
2023年12月15日,OpenAI的“超级对齐”团队发表了首篇论文,题为《弱到强的泛化:通过弱监督引出强性能》(Weak-to-Strong Generalization: Eliciting Strong Capabilities with Weak Supervision)。该论文为超级模型的实证对齐指明了新研究方向,并展示了良好的初步结果。
论文实则关乎人工智能发展的终极难题:当人工智能模型的智慧超越人类时,应怎样对强大人工智能进行有效监管,使之与人类价值观保持一致、不对人类造成伤害?

对此,OpenAI旨在探明的核心问题是:能否利用深度学习的泛化特性,以弱监督来控制强模型?即,我们能否用一个能力更弱的模型来监管另一个能力更为强大的模型?
该论文试图证明:通过弱模型监管强模型,或会是一条行之有效的路径。

01
AI VS 人类:
人工智能,人类把握得住吗?
据路透社、纽约时报等媒体报道,早在2023年3月29日,埃隆·马斯克(Elon Musk)和苹果联合创始人史蒂夫·沃兹尼亚克(Steve Wozniak)等1000多名科技界领袖呼吁暂停开发人工智能。他们担心这场“没有人能预测或控制的危险竞赛”会对社会和人类构成“深远的风险”,且可能产生“灾难性”影响。
路透社:“马斯克呼吁停止AI发展,称其对社会有害”
在由非营利组织生命未来研究所(The Future of Life Institute)发布的一封名为《暂停大型人工智能实验》公开信中,马斯克和其他科技界领袖呼吁,所有人工智能实验室应停止产品开发6个月以上,并对人工智能进行更多风险评估。
“我们呼吁所有人工智能实验室立即暂停比GPT-4更强大的人工智能系统的试验,至少6个月。”信中建议道,暂停行动应该是公开的、可核实的。如果相关实验室拒绝,呼吁者们希望政府能够介入,并强制暂停实验。
奇点指向一种假设的未来——技术超越了人类的智力,改变了人类演变的道路。而一旦人工智能达到这一点,其创新速度将远超人类。
千人署名要求暂停人工智能发展的背后,无疑是对人工智能超越人类智慧的担忧,是对“奇点将近”的惶恐。
OpenAI也认为,远超人类智慧的“超级智能”(superintelligence)将在未来十年之内涌现,而其“超级对齐”(Superalignment)团队正是为破题而来。
2023年7月,OpenAI首次提出“超级对齐”(Superalignment)的概念,并宣布将投入20%的计算资源,花费4年的时间全力打造一个超级对齐系统,意在正确引导、监控超级人工智能系统,让人工智能系统与人类价值观保持一致,确保超越人类智慧的人工智能系统亦不威胁人类安全,乃至造福人类。
02
OpenAI:“由弱到强泛化”
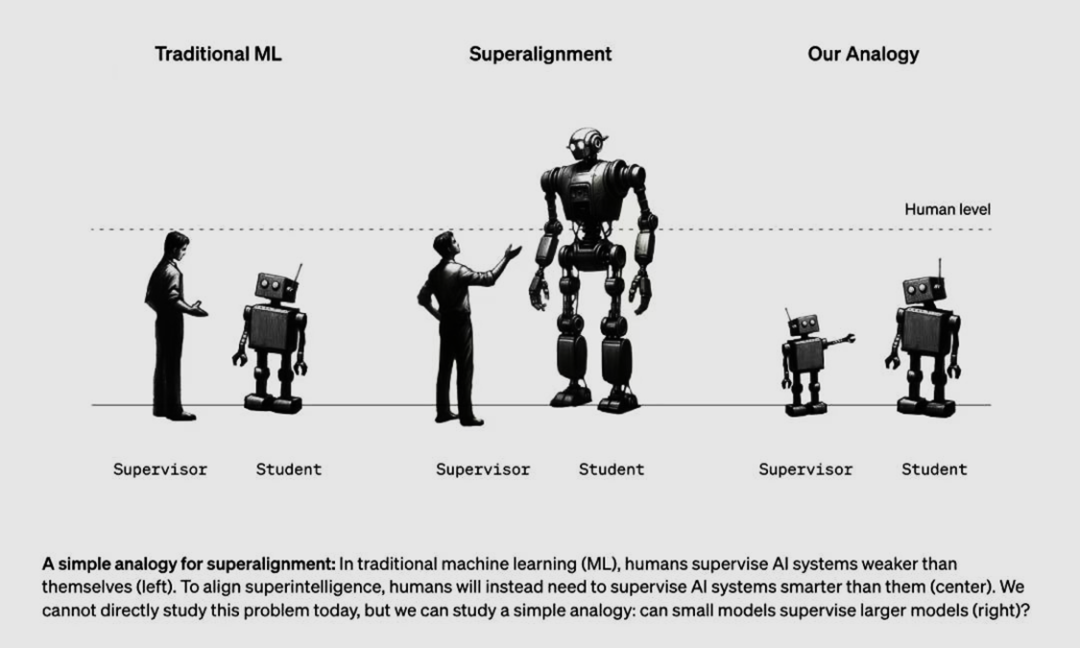
从左到右依次是“传统机器学习”(人训练弱AI)、超级对齐(人训练强AI)和OpenAI的假设(弱AI训练强AI)
OpenAI为什么要提出“从弱到强的泛化”?
什么是“从弱到强的泛化”?
弱模型监督能否开发出更强模型的全部能力?
该方法能否有效监管强AI模型?
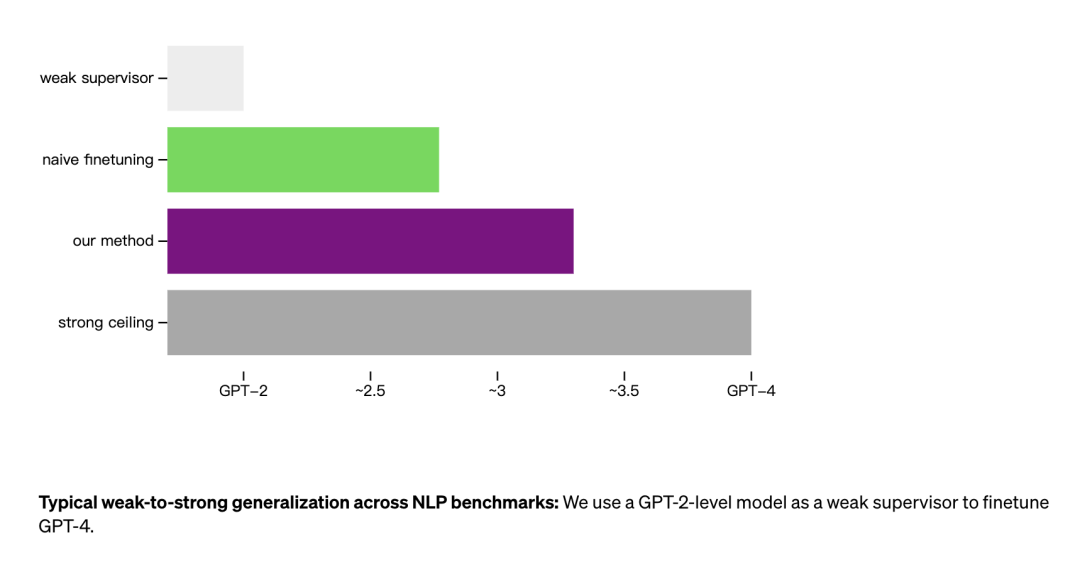
弱模型的性能表现基准(weak), 通过弱模型初始微调后的强模型的性能(weak-to-strong), 强模型的性能上限基准(strong ceiling)。
论文结论
03
人工智能治理,不止是技术问题
随着AI能力的迅速发展,模型对齐工作已经接近奇点,受限于人类标注者有限的能力以及规模化(Scale Up)的难度,寻求更为有效、不完全依赖人类标注者的算法迫在眉睫。OpenAI的工作带给研究团队和工业界同仁许多启发,更多研究者今后将把他们的目光转向以弱AI监督强AI自提升的算法道路。
技术的探索毋庸置疑是必要的,但与此同时,人工智能是否应该继续开发,并不单单是技术问题,还涉及治理、伦理等诸多方面。好的监管规则,能在一定程度上限制危险技术的开发、扩散或滥用。也为中国未来的AI监管提供了注解,本文认为可从以下5方面进行探索:
1.加强数据监管:以弱AI监督强AI需要大量数据支持,因此应该加强对数据的监管,包括数据质量、数据隐私等方面。
2.强化算法公正性:在以弱AI监督强AI的过程中,需要确保算法的公正性,避免算法偏见和歧视。这需要采用多样化的数据集进行训练,同时对算法进行严格的测试和验证。
3.推广算法解释性技术:对于强AI的模型,应该采用算法解释性技术,以便相关机构能够理解并掌握其工作原理和运行过程。
4.建立安全机制:为确保强AI的模型安全,需要建立安全机制,包括安全验证、安全设计和安全防护等方面,避免恶意攻击或误用导致造成的不利影响。
5.加强人工智能伦理方面的研究:以弱AI监督强AI需要关注人工智能伦理方面的问题,如隐私保护、公平性、透明度等,需要加强研究和探索相关的理论和方法。
参考来源:https://openai.com/research/weak-to-strong-generalization
论文链接:https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
文案丨陶含孜 王昕晨
排版丨赵杨博
校审丨王祚




关于我们
清华大学人工智能国际治理研究院(Institute for AI International Governance, Tsinghua University,THU I-AIIG)是2020年4月由清华大学成立的校级科研机构。依托清华大学在人工智能与国际治理方面的已有积累和跨学科优势,研究院面向人工智能国际治理重大理论问题及政策需求开展研究,致力于提升清华在该领域的全球学术影响力和政策引领作用,为中国积极参与人工智能国际治理提供智力支撑。
新浪微博:@清华大学人工智能国际治理研究院
微信视频号:THU-AIIG
Bilibili:清华大学AIIG
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢