
2024 开年巨献,深度解读 DeepSeek 大模型背后的技术秘密..
https://hf.co/deepseek-ai

技术报告 Highlights
深入探索了超参数的Scaling Laws:为选择最佳超参数(Batch Size、 Learning Rate)提供了经验框架 详细论证了数据质量对Scaling Laws的影响:同等数据规模下,数据质量越高,最优参数规模越大
完整的对齐实践细节,全方位的AGI能力评估
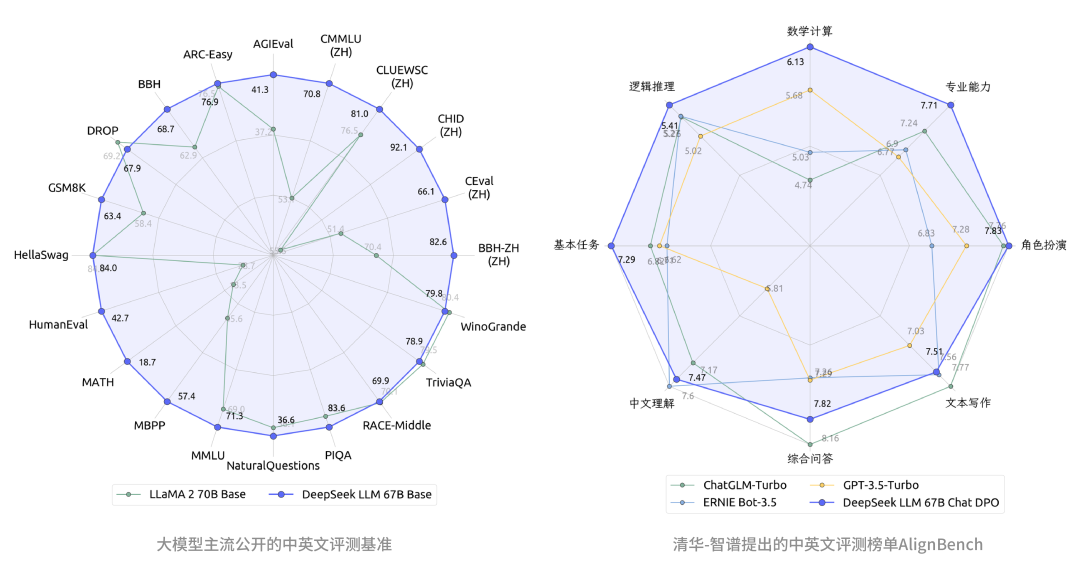
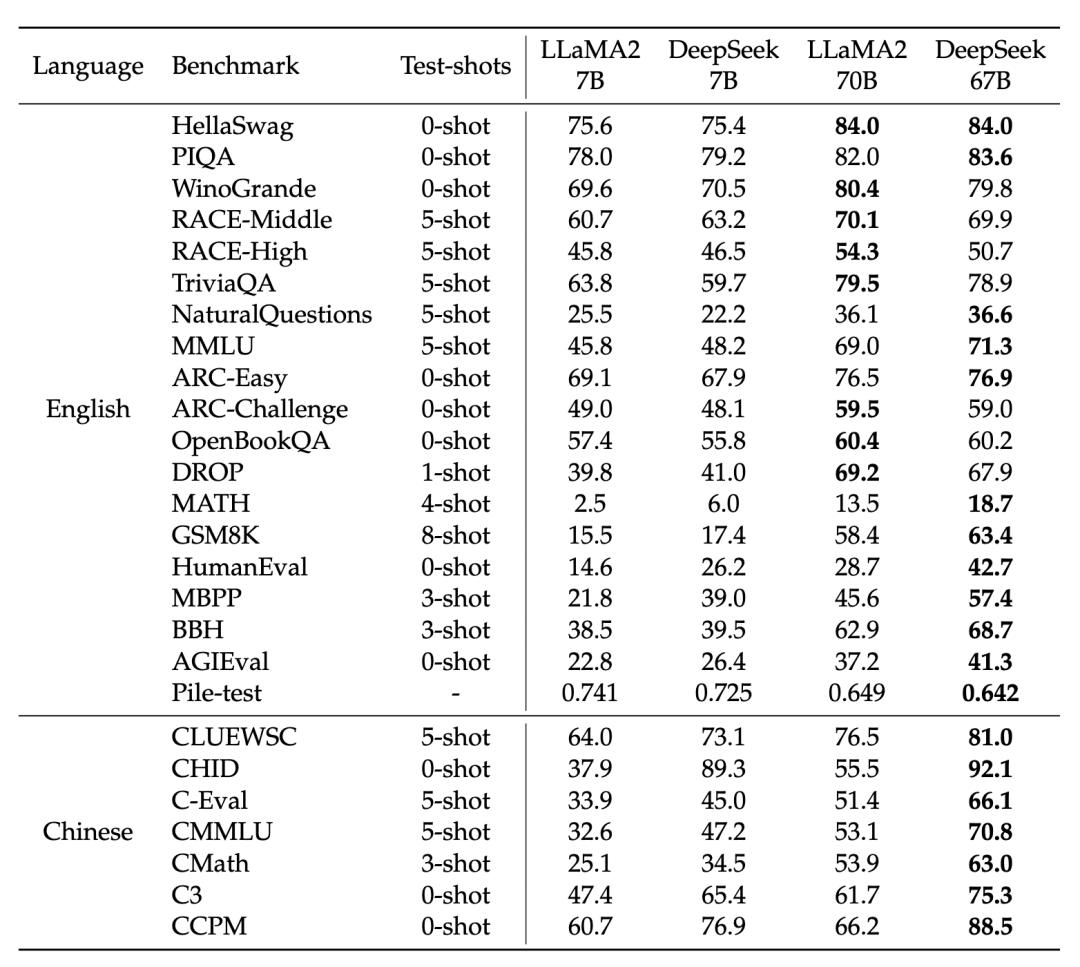
对比开源模型(左图),DeepSeek LLM 67B 的中英文能力已全面超越了开源标杆LLaMA2 70B 对比闭源模型(右图),免费开源商用的DeepSeek 67B Chat的中文能力已经超越了GPT-3.5-turbo,并在专业能力、数学计算、基本任务等小幅领先国内大模型
DeepSeek LLM 核心细节
1. 数据&架构
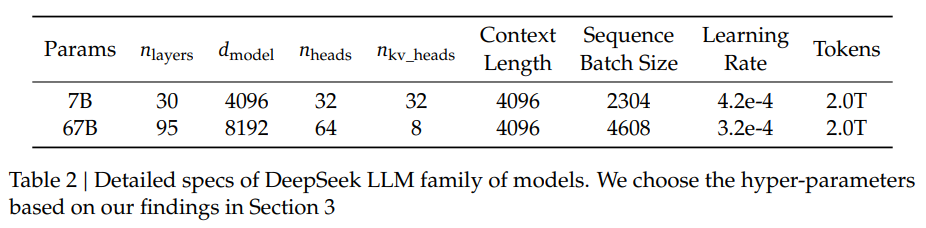
2. 训练&Infra
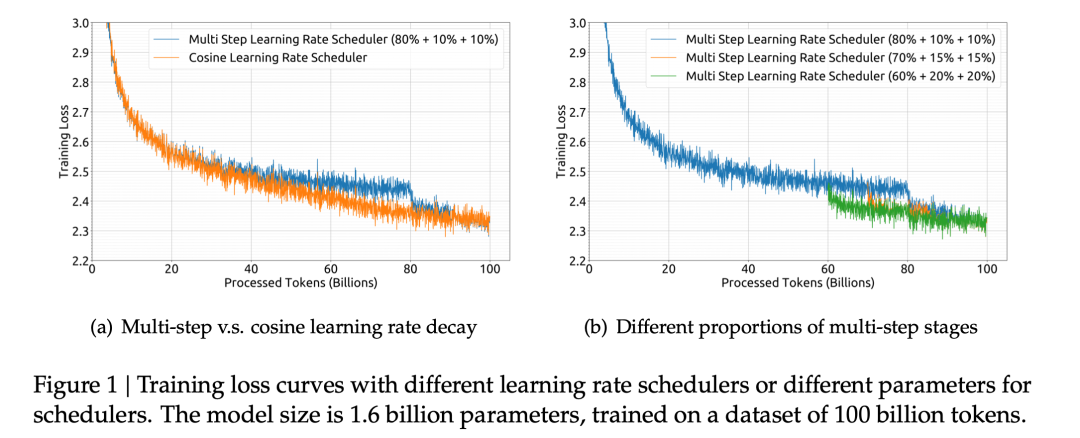
2.1 多阶段学习率调度器
相比较于广泛使用的余弦学习率调度器,我们使用了多阶段学习率调度器,可以方便我们复用第一个训练阶段,在continual training时有独特的优势。我们也通过细致的实验表明,使用多阶段学习率调度器可以获得不弱于余弦学习率调度器的性能。
2.2 Infra
我们使用了内部自研的轻量级高效训练框架HAI-LLM来支持我们训练和评估LLM。我们在训练过程中使用到了数据并行、张量并行、序列并行和1F1B流水线并行等并行策略,并采用了flash attention等加速算子来提高我们的硬件利用率。我们使用bf16来训练模型并使用fp32来累积梯度。
3. Scaling Laws
3.1 超参数的Scaling Laws
我们首先从超参数入手,尝试寻找超参数层面是否存在随计算规模变化的规律。经过大量实验,我们发现,给定模型规模和数据规模后,模型的batch size和learning rate有一个较大的接近最优参数空间,且这一参数空间随计算规模的变化明显。其余参数则在不同规模下共享同样的最优参数。因此我们将超参数的Scaling Laws限定在batch size和learning rate上进行研究。
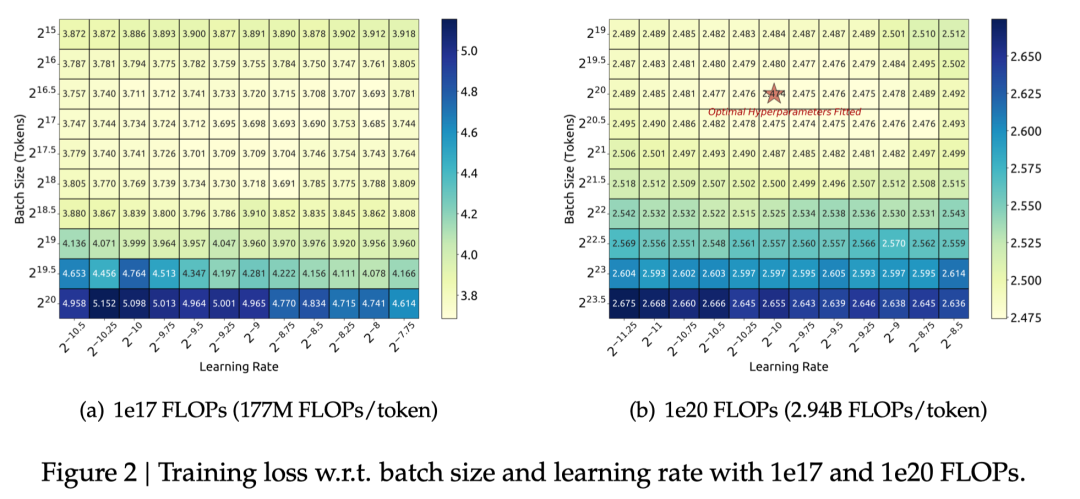
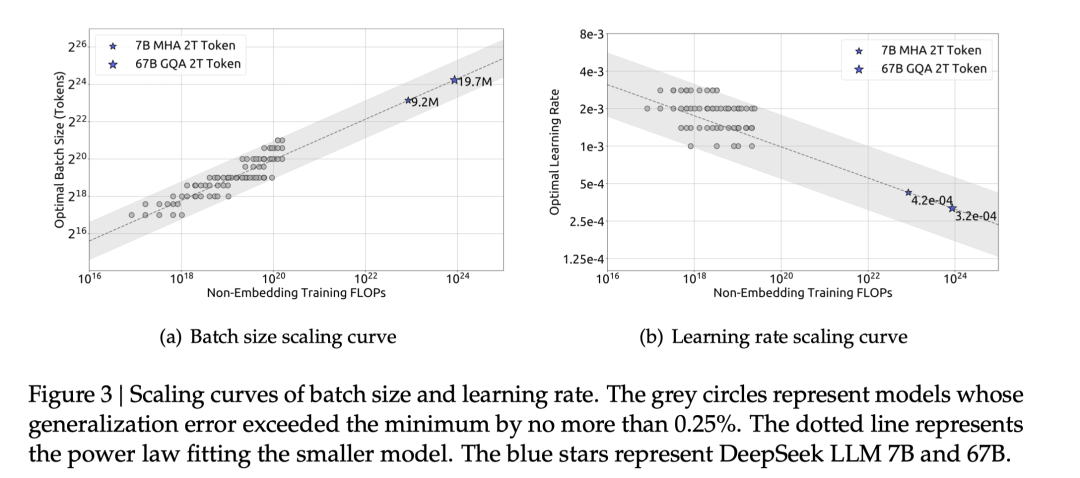
3.2 估计最优模型和数据扩展
在获得最优超参的经验公式后,我们借助Chinchilla中的IsoFLOP profile方法,对模型和数据的scaling laws进行了探究。为了获得更准确的估计,我们还使用Non-embedding FLOPs/token替换之前scaling laws研究中通常使用的模型参数来表示模型的规模。在此基础上,我们成功拟合出了模型和数据的scaling curve,并得到了模型和数据的最优分配比例。
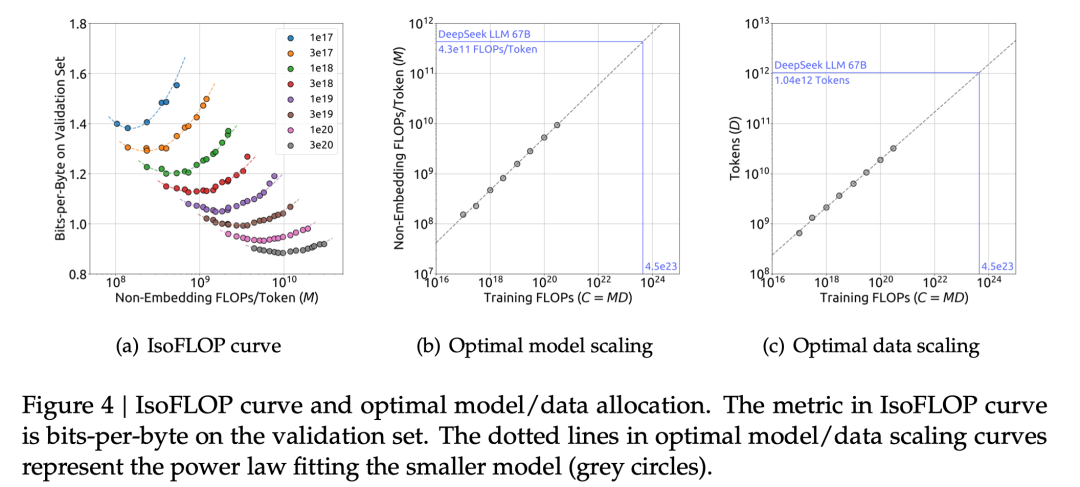
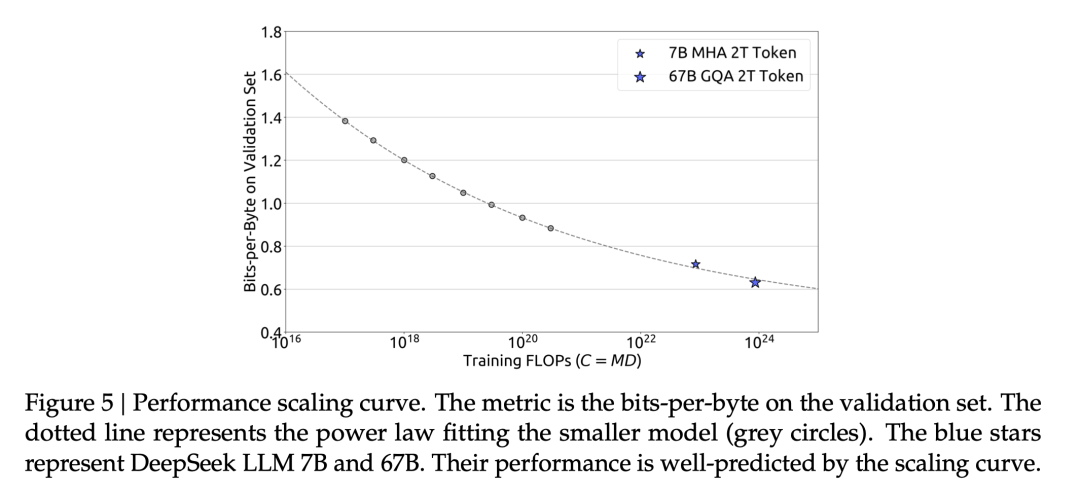
3.3 不同数据下的Scaling Laws
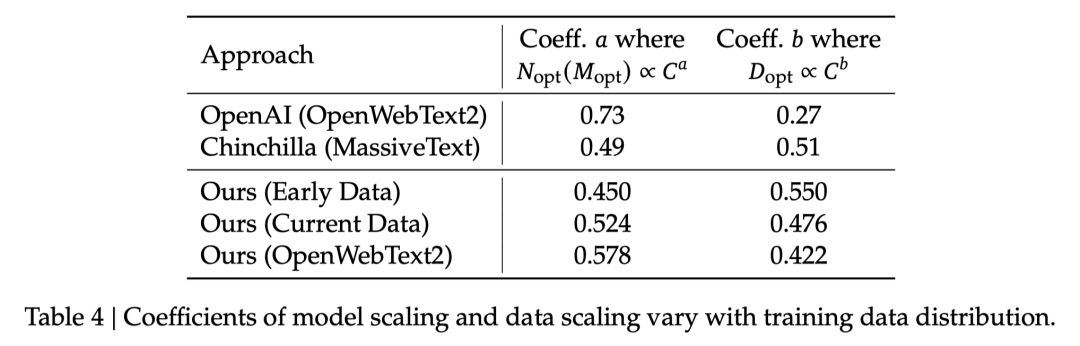
在DeepSeek LLM的开发过程中,我们的数据也经历了多次迭代,在调整数据比例的同时不断提高数据质量。这也让我们有机会探究不同数据对scaling laws的影响。
4. 对齐&评估
4.1 方法
在此版DeepSeek的对齐中,方法没有秘密,使用了标准的SFT和DPO进行helpfulness和safety方面的对齐。其中,SFT使用了约一百五十万数据,数据分布比例约为safety数据30万条,helpfulness 120万条。其中,helpfulness的细分占比为46.6%的数学,22.2%的代码,其余为普通文本类对齐数据。
4.2 Helpful评估
我们对模型做了全面的有用性评估,包括一系列的公开评测基准、开放性语言生成、以及一系列从未见过的考试题,客观公平地展现模型语言理解、编程、数学、知识、指令跟随等一系列能力。
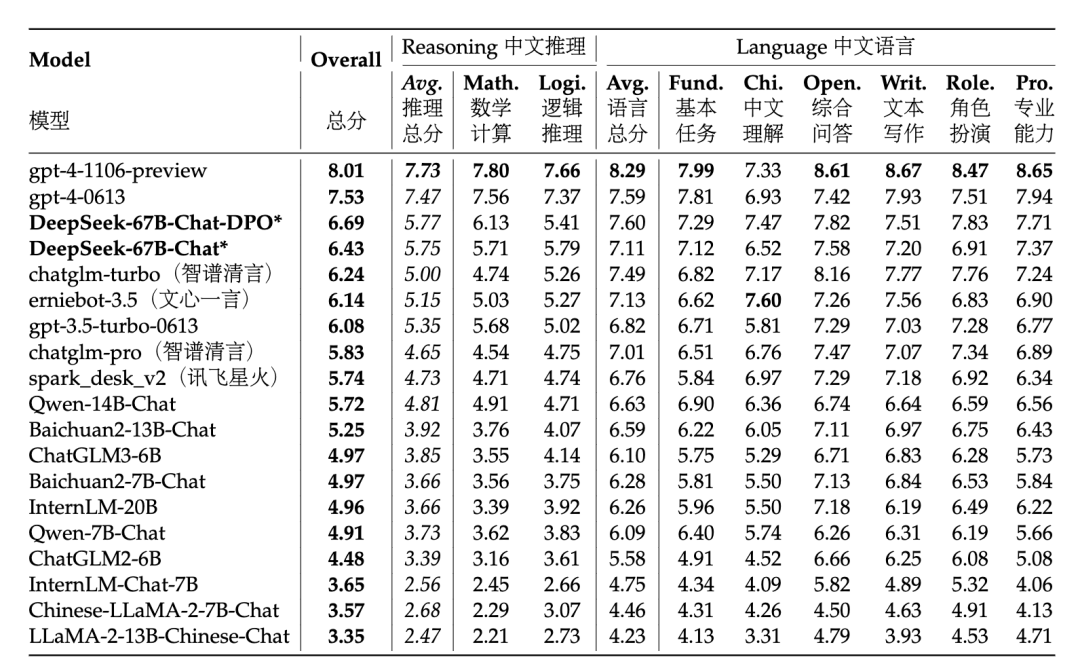
· 开放性语言生成:在清华-智谱提出的中文AlignBench开放语言生成能力评测集上,DeepSeek模型表现仅次于GPT-4,在中文能力上超过了GPT-4-0613。
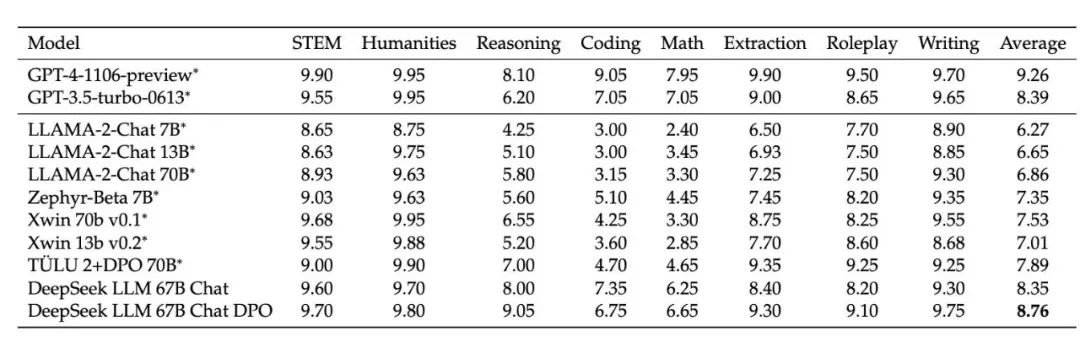
4.3 安全评估
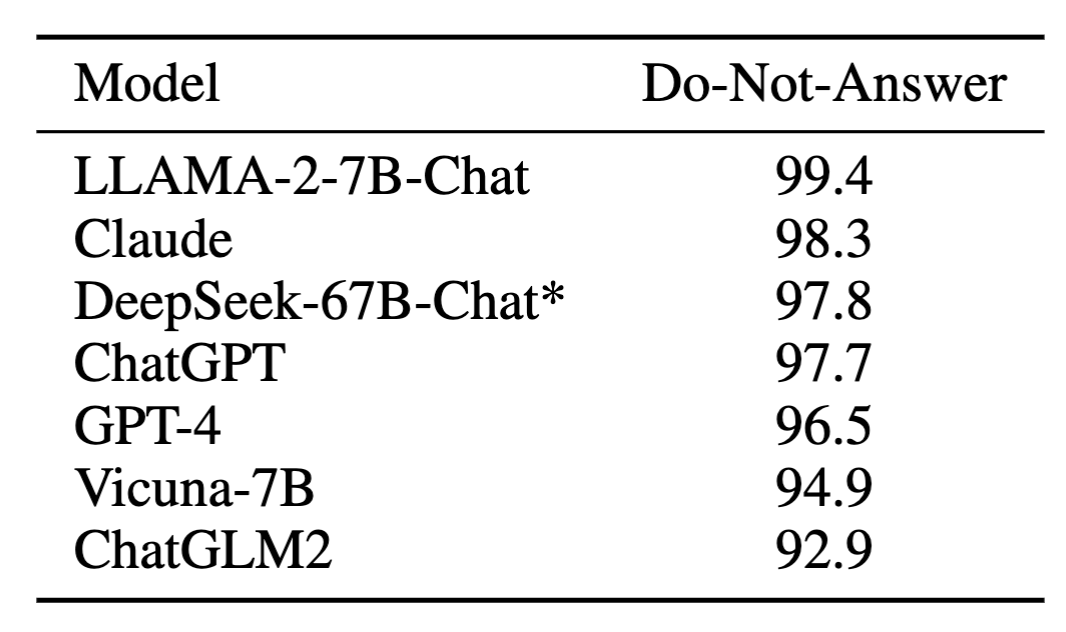
除了模型的有用性,我们也高度重视模型的安全性。我们在模型的全训练过程中(包括预训练、SFT和DPO阶段)都进行严格的数据安全性筛选,来保证训练得到的模型是足够符合人类价值观的,并且具有足够的社会亲和性。
4.4 讨论
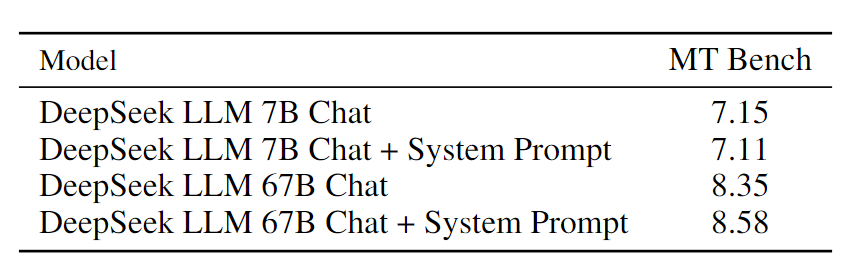
· 选择题数据对于大模型的影响:加入选择题可以提升模型在一些特定benchmark指标可以说是业界“公开的秘密”。我们在SFT阶段对加入大量选择题进行了尝试,获得了选择题相关测试集(C-Eval,MMLU等)极大的提升,但其他测试集提升微乎其微。所以,加入选择题更像一种“Benchmark Decoration”,为了不过拟合选择题测试集,我们避免在预训练及SFT中加入大量选择题。

欢迎访问: https://hf.co/deepseek-ai
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注微信公众号:
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢