
点击下方卡片,关注「集智书童」公众号

视觉 Transformer (ViTs)在视觉识别任务上近期取得了显著的成功。这种成功不仅归因于它们的自注意力表示,也归功于新开发的训练配置。例如,在训练技术方面的改进,如强大的数据增强和知识蒸馏,大大缓解了ViTs的耗数据问题,使其对于在ImageNet-1K上的训练更加可行。
训练配置的另一个重要发展是 Token 化(token labeling),其中,patch Token 被密集地分配给ViTs。在某种意义上, Token 化也可以被视为一种硬知识蒸馏的替代形式。然而, Token 化的密集性质使ViTs能够利用图像中的更精细信息,并考虑不同类别和物体定位。
与传统的知识蒸馏方法相比, Token 化使ViTs能够利用图像中的更广泛信息,从而获得更准确的结果。 Token 化的成功依赖于精心设计的 Token Level 标注器(即 Token 化器),它们可以为patch Token 提供准确的位置特定信息(即 Token )。在All tokens matter中,这通过使用在ImageNet-1K上预训练的卷积神经网络(CNNs)的特殊再 Token 过程来实现。虽然视觉 Transformer 在表示学习方面表现出色,但对其作为 Token 化器的建模的研究还很少。这提出了两个有趣的观点:
基于Transformer的模型是否能够自我产生有意义的 Token 标签?
是否可以利用自我产生的知识来改进ViTs的预训练,而不是外部教师?
STL: 本文旨在回答上述问题。作者提出了一种Self-emerging Token Labeling(STL)框架,该框架利用ViT Labeler 产生的自定义 Token 标签,而不是依赖卷积神经网络(CNNs)。STL基于最近提出的全注意力网络(FAN),出于两个原因:
首先,FAN在 Token 特征上表现出出色的自涌现视觉分组,这可以用来生成高质量的 Token 标签。 其次,FAN是一个具有最先进准确率和鲁棒性的ViT Backbone 网络家族。通过遵循 Token 标签设计的原则来进一步改进这个强大的 Backbone 网络家族,并验证其有效性。
贡献可以总结如下:
STL证明了ViT模型可以成为有效的 Token 标签器。作者提出了一种简单而有效的方法来训练一个FAN Token 标签器,该 Labeler 可以生成语义上具有意义的 Token 标签。
作者进行了深入分析,并确定了对 Token 标签准确性产生关键影响的因素。除了观察到的因素外,作者还设计了一个解决方案,以保留更准确的 Token 标签目标目标,从而改进模型预训练。
作者的模型使用STL训练,在不需要额外使用ImageNet-1K数据的情况下,在out-of-distribution数据集上创下了新记录。最佳模型在ImageNet-A上实现了46.1%的鲁棒准确率,在ImageNet-R上实现了56.6%的鲁棒准确率,如图1所示。
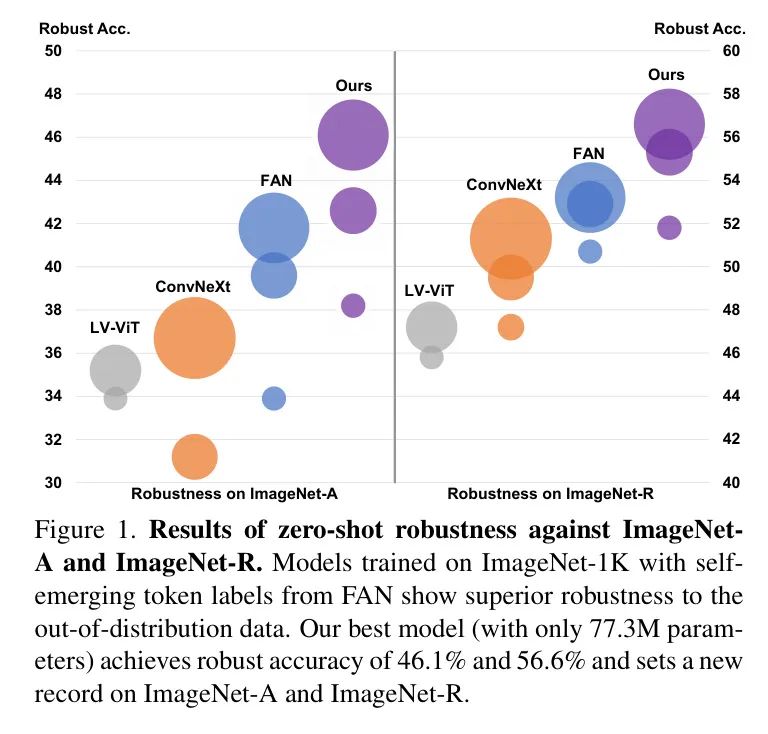
在下游任务的实验中,证明了 Backbone 模型的改进性能可以迁移到语义分割和目标检测。
STL框架类似于知识蒸馏中引入的教师-学生训练策略,包括两个阶段:
第一阶段: 训练一个FAN Labeler (FAN-TL)模型来生成 Token Level 标注。任务本质上是一个"鸡还是蛋"的问题,因为在 Token 标签的生成上没有明确的监督。通过同时 Token 分类 Token 和全局平均池化 Token 来解决这个问题。这生成了语义上具有意义的 Token 标签,如图2(b)所示。
第二阶段: 使用原始类别标签和来自FAN-TL的 Token Level 标注训练一个FAN学生模型。观察到 Token 标签的质量不完全,作者引入了一个基于Gumbel-Softmax的 Token 选择方法,该方法根据高置信度自适应地选择 Token 。所选 Token 的标签质量更好,目标定位更准确,从而提高了预训练。
视觉 Transformer (ViTs)是基于Transformer([7])的一类视觉识别模型。ViT将输入图像分割成一系列小patch,将每个patch映射为嵌入(也称为patch Token ),并附加位置嵌入。然后将生成的patch Token 和另一个可学习的类别 Token (用于聚合全局信息进行分类)输入到一系列Transformer编码器中,这些编码器由多头自注意力(multi-head self-attention)和FFN块组成。在类别 Token 上附加一个线性投影层来预测类别概率。
一些并行的研究指出,ViTs在对抗out-of-distribution样本方面表现出出色的零样本鲁棒性。一些工作提出了使用负数据增强和对抗训练来进一步增强鲁棒性。最近,FAN作为一种具有最先进准确率和鲁棒性的ViT Backbone 网络家族被引入。FAN继承了普通ViT的自注意力块,但还引入了一个通道注意力块,它采用了一种基于注意力的设计,以更全面的方式聚合跨通道信息,从而导致表示的改进。
Token 化(token labeling)All tokens matter被提出来改进ViT预训练。从训练策略的角度来看,它类似于知识蒸馏,因为它采用了师生模式。它也与ReLabel相关,它为图像提供多标签标注而不是单标签标注。然而,ReLabel和知识蒸馏都依赖图像 Level 的标签作为全局监督,而 Token 化将标签分配给每个图像patch Token ,并采用密集方式监督学生模型。
Token 化也与BEiT中的 Token 化相关,其中使用离线的预训练离散VAE作为 Labeler ,将patch编码为视觉 Token (即视觉词表中的代码)。与 Token 标签不同,这些视觉 Token 并没有明确的语义含义,因为它们起源于无监督训练的词表。STL与先前的 Token 化和蒸馏方法不同,其中预训练卷积神经网络广泛用作 Token 化器。相反,STL将教师和学生置于同一种Vision Transformer架构中,以生成高质量的 Token 标签。
在图像分类中,CNNs发现目标定位的现象。这个有趣的发现,也被称为类激活图(CAM),为 Token 化奠定了基础。最近的研究表明,ViTs在无需显式监督的情况下,展示了出色的物体定位能力。例如,DINO表明自监督的ViT特征可以生成语义上具有意义的物体分割。GroupViT表明仅使用文本监督的ViTs中出现了语义分割。同样,FAN揭示了ViT模型鲁棒性与其出色的视觉分组能力有关。这一特性使作者决定在FAN模型之上发展Self-emerging Token Labeling。
正如前面提到的,作者提出了一个Self-emerging Token Labeling(STL)框架,该框架使用自生成的 Token 标签来改进ViT预训练。
STL包括两个阶段:
训练一个有效的 Token 化器; 训练一个带有Self-emerging Token Labeling的学生模型。
在第一阶段,训练一个FAN Labeler (FAN-TL)来生成高质量的 Token 标签。正如在第1节和第2节中讨论的那样,FAN具有强大的鲁棒性和获取语义上具有意义的视觉分组的强大能力,这些强大的特性使作者能够在没有过多复杂功能的情况下获得高质量的 Token 标签。
在第二阶段,使用来自FAN-TL的图像级标签和FAN-TL生成的Self-emerging Token Labeling来训练一个FAN学生模型。在高层次上,FAN-TL和FAN学生模型遵循与FAN相同的架构设计,但稍微修改了patch Token 的结构。作者将每个patch Token 附加一个线性层来容纳 Token 标签,类似于在原始FAN和ViT设计中为类别 Token 添加的分类头。
原始FAN采用只使用图像级标签作为监督的训练范式。用表示输入图像,将一系列小patch()作为输出,其中是patch Token 的数量,代表类别 Token ,分别代表patch Token 。训练目标可以数学地表示如下:
其中是softmax交叉熵损失,是相应类别的图像级标签。
Token 化的关键是生成准确的位置特定 Token 信息。然而,遵循公式1中的常规训练范式,FAN模型的 Token 输出在训练过程中没有得到很好的语义引导,因为它们在训练过程中没有得到监督。作者提出了一种简单而有效的方法来解决这个问题。
作者的想法受到了ViTs训练中一个有趣的现象的启发,即在ViTs训练中,有意义的目标分割自然出现。与DINO中的自监督训练不同,利用FAN的强大视觉分组能力,并设计了一种完全监督方法,允许FAN生成准确和语义有意义的位置特定 Token 。
作者对所有patch Token 进行全局平均池化,然后同时将类别标签分配给类别和平均池化 Token 。FAN-TL的训练目标可以写如下:
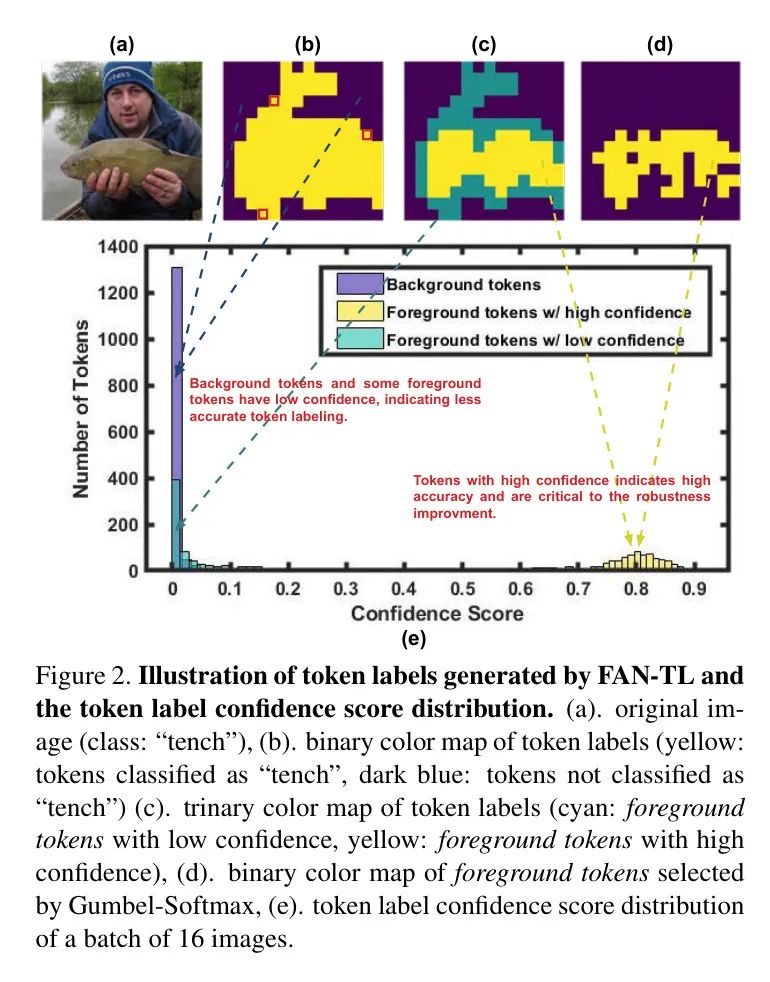
其中权衡两个损失函数的重要性。在实验中设置为1。在图2(b)中展示了一个由FAN-TL生成的 Token 标签的可视化示例。黄色的区域(即前景)代表与图像级标签相同的 Token (称之为前景 Token )。相反,深蓝色的区域(即背景)代表与图像级标签不同的 Token (称之为背景 Token)。可以看出,Self-emerging Token Labeling标签显示了目标目标"tench"的有意义的分割。
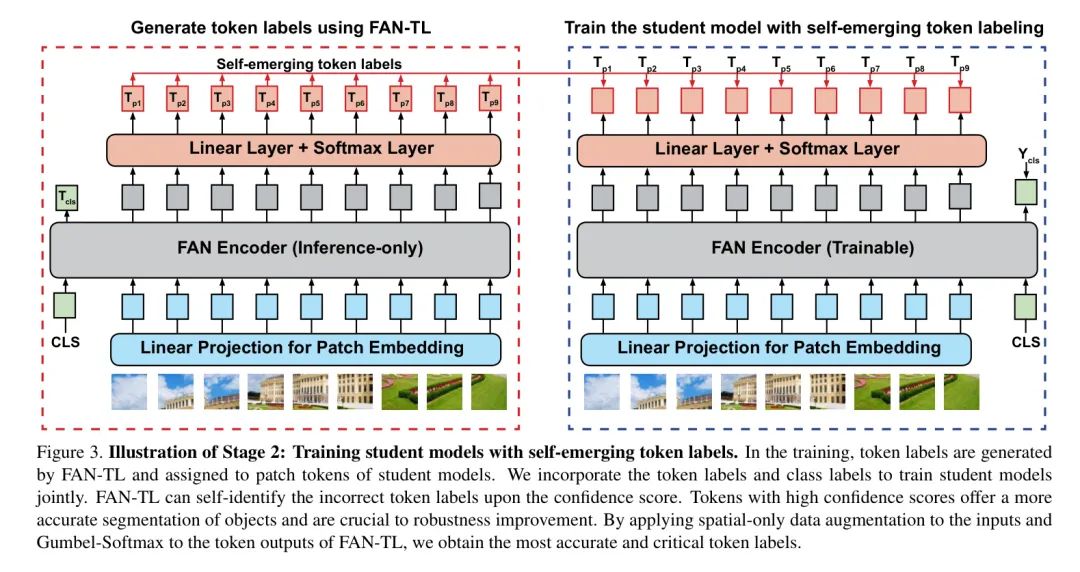
如图3所示,取FAN-TL的 Token 输出作为学生模型patch Token 的标签。然后将 Token 标签与类别标签结合,并共同优化类别 Token 和所有patch Token 的损失。训练目标如下:
其中表示FAN-TL的patch Token 输出,是超参数,用于平衡两个损失函数。在作者的实验中,设置为1。请注意, Token 标签的正确性(尤其是_foreground Token _)至关重要,因为错误的标签会引入无用的局部信息。
因此,作者提出了一些实现技巧,以生成和保留高度准确的 Token 标签,基于以下两个观察结果:
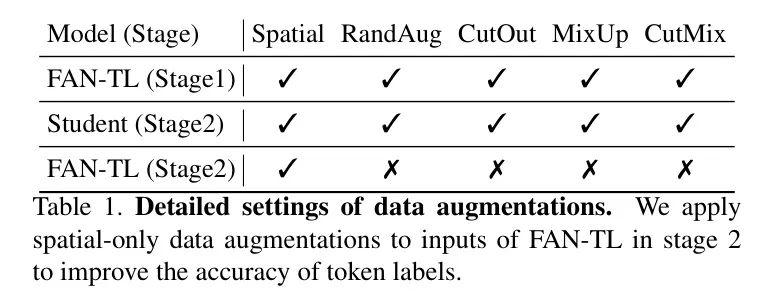
观察1:数据增强显著影响 Token 标签的准确性。最近的研究表明,数据增强可以提高ViT模型分类的准确性和鲁棒性。然而,大多数增强方法会降低 Token 标签的准确性。例如,RandAug中的增强,如分色和太阳能化,会更改像素值,CutOut会随机删除图像的一部分,Mixup和CutMix会将两个图像的内容混合,这都使得FAN-TL很难为patch Token 分配正确的标签。
为此,在生成 Token 标签时禁用这些数据增强,并保留仅包含空间信息的增强(即翻转、旋转、剪切和变换)。请注意,作者仍然在学生模型上应用全部数据增强。数据增强的具体设置如表1所示。
此外,强大的数据增强可以被视为类似于out-of-distribution数据集中损坏和扰动的无噪声噪声。FAN-TL和学生在数据增强上的输入差异使得自涌现的 Token 标签可以在噪声存在的情况下提供干净和正确的信息,从而提高模型的鲁棒性。
观察2:即使只包含空间信息的增强,也不是所有的Self-emerging Token Labeling都是正确的,甚至对于FAN-TL。例如,如图2(b)所示,一些只包含"人"和"湖"的patch(红色正方形)被FAN-TL错误地分类为目标目标"鲑"。确保前景 Token 标签的准确性特别重要,因为它们包含主导预测结果的图像目标。
然而,由于缺乏patch Level 的 GT ,确定哪些标签是错误的具有挑战性。有趣的是,FAN-TL可以根据 Token 标签的置信度自我识别这些错误分类的前景 Token ,这也归因于它的视觉分组能力。 Token 标签置信度定义为每个 Token 输出类的最大概率。
作者发现,具有正确标签的 Token 倾向于具有更高的置信度分数(0.7~0.9),如图2(c)和图2(e)所示,黄色区域表示置信度分数较高的前景 Token (0.7~0.9),这些 Token 产生了高度准确的目标目标分割。相反,蓝色区域表示置信度分数较低的前景 Token (0~0.2),它们恰好是具有错误标签的 Token 。
作者试图为目标目标(即foreground tokens)分配高度准确的标签。但是,对于所有图像的每个patch Token 的置信度分数进行完全检查是极其困难的,因为它会显著增加训练时间和需要更多的计算资源。因此,提出一种轻量级的替代方法,在 Token 输出上应用Gumbel-Softmax。从数学上讲,它可以表示为:
其中是维softmax向量,是类别概率,是从标准Gumbel分布中独立同分布地抽取的独立同分布样本,是softmax温度。在应用Gumbel-Softmax后,置信度分数较高的 Token 标签保持不变,而置信度分数较低的标签极有可能改变。
如图2(d)所示,以简单而有效的方式保留正确的 Token 标签并消除错误的 Token ,实现高准确度的foreground tokens标签和高精度目标分割。此外,由于patch Token 的一侧的训练目标可以看作是一个自训练过程,将softmax输出转换为"one-hot"概率分布(即硬标签),在自训练中使用硬标签可以促使模型通过最小化熵预测高置信度。
遵循上述仅包含空间的增强,可以重写学生模型的训练目标:
其中是FAN-TL的一个hot编码Gumbel-Softmax输出,是带有仅包含空间的数据增强的图像patch。同时,作者注意到所有background tokens(即深蓝色区域)也具有低置信度。这可能是因为这些 Token 既不包含与目标目标明显相关的特征,也不包含与数据集中任何其他类相关的明确特征。
然而,在训练中保留所有 Token (即使它们具有低置信度),遵循All tokens matter中的做法,因为涉及更多的 Token 进行损失计算可以获得更好的性能。
作者在图像分类任务上评估STL,并将其迁移到下游的语义分割和目标检测任务。
数据集。对于图像分类任务,作者在ImageNet-1K(IN-1K),ImageNet-C(IN-C),ImageNet-A(IN-A)和ImageNet-R(IN-R)上测试模型性能和鲁棒性。IN-C包含来自噪声、模糊、天气和数字类别等自然损坏的自然损坏,广泛用于评估模型对转移分布数据的鲁棒性。IN-A和IN-R由与ImageNet训练分布不同的图像组成,如自然对抗示例和由艺术渲染生成的图像,因此广泛用于测量模型对out-of-distribution数据的鲁棒性。
对于语义分割和目标检测,在Cityscapes(City),Cityscapes-C(City-C)和COCO上评估模型。与IN-C类似,City-C也包含来自同一四类别的损坏。
指标。在图像分类任务上采用标准的评估指标:对于IN-1K,使用干净准确率(clean accuracy);对于IN-C,作者使用鲁棒准确率(robust accuracy)。
作者还报告了IN-C上的平均损坏误差(mCE)。对于语义分割和目标检测,使用City和City-C上的干净和鲁棒均交点率(clean and robust mean Intersection over Union,mIoU)来评估模型性能,并在COCO上使用平均平均精度(mean average precision,mAP)作为指标。
此外,作使用保留率(retention rate)作为指标,以反映模型的鲁棒性不同容量模型的公平比较。保留率定义为。
实验是在8个NVIDIA Tesla V100s上进行的,代码基于Pytorch,timm库和MMSegmentation工具箱。作者采用FAN-Hybrid作为FAN-TL和学生的模型架构。
对于图像分类,作在ImageNet-1K上使用AdamW优化器,学习率为4e-3,批量大小为2048,训练350个周期。使用cosine学习率调度器,衰减率为0.1,每30个周期调整一次学习率。方程2和5中的和设置为1。
在训练中应用空间、RandAug、CutOut、Mixup和CutMix数据增强,并将标签平滑比设置为0.9。如第3节所述在FAN-TL的输入上应用空间数据增强,并在patch Token 输出上应用Gumbel-Softmax以获得准确的 Token 。使用预训练的图像分类模型作为语义分割的编码器,并使用SegFormer头作为解码器。
遵循SegFormer的训练配置,在Cityscapes上使用AdamW,学习率为6e-5,批量大小为8,训练160K次迭代。学习率调度器设置为"poly",默认因子为1.0。在训练中应用随机缩放、翻转和裁剪作为数据增强。
对于目标检测,遵循Swin Transformer+Cascade Mask R-CNN的做法,并使用AdamW(初始学习率为1e-4,权重衰减为0.05,批量大小为16)在COCO上训练作者的模型,共36个周期。
首先在图像分类任务上展示使用STL训练的模型性能,并将其与其他最先进模型进行比较(见表2)。
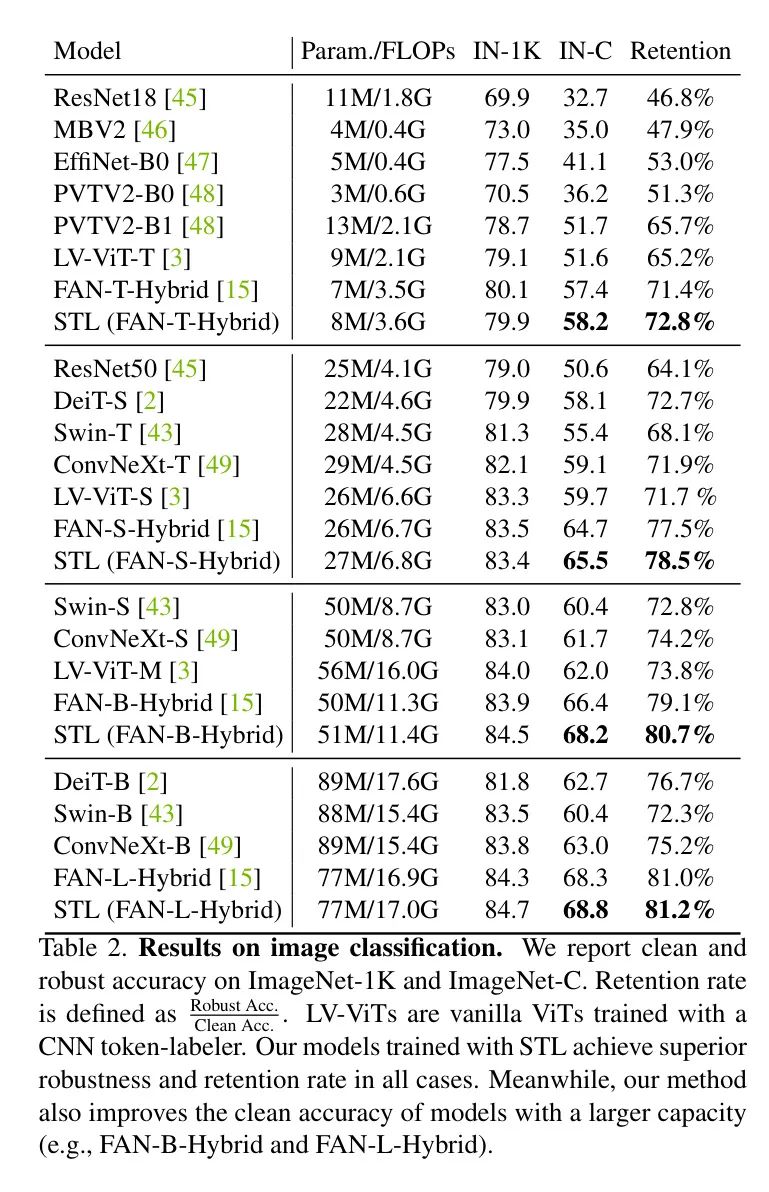
为了评估对分布性移相的零样本鲁棒性,所有模型都在ImageNet-1K数据上进行训练,并直接用于在ImageNet-C上进行推理,而无需微调。作者使用相同的模型类型来训练FAN-TL和学生的模型。可以看到,基于Transformer的模型通常比基于CNN的模型更鲁棒。
在所有大小 Level 上,作者的模型在其他模型上的鲁棒准确率和保留率均优于其他模型,包括仅使用类别标签训练的原FAN模型,这表明STL在提高模型鲁棒性方面的有效性。
值得注意的是,作者的模型在干净和鲁棒准确率方面显著优于LV-ViTs(即使用CNN Labeler 训练的普通ViT模型),这验证了FAN中的通道注意力块的重要性,并揭示了基于Transformer的模型中Self-emerging Token Labeling标签的潜力。
Token 标签嵌入图像patch的丰富局部信息。作者采用仅包含空间的增强和Gumbel-Softmax在FAN-TL上,以保留前景 Token 的高准确度,以确保Self-emerging Token Labeling始终为学生的模型提供正确信息。这种做法促进学生模型的泛化性能,因为它们可以在不同的输入数据分布下做出鲁棒的预测。
为了验证这一点,作者评估模型对out-of-distribution数据的鲁棒性,结果总结在表3中。
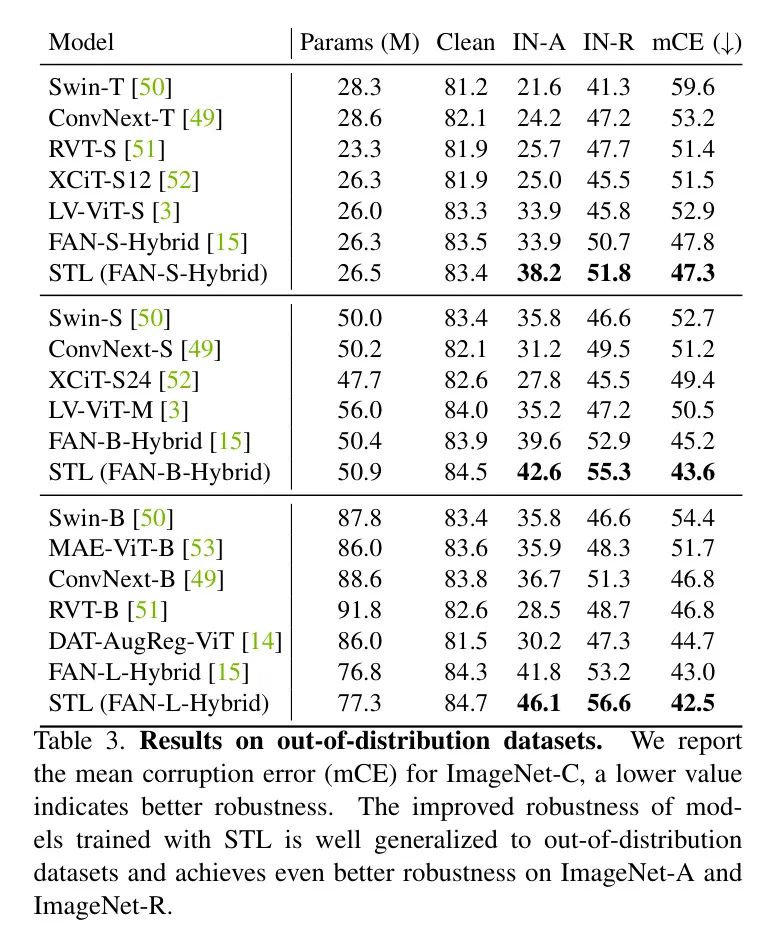
同样,这些模型并未进行微调以进行测试。作者发现LV-ViTs和原始FAN模型对out-of-distribution数据有很好的泛化能力,而其他基于Transformer的模型和最先进的基于CNN的ConvNext模型表现较弱。尽管原始FAN模型表现出色,但使用STL训练的模型展示出更好的泛化能力,并超过所有其他模型。
在IN-A和IN-R上的性能提升比IN-C和IN-R更显著,并创下了新的最先进水平,表明准确的Self-emerging Token Labeling对抵抗out-of-distribution数据的鲁棒性至关重要。
有研究表明使用不同训练配置的预训练模型在下游任务上的表现不同。All tokens matter验证了使用CNN Labeler 的 Token 在语义分割和提高干净mIoU方面有益。作者还评估了STL对语义分割的迁移性。
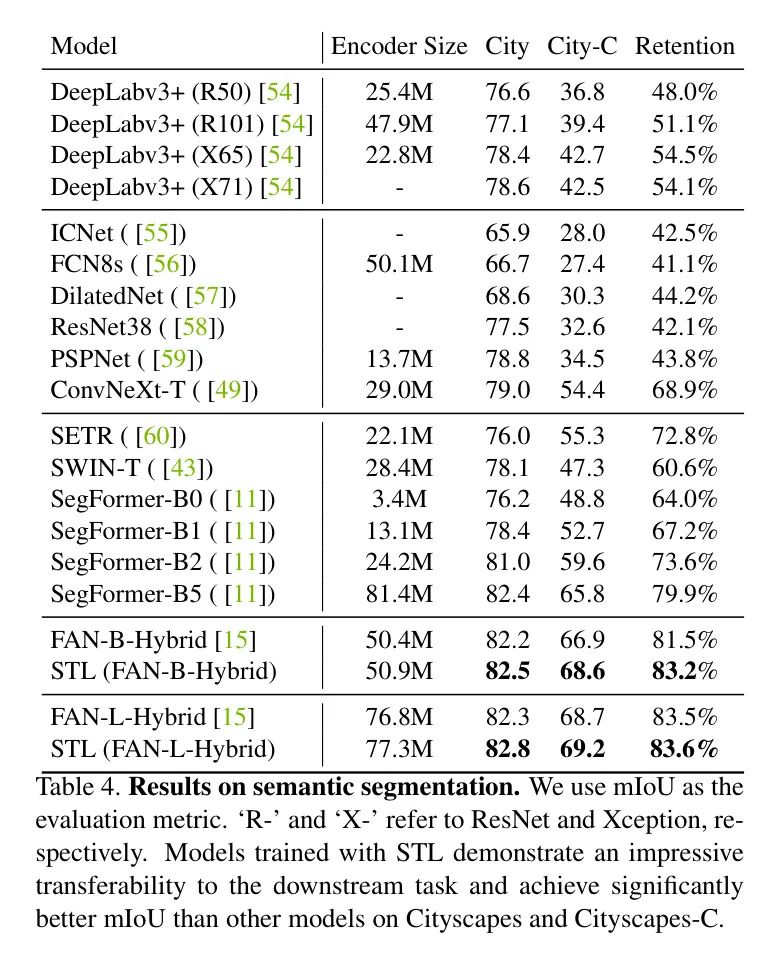
如表4所示,使用STL预训练的模型在迁移性方面优于原始FAN对应模型和其他重要 Backbone 网络。值得注意的是,STL在干净和损坏的数据集上都取得了优越的结果。据所知,这是首次揭示在 Backbone 网络预训练中应用密集监督不仅提高了干净性能,也提高了下游任务的鲁棒性。
同时,在COCO上验证了STL的迁移性到目标检测任务,并将在表5中呈现结果。
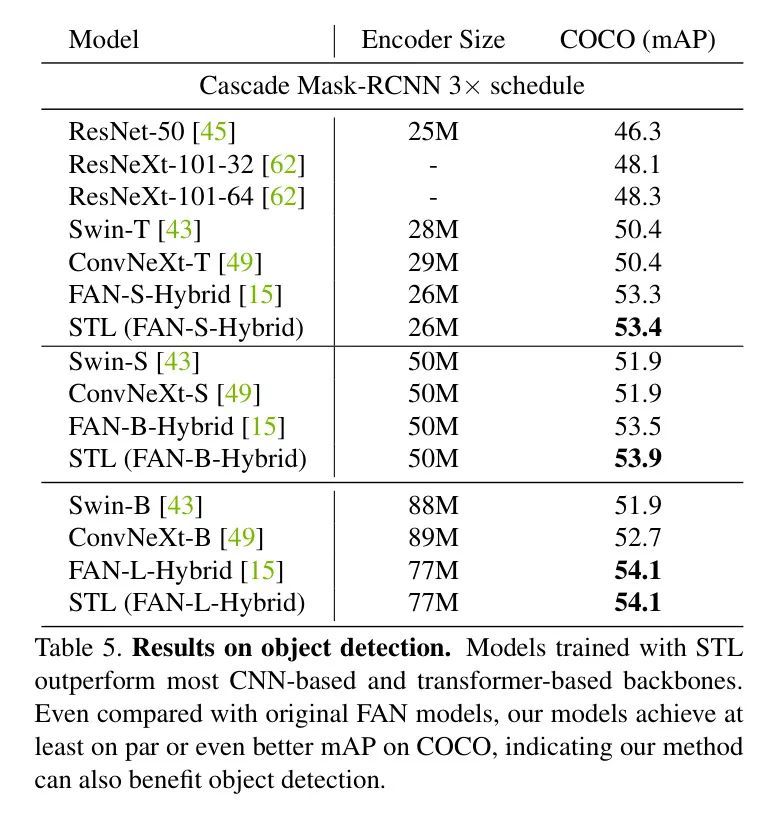
使用STL训练的模型在大多数基于CNN和基于Transformer的 Backbone 网络中表现更好。与原始FAN模型相比,STL为FAN-B带来了显著的性能提升,同时实现了与FAN-L和FAN-S相当的均方平均精度。
作者注意到,目标检测的整体改进并不如图像分类和语义分割那样明显,这可能是因为语义分割任务在密集预测的角度上与 Token 化更相似,而目标检测涉及不同的技术,如回归和多阶段细化。
作者对FAN-TL进行仅包含空间的增强,以获得准确无误的 Token ,这对于学生模型提供干净和正确的信息至关重要。这种策略是一个“干净的教师、噪声的学生”设计,学生仍然使用所有的增强。
作者设计这种策略的动机是让教师和学生在空间上对齐,教师尽可能干净地生成高质量 Token (如图4所示,强增强会使生成良好 Token 变得更困难)。

作者在表6中比较了针对FAN-TL施加的不同数据增强的影响。实验是在FAN-S-Hybrid模型上进行的。使用仅包含空间的增强 Token 的学生模型训练实现了最佳的鲁棒性,而施加更强的增强则有害于鲁棒准确性。
有趣的是,在FAN-TL和学生模型上应用一致的全部数据增强可以获得更好的干净准确性,这揭示出不同的数据增强组合可能在提高模型鲁棒性和干净性能方面发挥不同的作用。

作者提出使用Gumbel-Softmax作为轻量级解决方案来保留前景 Token 的正确标签并消除错误标签,从而获得更准确的物体分割。作者在FAN-S-Hybrid模型上评估Gumbel-Softmax的影响,结果见表7。
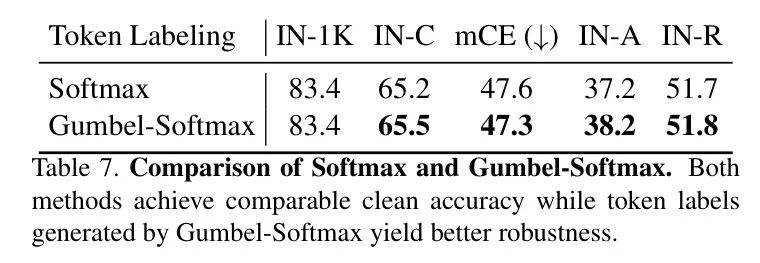
如表中所示,使用Softmax和Gumbel-Softmax生成的 Token 标签的模型在干净准确率上具有可比性,而Gumbel-Softmax提高了鲁棒准确性。这进一步验证了准确的前景 Token 标签对模型鲁棒性的重要性。
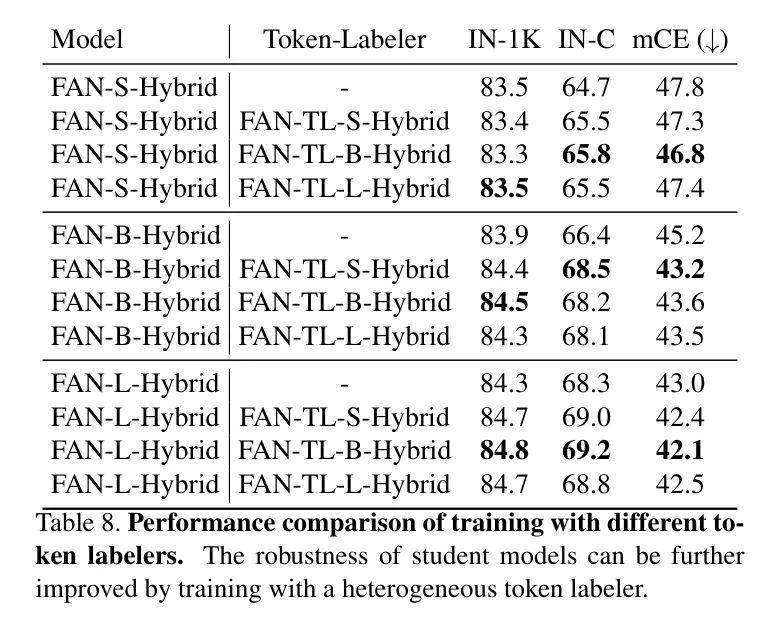
在之前的实验中,作者使用同构的FAN Labeler (例如,FAN-TL-S-Hybrid用于FAN-S-Hybrid)训练学生模型。作者对使用异构 Labeler 的训练感兴趣,并进行了消融实验,结果见表8。
对于每个学生模型,作者使用三种不同大小的异构FAN Labeler 进行训练,从小到大排列。使用异构FAN-TL训练的模型可以实现与使用同构 Labeler 训练的模型相当的或更好的性能。作者使用FAN-TL-B-Hybrid训练的大型模型进一步将干净和鲁棒准确率提高至84.8%和69.2%,mCE为42.1%。这表明STL对不同的 Labeler 具有鲁棒性。这种鲁棒性使作者能够使用较小的 Labeler 训练较大的学生模型,从而降低训练成本。
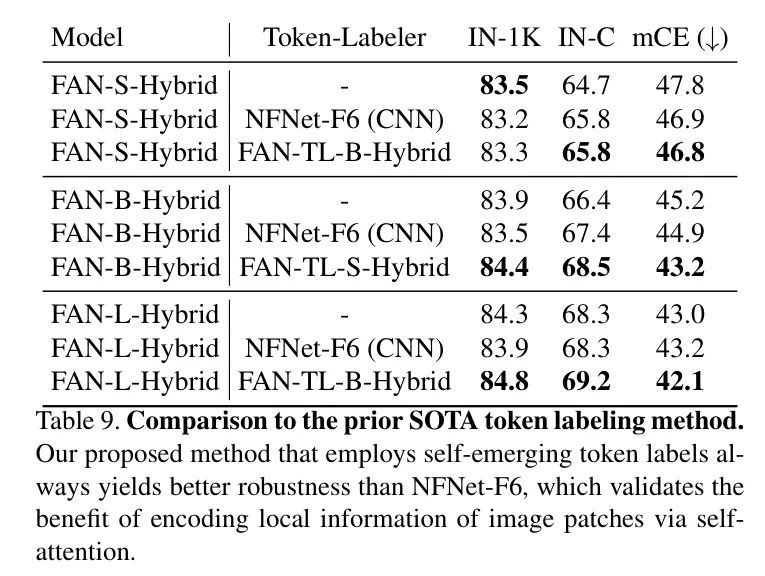
作者使用不同的方法训练相同的FAN模型,结果总结在表9中。可以看到,即使使用相同的學生模型,STL仍然显著优于CNN Labeler 。
请注意,NFNet-F6具有超过4亿参数,在ImageNet-1K上达到86.3%的Top-1准确率,而最大的FAN-TL(即FAN-TL-L-Hybrid)只有77.3M参数,达到84.3%的Top-1准确率。然而,FAN-TL始终比NFNet-F6产生更好的结果。这种背后的原因是Self-emerging Token Labeling为学生模型提供了自一致的信息。
在同时优化多个损失时,选择合适的损失权重很重要。为了研究损失权重的影响并验证STL在训练学生模型时对不同损失权重的鲁棒性,作者用各种值变化,并将在表10中呈现结果。
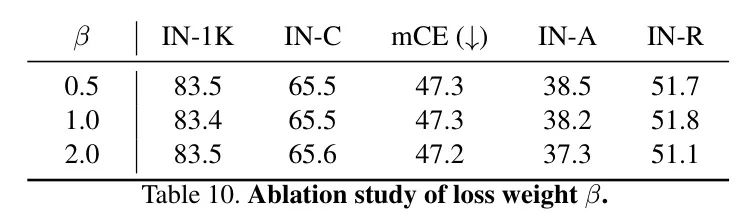
作者发现STL对不敏感。干净和鲁棒准确率在小的范围内波动。因此,作者简单地设置来平衡损失,使其对等权重。类似地,对于 Labeler 的训练,也设置为1。
在本文中提出了一种基于Transformer模型的Self-emerging Token Labeling(STL)框架,而不是CNNs。STL使得FAN Labeler 能够自产准确且语义有意义的 Token 标签,以进行密集监督训练学生模型。
通过广泛的实验和消融研究证明了使用STL训练的模型显著优于仅使用图像级标签的原FAN对应模型,并在各种视觉识别任务中实现了显著的鲁棒性改进。作者的研究表明,ViTs自产的知识确实可以为其预训练带来好处。作者希望这项工作能够启发ViTsSelf-emerging Token Labeling的潜力,并理解其未来的研究方向。
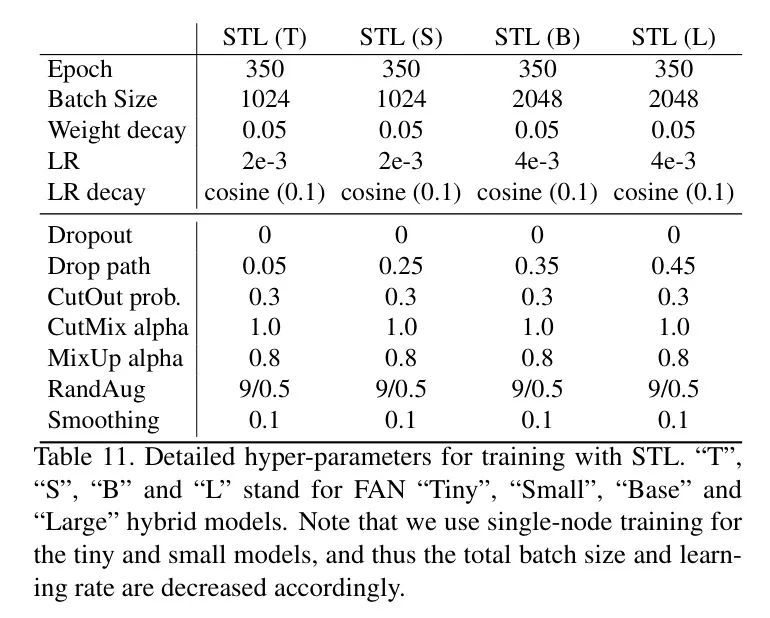
作者在表11中展示了详细的训练设置。使用多节点训练FAN基础模型和大型模型,以及单节点训练小模型和 tiny 模型。默认的批处理大小和学习率调整为单节点训练的 1024 和 2e-3。FAN-TL 模型在第一阶段的训练设置与第一阶段FAN学生模型相同。训练设置对于第二阶段FAN学生模型也相同。
作者还尝试了两种额外的训练FAN-TL的方法,但它们在生成有效 Token 标签方面都不太有效。
首先,通过只优化类 Token 损失(遵循传统的训练范式)来训练FAN-TL。由这种方法生成的FAN-TL Token 标签是没有意义的,因此无法改进预训练。
其次,通过同时优化类 Token 损失和全局平均池化 Token 损失,同时停止全局平均池化 Token 损失的梯度反向传播,来训练FAN-TL。
作者的目标是评估来自patch Token 侧的梯度的重要性。使用第二种方法训练的FAN-TL无法自我识别前景 Token 的错误分类标签,因为所有 Token 的置信分数都很高。因此,由使用第二种方法训练的FAN-TL生成的 Token 标签准确性较低。实验结果表明,来自类 Token 和全局平均池化 Token 侧的梯度在训练FAN-TL方面至关重要。
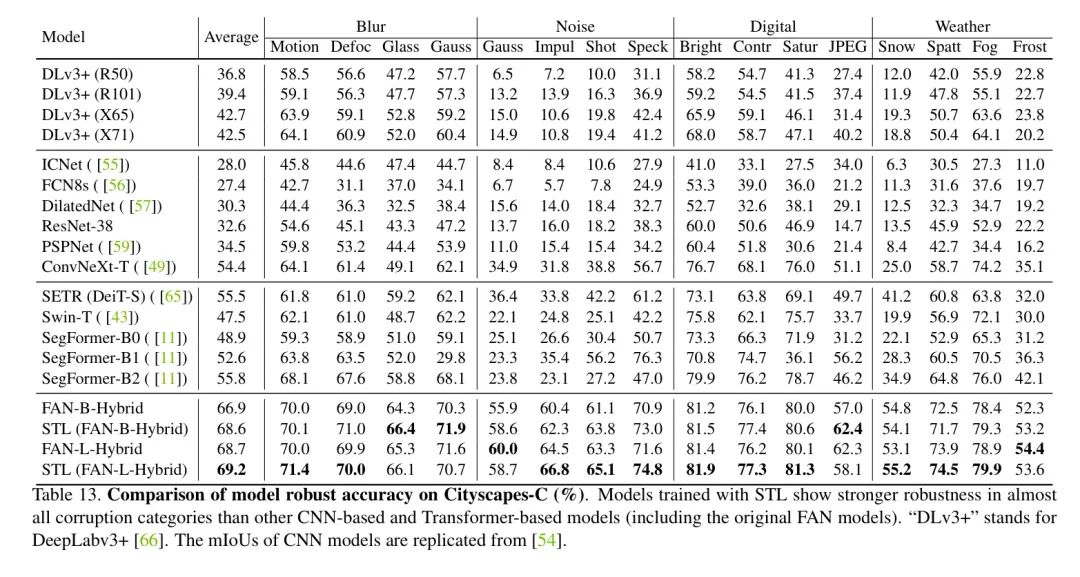
作者全面评估了模型对不同类型的损坏的鲁棒性,并在表12中总结了每个类别的结果。对于每个类别,作者平均所有五个严重程度的鲁棒准确性。与其它模型相比,原始FAN模型已经显示出比其他模型更强的鲁棒性。
然而,使用STL训练的模型在模糊和噪声损坏方面具有可比的鲁棒性,并且在数字和天气损坏方面表现出色,获得了更高的整体鲁棒性和特别适合实际应用,如自动驾驶车辆。

与图像分类任务类似在语义分割任务上,如表13所示,呈现了模型对不同类别的鲁棒性。遵循SegFormer 的做法,计算了噪声类别中前三个严重程度的平均IoU。对于其余类别,作者计算了所有五个严重程度的平均值。实验结果表明,使用STL训练的模型在几乎所有类别上,包括原始FAN对应模型,都优于其他基于CNN和Transformer的模型,表现出色。
如图2所示,FAN-TL可以生成语义上具有意义的 Token 标签。通过应用仅包含空间的增强和Gumbel-Softmax,作者可以进一步保留目标目标的更准确的 Token 标签。作者展示了使用仅包含空间的增强和Gumbel-Softmax生成的 Token 标签的更多可视化结果,如图5所示。
可以看到,FAN-TL在捕捉目标整体和为具有旋转、裁剪、剪切和变换的图像生成准确 Token 标签方面一直表现良好。

[1].Fully Attentional Networks with Self-emerging Token Labeling

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)





前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢