
今天是2024年1月5日,星期五,北京,天气晴。
今天我们再来谈谈一些有趣的话题。
一个是与mixtral并行方式不同的嫁接模型SOLAR,很像缝合怪,这个思路很有趣,社区也做了讨论。
另一个话题还是延续开放数据集的事情,面向实体识别及提升数学能力的微调指令数据集,关注数据的工作,这些都是模型性能提升的关键。
供大家一起参考。
一、有趣的嫁接模型SOLAR
早上读到张俊林老师的一条微博(https://weibo.com/1064649941/4986390481209085),很有趣,现在引用出来,一起参考。
《SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling》(https://arxiv.org/abs/2312.15166)这一工作,提出了一个模型嫁接的一种思路,很有趣,用不同预训练模型嫁接到一起。
1、基本思想是什么
其思想在于深度缩放(Depth Up-Scaling),在有n层的基础模型上,为缩放模型设定目标层数s,这取决于可用的硬件。
根据上述方法,深度缩放过程如下:复制包含n层的基础模型,以便后续修改。然后,从原始模型中移除最后的m层,并从其副本中移除最初的m层,从而形成两个不同的n-m层模型。最后将这两个模型连接起来,形成一个具有s=2-(n-m)层的缩放模型。
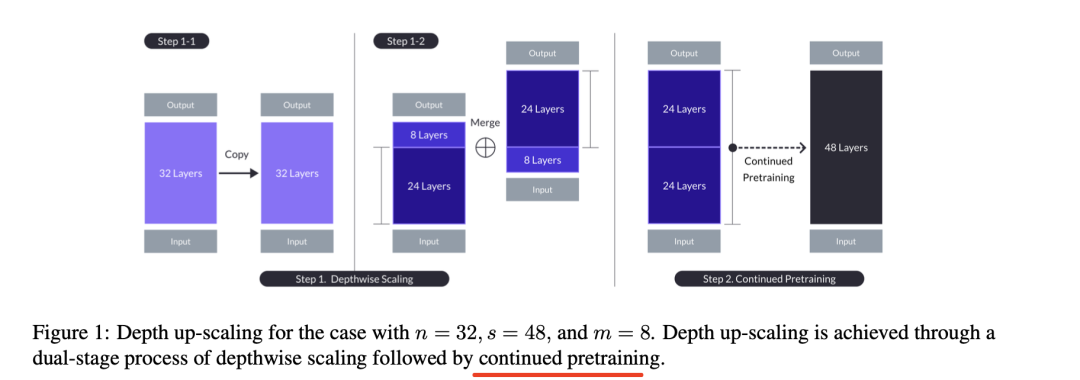
如图1所示,基础模型中n=32,考虑到硬件限制和效率,考虑到硬件限制和缩放模型的效率(即拟合70亿至130亿个参数),设置s=48,但尚未确定这个值是否是提高性能的最佳值。
也就是说,训练好的Mistral 7B模型Transformer结构有32层,把Mistral的32层从第24层掰成两段(底层24层,高层8层),之后高层那段的8层上移,中间留出16层的参数空间,接下来把Mistral的第9层到25层这16层插入中间,通过这种嫁接形成48层的SOLAR模型,参数规模由Mistral 7B拓展到了10.7B。
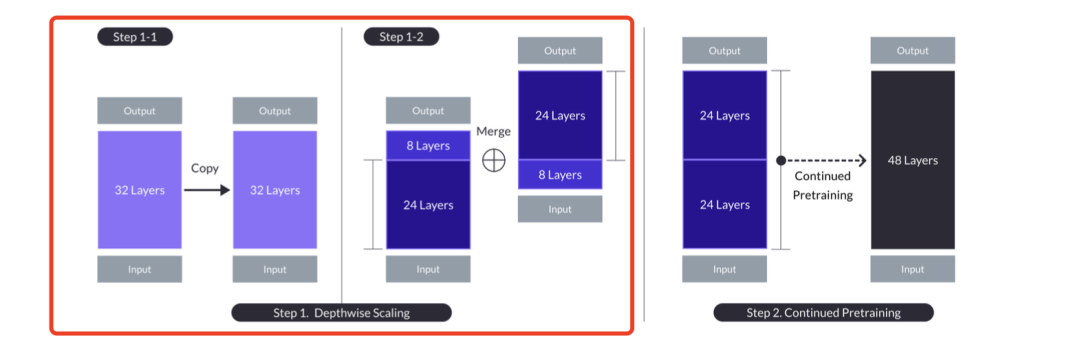
因为嫁接过程都是用的Mistral,所以是自我嫁接。
2、继续预训练及SFT
嫁接完之后效果如何,比Mistral差【但没有数据支撑】,因为嫁接的两个部分参数还没有融合成为一个整体,第25层附近是个断层。
使用3Trillion的数据进行“继续预训练”,在持续预训练过程中,观察到缩放模型的性能恢复很快,深度缩放的特殊方式隔离了缩放模型中的异质性,从而实现了性能的快速恢复。
缩放模型的异质性,一个比深度缩放更简单的替代方法是再次重复其层数,即从n层到2n层。这样,"层距 "或基本模型中的层指数差只有在层n和n+1相连的地方(即接缝处)才大于1,但这会导致接缝处的层距达到最大值,而这一差异可能过于明显,持续的预训练无法快速解决,但深度缩放牺牲了2m的中间层,从而减少了接缝处的差异,使持续预训练更容易快速恢复性能。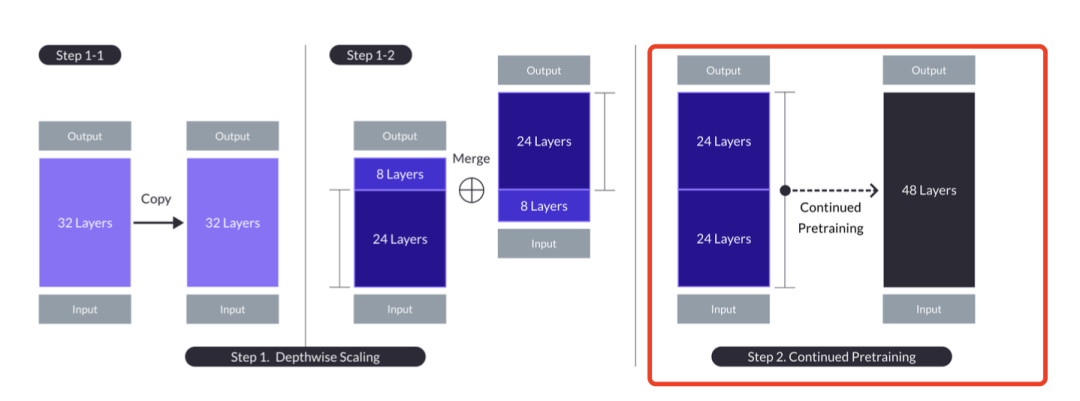
这步对嫁接模型参数进行融合的,不过貌似用的数据量有点大,很多人有这个数据量和算了,可以重新训练一个模型,形成了SOLAR-base基座模型。

在继续预训练之后,又引入两个阶段:instruct tuning和alignment tuning。
其中:
instruct tuning,采用开源instruct数据并改造出一个数学专用instruct数据,以增强模型的数学能力;
alignment tuning,开源+数学增强数据,采取DPO,这个环节对应传统的RLHF阶段。这样形成了SOLAR-chat版本。
4、最终形成的模型
合并模型的代码放在:https://github.com/cg123/mergekit#merge-methods
模型地址放在:https://huggingface.co/upstage/SOLAR-10.7B-v1.0

二、面向实体识别及提升数学能力的微调指令数据集
在前面的文章中,我们介绍了关于面向NLP的指令微调数据集,我们现在再来看看
1、chinese_ner_sft
中文实体识别指令数据集,收集开源的实体识别数据集, 将其制作为sft数据集用于LLM微调。
包括的实体数据集:

数据的样例:
{
"prompt": "在做手机智能助手上, 你需要识别用户话语中的关键实体, 实体类型包括:\n联系人姓名,场景,主旋律,乐器名称,曲风,手机号码,语言,时代,目的地,流行榜单,情绪,出发地点,曲名\n\n用户的话语为:\n来一首周华健的花心\n\n请按以下格式输出实体:\nText: 实体的原始文本, 从原句子中截取.\nLabel: 实体类型, 以上给出的实体类型之一.\n\nTips:\n1. 可同时输出多个实体.\n2. 没有实体时可回答: 找不到任何相关的实体.",
"response": "Text: 花心\nLabel: 曲名"
}
地址:https://huggingface.co/datasets/qgyd2021/chinese_ner_sft
2、面向数学能力的开放数据集
我们在之前的文章中有介绍过mathpile数据集,现在,我们来看看其他的数据集。
1)open-web-math
OpenWebMath是一个数据集,包含互联网上大部分高质量的数学文本。该数据集是从CommonCrawl上超过200B的HTML文件中筛选和提取出来的,共包含630万个文档,总计1470B个词组。OpenWebMath用于预训练和微调大型语言模型。
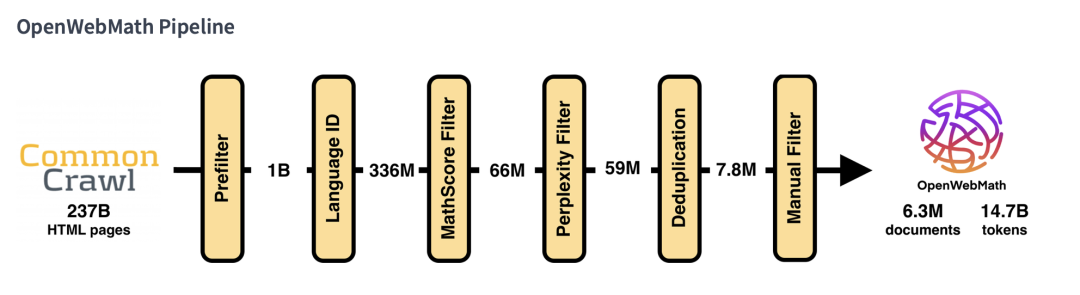
地址:https://huggingface.co/datasets/open-web-math/open-web-math
2)proof-pile-2
Proof-Pile-2是一个包含550B的数学和科学文档数据集,创建该数据集是为了训练Llemma7B和Llemma34B模型由三个子集组成:
arxiv(29Btokens):RedPajama的ArXiv子集;
open-web-math(15Btokens):OpenWebMath数据集,其中包含大量来自互联网的高质量数学文本;
algebraic-stack(11Btokens):代数堆栈数据集:一个新的数学代码数据集,包括数值计算、计算机代数和形式数学。
地址:https://huggingface.co/datasets/EleutherAI/proof-pile-2
地址:http://arxiv.org/abs/2310.10631
总结
本文主要介绍了有趣的嫁接模型SOLAR以及面向实体识别及提升数学能力的微调指令数据集两个话题。
当然,也有一些新的话题出来,比如垂领域通用能力遗忘,是否这样收益也比较大,一个自训练的垂领域模型+能力较好的通用模型,看了应该分第二步应该分主附模型,这个怎样做比较好呢?比如,如果两个不同的base模型,尤其是差异很大,估计缝合起来效果不会好,基于同个基座寻得垂领域模型,再缝合原始基座呢。
又如做一个vqa的任务,想用多模态模型比如visualglm来做。如果我把visualglm里的视觉模态模型BLIP替换成其他的模型,是不是只能从头训练,没办法lora finetune。
还是那些建议,关注数据的工作,这些都是模型性能提升的关键。
参考文献
1、https://arxiv.org/abs/2312.15166
2、https://weibo.com/1064649941/4986390481209085
3、https://zhuanlan.zhihu.com/p/636129910
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢