
“FlashAttention能够在BERT-large训练中节省15%,将GPT训练速度提高2/3,并且是在不需要修改代码的情况下实现的。这为LLM(大型语言模型)的研究提出了一个新的方向。可以说FlashAttention的研究方向主要集中在机器学习,特别是自然语言处理(NLP)领域,并在这个领域中寻求更有效的模型训练方法。
”
研梦非凡针对大模型研究领域研发《FlashAttention-大模型前沿研究》直播课,从⌈论文核心要点⌋到⌈算法分析和实验研究⌋总分总讲解,力求大家掌握正确的读论文技能。1月17号-18号两天连播!扫码加助教预约直播课👇!

👆加助教送:50小时3080Ti GPU算力+8篇大模型前沿论文和代码+百篇大模型必读论文👇

FlashAttention是一种快速且内存高效的精确注意力机制,同时具有IO感知性。 它主要解决了Transformer在计算长文本时面临的平方时间复杂度问题,即处理速度慢和存储占用高的问题。 不同于其他Efficient Transformer通过降低模型的浮点运算来提高效能,FlashAttention将优化重点放在了降低存储访问开销上。 ......
IO-Aware Runtime Optimization Efficient ML Models with Structured Matrices Sparse Training Efficient Transformer
计算机架构 Self-Attention 计算 Safe Softmax 公式 Online softmax 公式 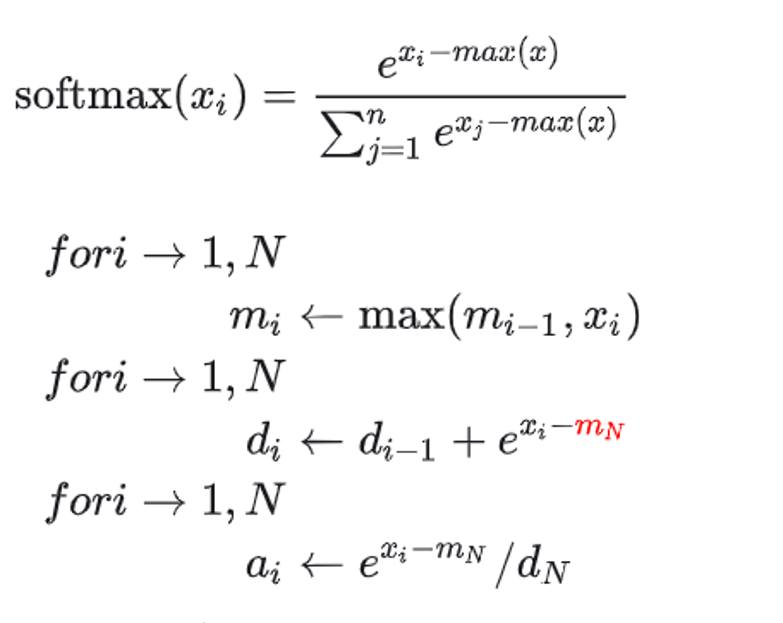
Flash Attention算法两个主要思想 Flash attention的计算过程(算法实现)
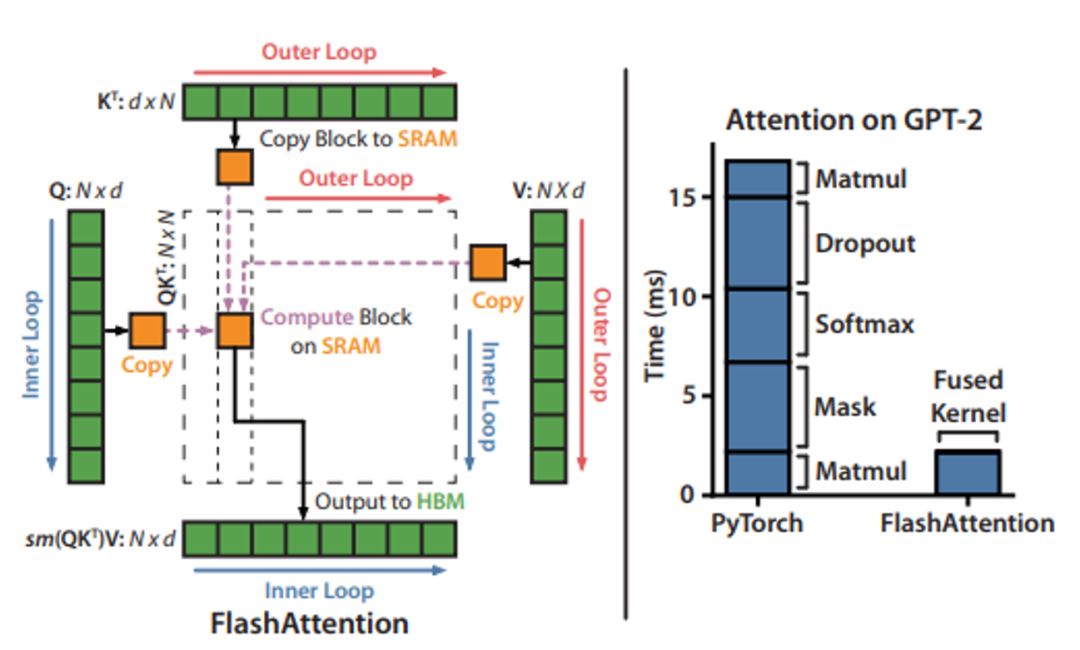
Training Speed 模型加速测试 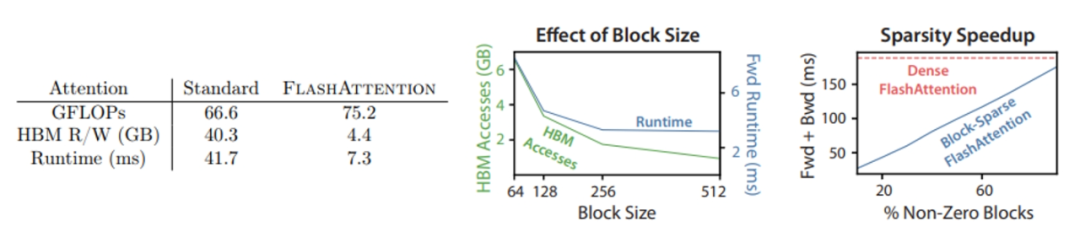


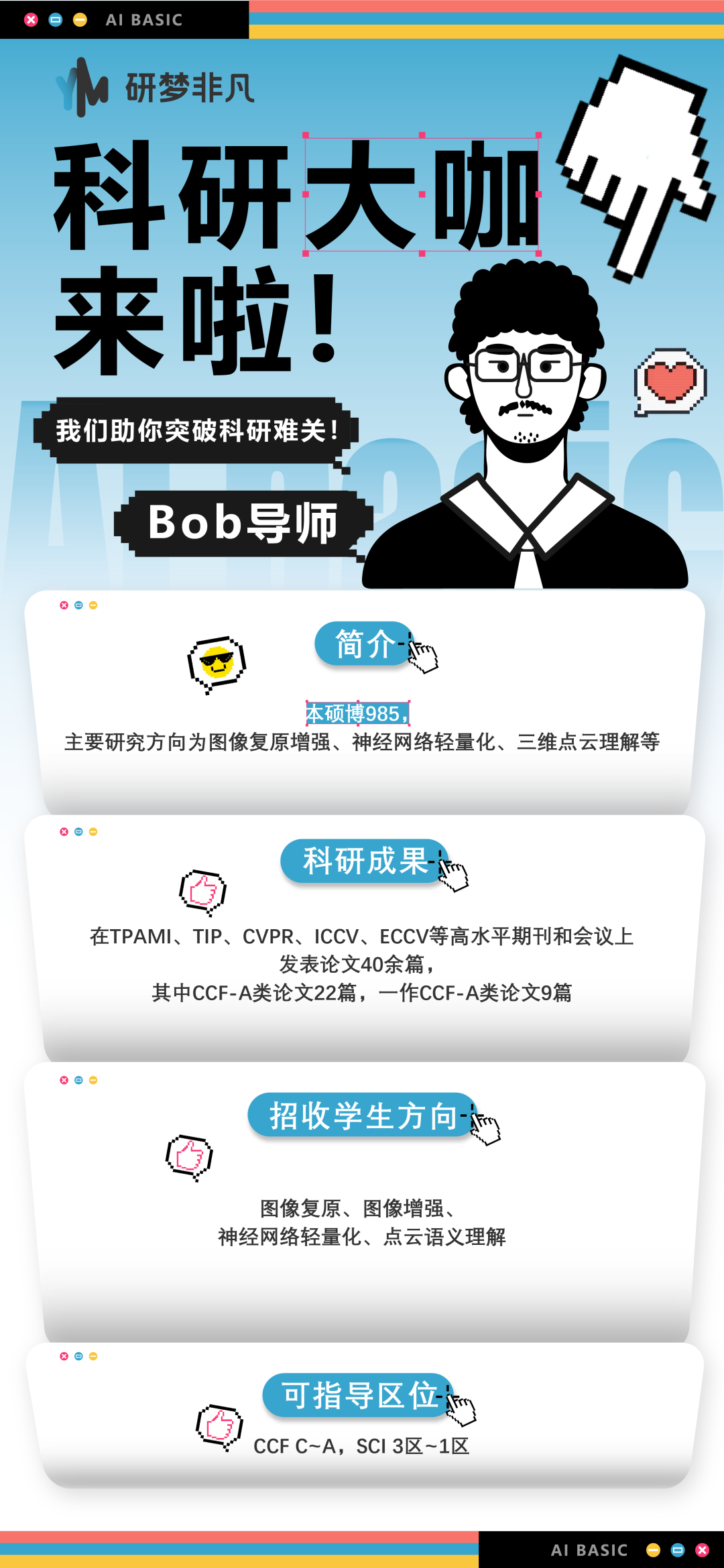
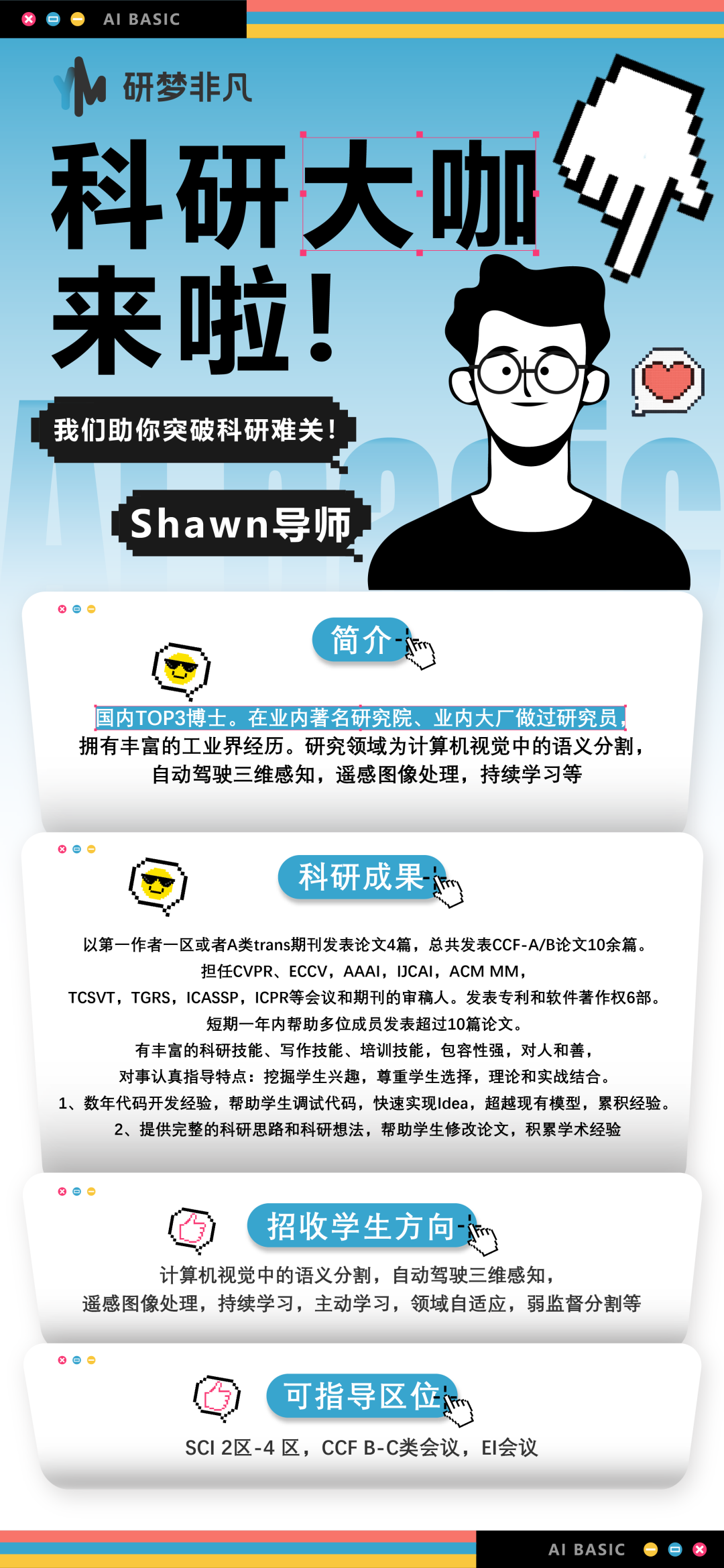
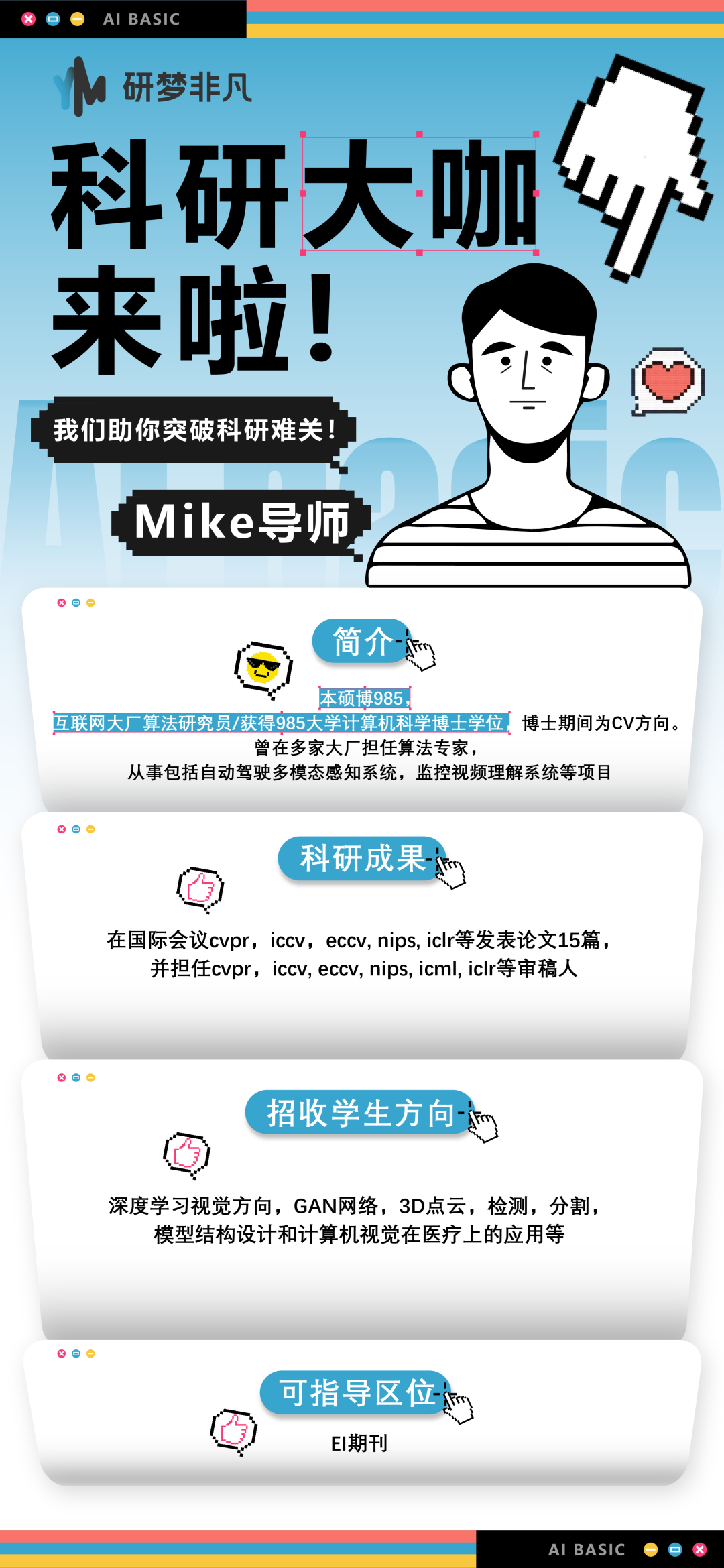
直播课导师:魏导师
“魏导师有丰富的深度学习研究经验。从事新能源汽车智能座舱语音对话高级算法研发;芯片公司模型训练推理加速框架研发和高性能计算工程师;大模型算法资深工程师。
”
“主要研究方向: 深度学习,自然语言算法与应用,大语言模型预训练微调、模型推理加速、AIGC多模态、AI推理框架。发表学术论文多篇(均为独立发表),工信部重点项目1项。
”
“可指导学生方向:大语言模型预训练和微调对齐、医疗大语言模型、code LLM算法研究。
”



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢