
引言
在大语言模型中,我们期望模型能够理解人类语言的一般规律,从而做出和人类相似的表达方式,通过使用大量的数据进行训练从而获得使模型学习到数据背后的一般规律。在训练预训练模型时,通常有两个可以提高大语言模型性能的选项:增加数据集大小和增加模型中的参数量。在此基础上,训练过程中还存在一个限制条件,即训练成本,比如GPU的数量和可用于训练的时间等。因此,大语言模型的预训练,通常伴随着模型容量、数据量、训练成本的三方权衡博弈。
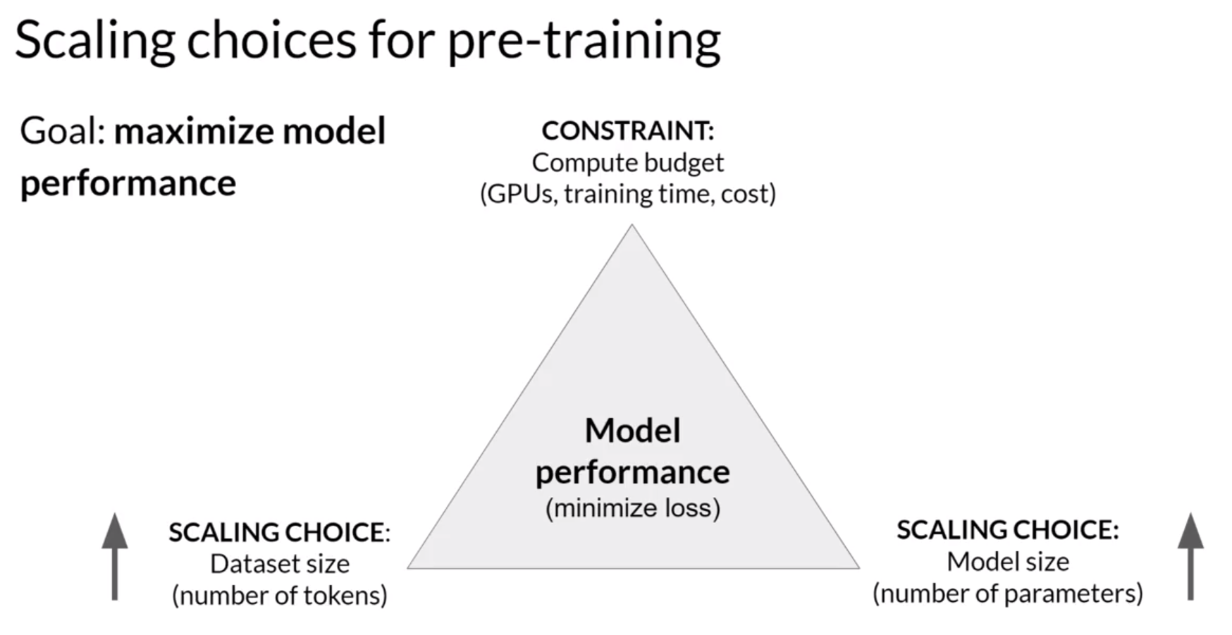
Figure 1. 模型规模扩展的选项概览
什么是Scaling Laws
对于这种三角形式的拔河关系,往往存在一些三元悖论,比如分布式计算领域中的公认定理:CAP理论。分布式系统不可能同时满足一致性、可用性和分区容错性,最多只能同时满足其中2个条件。大语言模型训练中同样存在类似这种三元关系的探索,这就是缩放定律(Scaling Laws)。
在大语言模型预训练过程中,交叉熵损失(cross-entropy loss)是一种常用的性能衡量标准,用于评估模型预测输出与真实情况之间的差异。较低的交叉熵损失意味着模型的预测更准确。训练的过程也是追求损失值的最小化的过程。
Scaling Laws的意义在于,AI专业人士可以通过Scaling Laws预测大模型在参数量、数据量以及训练计算量这三个因素变动时,损失值的变化。这种预测能帮助一些关键的设计决策,比如在固定资源预算下,匹配模型的最佳大小和数据大小,而无需进行及其昂贵的试错。
OpenAI V.S DeepMind
DeepMind
We’re a team of scientists, engineers, ethicists and more, committed to solving intelligence, to advance science and benefit humanity.
—— DeepMind
DeepMind,成立于2010年并于2015年被谷歌收购,是Alphabet Inc.的子公司。该公司专注于开发能模仿人类学习和解决复杂问题能力的AI系统。作为Alphabet Inc.的一部分,DeepMind在保持高度独立的同时,也在利用谷歌的强大能力推动AI研究的发展。
DeepMind在技术上取得了显著成就,包括开发AlphaGo,击败世界围棋冠军李世石的AI系统,展示了深度强化学习和神经网络的潜力,开启了一个AI时代。另一项重要成就是AlphaFold,这是一个革命性的用于准确预测蛋白质折叠的工具,对生物信息学界产生了深远影响。DeepMind用AI进行蛋白质折叠预测的突破,将帮助我们更好地理解生命最根本的根基,并帮助研究人员应对新的和更难的难题,包括应对疾病和环境可持续发展。
OpenAI
“Our mission is to ensure that artificial general intelligence—AI systems that are generally smarter than humans—benefits all of humanity.”
——2023年2月14日《Planning for AGI and beyond》
在谷歌收购DeepMind后,为避免谷歌在AI领域形成垄断,埃隆·马斯克和其他科技行业人物于2015年决定创建OpenAI。它作为一个有声望的非营利组织,致力于开发能够推动社会进步的AI技术。不同于DeepMind 像一个精于解决棋盘上复杂战术的大师,专注于解决那些有明确规则和目标的难题,OpenAI更像是一个擅长语言艺术的诗人,致力于让机器理解和生成自然的人类语言。
从坚持初期被外界难以理解的GPT路线信仰,直到拥有1750亿参数的GPT-3问世,OpenAI展示了其在生成式模型上无与伦比的能力,引领了另一个AI时代。类比Deepmind和谷歌的关联,OpenAI与科技巨头微软牵手,展开了深度的战略合作,进一步推进AI技术的发展。

Figure 2. Deepmind和OpenAI核心产品发展时间线(原创)
OpenAI在Scaling Laws研究中的主要成就 —— GPT系列模型
2020年,来自OpenAI的Kaplan等人的团队,在《Scaling Laws for Neural Language Models》论文中首次提出模拟神经语言模型的模型性能(Loss)与模型大小 、数据集大小和训练计算量的关系。该团队发现三者中任何一个因素受限时,Loss与其之间存在幂律关系。【注:幂律指的是两个变量中的一个变量与另一个变量的某个幂次成正比。如果体现在图表中,当两个轴都是对数时,图像呈现为直线】

Figure 3. Loss随着模型大小、数据集大小和用于训练的计算量的增加而平稳下降
该团队的研究结论总结如下:
- 影响模型性能的三个要素之间,每个参数会受到另外两个参数的影响。当没有其他两个瓶颈时,性能会急剧上升,影响程度为计算量 > 参数 >>数据集大小。
- 在固定计算预算下进行训练时,最佳性能可以通过训练参数量非常大的模型并在远离收敛前停止(Early Stopping)来实现。

Figure 4. 参数量为10^3到10^9不等的几个模型,训练运行中的Loss随训练token和计算量的变化曲线
- 更大的模型在样本效率方面表现更好,能以更少的优化步骤和使用更少的数据量达到相同的性能水平。在实际应用中,应该优先考虑训练较大的模型。
OpenAI的观点可以翻译为:
如果大语言模型的训练过程是一位厨师在制作一道复杂菜肴。那么语言模型的性能就是这道菜的最终口味。
模型大小是厨师水平。更有经验的厨师(更大的模型)通常能做出更美味的菜肴。随着厨师技能的提升,菜肴的味道(模型性能)也会随之提升。
数据集大小是厨师可以使用的食材种类和数量。更多的食材选择(更大的数据集)意味着厨师有更多的组合方式来创造美味(更好的模型性能)。
训练的计算量是准备和烹饪食物的时间及所用的厨具。更多的准备和烹饪时间,以及更好的厨具(更多的计算资源),通常能使菜肴更加精致。
OpenAI的研究就像在不断调整这三个方面(厨师的技能、食材的多样性和烹饪的资源),以最终制作出一道口味卓越的菜肴。并从其中得到的经验:影响制作出一道美味的菜肴(高性能的语言模型)的因素,烹饪的资源(训练的计算量)>厨师的技能(模型大小)>>食材的多样性的影响(训练的计算量)。因此,为了资源更好的利用,应该优先选择更大的模型。
也正是因为这项研究,OpenAI有了在数据和参数规模上Scaling-up的信心,在同年的四个月后,火爆全球的GPT3问世。
DeepMind在Scaling Laws研究中的主要成就 —— Chinchilla
2022年,来自Deepmind的Hoffmann等人的团队,在《Training Compute-Optimal Large Language Models》提出了与OpenAI截然不同的观点。
OpenAI建议在计算预算增加了10倍的情况下,如果想保持效果,模型的大小应增加5.5倍,而训练token的数量仅需增加1.8倍。Deepmind这支团队则认为模型大小和训练token的数量都应该按相等的比例进行扩展,即都扩大三倍左右。该团队还暗示许多像GPT-3这样的千亿参数大语言模型实际上都过度参数化,也就是说它们的参数量超过了实现良好的语言理解所需,并训练不足。
该团队的研究结论如下:
- 对于给定的FLOP预算,损失函数有明显的谷底值(Figure3):模型太小时,在较少数据上训练较大模型将是一种改进;模型太大时,在更多数据上训练的较小模型将是一种改进。也就是说,在给定的计算量下,数据量和模型参数量之间的选择平衡存在一个最优解。

Figure 5. 给定不同的FLOP预算(不同颜色),训练损失和模型参数量的关系
- 在计算成本达到最优情况下,模型大小和训练数据 (token) 的数量应该等比例进行缩放,即:如果模型的大小加倍,那么训练数据的数量也应该加倍。对于给定参数量的模型,最佳的训练数据集大小约为模型中参数量的20倍。比如,对于一个7B的模型,理想的训练数据集大小应该约为140B tokens。
- 大模型训练需要更加关注数据集的扩展,但是只有数据是高质量的时候,更大数据集的益处才能体现出来。
回到刚才做菜的比喻,Deepmind的观点是认为当烹饪资源(计算量)一定时,厨师的水平(模型规模)和食材多样性(数据大小)同等重要。而一个厨师,拥有自己水平20倍丰富度的食材,做出的菜才是最佳效果。
基于这种模型规模和数据量的重新评估,他们训练了Chinchilla模型,一个基于1.4T tokens训练的70B模型,并发现Chinchilla的表现在大范围的下游任务评估中一致且显著地优于Gopher(280B)、GPT-3(175B)、Jurassic-1(178B)和Megatron-Turing NLG(530B)。
这个现象,某种程度上代表了大语言模型发展的一个新方向,从一味追求模型规模的增加,变成了优化模型规模和数据量的比例。
国内有什么观点?
目前国内关于讨论Scaling Laws的论文还不是很多。根据目前搜集到部分公开资料看到了百川智能的Baichuan2和北京理工大学的明德大模型(MindLLM)的论文中讲述了自己对scaling law的尝试。两者在真正着手训练数十亿或者百亿参数的大语言模型之前,训练多个小型模型为训练更大的模型拟合拓展规律。具体做法是在同一套(足够大)的训练集上,采用一致的超参数设置,独立训练每个模型,收集训练的计算量和最终损失。而后以OpenAI论文中结论的幂律关系拟合,预测出期望参数量模型的训练损失。
百川的做法是在开始训练7B和13B参数量模型前,设计大小从1000万到30亿不等的7个模型,采用一致的超参数,在高达1Ttoken的数据集上进行训练。基于不同模型的损失,拟合出了训练浮点运算次数(flops)到训练损失的映射,并基于此预测了最终大参数模型的训练损失。(Figure 5)

Figure 6. Baichuan2的缩放定律: 使用1万亿个token训练了从1000万到30亿参数不等的7个模型,对给定训练浮点运算次数(flops)时的训练损失进行幂律拟合(蓝线),从而预测了在2.6万亿token上训练Baichuan2-7B和Baichaun2-13B的损失。拟合过程精确预测了最终模型的损失(两颗星标记)
明德大模型团队的关注点与百川相似,在训练3B模型前,在10b Tokens 上训练了参数量从1000万到5亿的5个模型,通过分析各个模型的最终损失,同样基于幂律公式,建立从训练浮点运算次数(FLOPs)到目标损失的映射,以此预测最终大参数模型的训练损失。(Figure 6)

Figure 7. MindLLM的缩放定律: 在100亿token的数据集上训练参数从1000万到5亿参数的5个模型。通过对训练浮点运算次数(FLOPs)和损失幂律拟合,预测使用5000亿token的数据集训练MindLLM-3B的最终训练损失。该拟合过程准确预测了模型的最终损失,用星星标记。
此外,李开复零一万物团队的黄文灏,在知乎上关于Yi大模型的回答也较有代表性:”Scaling Law is all you need:很多人都认为scaling law就是用来算最优的数据和参数量的一个公式,但其实scaling law能做的事情远不止如此。为了真正理解scaling law,要做的第一件事就是忘记Chinchilla Scaling Law,然后打开OpenAI的Scaling Law的paper,再把paper中OpenAI引用自己的更早的paper都详细的读几十遍"。 其中Chinchilla Scaling Law指的是Deepmind思想。黄文灏认为大模型需要的是系统性的研究,把基础研究做好,才能更好的支持scale up。
OpenAI和Deepmind哪个会更早到达AGI?
Deepmind 在《Levels of AGI: Operationalizing Progress on the Path to AGI》中提出了一个直观的分类方法,可以帮助更清楚地理解 AGI 的各个发展阶段。如下图所示,这个分类体系基于两个关键维度:性能(深度)和泛化性(广度)。其中,性能(深度)分为了 Level 0-5,代表无AI-涌现-胜任-专家-大师-超人类五个能力层次;泛化性(广度)分为了专用(Narrow)和通用(General)两个维度。专用指类似于专精于特定领域或任务的专家。而通用更像是多才多艺的全能型人才,能够处理广泛的非物理任务,包括学习新技能等元认知能力。这个系统就将AGI 分成了12个有独特特征的层级,就像我们职场中的不同职级一样,每个等级都代表了不同的能力和责任。(Figure 7)

Figure 8. 根据能力的深度(性能)和广度(通用性)对走向AGI(人工通用智能)的系统进行分类
在DeepMind发布的标准中,OpenAI的ChatGPT在通用能力上还处于Level 1 的阶段,能力等同或略强于没有经过训练的人类。而DeepMind的AlphaFold在专业能力上,已经处于Level 5 阶段,在特定领域上的表现将100%强于人类。
不难看出,DeepMind 的 AI 系统更关注具体任务上,比如深蓝和 AlphaGo 属于人类大师水准,而 AlphaFold 和 AlphaZero 表示已经超越了人类。Google的语言模型过去也更看重下游任务的表现。相比之下,OpenAI 的 ChatGPT,一直保持着追求新兴的高泛化 AI 特性的理念,倒是DALL.E 在这个标准中位于专家水平。
随着Google高调发布Gemini,我们看到搜索霸主与屠龙少年,现在都迈入了同一条波涛汹涌的河流。
此前, Pichai 被问到:
“没抢在 ChatGPT 前发布 Bard,你错过了什么?”
Pichai 回答:
“谷歌不是第一个做出搜索引擎,也不是第一个做出浏览器。有时候成为第一很重要,但有时候无关紧要。”
我们很难判断未来到底谁是最终赢家,谁将会第一个到达AGI或是以什么方式到达,但是我们相信,你追我赶才是技术研发创新和市场充满活力的良好状态。
结语
竞争有时候不仅是技术的较量,也是对未来愿景的探求。中国在大模型基础研究的起步时间虽然稍晚,但目前国内市场也体现出了较高的参与热情。
这场关于大模型竞争的深远影响或许会远超过单纯的技术突破。它引发了全球对人工智能的深思和投资,激发了一个更广阔的讨论:在构建智能的未来时,我们的目标和道路应该是什么。可能最后,通过全球范围内的合作与知识共享,会共同铺就了人工智能发展的多元化道路。在这个过程中,我们将不仅见证技术的飞跃,也会参与对人类与机器共存的未来塑造。
原创外插图来自
《Scaling Laws for Neural Language Models》
《Training Compute-Optimal Large Language Models》
《Baichuan 2: Open Large-scale Language Models》
《MindLLM: Pre-training Lightweight Large Language Model from Scratch, Evaluations and Domain Applications》
《Levels of AGI: Operationalizing Progress on the Path to AGI》
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢