
关键词:微型机器人,生物医学工程,强化学习


论文题目:Autonomous 3D positional control of a magnetic microrobot using reinforcement learning 论文期刊:Nature Machine Intelligence 论文地址:https://www.nature.com/articles/s42256-023-00779-2
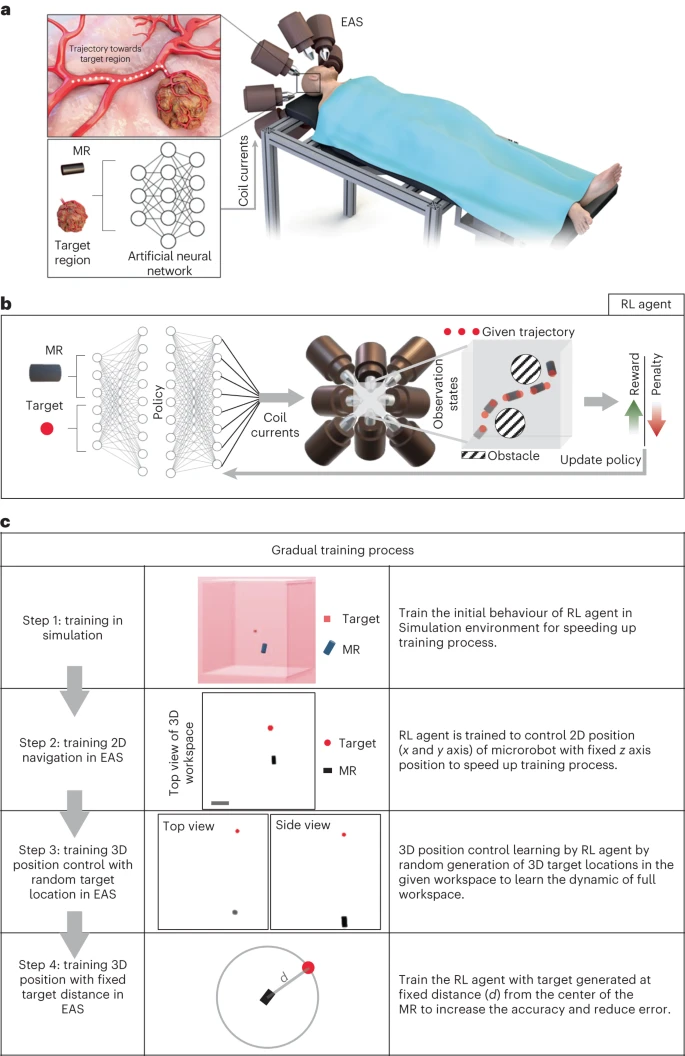
图1 a、基于强化学习的磁性微型机器人导航。该研究开发了一种使用强化学习控制外部激励系统(EAS)在复杂环境中导航微型机器人的自主方法。b、RL 代理通过改变 EAS 线圈电流来精确控制 MR 的位置 PMR。MR 按照策略π(神经网络, RL 代理的一部分)以最少的步数达到目标位置 PT,同时必须保持在定义的工作区感兴趣区域 (ROI, region of interest) 内。c、该研究采用了一个四步的训练过程,以减少代理的训练时间并提高准确性。这有助于初始探索并逐渐增加复杂性,确保准确的导航。
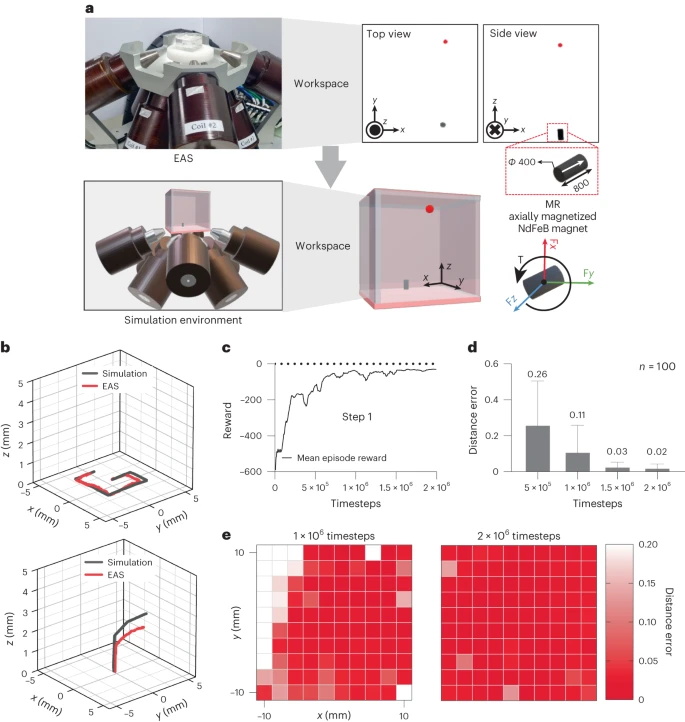
图2 在仿真环境中的评估和训练结果。a、在Unity 3D中开发的一个仿真环境,用于具有八个线圈的EAS和一个磁性微型机器人(一个带有南向北磁化方向的永磁体,如白色箭头所示)浸泡在350cSt硅油中,NdFeB代表钕铁硼材料。b、环境评估。c、训练过程的第一步中强化学习代理模型的训练结果,以随时间步骤变化的平均奖励值表示。d、距离误差(从微型机器人到目标点的距离)随着强化学习代理在不同训练步骤中导航的变化。e、整个工作区的距离误差热力图。
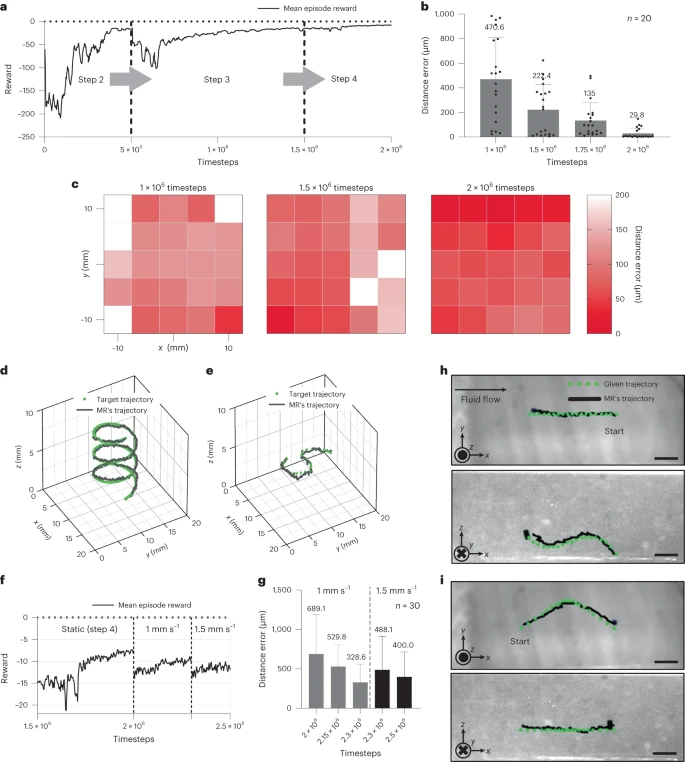
图3 使用EAS(真实环境)重新训练强化学习代理模型。a、使用EAS对RL代理进行了2×106个时间步长的重新训练,并在每个饱和点(步骤2-4)后更改了训练条件。b、距离误差(从微型机器人到目标点的距离)随着强化学习代理在各种训练间隔中导航MR而变化。c、整个工作区域的距离误差热力图。d、给予强化学习代理的螺旋轨迹用于导航微型机器人。该任务涉及到三个轴的变化,验证了代理的性能。e、在xy平面上,将MR沿S形轨迹导航;z轴被固定。这种方法验证了强化学习代理的悬停能力。f、在流体流动条件下对RL代理进行了重新训练,涉及到流体速度分别为1 mm/s和1.5 mm/s 的300,000和200,000个时间步长。g、在动态流体环境中重新训练时,两种不同速度的距离误差。h、对抗流体流向(1 mm/s)进行导航。i、顺着流体流向(1 mm/s)进行导航。
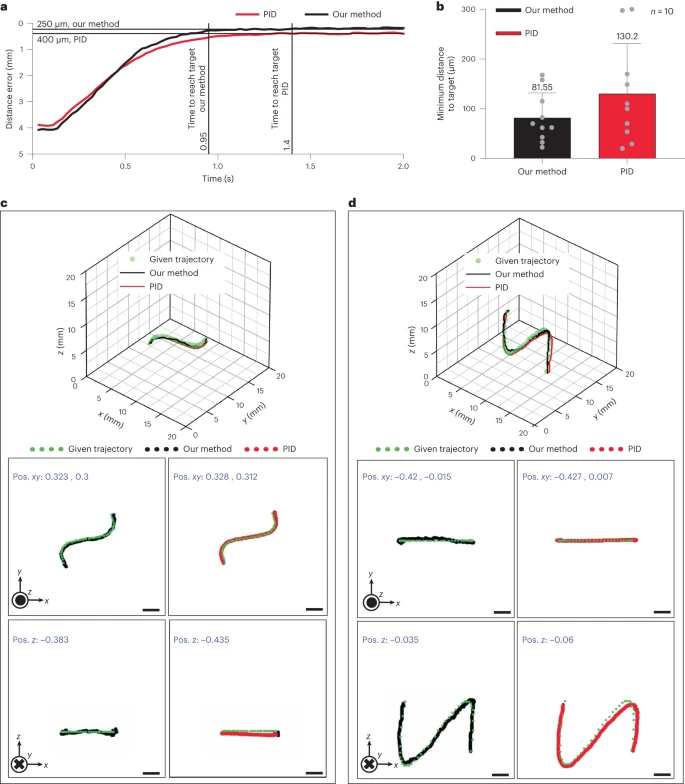
图4 该方法与使用PID控制器进行闭环控制的对比。a、使用这两种方法,通过在当前MR位置创建一个距离目标点4mm的目标点来评估到达目标点所需的时间。b、通过将MR导航到随机目标点并记录与目标点的最小距离,比较了准确性。c、用于比较(固定z轴)的悬停性能的轨迹。d、用于评估(固定y轴)在重力下的性能的轨迹。
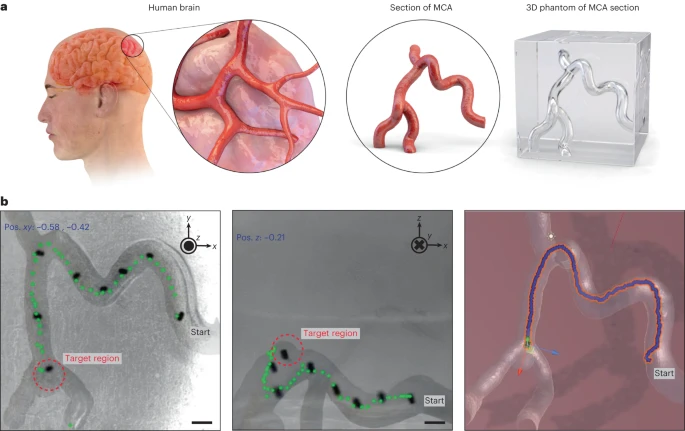
图5 在脑血管仿真模型中导航MR。a、缩小比例的MCA截面的复制品作为脑血管仿真模型,用于评估RL代理作为潜在医疗应用的性能。b、RL代理从指定的起点导航到目标点,即仿真模型内的动脉瘤。
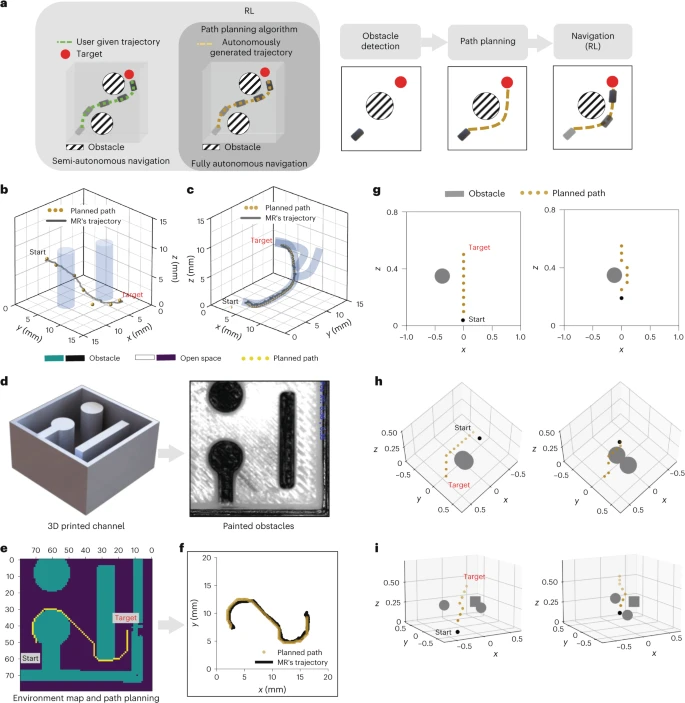
图6 在不同环境下对MR进行完全自主控制。a、RL代理用于生成三维闭环位置控制的最优电流(假设非线性系统和非线性环境)的"大脑"(导航轨迹是由人类选择的)。RL代理与路径规划算法合并,生成通向目标的轨迹;这构成了完全自主控制。b、c、使用A*生成的轨迹的两个不同的MR导航场景:第一个包含虚拟障碍物(两个圆柱体)(b),第二个包含一个三维虚拟通道(c)。d、使用图像处理检测障碍物和开放空间,然后进行环境映射。使用带有障碍物的立方体通道来测试路径规划和导航。e、路径规划的结果。f、在带有物理障碍物的通道中导航。g、h、i、MR导航中遇到单个动态障碍物(g)、两个动态障碍物(h)和两个动态障碍物加一个静态障碍物(i)。
大语言模型与多智能体系统读书会

点击“阅读原文”,报名读书会
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢