
点击下方卡片,关注「AI视界引擎」公众号

近年来,在开发基础模型(Foundation Models,FMs)方面取得了显著的进展。与自然语言处理中的大型语言模型(Large Language Models,LLMs)同时,视觉语言基础模型(Vision-Language FMs)的代表,如CLIP及其变体,在需要同时理解视觉和文本模态的任务中获得了显著的声誉,并成为主流。
得益于大规模的网页爬取数据,这些模型在需要全局对齐的任务上(例如分类和检索)实现了显著的性能提升。然而,当面临需要对区域或像素 Level 进行更复杂理解的任务时,它们的性能往往相对较差。这种差异源于CLP(对比学习)的学习范式的主要关注点,即强调捕捉文本和图像之间的整体关系,而不是深入研究细粒度的区域特定或像素 Level 细节。
为了克服这个局限性,已经投入了大量的努力来增强CLIP的训练粒度。这些努力主要涉及将CLIP定制为特定任务,例如目标检测和分割。然而,由于高质量图像数据集的稀缺性,现有的CLIP训练方法往往无法充分利用这些数据集的优势。此外,这些方法引入了由于挖掘过程的隐式性质而产生的标注噪声。
在本文中,作者探索将细粒度定位能力集成到当前CLIP模型中。主要的挑战来自三个方面:缺乏高质量、细粒度标注的数据集,以及可以包含不同 Level 监督的有效训练框架,以及考虑到任务差异,处理各种视觉任务的低成本适应范式。作者在数据和模型两个方面解决了上述挑战。
多粒度数据集生成。通过利用来自机器学习社区的广泛模型,作者能够开发出一种自动标注工作流程,能够在不同粒度 Level 上生成详细的标注。具体来说,作者使用高性能分类,检测和分割模型作为标注器,自动生成图像、区域和像素 Level 的标注。此外,作者评估生成的标注质量,并开发一种自动过滤方案,以精心选择和集成最终的标注数据。作者标注了六个公共数据集,并获得了UMG-41M,其中包含大约4.1亿张图像,3.89亿个区域,涵盖11,741个类别。
多任务预训练范式。因此,作者提出了一种统一的、多粒度学习框架,名为UMG-CLIP,以赋予CLIP局部感知能力。具体来说,除了传统的图像-文本匹配外,UMG-CLIP从图像中提取区域并执行区域-文本匹配,以增强其对细粒度的明确理解能力。此外,UMG-CLIP将这两个 Level 的标签监督集成起来,以提高其类别区分能力。为确保效率,尤其是在使用高分辨率图像进行细粒度预训练时,UMG-CLIP采用了一种基于聚类的策略,并在预训练过程中减少了75%的视觉标记。
高效下游适应。由于UMG-CLIP已经通过在不同粒度任务上进行预训练而获得了通用能力,因此其下游适应的负担可以显著减轻。因此,作者使用参数高效的调优(PET)技术将UMG-CLIP适应到不同的任务中,其中UMG-CLIP的预训练 Backbone 被冻结,从而保留了其现有的知识,避免了需要大量调整资源的繁琐过程。
此外,UMG-CLIP还将可学习的轻量级卷积pass模块集成到其 Backbone 中,以及与任务相关的解码器,以适应不同的下游任务。
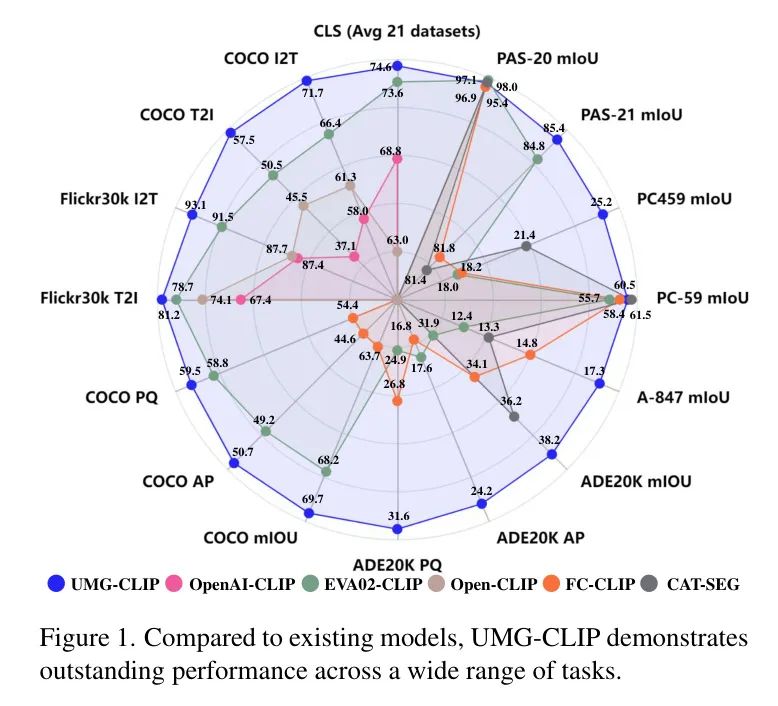
将上述成分结合在一起,产生了一个强大的视觉框架。如图1所示,与现有的视觉语言模型相比,UMG-CLIP在具有不同粒度 Level 的多个下游任务上表现出卓越的性能。值得注意的是,它在一系列基准测试中实现了最先进(SOTA)的结果,涵盖了开放世界识别、检索、语义分割和panoptic分割。
对于视觉理解,近年来趋势是从紧密的设置转向更具挑战性的、开放的世界的理解。其中,CLIP 和ALIGN是先驱之作,它们通过使用大量的图像-文本对进行训练。接下来,FLIP通过引入Mask加速了训练过程。BLIP 将理解和生成任务集成在一起,使模型具有描述能力。值得注意的是,EVA-Series调整了模型结构,增加了训练数据和模型大小,并在不同的视觉任务上实现了一系列最先进性能。还有考虑为CLIP引入局部感知能力的工作。
DetCLIP引入了一个概念词典,用其描述丰富了概念。CoDet在图像之间发现共同出现的目标,并将其与共享概念对齐。MaskCLIP 向冻结的CLIP添加了一个Mask生成器,并计算Mask与文本嵌入之间的相似性,以完成零样本任务。
这些数据集从小规模,如SBU ,Flickr30k ,和CC3M,到较大的,如CC12M ,LAION400M,COYO-700M,LAION5B。然而,这些数据集都受到全局图像-文本对的限制。
最近,SA-1B提供了局部区域的Mask标注,但缺乏语义信息。虽然有关于描述局部区域的工作,如Visual Genome和RefCOCO,但这些数据集在大小上仍然相对较小。GLIP试图构建词-区域对齐数据,但其词数据是从检测数据集中提取的,并使用原始图像标题作为名词短语,这在丰富性和质量方面存在一定的缺陷。最近的工作All-Seeing 开发了一种自动标注过程,为区域提供详细的文本标注,但其标注粒度仅限于区域 Level 。
在这个部分,作者将详细介绍自动化标注工作流程,以及标记的大规模细粒度数据集UMG-41M。
数据标注工作流程。如图2所示呈现了一个自动化标注工作流程,该流程便于全面标注,涵盖图像级、区域级和像素级视角:
图像级。对于全局图像,使用高性能标签模型RAM 来标注其标签。同样,使用BLIP2 和Shikra来提供相应的标题。此外,作者使用EVA-CLIP为每个标题分配一个分数,该分数作为过滤高质量标题的指示器。
区域级。对于区域级标注,首先利用两个ViTDet模型,分别在大Detection和V3Det 上进行训练,来生成候选边界框及其对应的类别标签。然后,过滤掉置信度低于0.3的候选项,并应用非极大值抑制(NMS)来合并剩余的框。基于生成的框,作者使用GPT4ROI 和Shikra模型来标注相应的标题。
像素级。对于像素级标注,使用两种技术:Mask DINO用于生成背景Mask,SAM 用于提取前景Mask。SAM使用的边界框提示是从作者的区域级标注派生而来的。为了确保标注质量,作者使用一些方法来增强标注,如在SAM中使用区域级标注派生的提示。
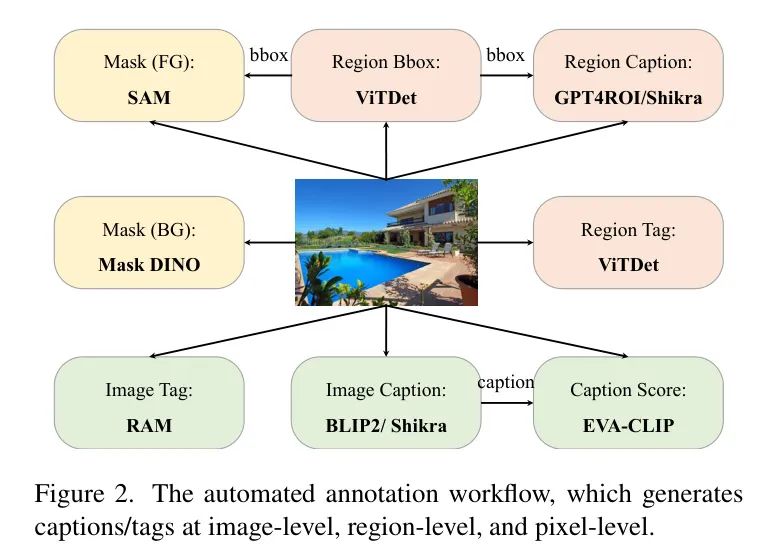
为了确保生成的前景Mask的质量,作者还需要评估它们在边界框扰动下的稳定性,并随后消除稳定性较低的Mask,更详细的细节请参见附录。
数据集细节。从六个公共数据集中标注了总共41.41亿张图像,这些数据集包括CC3M ,CC12M,SBU,VG,YFCC15M和IN21K。作者提出的数据集名为UMG-41M,它涵盖了不同粒度的标注。

如表1所示,UMG-41M包含389.13亿个区域,每个区域对应于11,741个不同的类别。每个区域至少与4个标注相关联(在去重后),以确保文本描述的多样性。作者还为每张图像提供了全局标签,以及7种以上从不同视角描述图像的不同标注。这些标注用于预训练,如第4.1节所述。
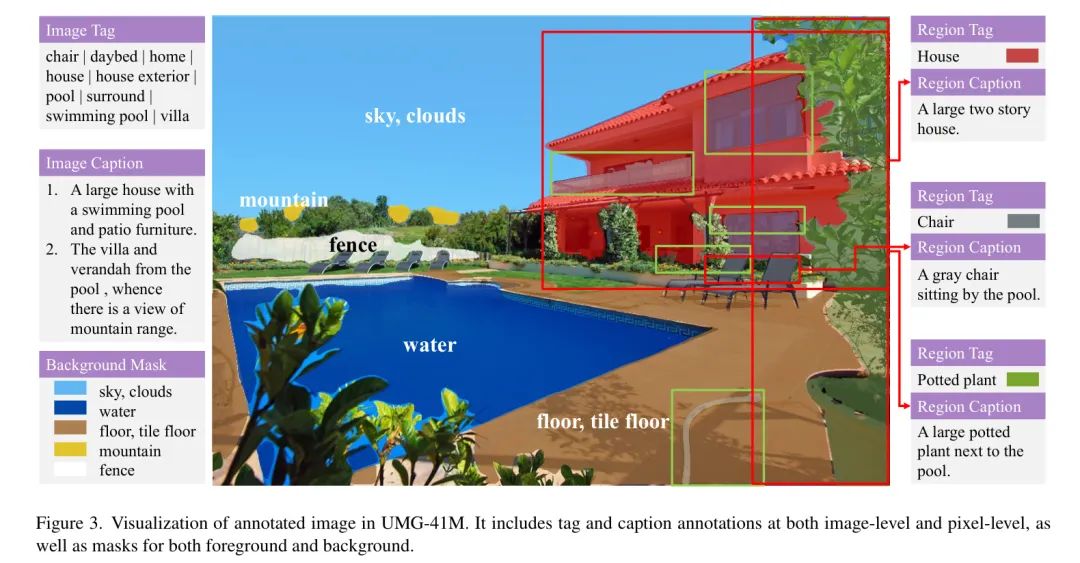
此外,还为BigDet提供了像素级标注,结果是BigDet Panoptic数据集,包含3.59亿张图像,48.60亿个区域和653个类别。作者利用BigDet Panoptic进行密集级下游适应,更多信息请参见第4.2节。图3提供了标注数据的示例,更多信息请参见附录。
在这个部分,作者将介绍多粒度视觉通用模型的预训练方法,以及将该模型有效地适应各种下游任务所采用的技术。
正如第3节所述,UMG-41M数据集包括不同粒度的标注,包括图像 Level 的标签和标题,以及区域 Level 的边界框,标签和标题。基于这些细粒度的标注,作者训练了一个具有通用能力的强健基础模型,称为UMG-CLIP。
框架概述 UMG-CLIP的整体框架如图4所示。
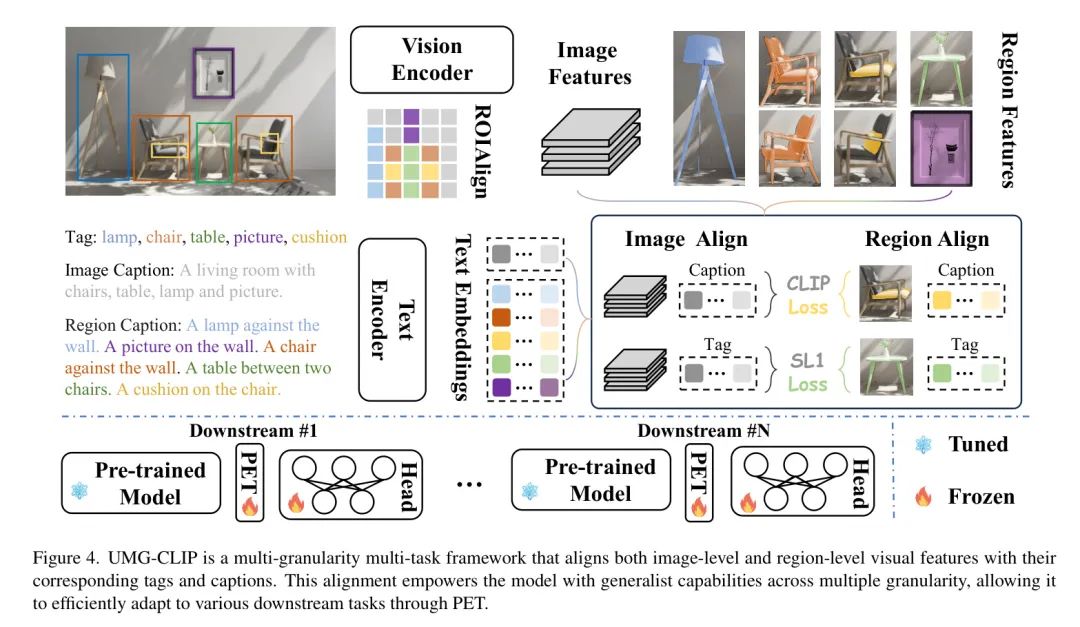
具体来说,对于输入图像批次,将它发送到图像编码器,以获取视觉嵌入序列,其中和分别表示类别标记和视觉标记。,和分别表示批处理大小、视觉标记数量和维度。
请注意,使用EVA-CLIP 预训练权重来初始化和文本编码器。然后,将和边界框标注(其中是输入图像中的区域总数),发送到RoIAlign层,并生成区域嵌入。上述过程可以表示为:
接下来,将图像 Level 的标签和,以及区域 Level 的标签和,通过文本编码器进行传递,以获得它们的相应嵌入。
其中和,最后,总损失通过考虑多粒度监督的贡献进行计算。
在此处, 表示线性映射后的嵌入。图像 Level 损失和区域 Level 损失的贡献由 和 分别控制,且作者分别将它们设置为 。
考虑到不同的数据可能具有相同的或重叠的标签,使用Smooth L1 损失 对 进行优化,而对于 ,采用视觉文本对比损失。
减少预训练内存。 更细粒度的预训练需要比图像 Level 更高的预训练分辨率以确保预训练质量,而增加分辨率通常会导致更大的内存负担。为了处理这个问题,UMG-CLIP采用了一种基于聚类的策略,在预训练期间减少了75%的视觉标记。与FLIP中随机屏蔽视觉标记不同,作者认为UMG-CLIP需要保留区域级学习所需的详细空间和语义信息。
因此,受到AliRus的启发,将冗余标记聚类为代表性标记,并通过后续的 Transformer 层仅传递这些代表性标记。在 Transformer 结束时,作者将代表性标记展开以恢复区域级学习的原始分辨率。
考虑到UMG-CLIP已经预训练了具有各种粒度任务通用的能力,将其适应不同的下游任务可以显著减轻负担。因此,作者采用了参数高效的调优(PET)技术来实现这种高效的下游适应。
具体来说,将UMG-CLIP Backbone 的预训练参数冻结以保留其现有的知识,同时在其适应过程中引入可学习的PET模块和任务特定的解码器,以增强其对具体下游任务的理解。PET模块并行地集成在UMG-CLIP的原始多头自注意力(MHSA)和MLP层中,它们的计算可以表示如下公式:
其中s是控制PET模块贡献的超参数,经验上设置为0.1。X是MHSA层的输入。作者使用具有三个卷积层(,,)和两个GELU激活的Convpass模块(用于和),以适应下游任务的粒度要求。
为了适应不同的下游任务,作者开发了两个不同的适应模型,更多信息请参见第5.1节。
预训练设置。作者遵循EVA-CLIP的训练配置,在预训练阶段保持其大部分设置不变。具体来说,使用LAMB优化器,其中,,以及的重量衰减。
视觉编码器的学习率设置为UMG-CLIP-B/16为,其他模型为。文本编码器的学习率设置为UMG-CLIP-B/16为,其他模型为。所有模型的输入分辨率都设置为,预训练周期设置为UMG-CLIP-E/14为6,其他模型为10。为确保训练过程的平滑,作者按照 Warm up 和 learning rate 衰减时间表进行训练。此外,还利用DeepSpeed优化库来节省内存并加速训练过程。
适应设置。根据任务的粒度采用两种不同的策略进行下游适应。对于全局 Level 的识别任务,如分类和检索,使用PET在UMG-CLIP上进行适应,利用UMG-41M数据集的监督。使用LAMB优化器将学习率设置为。输入大小保持不变。对于UMG-CLIP-E/14和所有其他模型的适应周期分别设置为2和5。对于密集 Level 的识别任务,如panoptic分割和语义分割,使用两个不同的数据集:COCO Panoptic和标注BigDet Panoptic进行适应。采用FC-CLIP中使用的适应设置,唯一的区别在于输入分辨率和适应周期。
具体来说,所有适应的学习率保持一致,设置为,并使用AdamW优化器。对于COCO Panoptic,进行适应50个周期,使用的输入分辨率。在处理BigDet Panoptic时,选择一个减少的输入分辨率,并适应10个周期。
为了最小化计算成本并保持满意的性能,在处理BigDet Panoptic时,选择适应10个周期。
零样本分类。 表2展示了在21个不同基准上的零样本分类结果。UMG-CLIP-L/14的平均Top-1准确率为72.1%,比OpenAI CLIP-L/14高0.3%,比EVA-02-CLIP-L/14高0.5%。UMG-CLIP-E/14进一步提高了平均性能,达到74.6%,比EVA-02-CLIP-E/14高1.0%。这些结果表明,尽管UMG-CLIP对细粒度分类给予了更多的关注,但在全局水平基准上,它仍然具有高度竞争力。
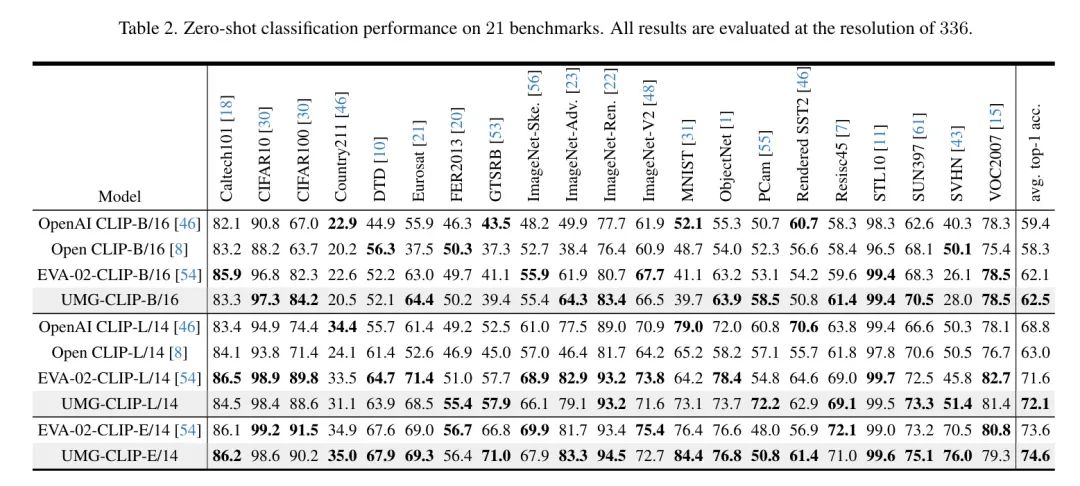
零样本检索。 表3在COCO和Flickr30K数据集上展示了零样本检索结果,突出了UMG-CLIP相对于其他方法的优势。
值得注意的是,作者的方法与EVA-02-CLIP-E/14相比,在COCO I2T和T2I上的R@1改进分别为5.3%和7.0%。这种显著的改进可以归因于UMG-41M中文本对的质量更高且多样性更大,这增强了作者的UMG-CLIP对图像-文本理解的 capability。
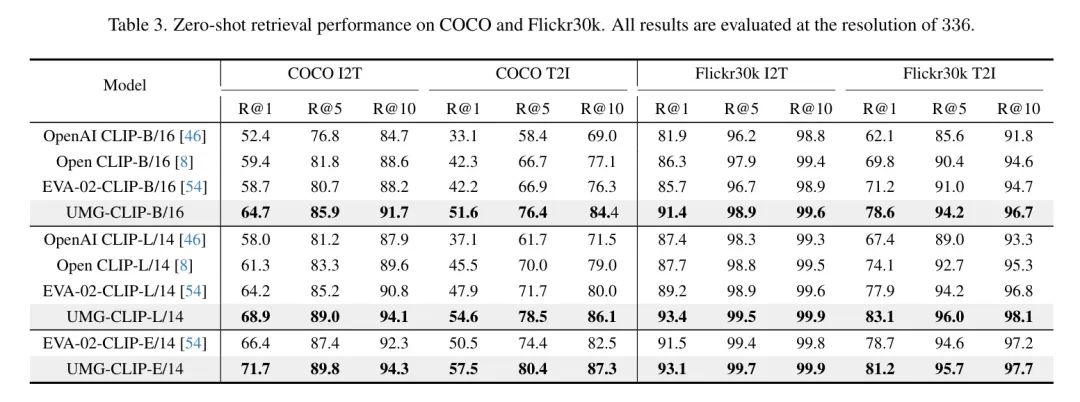
开放词汇panoptic分割。 表4检查了panoptic分割结果。遵循FC-CLIP,首先使用COCO Panoptic数据集适应UMG-CLIP,然后评估其性能在COCO和ADE20K上的表现。
值得注意的是,UMG-CLIP在_seen_ COCO数据集上达到了与EVA-02-CLIP相当的性能,但在_zero-shot_ ADE20K数据集上显著优于它。这种卓越的零样本性能也一致地保持在语义分割任务中,如表5所示,并在稍后的讨论中进一步阐述。通过利用标注的Bigdet Panoptic数据集进行适应,UMG-CLIP进一步获得了新的state-of-the-art性能。
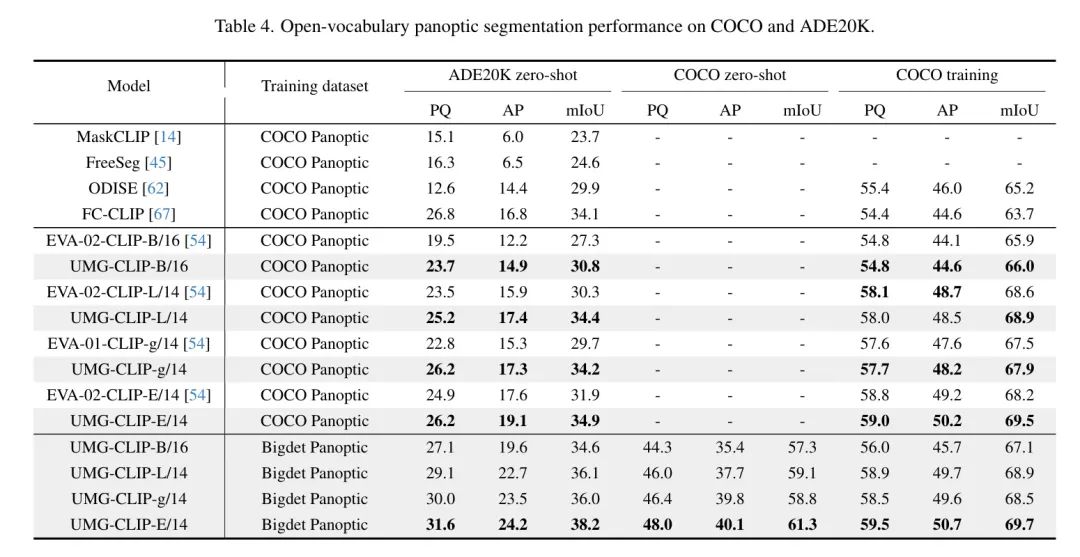
在所有基准上,UMG-CLIP获得了最先进的性能。
开放词汇语义分割。 表5在6个不同的基准上展示了语义分割的结果。值得注意的是,当使用COCO Panoptic进行适应时,UMG-CLIP已经显示出比EVA-02-CLIP和FC-CLIP更好的性能。
此外,当使用Bigdet Panoptic进行适应时,UMG-CLIP的表现进一步显著改进,特别是在具有挑战性的基准,如A-150,A-847和PC-459上。
损失组合。 表6展示了不同多任务学习目标的组合的消融结果。在这个分析中,作者排除了PET模块并利用数据子集加速验证过程,在预训练阶段使用2.7亿数据(减少周期至2),在密集 Level 适应阶段使用20%的COCO,输入分辨率为384×384。
通过结合区域级标题监督,与仅依赖图像级标题监督相比,分割性能显著提高了2.2 mIoU。这种改进伴随着分类(-0.4%)和检索性能(-0.1%)的轻微下降。此外,添加标签监督进一步提高了分割性能,导致mIoU达到50.7,同时保持了令人满意的分类和检索性能。
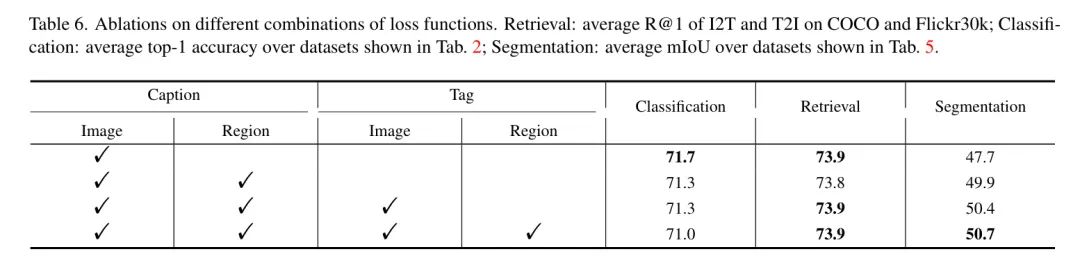
PET和分辨率对于密集 Level 下游。 表7全面分析了将PET模块集成到下游适应中的好处,并得出了鼓舞人心的结果。装备有PET的模型在ADE20K和COCO数据集上始终优于没有PET的模型。
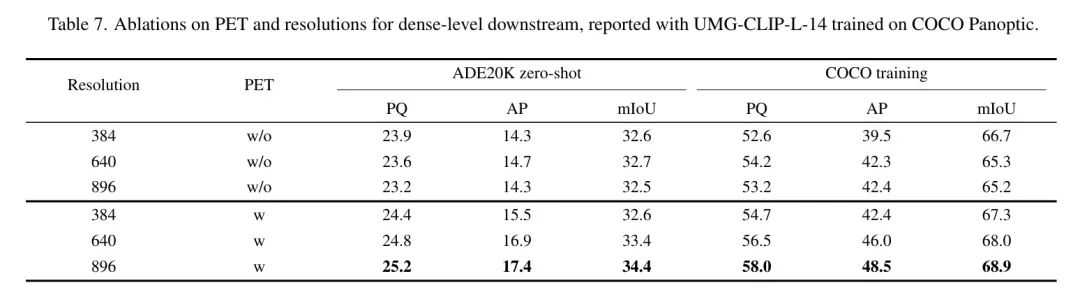
此外,作者注意到基于ViT的模型往往在输入尺寸增加时难以进行泛化。然而,表7中的结果表明,通过实现PET可以缓解这个问题。具体来说,作者观察到模型性能随着输入分辨率的增加而持续提高。这些发现提供了有力的证据,证明了作者采用的PET策略可以有效增强UMG-CLIP的下游适应能力。
这篇论文提出了UMG-CLIP,一种统一的、多粒度的学习框架,为原始CLIP赋予了精确的局部感知能力。UMG-CLIP解决了与数据和模型训练相关的挑战。在数据方面,作者提出了一种自动工作流程,能够通过利用广泛存在于机器学习社区中的模型来生成不同粒度的标注。这使得作者可以获得具有不同粒度的标注,从而增强了训练数据的丰富性。
在模型训练方面提出了一种多任务学习策略,同时在不同维度(标题和标签)上执行区域-文本匹配和传统的图像-文本匹配。这种全面的训练方法使得UMG-CLIP能够有效地学习和利用区域及其对应文本描述之间的关系。配备了PET策略,UMG-CLIP在各种开放世界理解任务上展现出卓越的性能优势。作者希望UMG-CLIP能够成为推进视觉语言基础模型的有价值的选项。
CLIP可以作为推进视觉语言基础模型的有价值的选项,为各种视觉语言任务和应用提供增强的能力。
虽然作者承认数据标注过程可能繁琐,需要使用多个额外的模型,但作者认识到模型训练和数据标注过程之间需要更好的协同作用以有效地扩大数据收集。作者将这视为未来研究的方向。
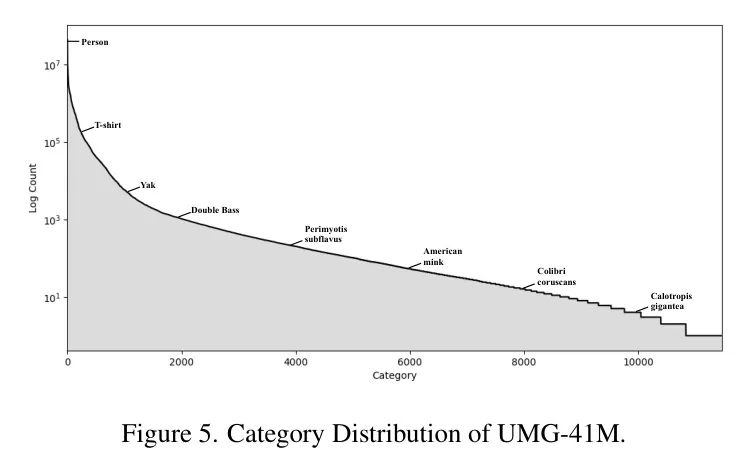
类别分布。 图5显示了UMG-41M的类别分布统计。除了常见的类别(例如人和T恤),UMG-41M还提供了一些更细粒度的类别标注(例如,Colibri coruscans和Calotropis gigantea)。整体类别呈现出长尾分布。
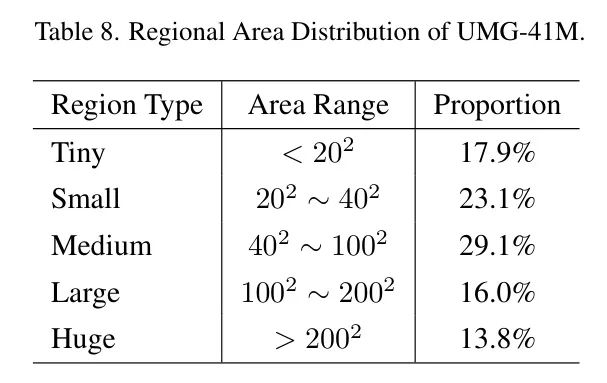
区域面积分布。 表8检查了UMG-41M中的区域面积分布。由于UMG-41M主要分析具有多个物体的复杂场景,观察到约50%的标注区域是小或中型。
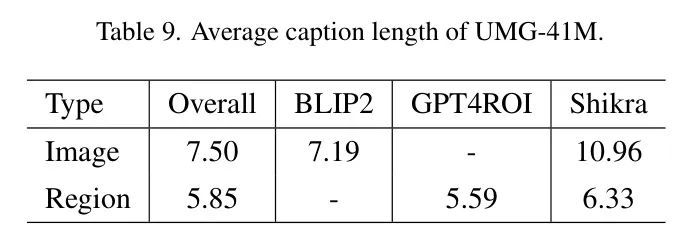
句子长度。 表9检查了UMG-41M的平均句子长度。UMG-41M使用7.50个词来描述一张图像的整体信息,而Shikra提供的文本标注更为具体,为10.96个词。区域描述使用相对较少的文本(5.85个词),因为区域包含的信息少于整个图像。
为了确保生成的前景Mask的质量,作者通过让它们经历边界框抖动来评估它们的稳定性,然后删除稳定性较低的Mask。这个过程涉及将原始边界框沿着对角线略微平移,并使用平移后的边界框生成一个新的Mask。接下来,作者计算新生成Mask和原始Mask之间的像素IoU。稳定性分数然后由多次平移得到的平均像素IoU确定。
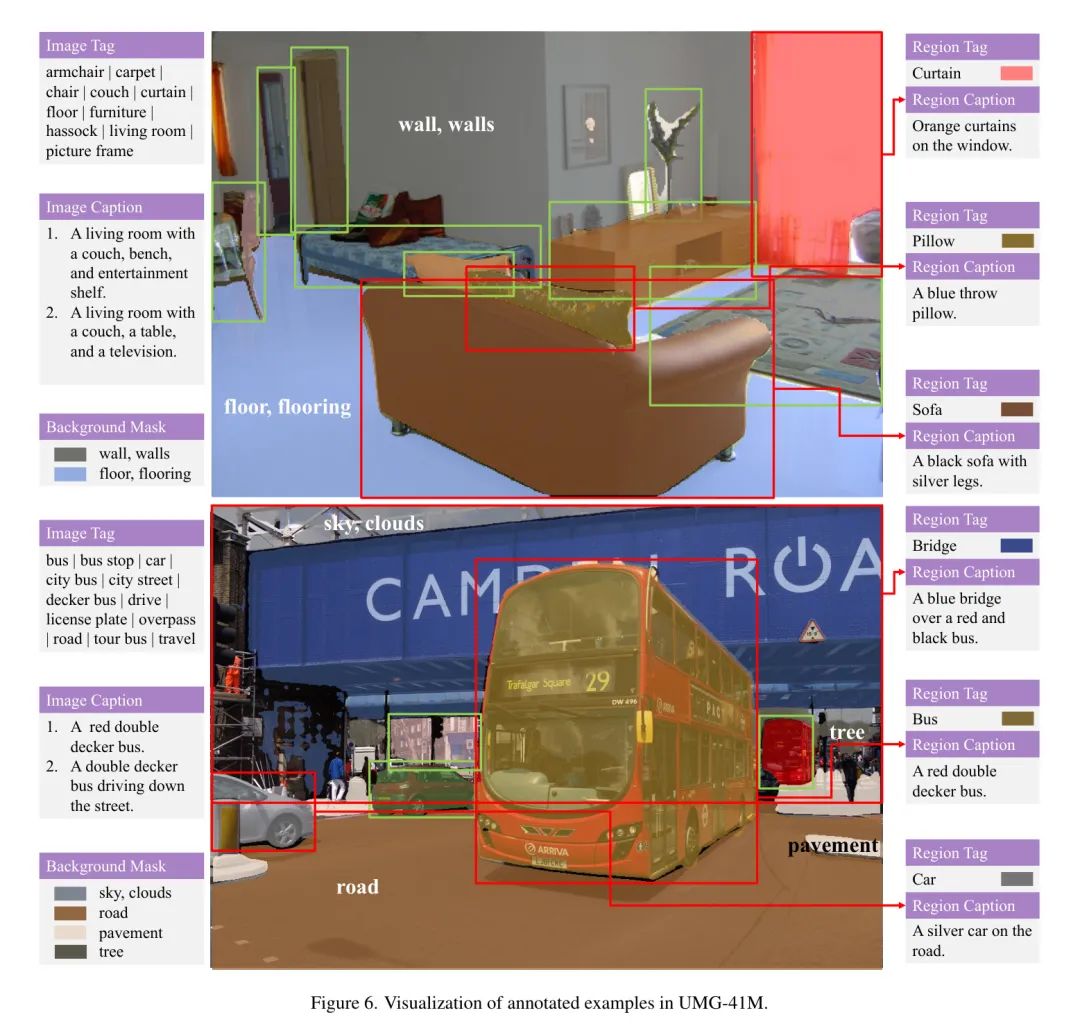
在图6中,作者提供了UMG-41M数据集标注的附加示例,以增强作者对UMG-41M的易懂性。这些插图展示了作者标注质量在不同数据样本上的高质性。
[1].UMG-CLIP: A Unified Multi-Granularity Vision Generalist for Open-World Understanding.

点击上方卡片,关注「AI视界引擎」公众号
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢