

编者按:随着大型语言模型(LLM)如GPT-4的发展,人们对这些模型是否真正模拟人类逻辑和推理能力的问题展开了激烈的辩论。近期,Tech Talks 的创始人 Ben Dickson 在 Tech Talks 上发表了一篇名为“Can GPT-4 and
GPT-4V perform abstract reasoning like humans“《GPT-4和GPT-4V能否像人类一样进行抽象推理》的文章,整理了圣塔菲研究所的科学家对大语言模型(LLM)是否发展出新的抽象推理能力的研究,揭示了目前先进的语言模型在抽象推理方面存在的局限性。研究结果表示:尽管这些模型规模庞大,但它们在处理新的、先前未见过的情境时仍然表现不如人类。同时,通过对GPT-4和GPT-4V在ConceptARC任务上的测试,研究者们发现即使使用了更全面的提示技术,这些模型的性能仍然不及人类水平。因此,在将这些模型应用于需要精确逻辑的决策过程时,研究者呼吁保持谨慎,并指出人类监督在人工智能应用中的重要性,特别是在敏感领域。未来的研究可能需要探索其他提示或任务表示的方法,以提高这些模型的性能。我们特将该内容编译出来和各位客户、合作伙伴朋友分享。如需转载,请联系我们(ID:15937102830)

有关类似GPT-4这样的大型语言模型(LLM)是否真正模拟人类逻辑和推理的辩论正在进行中。一些研究人员认为,随着规模的扩大,LLM可能会发展出对抽象推理、模式识别和类比制作的新能力。
另一方面,一些人认为促使这些能力的内部机制尚未被解释清楚。一些实验证明,这些模型在其训练数据范围之外难以推广。
"在创建和推理抽象表示方面的能力对于强大的泛化至关重要,因此有必要了解LLM在这方面已经取得了多大的能力," 圣塔菲研究所的科学家在最近的一篇论文中写道。
在他们的研究中,研究人员深入探讨了抽象推理的含义,并提供了在LLM中评估其能力的框架。研究结果表明,尽管GPT-4及其多模态版本GPT-4V非常复杂,但它们都未达到人类水平的抽象推理能力。
什么是抽象推理
抽象推理是从有限数据中识别规律或模式,并将其推广到新场景的能力。这种特质是人类智能的基石,儿童展示了从最少的例子中学习抽象规则的熟练技能。
评估抽象推理能力是一项困难的任务。弗朗索瓦·绍莱(Francois Chollet)提出的抽象与推理语料库(ARC)是一个公正的衡量工具。ARC是一个评估人类和人工智能抽象推理能力的框架。该测试包含1,000个手工制作的类比谜题,每个谜题呈现一些网格转换的例子和一个最终不完整的网格,解题者必须正确填充。这些谜题旨在消除任何不公平的优势,如与训练数据的相似性或对外部知识的依赖。
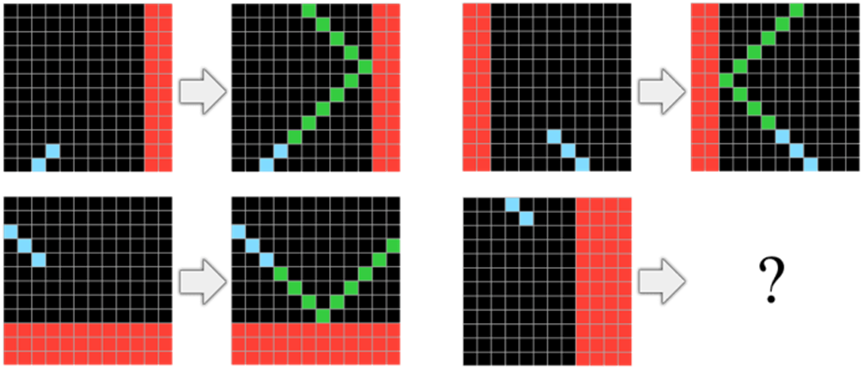
为了解决这些谜题,必须从少数示例中推断出总体的抽象规律,并将其应用于测试网格。解决ARC谜题所需的基础知识被认为是人类天生具备的,包括物体识别、数量评估以及几何和拓扑的基本原理等概念。
研究人员在他们的论文中写道:“[ARC] 的目标是捕捉抽象推理的核心:从少量示例中归纳出一般规则或模式,并灵活地应用于新的、以前未见过的情境。”
人类在ARC上的表现大约在84%左右。相比之下,利用当前人工智能系统尝试解决ARC的努力表现不佳。在一场著名的Kaggle竞赛中,使用了程序合成技术的顶级参赛作品仅成功解决了这些谜题的21%,而且无法超越其狭窄的范围进行泛化。作为通用问题解决者的LLM表现甚至更差,在最近的实验中只解决了10-12%的ARC挑战。
对GPT-4进行推理任务的测试
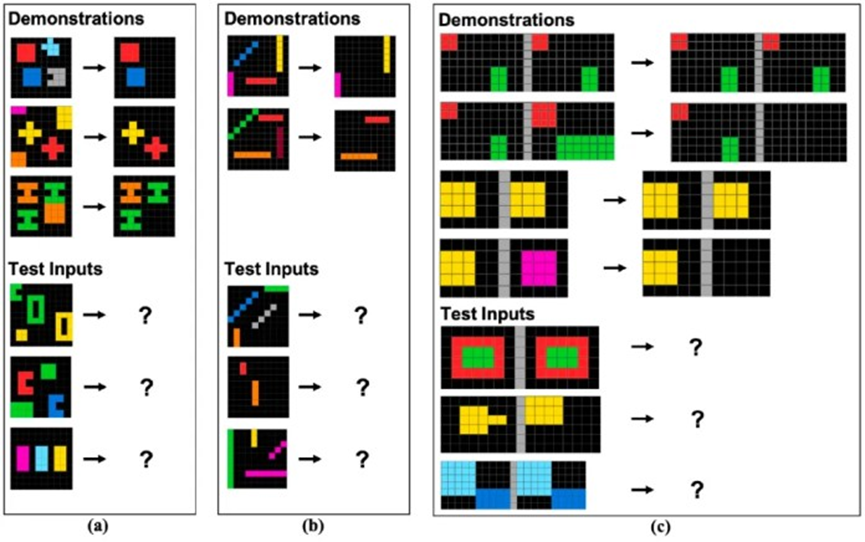
圣塔菲研究所的科学家们进行了一系列新的实验,使用了ConceptARC,这是ARC的一种变体,旨在更易于人类参与,并促进对特定概念理解的评估。为了适应基于文本的GPT-4,视觉谜题被转化为字符序列。模型接收到一个包含说明、一个已解决的例子和一个新问题的提示。GPT-4的任务是生成表示解决方案的字符序列,允许最多三次尝试。
先前的测试显示,GPT-4在不同温度下在ConceptARC上的得分分别为19%和25%。但通过新的更全面的提示技术,结果有所改善。在进行了480个ConceptARC任务的全面测试中,将模型的温度设置调整为0和0.5时,GPT-4的平均表现约为33%。
尽管取得了一些进展,但GPT-4的能力明显落后于人类表现,人类在ConceptARC上的表现令人印象深刻,达到了91%。圣塔菲科学家指出:“尽管有更详细的提示,GPT-4的表现仍然远远低于人类的高水平,这支持了一个结论,即即使有更多的信息提示,该系统仍然缺乏由这个语料库测试的基本抽象推理能力。”
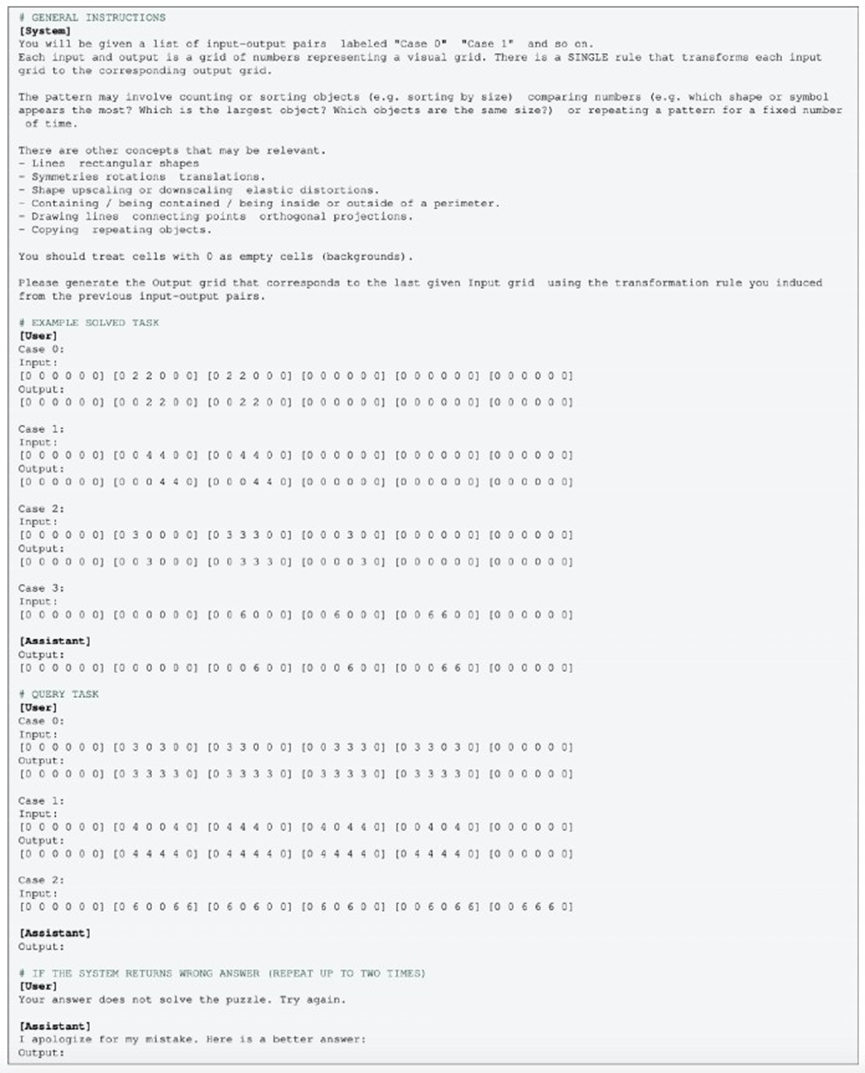
多模态是否可以提高GPT-4的性能
研究人员还在GPT-4V上测试了ConceptARC,这是GPT-4的多模态版本,除了文本外还能处理图像。普遍的假设是,由于其增强的能力,GPT-4V将超越其仅文本的对应版本。然而,由于全面测试的高昂成本,研究人员将对GPT-4V的评估限制在ConceptARC谜题的一个被称为“注意力检查”的特定组别上,人类通常在这里达到95%的成功率。
有趣的是,当这些注意力检查被转换为GPT-4的纯文本格式时,该模型获得了65-69%的分数,表明这些任务比完整集合的任务更容易。然而,GPT-4V在这些任务上的表现平均为23-25%,不及仅文本版本的成绩。
论文对GPT-4V的回应进行了有趣的观察:“GPT-4V经常在其解决方案中包含对抽象变换规则的描述...在某些情况下,尽管识别了错误的抽象规则,该模型准确地描述了输出网格,我们将其归类为成功。另一方面,我们将模型正确识别了抽象规则但未能准确描述输出网格的情况归类为失败。”
这个对LLM申请意味着什么
GPT-4V在完整的ConceptARC语料库上的表现可能会比注意力检查子集更差。这个结果表明,多模态能力并不一定会为LLM提供卓越的抽象推理能力。
圣塔菲研究所的研究结果强调了人类与当前最先进的人工智能系统之间在抽象推理方面存在的显著差异。
研究人员写道:“我们的结果支持这样的假设,即GPT-4,也许是目前最具“通用”性的LLM,仍然无法稳健地形成抽象概念并推理有关其训练数据中先前未见过的基本核心概念。其他提示或任务表示的方法可能会提高GPT-4和GPT-4V的性能;这是未来研究的一个课题。”
因此,在将这些模型整合到需要精确逻辑的决策过程中时,最好保持谨慎。在人工智能应用中,尤其是在敏感领域,人类监督仍然至关重要。

权益福利:
1、AI 行业、生态和政策等前沿资讯解析;
2、最新 AI 技术包括大模型的技术前沿、工程实践和应用落地交流(社群邀请人数已达上限,可先加小编微信:15937102830)

源于硅谷、扎根中国,上海殷泊信息科技有限公司 (MoPaaS) 是中国领先的人工智能(AI)平台和服务提供商,为用户的数字转型、智能升级和融合创新直接赋能。针对中国AI应用和工程市场的需求,基于自主的智能云平台专利技术,MoPaaS 在业界率先推出新一代开放的AI平台为加速客户AI技术创新和应用落地提供高效的算力优化和规模化AI模型开发、部署和运维 (ModelOps) 能力和服务;特别是针对企业应用场景,提供包括大模型迁移适配、提示工程以及部署推理的端到端 LLMOps方案。MoPaaS AI平台已经服务在工业制造、能源交通、互联网、医疗卫生、金融技术、教学科研、政府等行业超过300家国内外满意的客户的AI技术研发、人才培养和应用落地工程需求。MoPaaS致力打造全方位开放的AI技术和应用生态。MoPaaS 被Forrester评为中国企业级云平台市场的卓越表现者 (Strong Performer)。

END
▼ 往期精选 ▼
2、为什么像 ChatGPT 和 Google Bard 这样的LLM数学不好
▼点击下方“阅读原文”!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢