
今天是2024年1月3日,星期三,北京,天气晴。
今天我们来看看一个有趣的话题,关于向量化,目前的大模型,在给定instruction后会按照指令生成相应的内容,那么对于句向量模型而言,同样一句话,可以通过给定模型不同的instruction,让模型生成适合下游任务的句向量?
《One Embedder, Any Task: Instruction-Finetuned Text Embeddings》(https://arxiv.org/abs/2212.09741)这一工作,提出了INSTRUCTOR(Instruction-based Omnifarious Representations)的思路,是一种根据任务说明计算文本嵌入的新方法:每个文本输入会与解释用例的说明(如任务和领域描述)一起进行嵌入。
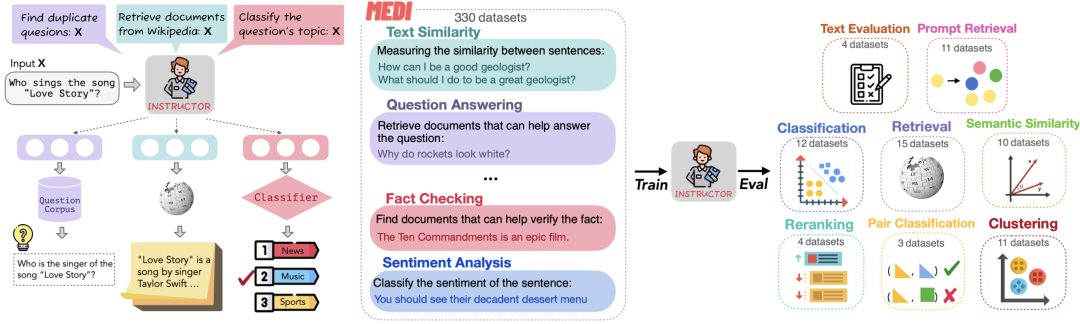
在具体实现上,该工作通过构造330种不同任务的说明,并在这种多任务上对INSTRUCTOR进行了对比损失训练,这个和当前大模型的instruction tuning工作很像。
项目地址:https://instructor-embedding.github.io
虽然该工作只支持英文,但思路很有趣,供大家一起参考。
一、INSTRUCTOR的核心思想
与之前只接受文本输入的嵌入方法不同,INSTRUCTOR方法的核心是基于指令的微调,其将每个输入与其最终任务和领域指令一起嵌入。INSTRUCTOR将相同的输入嵌入到不同的向量中,以实现不同的最终目标。
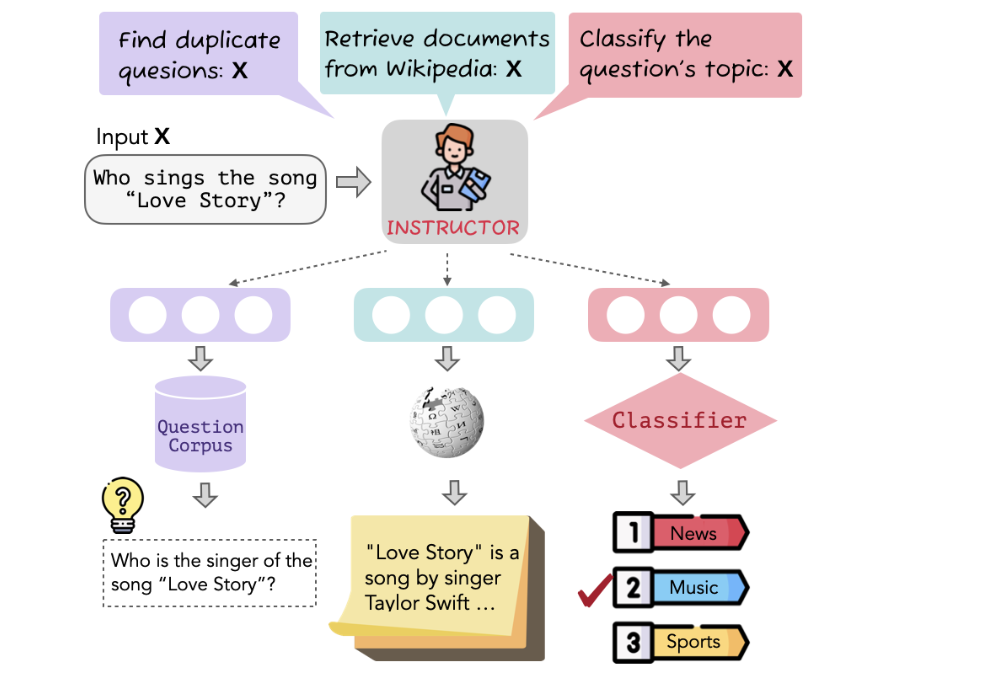
如在图1中,"谁会演唱歌曲《爱情故事》?"被嵌入到三个不同的向量中,以实现不同的任务(duplicate question detection, information retrieval, and topic classification)
最核心的,我们可以首先来看看其架构设计及目标函数。
在训练架构上,其基于单一编码器架构构建了INSTRUCTOR。使用GTR模型作为骨干编码器(GTR-Base用于INSTRUCTOR-Base,GTR-Large用于INSTRUCTOR,GTR-XL用于INSTRUC-TOR-XL)。
GTR模型训练方法虽然还是用的对比学习,但是具体计算过程跟simcse有所差异,由于每一个instance都包含(query, pos, neg),pos跟neg分别是query对应的相关文档positive跟强不相关文档hard negative,对应的对比学习的损失由两部分, 一个是同一个instance里的query跟pos是正样本,query跟同个batch里的所有neg之间都是负样本。
另一个是同一个instance里的pos跟query是正样本,pos跟同个batch里其他instance的query之间都是负样本。
Instructor采用了GTR作为初始模型,训练方法也依旧保持,只是原本的模型接受文本作为输入,instructor同时接受instruction跟文本作为输入,从而生成符合指令的句向量。
在具体数据处理上,给定输入文本x和任务指令Ix,INSTRUCTOR对它们的连接Ix⊕x进行编码。然后,通过对x中标记的最后一个隐藏代表进行均值池化处理,生成一个固定大小的任务特定嵌入模型EI(Ix,x)。
在训练方法上,INSTRUCTOR将各种任务表述为一个文本到文本的问题,即在输入x的情况下区分好/坏候选输出y∈{y+,yi-},其中训练样本对应于元组(x,Ix,y,Iy),Ix和Iy分别是与x和y相关的指令。
例如:
在检索任务中,x是一个查询,好/坏y是某个文档集中的相关/不相关文档。对于文本相似性任务,输入和输出具有相似的形式,通常来自相同的源集合。
对于分类任务来说,训练样本可以通过选择y作为与好例子和坏例子的相同类别和不同类别相关联的文本序列来构成。
输入和输出指令取决于任务,对于非对称任务,如检索,输入是一个单句查询,输出是一个文档。输入x的候选词y的好坏由相似度s(x,y)给出,相似度s是输入x和候选词y之间的余弦值。
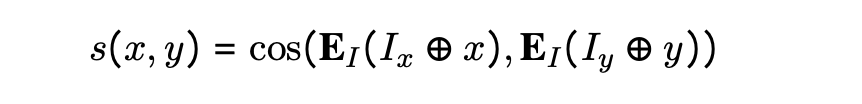
通过最大化正对(x,y+)之间的相似性,最小化负对{(x,yi-)},并计算x和y互换后的相同损失,并将其与之前的损失相加(即双向批内采样损失)。
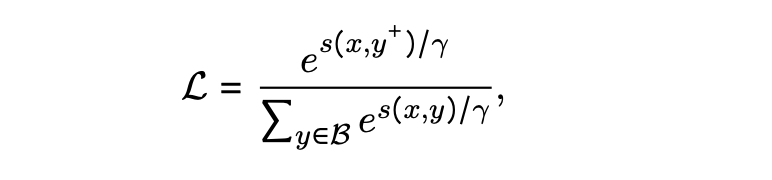
二、INSTRUCTOR的训练数据收集与指令设计
Instructor的训练数据是一个数据集集合MEDI,里面包含330个来自SuperNaturalInstructions的数据集跟30个现存的用于句向量训练的数据集。
文章(https://zhuanlan.zhihu.com/p/636129910)中说的比较好,直接引用如下:
每个数据集都包括对应的instruction,数据集中的每个instance都是如下格式:
Instance = {“query”: [instruction_1, sentence_1],“pos”:[instruction_2, sentence_2],
“neg”:[Instruction_2, sentence_3]}
如果是类似句子相似度的对称类任务,那就只有一个instruction,示例中的instruction_1跟instruction_2就是同一个,如果是类似检索的非对称任务,那么query跟doc都各有一个instruction,instruction_1跟instruction_2就是两个不同的instruction。
Sentence_2表示是跟sentence_1相关的文本,而sentence_3则是不相关的文本。通过这种数据集构造,可以保证每个instance都有自身的hard negative,以及同个batch内其他instance充当简单负样本。
在训练过程过程,为了提高难度,会保证同个batch里所有instance都来自于同个数据集。
1、训练数据收集
构建了一个包含不同任务类别和领域指令的330个数据集的集合-多任务指令嵌入数据(MEDI),主要包括将超级自然指令集(Super-NI)中的300个数据集与现有嵌入训练数据集中的30个数据集相结合。
1)超级自然指令集(Super-NI)
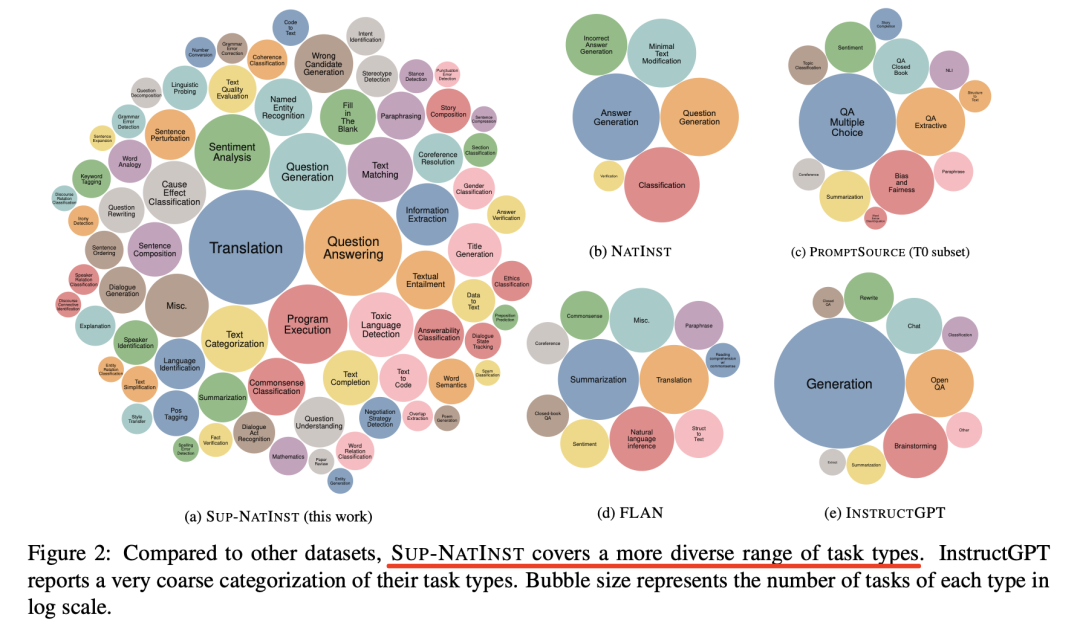
其中提到一个数据集《Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks》(https://arxiv.org/pdf/2204.07705.pdf),SUPER-NATURALINSTRUCTIONS(简称SUP-NATINST)是一个包含1616个NLP任务及其自然语言指令的大型基准,汇集了各种各样的任务--76种广泛的任务类型,涵盖55种不同的语言。
每项任务都与一个指令配对,该指令包括将输入文本映射到任务输出的任务定义,以及将输入文本映射到任务输出的几个示例。
数据地址放在:https://huggingface.co/datasets/andersonbcdefg/supernatural-instructions-2m
对应的github地址放在:https://github.com/allenai/natural-instructions/tree/master
该数据的特点在于:所有任务指令都遵循相同的统一模式,该模式由以下部分组成:
定义(DEFINITION)用自然语言定义给定任务,是输入文本(如句子或文档)如何映射到输出文本的完整定义;正面示例是输入及其正确输出的示例,并附有简短的解释;负面示例是输入及其错误/无效输出的示例,以及对每个示例的简短解释。

2、其他数据
其他30个嵌入训练数据集分别来自SentenceTransformers嵌入数据、KILT和MedMCQA。
其中:
SentenceTransformers嵌入数据,可以查看https://huggingface.co/datasets/sentence-transformers/embedding-training-data
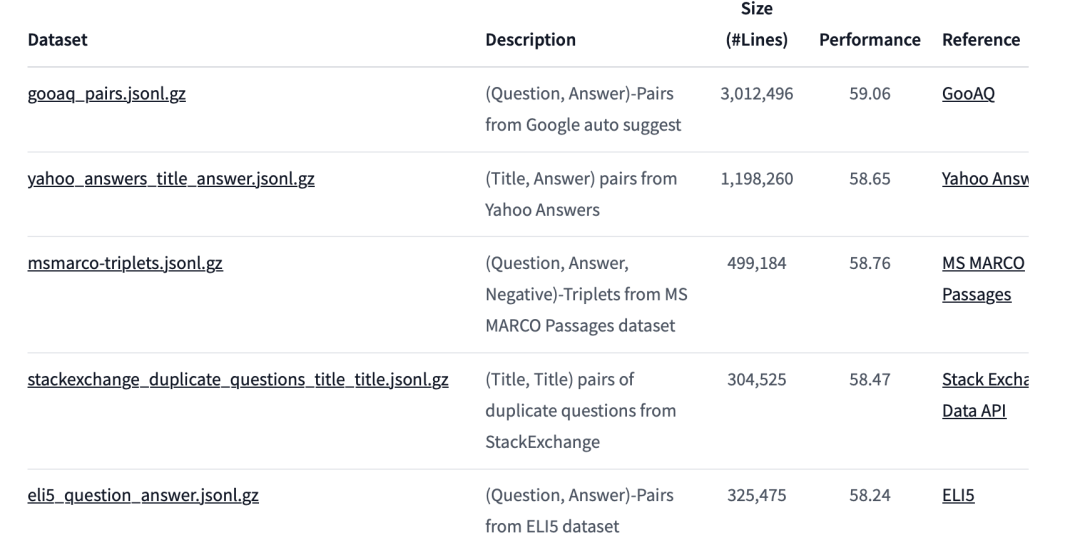
KILT《KILT: a benchmark for knowledge intensive language tasks》(https://arxiv.org/pdf/2009.02252.pdf)是一个知识导向的任务数据集。

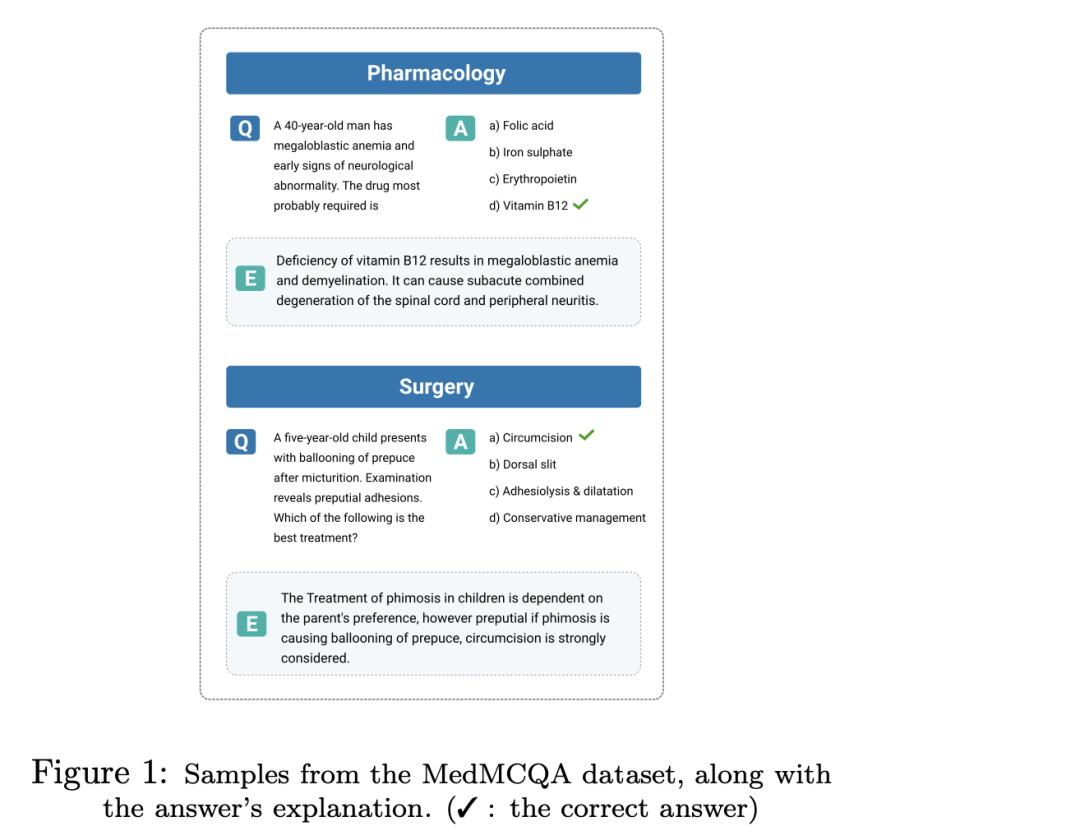
MedMCQA《MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering》(https://arxiv.org/pdf/2203.14371.pdf)是一个面向医学领域的多项选择题数据集。
3、训练数据的instruction设计
MEDI的每个训练实例都是一个元组(x,Ix,y,Iy),其中自然语言指令Ix和Iy描述了如何在任务中使用x和y的嵌入。
例如,在开放问答领域,Ix是"表示维基百科问题,用于检索支持文档;输入:,",Iy是"表示维基百科文档,用于检索;输入:,"。
为了使MEDI中所有数据集的指令保持一致,该工作设计了统一指令格式,其中:
文本类型指定我们使用嵌入模型进行编码的输入文本类型。
任务目标(可选)描述任务中如何使用输入文本的目标。
领域(可选)描述的是主要任务。
1)symmetric对成性任务提示的设计
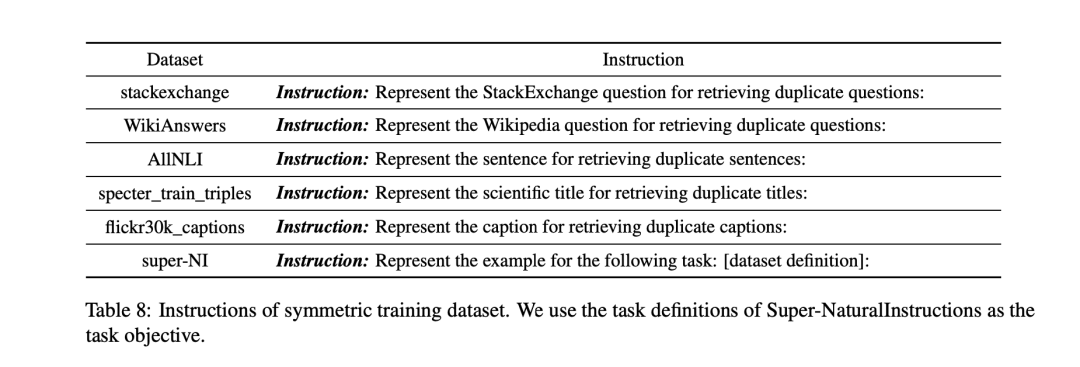
2)asymmetric反对称任务提示的设计

最后形成的训练数据如下,地址在https://drive.google.com/file/d/1_Ax8rTeeDKpNxj85LD2Yh7qsh3sYEiSH/view?usp=sharing:

三、INSTRUCTOR的模型的使用
可以在https://github.com/xlang-ai/instructor-embedding中找到调用方式。
权重地址:https://huggingface.co/hkunlp/instructor-large
pip install InstructorEmbedding
模型调用方式:
from InstructorEmbedding import INSTRUCTOR
model = INSTRUCTOR('hkunlp/instructor-large')
sentence = "3D ActionSLAM: wearable person tracking in multi-floor environments"
instruction = "Represent the Science title:"
embeddings = model.encode([[instruction,sentence]])
print(embeddings)
总结
本文主要介绍了结合指令的向量化方案,很有趣。其中涉及到的一些任务数据集,可以关注,现在提升预训练大模型的下游任务能力,任务数据集扮演着很重要的角色。
参考文献
1、https://arxiv.org/abs/2212.09741
2、https://github.com/xlang-ai/instructor-embedding
3、https://zhuanlan.zhihu.com/p/636129910
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢