

编者按:最近斯坦福大学机器人研究中心的 Mobile ALOHA 项目引起了人们对机器人研究的广泛关注。该项目利用低成本的硬件,可以直接从真实演示中进行端到端的模仿学习,基于Transformer模型来预测机器人的行动,使Mobile ALOHA能够自主完成复杂的移动操作任务, 这个成果也给人们带来很大的期待。
虽然基于Transformer的大型语言模型(LLMs)带来的生成式人工智能的革命已经深刻改变了信息处理和文本生成的方式;这些大模型训练自海量来自网络或其它来源的数据,在语言和图像处理和生成等任务上涌现出惊人的能力。然而,这种方法在机器人领域却面临着巨大的挑战,当然训练数据集的稀缺是影响机器人广泛应用的因素之一。人们期待工业界和学术界实验室合作整合资源来攻克这些挑战。最近,IEEE Spectrum 杂志发表了“THE GLOBAL PROJECT TO MAKE A GENERAL ROBOTIC BRAIN(打造通用机器人大脑的全球合作项目)”介绍目前的机器人研究的一个活跃的全球合作项目。该项目的主要参与者加州大学伯克利分校Sergey Levine教授和 Google DeepMind 的资深科学家Karol Hausman联合撰写了这个报告。全球34个实验室联手参与该项目,通过整合多机器人数据和互联网知识,试图实现通用机器人大脑的构建。这一努力不仅为机器人学习提供了新的方向,也展示了人工智能领域合作的力量,将LLMs的抽象智能推向更实际、更广泛的应用。未来,这或将为机器人技术和大型语言模型的结合带来更多可能性。我们特将该文章编译出来和各位客户、合作伙伴朋友分享。如需转载,请联系我们(ID:15937102830)

生成式AI革命,如ChatGPT、Midjourney等工具体现在其核心基于一个简单的公式:采用非常庞大的神经网络,对其进行在网络上抓取的大规模数据集的训练,然后利用它来满足广泛的用户请求。大型语言模型(LLMs)可以回答问题,编写代码,吟诵诗歌,而生成图像的系统可以创作逼真的洞穴绘画或当代艺术。
那么为什么这些令人惊叹的AI能力没有转化为我们在科幻小说中看到的那种有用且广泛可用的机器人呢?哪里有可以清理桌子、叠被子并为您做早餐的机器人?
不幸的是,高度成功的生成AI公式——在大量互联网数据的基础上训练大型模型——并不容易转化为机器人技术,因为互联网并没有像文本和图像那样充满机器人交互数据。机器人需要从机器人数据中学习,而这些数据通常由研究人员在实验室环境中为非常具体的任务而缓慢而费力地创建。尽管在机器人学习算法方面取得了巨大进展,但没有丰富的数据,我们仍然无法使机器人在实验室外执行现实世界的任务(比如做早餐)。最令人印象深刻的结果通常只在单个实验室、单个机器人上工作,并且通常只涉及少数行为。
如果每个机器人的能力受到手动教授其执行新任务所需的时间和精力的限制,那么如果我们将许多机器人的经验汇集在一起,使新机器人可以同时从它们所有人那里学习呢?我们决定试一试。在2023年,我们在谷歌和加利福尼亚大学伯克利分校的实验室与北美、欧洲和亚洲的其他32个机器人实验室一起启动了RT-X项目,目标是汇集数据、资源和代码,使通用用途的机器人成为现实。
以下是我们从这一努力的第一阶段中学到的内容。
如何创建通用机器人
人类在这种学习方面要好得多。我们的大脑可以在一点点练习后处理基本上是对我们身体结构的改变,当我们拿起工具、骑自行车或坐车时就会发生这种情况。也就是说,我们的“具身”发生了变化,但我们的大脑适应了。RT-X的目标是在机器人中实现类似的功能:使一个深度神经网络能够控制许多不同类型的机器人,这一能力被称为跨具身。问题是,一个深度神经网络是否可以通过在足够多的不同机器人的数据上进行训练来学会“驾驶”它们所有——甚至是外观、物理属性和功能非常不同的机器人。如果是这样,这种方法有可能释放机器人学习的大型数据集的潜力。
这个项目的规模非常大,因为必须如此。RT-X数据集目前包含了近百万次对22种不同类型机器人的试验,包括市场上许多常用的机器人臂。这个数据集中的机器人执行各种各样的行为,包括拾取和放置物体、装配以及像电缆布线这样的专门任务。总共有约500种不同的技能和与成千上万种不同对象的交互。这是目前存在的最大的开源实际机器人行为数据集。
令人惊讶的是,我们发现我们的多机器人数据可以使用相对简单的机器学习方法,前提是我们遵循使用大型神经网络模型和大型数据集的方法。利用与当前LLMs(如ChatGPT)中使用的相同类型的模型,我们能够训练机器人控制算法,而不需要任何用于跨具身的特殊功能。就像一个人可以使用同一大脑驾驶汽车或骑自行车一样,模型在RT-X数据集上训练后可以简单地识别它从机器人自己的摄像头观察中控制的是哪种机器人。如果机器人的摄像头看到的是一个UR10工业臂,模型会发送适用于UR10的命令。如果模型看到的是一个低成本的WidowX爱好者臂,模型会相应地移动它。
为了测试我们模型的能力,参与RT-X合作的五个实验室中的每个实验室都在与他们为自己的机器人独立开发的最佳控制系统进行了头对头比较。每个实验室的测试涉及其用于自己研究的任务,包括拾取和移动物体、打开门以及通过夹子引导电缆。令人吃惊的是,单一的统一模型在平均水平上比每个实验室自己的最佳方法提供了更好的性能,成功完成任务的频率平均提高了约50%。
虽然这个结果可能看起来令人惊讶,但我们发现RT-X控制器可以利用其他机器人的多样经验来提高在不同环境中的稳健性。即使在同一个实验室内,每当机器人尝试一个任务时,它都会发现自己处于略微不同的情境中,因此借鉴其他机器人在其他情境中的经验有助于RT-X控制器处理自然变异和边缘情况。以下是这些任务范围的几个例子:



构建能够进行推理的机器人
在成功将许多不同类型的机器人数据结合起来的基础上,我们接下来试图研究如何将这些数据纳入具有更深度推理能力的系统中。仅从机器人数据中学习复杂的语义推理是困难的。虽然机器人数据可以提供各种物理能力,但更复杂的任务,比如“将苹果从罐头移动到橙子”,还需要理解图像中对象之间的语义关系、基本常识和其他与机器人的物理能力直接无关的符号知识。
因此,我们决定将另一个庞大的数据源添加到混合中:互联网规模的图像和文本数据。我们使用了一种现有的大型视觉语言模型,该模型已经熟练掌握了许多需要理解自然语言和图像之间关系的任务。这个模型类似于公开可用的模型,如ChatGPT或Bard。这些模型经过训练,可以在包含图像的提示中输出文本,使它们能够解决视觉问答、字幕和其他开放式视觉理解任务等问题。我们发现这样的模型可以通过训练它们在以机器人命令为框架的提示中也输出机器人动作,从而简单地适应机器人控制。我们将这种方法应用于RT-X合作的机器人数据。
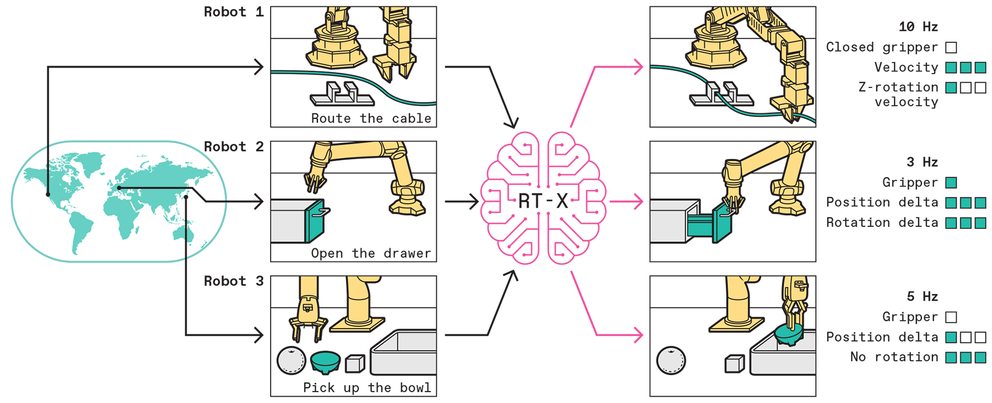
RT-X模型使用特定机械臂执行不同任务的图像或文本描述,输出一系列离散的动作,使任何机械臂都能执行这些任务。通过从世界各地的机器人实验室收集许多机器人执行许多任务的数据,我们正在构建一个开源数据集,可用于教导机器人成为通用工具。CHRIS PHILPOT
为了评估互联网获取的智能和多机器人数据的结合,我们使用了谷歌的移动操纵机器人进行了RT-X模型的测试。我们进行了最具挑战性的泛化基准测试。机器人必须识别物体并成功操纵它们,同时还必须通过进行逻辑推理来响应复杂的文本命令,这需要整合来自文本和图像的信息。后者是使人类成为出色通才的因素之一。我们能否给我们的机器人至少一些这样的能力的提示呢?
我们进行了两组评估。首先,我们使用了一个模型,该模型排除了所有与谷歌机器人无关的广义多机器人RT-X数据。实际上,谷歌机器人特定的数据集是RT-X数据集的最大部分,包含超过10万个演示,因此关于其他所有多机器人数据是否在这种情况下真的有帮助的问题仍然很有争议。然后我们尝试了包含所有这些多机器人数据的情况。
在其中一个最困难的评估场景中,谷歌机器人需要完成一个涉及空间关系推理的任务(“将苹果移动到罐头和橙子之间”);在另一个任务中,它必须解决基本的数学问题(“将一个物体放在解答‘2+3’的纸上”)。这些挑战旨在测试推理和得出结论的关键能力。
在这种情况下,推理能力(如“在…之间”和“在…之上”的含义)来自于训练视觉语言模型时包含的Web规模数据,而将推理输出与机器人行为(实际上移动机器人手臂的命令)相关联的能力来自于在RT-X的跨具身机器人数据上的训练。下面的视频中显示了我们要求机器人执行未包含在其训练数据中的任务的评估示例。
虽然对于人类来说这些任务很基础,但对于通用机器人来说却是一个重大挑战。如果没有清晰展示诸如“在…之间”、“附近”和“在…之上”等概念的机器人演示数据,即使是在训练数据来自许多不同机器人的系统也无法弄清楚这些命令的含义。通过整合视觉语言模型的Web规模知识,我们的完整系统能够解决这样的任务,从互联网规模的训练中得出语义概念(在这种情况下是空间关系),并从多机器人RT-X数据中得出物理行为(拾取和移动物体)。令我们惊讶的是,我们发现包含多机器人数据使谷歌机器人在推广到此类任务的能力提高了三倍。这一结果表明,多机器人RT-X数据不仅对获取各种物理技能有用,还可以帮助更好地将这些技能与视觉语言模型中的语义和符号知识连接起来。这些连接赋予机器人一定的常识,有朝一日可能使机器人能够理解复杂而微妙的用户命令,例如“给我拿早餐”,并执行使其发生的动作。
RT-X的下一步计划
RT-X项目展示了当机器人学习社区共同行动时可能发生的情况。由于这一跨机构的努力,我们能够组建一个多样化的机器人数据集,并进行全面的多机器人评估,这在任何单一机构都是不可能的。由于机器人学社区不能依赖于在互联网上获取训练数据,我们需要自己创建这些数据。我们希望更多的研究人员将他们的数据贡献到RT-X数据库,并加入这一合作努力。我们还希望提供工具、模型和基础设施来支持跨具身研究。我们计划超越在实验室之间共享数据,并希望RT-X将发展成一个协作努力,以开发数据标准、可重用模型以及新的技术和算法。
我们早期的结果暗示了大规模跨具身机器人模型如何改变该领域。就像大型语言模型已经掌握了各种基于语言的任务一样,在未来,我们可能会使用相同的基础模型作为许多现实世界机器人任务的基础。也许通过微调或甚至提示预训练的基础模型,可以启用新的机器人技能。类似于您可以提示ChatGPT讲述一个故事而无需先在该特定故事上进行训练,您可以要求机器人在蛋糕上写“生日快乐”,而无需告诉它如何使用裱花袋或手写文本是什么样子。当然,这些模型要具备这种通用能力还需要更多的研究,因为我们的实验主要集中在单臂、双指夹爪进行简单操纵任务的情况下。
随着更多的实验室参与跨具身研究,我们希望进一步推动单一神经网络控制多个机器人的可能性的前沿。这些进展可能包括添加从生成的环境中获取的多样化的模拟数据,处理具有不同数量臂或手指的机器人,使用不同的传感器套件(如深度摄像头和触觉感知),甚至结合操纵和移动行为。RT-X已经为这样的工作打开了大门,但最激动人心的技术发展仍在前方。
这只是个开始。我们希望通过这一第一步,我们共同创造机器人技术的未来:通用机器人大脑可以驱动任何机器人,从全球所有机器人共享的数据中受益。

权益福利:
1、AI 行业、生态和政策等前沿资讯解析;
2、最新 AI 技术包括大模型的技术前沿、工程实践和应用落地交流(社群邀请人数已达上限,可先加小编微信:15937102830)

源于硅谷、扎根中国,上海殷泊信息科技有限公司 (MoPaaS) 是中国领先的人工智能(AI)平台和服务提供商,为用户的数字转型、智能升级和融合创新直接赋能。针对中国AI应用和工程市场的需求,基于自主的智能云平台专利技术,MoPaaS 在业界率先推出新一代开放的AI平台为加速客户AI技术创新和应用落地提供高效的算力优化和规模化AI模型开发、部署和运维 (ModelOps) 能力和服务;特别是针对企业应用场景,提供包括大模型迁移适配、提示工程以及部署推理的端到端 LLMOps方案。MoPaaS AI平台已经服务在工业制造、能源交通、互联网、医疗卫生、金融技术、教学科研、政府等行业超过300家国内外满意的客户的AI技术研发、人才培养和应用落地工程需求。MoPaaS致力打造全方位开放的AI技术和应用生态。MoPaaS 被Forrester评为中国企业级云平台市场的卓越表现者 (Strong Performer)。

END
▼ 往期精选 ▼
4、为什么像 ChatGPT 和 Google Bard 这样的LLM数学不好
▼点击下方“阅读原文”!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢