
今天是2024年1月7日,星期日,北京,天气晴,2024年的第一周就这么过去了。
回顾这一周,我们主要围绕模型缝合(《有趣的大模型嫁接思路SOLAR:兼论面向实体识别及数学能力的大规模开源数据集,https://mp.weixin.qq.com/s/9-4P3ZL8ozIrCDdWAPUIHQ》)、RAG召回阶段的embedding优化(《引入任务Instruction指令的句子向量化方案:Instructor的实现思路及训练数据集构造方案》,https://mp.weixin.qq.com/s/qIh07eU8_lYL2gBVzTFzKA),
并由此延伸的关于instruction任务数据集的一些数据增强开源工作(《2024开篇之大模型遇见信息抽取:常见数据增强、形式化语言及可练手小模型开源项目》,https://mp.weixin.qq.com/s/86FF6w91zompGsb6C80N6g),这些工作都是微调RAG展开。
而对于RAG而言,23年已经出现了很多工作,草台班子有了一堆,架构也初步走通,24年应该会围绕搜索增强做更多的优化工作,因此我们今天来系统回顾下RAG中的模块,包括一些架构,文本嵌入embedding等,供大家一起参考。
一、从RAG的整体架构及开源两阶段RAG项目说起
我们在之前的文章《也读大模型RAG问答技术综述及评估思路:兼看UHGEval幻觉评估数据集的构建细节》(https://mp.weixin.qq.com/s/PiTWDht3rOTwXE2vN5p6PQ)中对《Retrieval-Augmented Generation for Large Language Models: A Survey》(https://arxiv.org/pdf/2312.10997) 进行了介绍,其对于增强大家对RAG的基本理论认知有一定的帮助。
例如,该工作将RAG分成navie RAG, Advanced RAG以及Modular RAG,
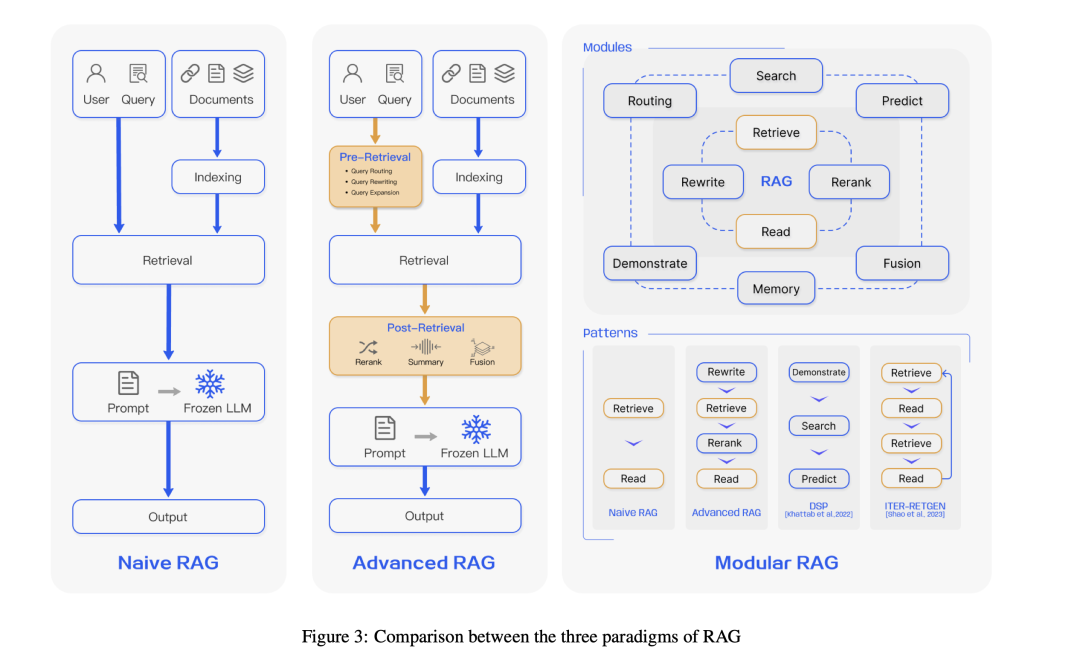
而另一个文章:https://blog.llamaindex.ai/a-cheat-sheet-and-some-recipes-for-building-advanced-rag-803a9d94c41b又整理了个图,在圈子里火了起来。
Motivation 与 Basic RAG
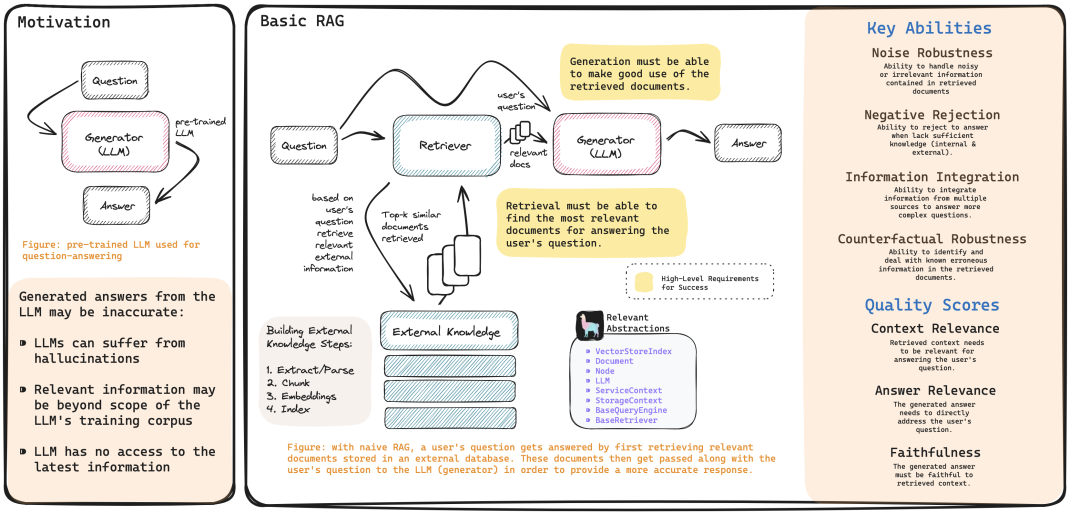
Advanced RAG
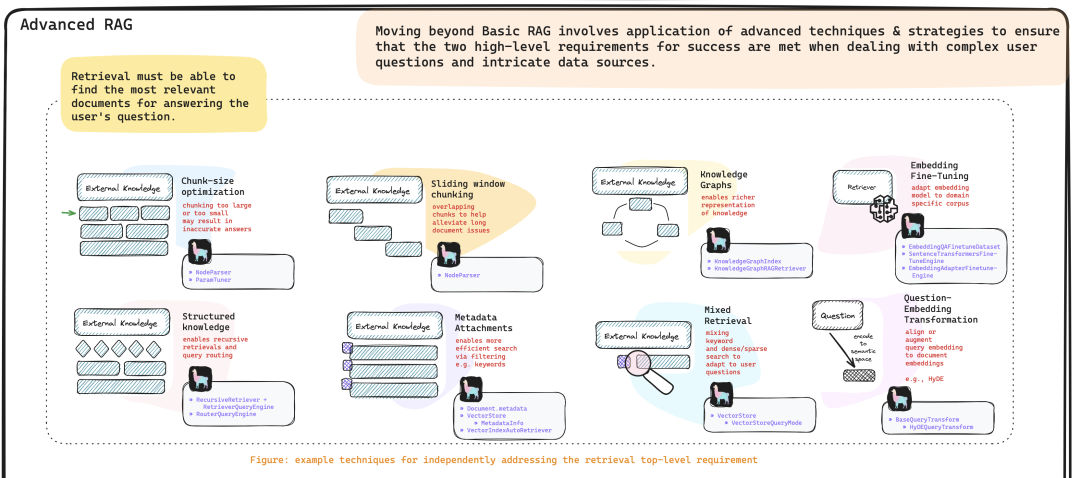
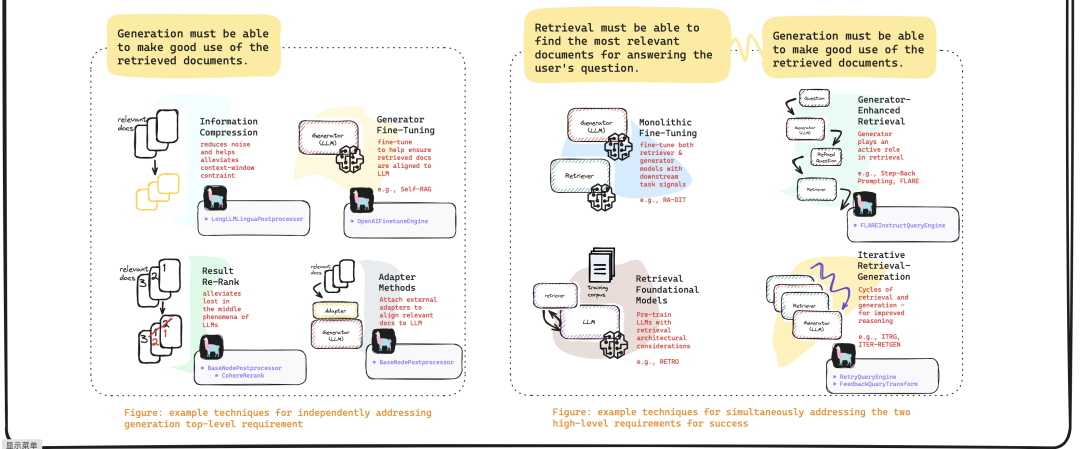
感兴趣的可以去看看,而最近也有开源一个涵盖到reranker阶段的RAG开源项目QAnything
QAnything (Question and Answer based on Anything) 致力于支持任意格式文件或数据库的本地知识库问答系统,支持PDF,Word(doc/docx),PPT,Markdown,Eml,TXT,图片(jpg,png等),网页链接等。
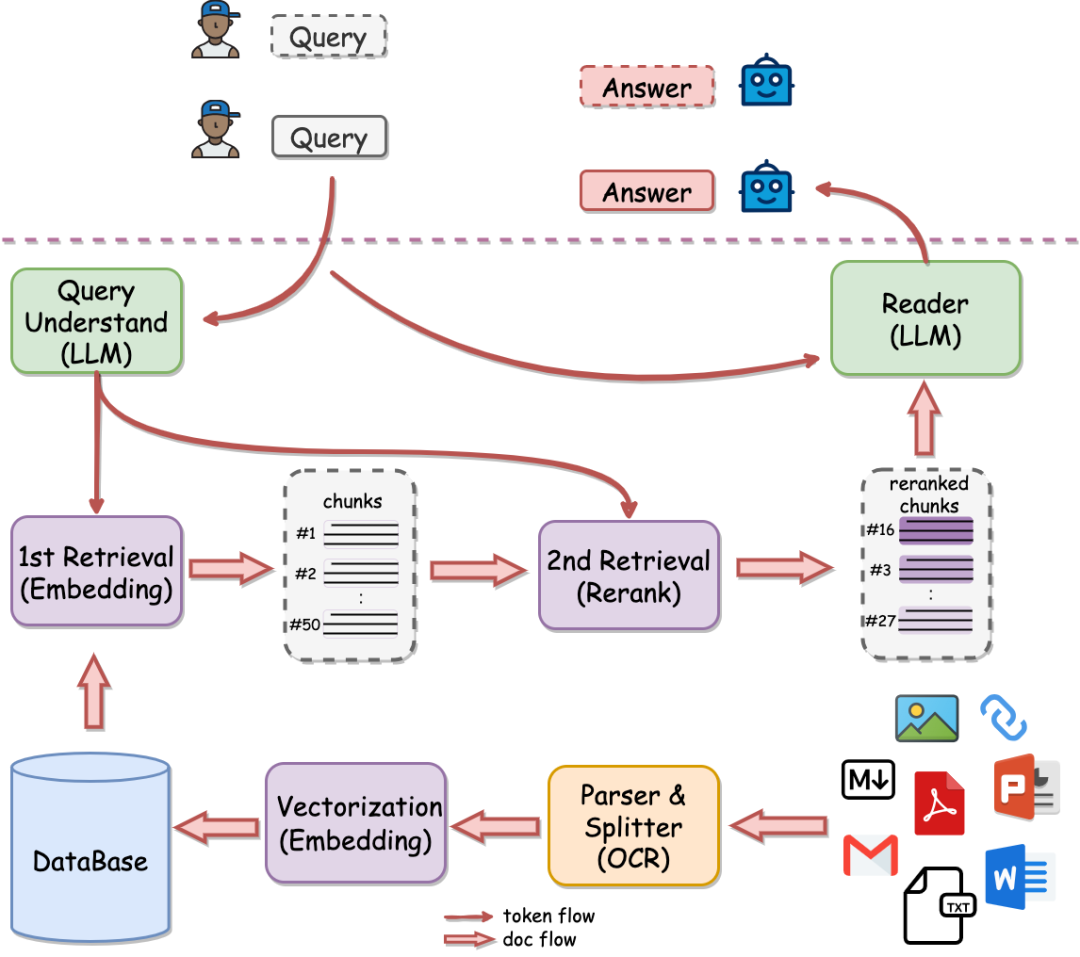
地址:https://github.com/netease-youdao/QAnything
QAnything使用两阶段检索范式,其提到,知识库数据量大的场景下两阶段优势非常明显,如果只用一阶段embedding检索,随着数据量增大会出现检索退化的问题,如下图中绿线所示,二阶段rerank重排后能实现准确率稳定增长,即数据越多,效果越好。
二、再看RAG中的embedding模型
本周,也出现了一些新的文本嵌入模型和RAG项目,例如NetEase Youdao开源了其嵌入项目BCEmbedding以及问答系统QAnything。
EmbeddingModel用于生成语义向量,在语义搜索和问答中起着关键作用,EmbeddingModel支持中文和英文。
EmbeddingModel通常用于粗排,因为其可以预先对文本进行向量表示,并预先建立索引,在真实场景下只需要检索计算相似度即可,很快速,并且各个文本计算相似度可以
from BCEmbedding import EmbeddingModel
# list of sentences
sentences = ['sentence_0', 'sentence_1', ...]
# init embedding model
model = EmbeddingModel(model_name_or_path="maidalun1020/bce-embedding-base_v1")
# extract embeddings
embeddings = model.encode(sentences)
不过EmbeddingModel并为考虑文本之间的交互,并且不同的场景下,相似度阈值并不好控制。
1、BCEmbedding
BCEmbedding(BCEmbedding: Bilingual and Crosslingual Embedding for RAG)是由网易有道开发的双语和跨语种语义表征算法模型库,其中包含EmbeddingModel和RerankerModel两类基础模型。
实际上,与此相对应的更早的模型,有智源开放的BGE模型。

地址:https://github.com/netease-youdao/BCEmbedding
2、BGEEmbedding
BGEEmbedding是一个通用向量模型,基于retroma 对模型进行预训练,再用对比学习在大规模成对数据上训练模型,地址:https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/baai_general_embedding
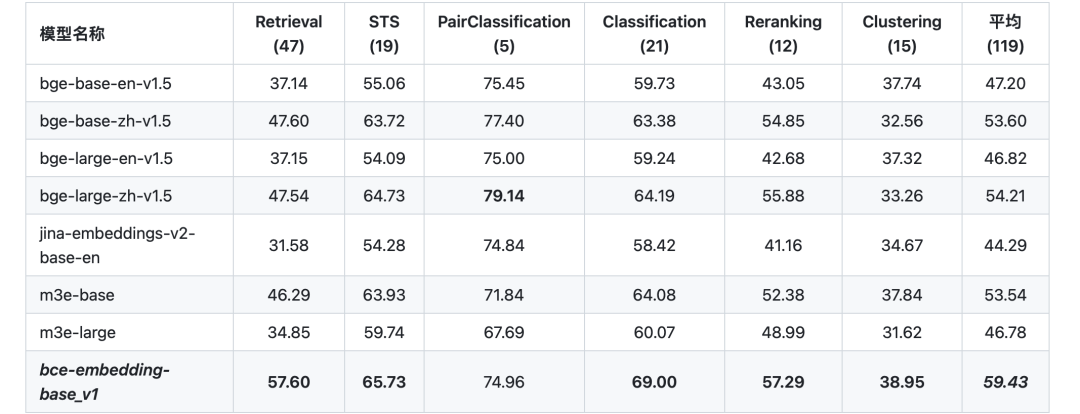
3、效果对比
可以在https://github.com/netease-youdao/BCEmbedding中找到embedding侧的对比结果。
其采用基于MTEB的语义表征评估基准(https://github.com/embeddings-benchmark/mteb)。
二、再看带有prompt的向量化embedding
知乎文章《https://zhuanlan.zhihu.com/p/661867062》针对这块有了个不错的总结【感兴趣的可以进一步看看】,其提到,在大模型微调这块,有个hard prompt tuning的方式,在进行多任务微调的时候,给不同的任务的input前边都加入固定模式的文字,让模型学会,看到某一段文字之后,就知道要做什么任务了,有助于提高下游不同任务的效果。
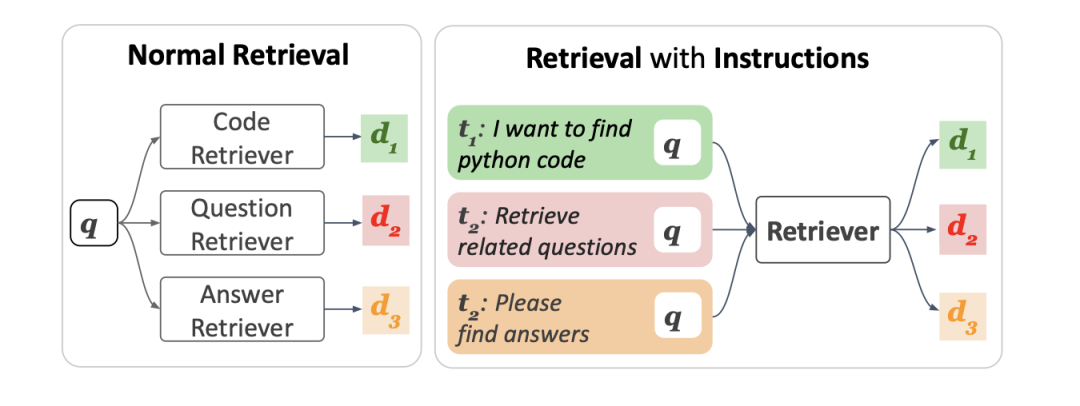
举一反三,都是语言模型,当然也可以在向量化模型上用这个trick了,也就是做不同的任务时,分别给不同任务的query和key加上不同的prompt之后在做向量化,因此,母亲也出现了许多很有意思的idea。
1、TART
《Task-aware Retrieval with Instructions》(https://arxiv.org/pdf/2211.09260.pdf)是在2022年很早期的一个工作,该工作目标是利用多任务指令调整技术开发一种通用的任务感知检索系统,该系统可以按照人类编写的指令为给定查询找到最佳文档,首次大规模收集了约40个带指令的数据集(BERRI,Bank of Explicit RetRieval Instructions),并介绍了在带指令的BERRI上训练的多任务检索系统TART(TAsk-aware ReTriever),TART展示了通过指令适应新检索任务的可行性。

2、instructor
我们在之前的文章《引入任务Instruction指令的句子向量化方案:Instructor的实现思路及训练数据集构造方案》(https://mp.weixin.qq.com/s/qIh07eU8_lYL2gBVzTFzKA)** 中有介绍到instructor的方案,其在每个query上,加上了指令信息,并一次来计算对比学习loss:
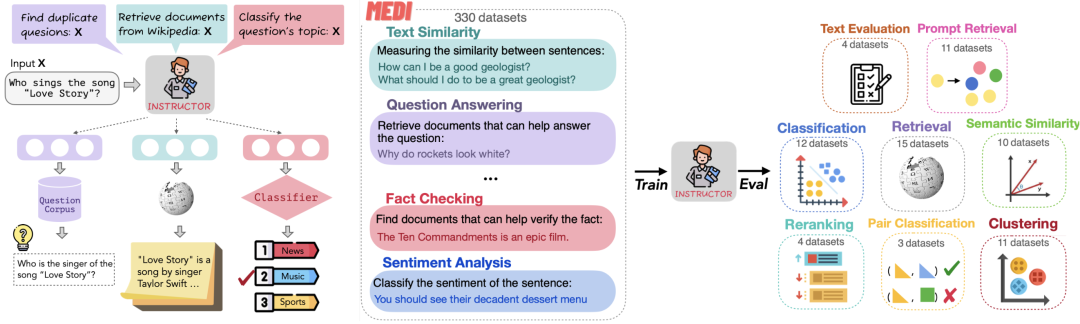
这种思路引入了适配特定instruction任务的嵌入方案,这与instruction微调美妙结合。
对应的工作《One Embedder, Any Task: Instruction-Finetuned Text Embeddings》(https://arxiv.org/abs/2212.09741)这一工作,提出了INSTRUCTOR(Instruction-based Omnifarious Representations)的思路,是一种根据任务说明计算文本嵌入的新方法:每个文本输入会与解释用例的说明(如任务和领域描述)一起进行嵌入。
在具体实现上,该工作通过构造330种不同任务的说明,并在这种多任务上对INSTRUCTOR进行了对比损失训练,这个和当前大模型的instruction tuning工作很像。
项目地址:https://instructor-embedding.github.io
3、基于合成任务优化embedding
而最近的另一个工作,《Improving Text Embeddings with Large Language Models》(https://arxiv.org/abs/2401.00368) 这一工作,利用LLM为近100种语言的文本嵌入任务生成多样化的合成数据,在合成数据上使用标准对比损失对开源模型LLM进行微调,得到更好的嵌入表示。
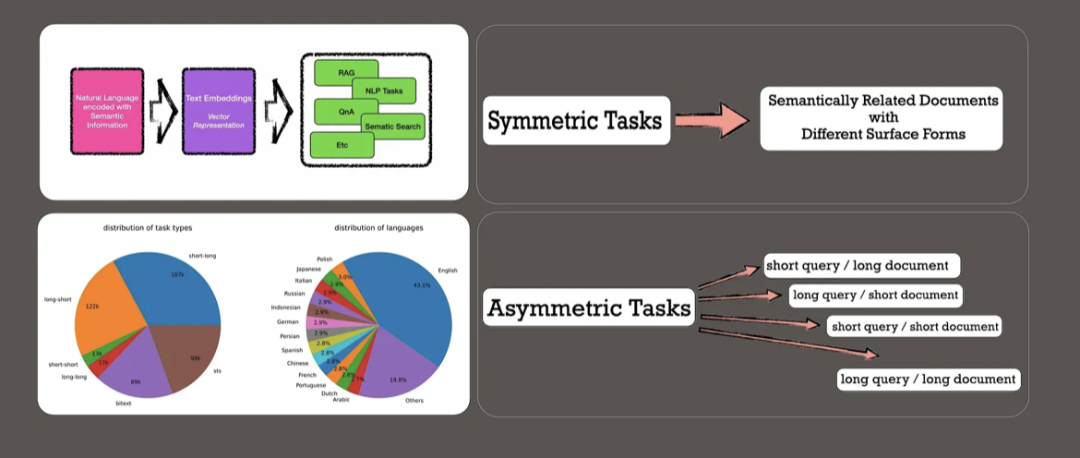
具体思路上,用了两步提示策略:首先提示LLMs对候选任务库进行头脑风暴,然后提示LLMs从任务库中生成以给定任务为条件的数据。为了涵盖各种应用场景,为每种任务类型设计了多个提示模板,并将不同模板生成的数据结合起来,以提高多样性。对于文本嵌入模型,选择微调功能强大的开源LLM,而不是BERT式的小型模型。
4、LLM Embedder
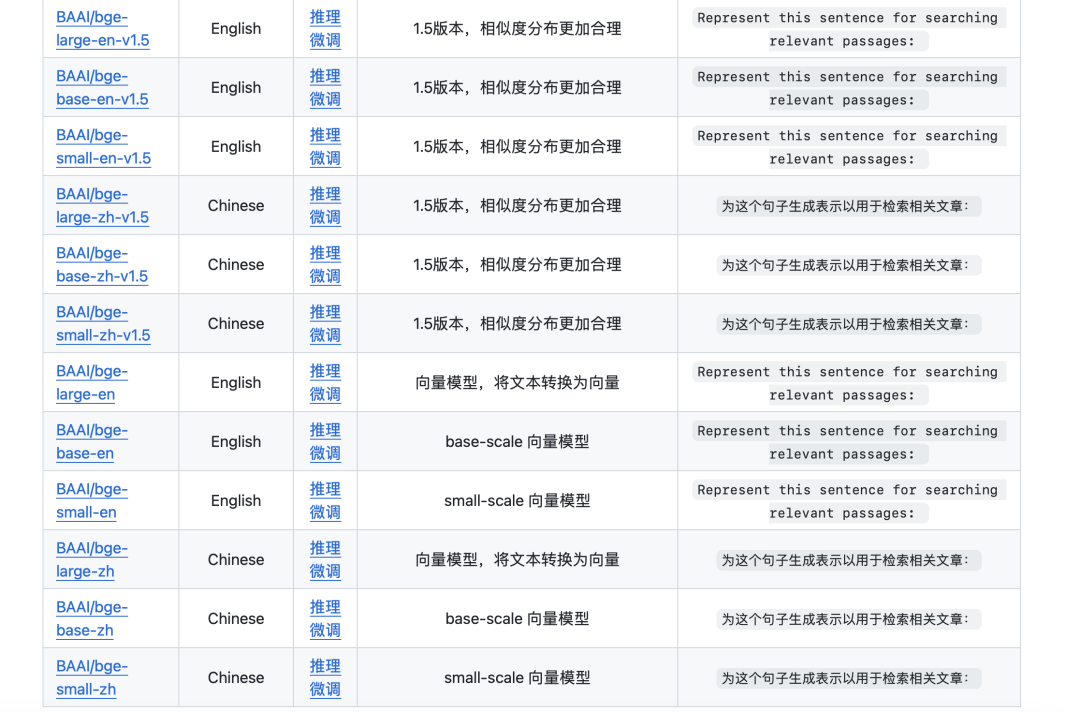
LLM-Embedder《Retrieve Anything To Augment Large Language Models》(https://arxiv.org/abs/2310.07554),也就是BGE2。其实,其在第一个版本的时候,就已经引入了instruction的思想,做向量化召回时候只将召回任务分成两类:对称检索(相似句匹配)和非对称检索(QA匹配),如果做是QA匹配,需要在Q进行向量化时候,加入前缀:“为这个句子生成表示(for s2p(short query to long passage) retrieval task, each short query should start with an instruction ),不同版本的模型对应的prompt如下:
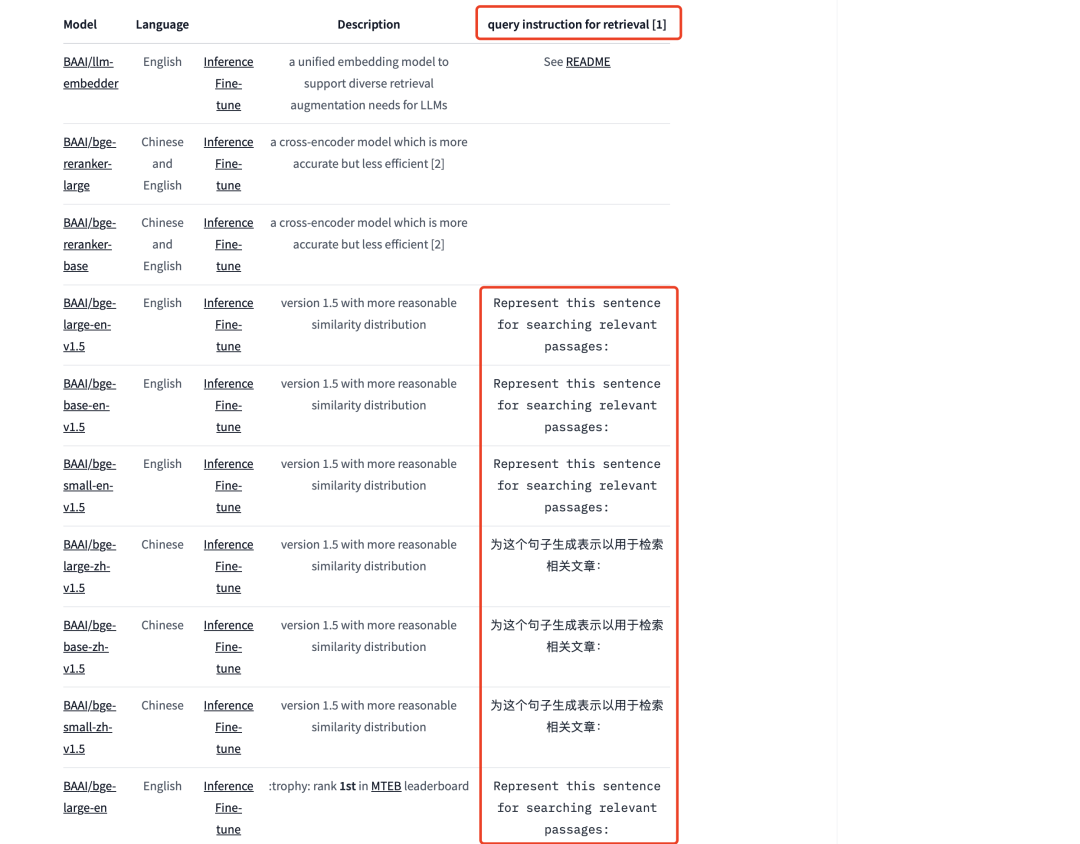
例如使用BGE模型时,源代码可以为:
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
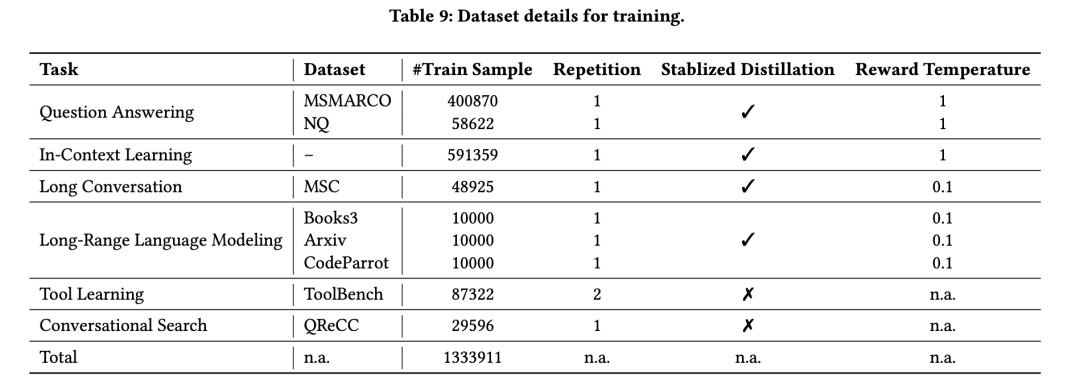
在具体实现上,BGE2根据LLM的反馈进行微调,支持大型语言模型的检索增强需求,包括知识检索、记忆检索、示例检索和工具检索,在具体实现上,在6个任务上进行了微调:问题回答、对话搜索、长对话、长文本建模、上下文学习和工具学习。
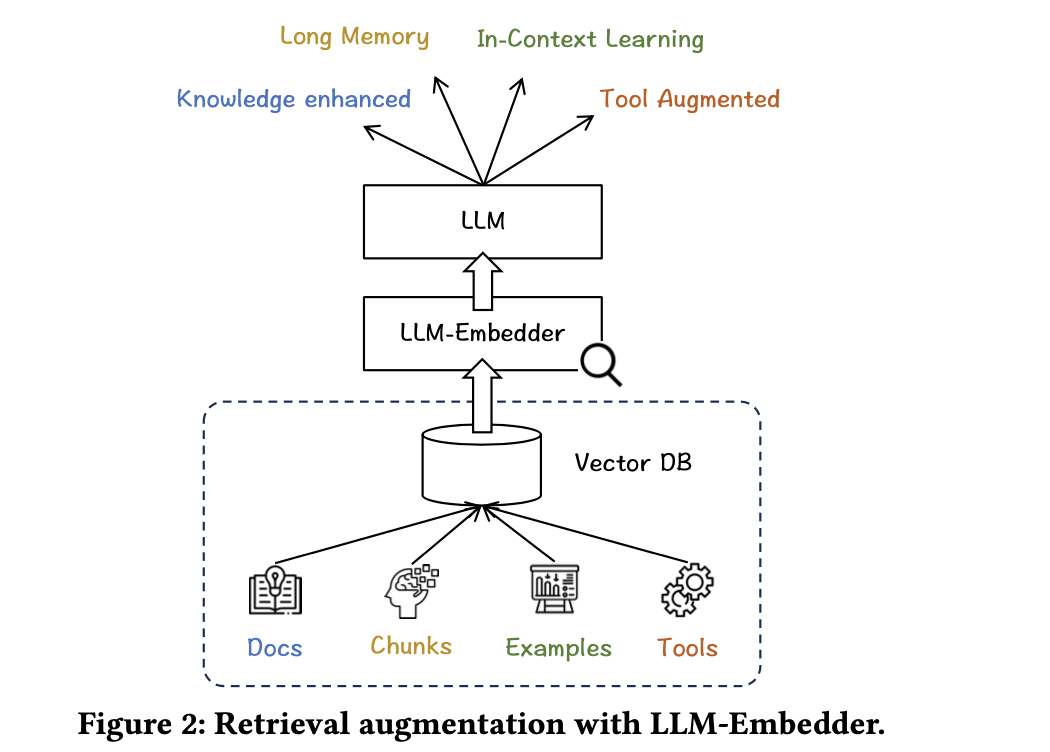
对应的prompt如下:
INSTRUCTIONS = {
"qa": {
"query": "Represent this query for retrieving relevant documents: ",
"key": "Represent this document for retrieval: ",
},
"icl": {
"query": "Convert this example into vector to look for useful examples: ",
"key": "Convert this example into vector for retrieval: ",
},
"chat": {
"query": "Embed this dialogue to find useful historical dialogues: ",
"key": "Embed this historical dialogue for retrieval: ",
},
"lrlm": {
"query": "Embed this text chunk for finding useful historical chunks: ",
"key": "Embed this historical text chunk for retrieval: ",
},
"tool": {
"query": "Transform this user request for fetching helpful tool descriptions: ",
"key": "Transform this tool description for retrieval: "
},
"convsearch": {
"query": "Encode this query and context for searching relevant passages: ",
"key": "Encode this passage for retrieval: ",
},
}
其在具体实现上很有意思,重点在于基于大语言模型反馈的奖励机制、知识蒸馏的稳定化以及明确指示的多任务微调。具体的:
在基于大语言模型反馈的奖励机制方面,
LLM的期望输出表示为𝑂,检索候选表示为𝐶,候选的奖励表示为𝑟𝐶|𝑂,由以下方程导出:
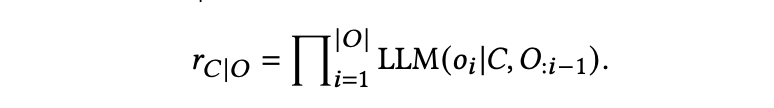
𝑜𝑖表示期望输出的第𝑖个标记,而LLM(𝑥|𝑦)表示在给定上下文𝑦的情况下,LLM生成𝑥的可能性。换句话说,如果一个检索候选导致期望输出的生成可能性更高,那么将分配更高的奖励。
对于问答任务,奖励计算为在给定一个单一候选段落的情况下,生成答案的可能性;对于指令调整任务,奖励计算为在给定一个候选示例的情况下,生成指定的输出的可能性。对于生成任务,奖励计算为在给定一个候选历史块的情况下,生成新内容的可能性。不过,LLM奖励不适用于会话搜索和工具学习数据集,因为在这些情况下没有对LLM输出的明确期望。
在损失函数方面,使用对比学习的损失函数:
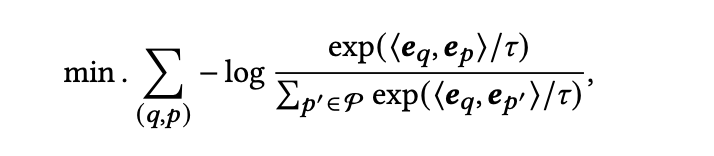
在知识蒸馏方面,通过最小化使用LLM的奖励计算的候选样本分布与由嵌入模型预测的分布之间的差距来提高模型性能,通过计算KL散度,以减小LLM的奖励的波动对蒸馏的负面影响:
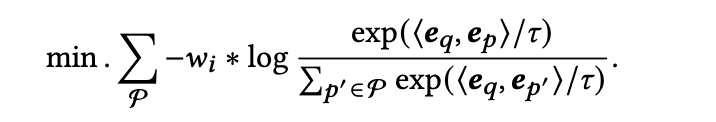
最后,在训练数据方面,
三、最后看关于RerankerModel精排模型
交叉编码器将对查询和答案实时计算相关性分数,这比向量模型(即双编码器)更准确,但比向量模型更耗时。 因此,它可以用来对嵌入模型返回的前k个文档重新排序。
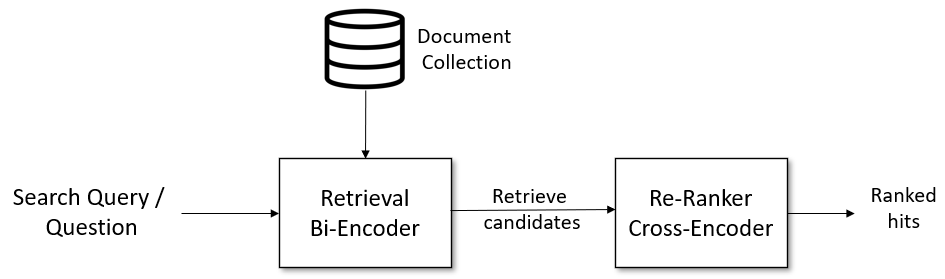 不同于向量模型需要输出向量,直接文本对输出相似度(因为交叉编码器在句子层面的任务上表现非常好,但它存在一个“致命”缺点:交交叉编码器不产生句子嵌入,这个嵌入没有绝对意义),排序准确度更高,可用于对向量召回结果的重新排序,提升最终结果的相关性。
不同于向量模型需要输出向量,直接文本对输出相似度(因为交叉编码器在句子层面的任务上表现非常好,但它存在一个“致命”缺点:交交叉编码器不产生句子嵌入,这个嵌入没有绝对意义),排序准确度更高,可用于对向量召回结果的重新排序,提升最终结果的相关性。
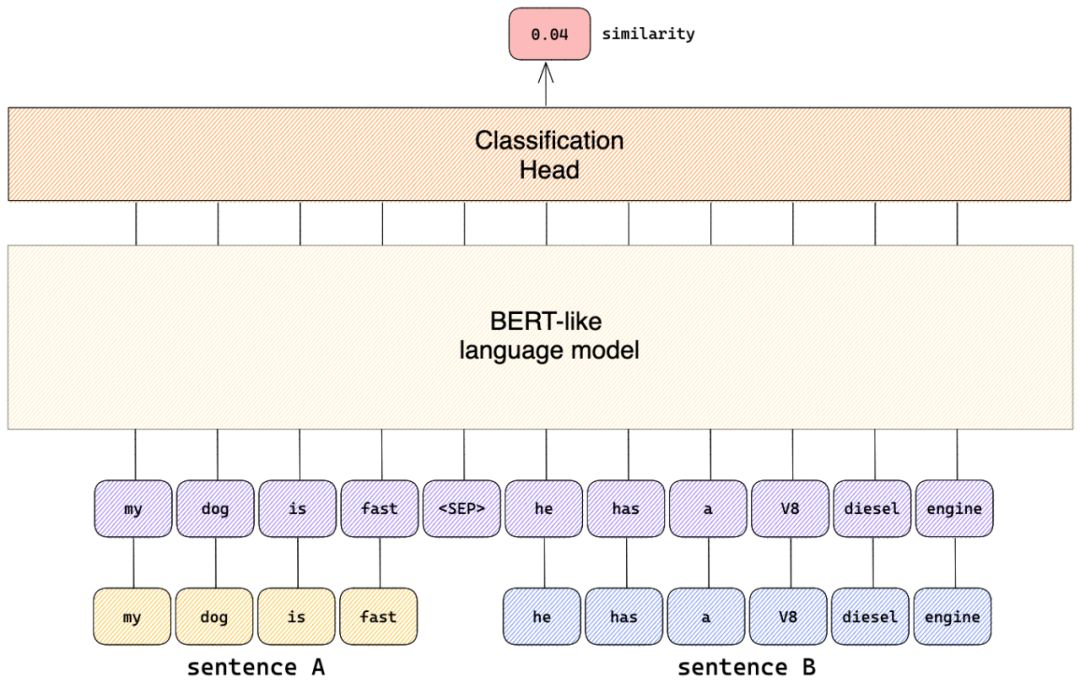
在技术实现上,Query-Passage paire组成的正负样例,一块送入模型,训练目标是,正样例的logits score大于batch内的负样例。
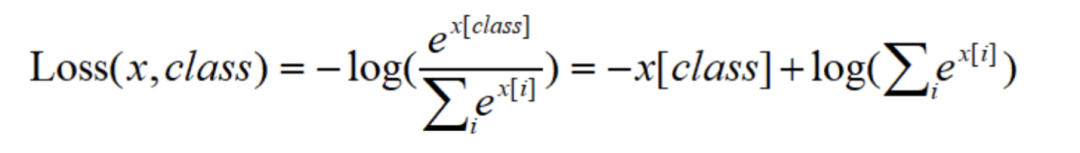
也就是说,其通过句子对及表征其语义相似程度的基本事实标签(可能是离散的类别标签,或者是连续性的相似度数值)来进行有监督训练。
这块的实现可以参考:https://github.com/luyug/Reranker/tree/main
from BCEmbedding import RerankerModel
# your query and corresponding passages
query = 'input_query'
passages = ['passage_0', 'passage_1', ...]
# init reranker model
model = RerankerModel(model_name_or_path="maidalun1020/bce-reranker-base_v1")
# method 1: rerank passages
rerank_results = model.rerank(query, passages)
但是,很现实的是,交叉编码器在实际应用中的速度很慢,所以通常都是作为精排出现,关于rerank精排这块的对比实验,可以查看《Agents大模型外挂检索优化》(https://zhuanlan.zhihu.com/p/657653570),有些结论很有意思:
bge-reRank模型虽然是一个rank模型,但其的score值还是较好的稳定在一个取值范围,业务场景中,可在自己的测评数据上,找到的一个不错的score值,来解决不应该召回的情况。
使用reRank,可显著提升检索效果,前提还是bge-reranker-large效果比较好。笔者对比,阿里的通用reRank模型,效果比检索还差了。
检索的候选多了,效果上限会提高但ReRank效果可能会下降。
通过domain数据finetune,可进一步提升,检索效果,为业务指标提升,展现了一条康庄大道。
而进一步的,在训练数据方面,常用的数据包括
T2ranking:https://huggingface.co/datasets/THUIR/T2Ranking
MMmarco:https://github.com/unicamp-dl/mMARCO
dulreader:https://github.com/baidu/DuReader
Cmedqa-v2:https://github.com/zhangsheng93/cMedQA2
nli-zh:https://huggingface.co/datasets/shibing624/nli_zh
msmarco:https://huggingface.co/datasets/sentence-transformers/embedding-training-data
nq:https://huggingface.co/datasets/sentence-transformers/embedding-training-data
hotpotqa:https://huggingface.co/datasets/sentence-transformers/embedding-training-data
NLI:https://github.com/princeton-nlp/SimCSE
Mr.TyDi:https://github.com/castorini/mr.tydi
1、youdao RerankerModel
RerankerModel擅长优化语义搜索结果和语义相关顺序精排,支持中文,英文,日文和韩文。
地址:https://github.com/netease-youdao/BCEmbedding
2、BGE Reranker
FlagEmbedding(https://github.com/FlagOpen/FlagEmbedding/)在检索增强llm领域做了许多开源工作,Reranker Model也是其中的一个重点,其在在多语言数据上训练了交叉编码器。
地址:https://huggingface.co/BAAI/bge-reranker-large
3、模型对比效果
模型评测方面,使用llamaindex进行测试,可以从https://github.com/netease-youdao/BCEmbedding中找到对应的评测结果,如下表所示:
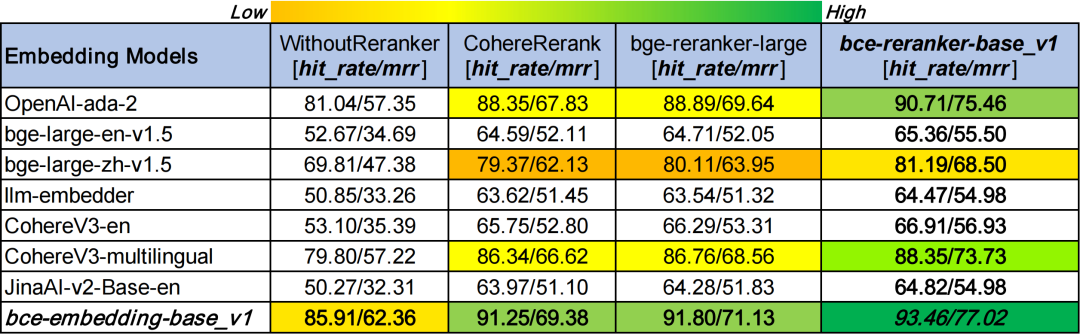
当然具体的数值还可以参考:《Boosting RAG: Picking the Best Embedding & Reranker models(https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)
总结
本文主要介绍了RAG系统中的一些有趣的话题,包括从RAG的整体架构及开源两阶段RAG项目、带有prompt的向量化embedding、关于RerankerModel精排模型,这些都在2024年开年这一周出现了很多有趣的工作。
搜索增强,在24年会有很多工作,大家可以多跟进。
参考文献
1、https://www.datagrand.com/blog/技术干货:如何训练高性能语义表示模型-交叉.html
2、https://zhuanlan.zhihu.com/p/661867062
3、https://www.sbert.net/examples/applications/retrieve_rerank/README.html
4、https://blog.llamaindex.ai/a-cheat-sheet-and-some-recipes-for-building-advanced-rag-803a9d94c41b
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢