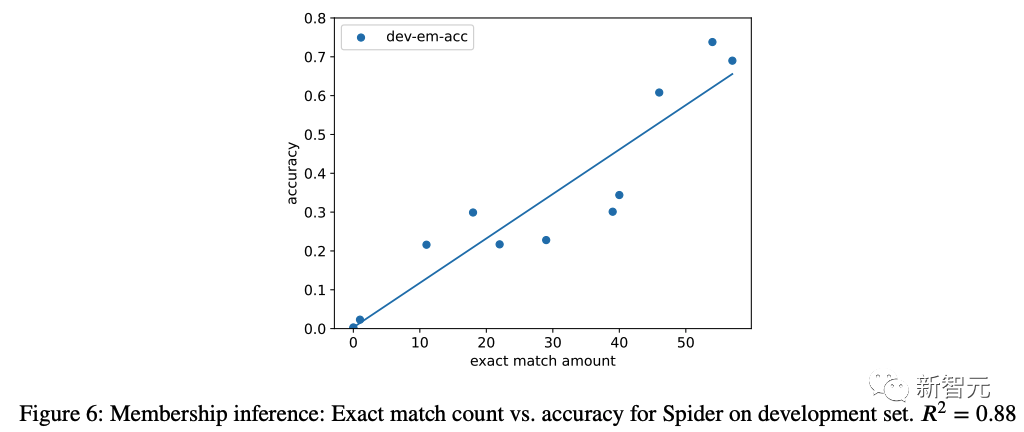
他们还在提示中添加模式后计算执行准确性,并将其与完全匹配的代数进行绘制(图 6)。我们发现完全匹配的生成示例数量与执行准确性之间存在很强的正相关性(𝑅 = 0.88),这强烈表明污染的增加与性能的提高有关。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢