
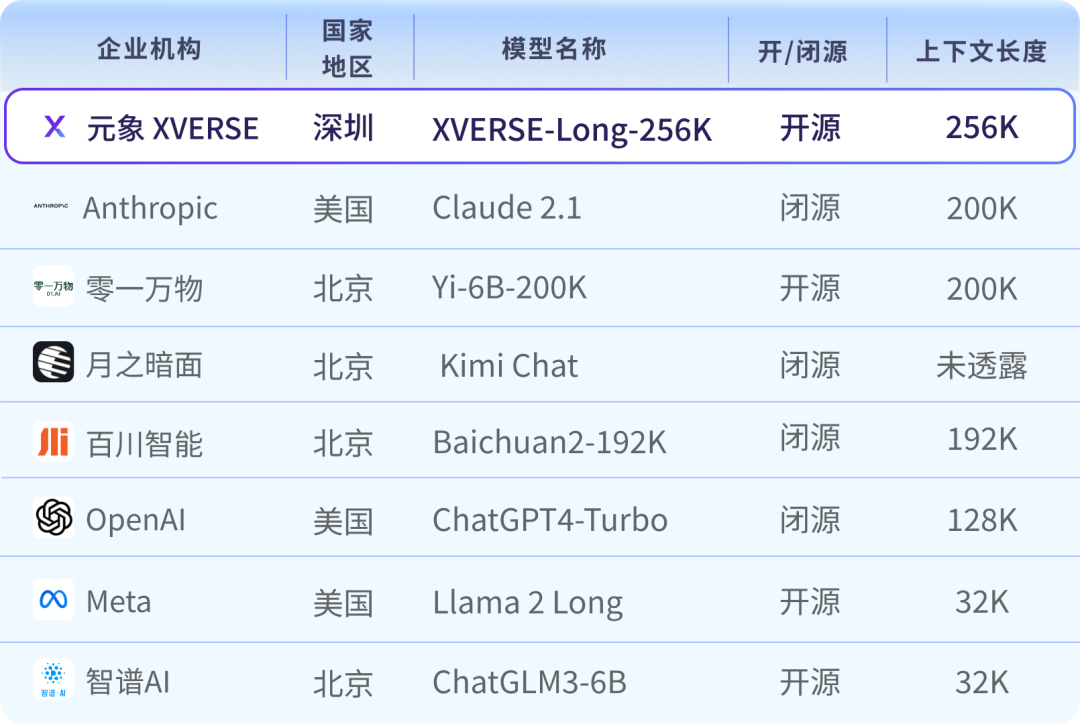
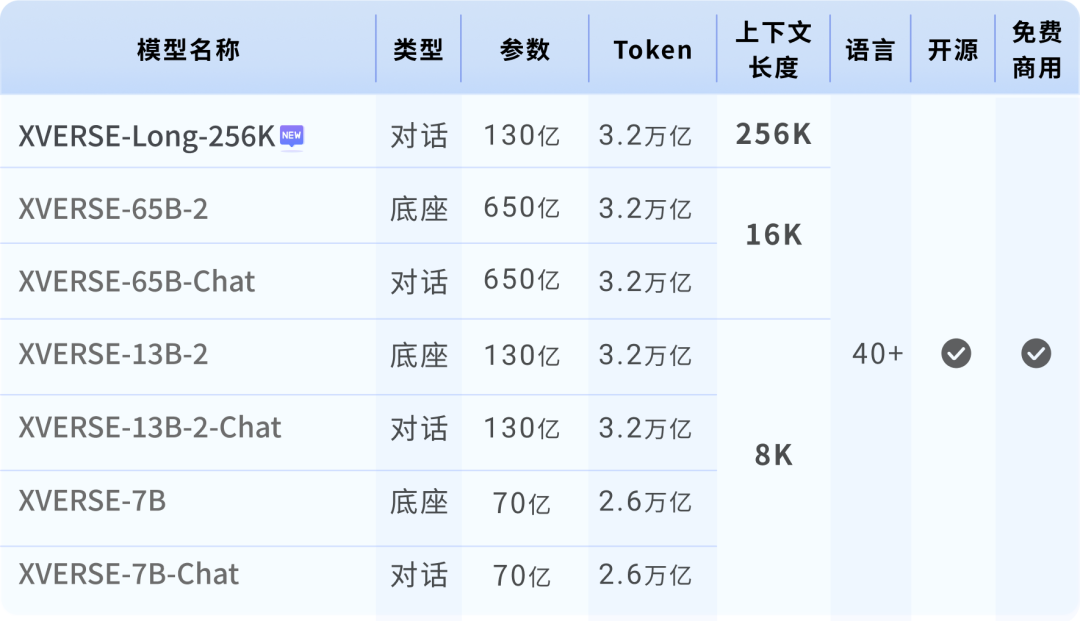
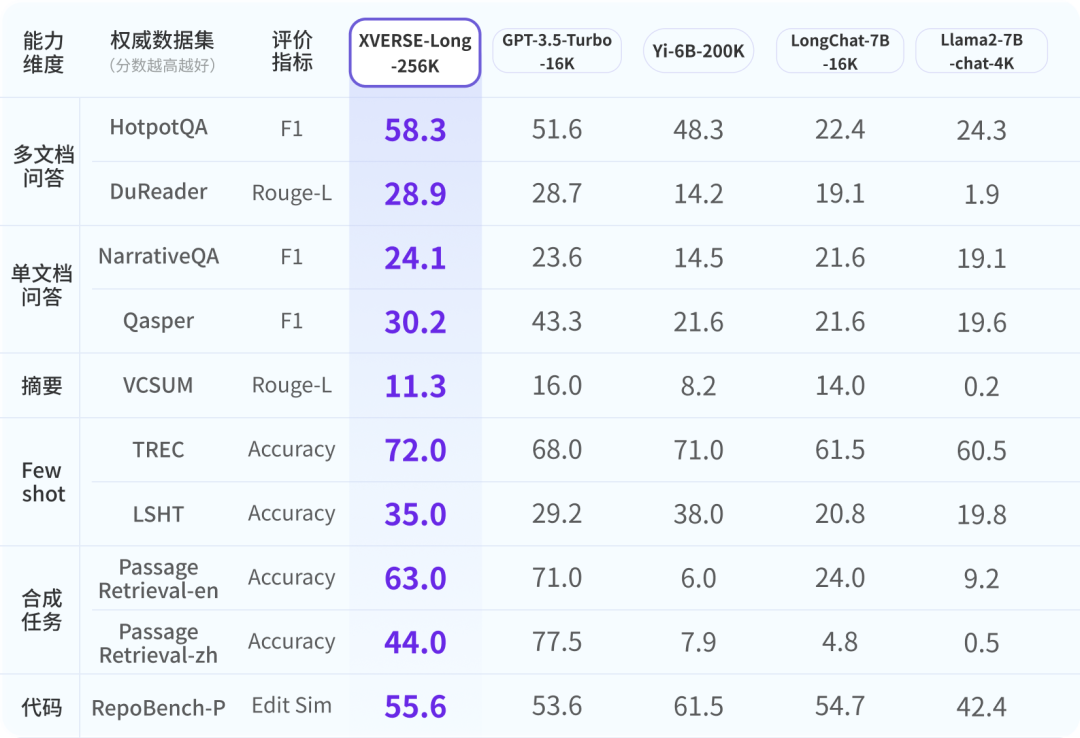
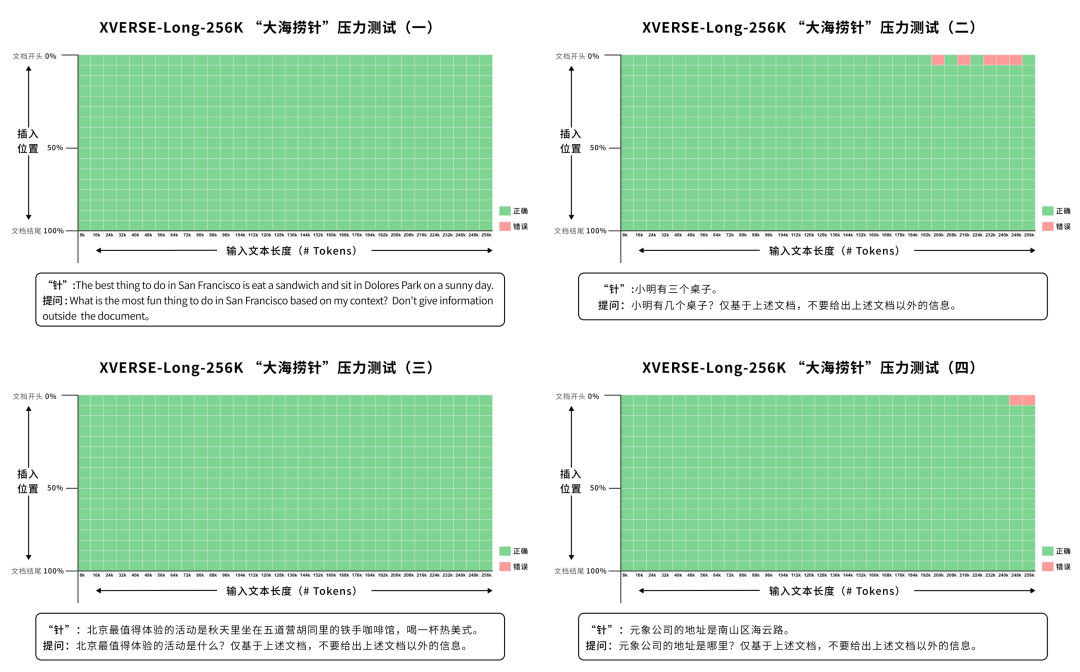
元象发布全球首个上下文窗口长度256K的开源大模型XVERSE-Long-256K,支持输入25万汉字,让大模型应用进入“长文本时代”。该模型全开源,无条件免费商用,且附带手把手训练教程,让海量中小企业、研究者和开发者更早一步实现“大模型自由”。
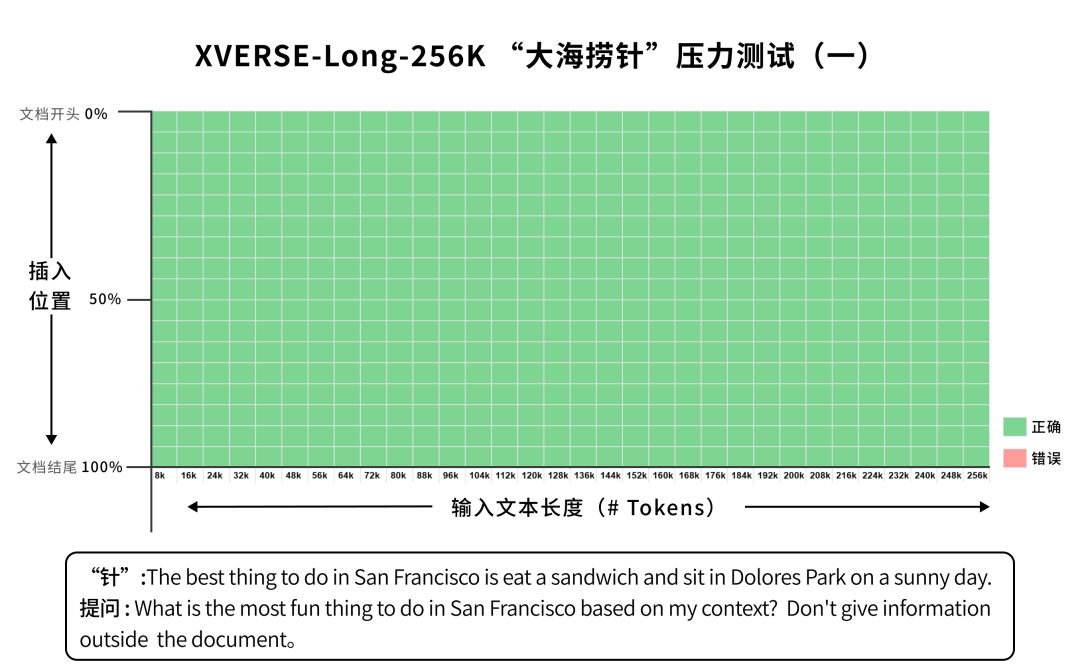
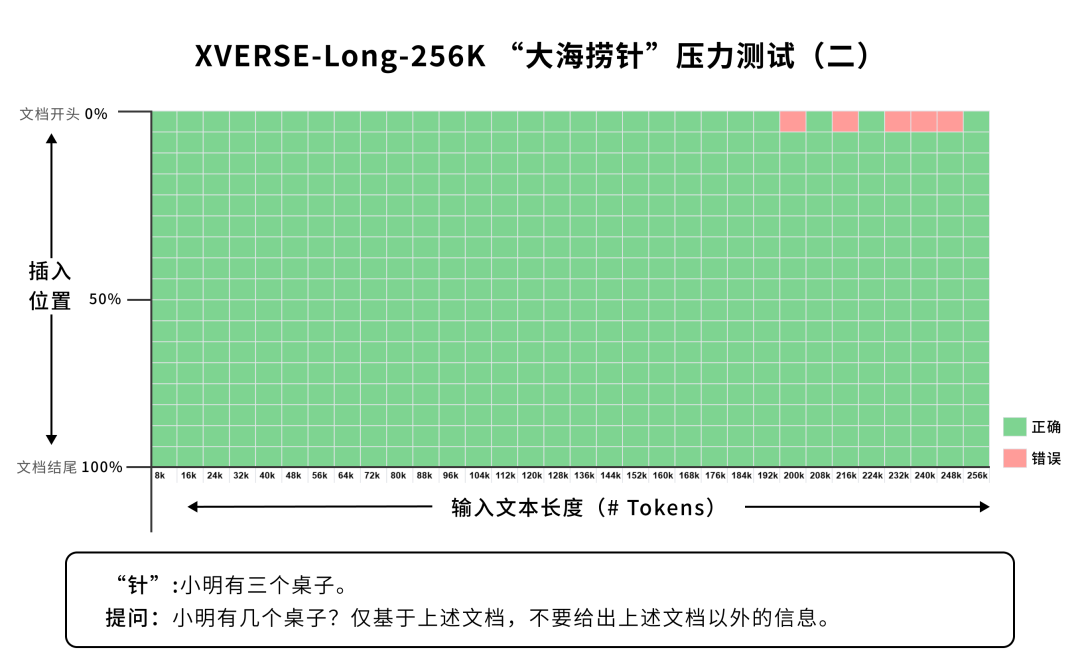
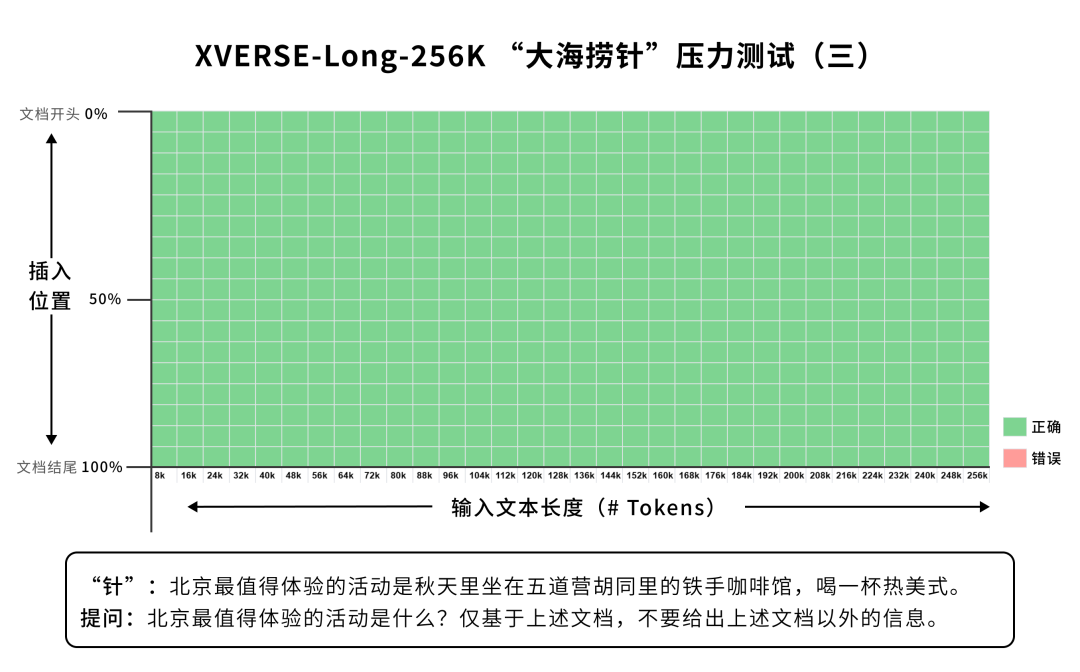
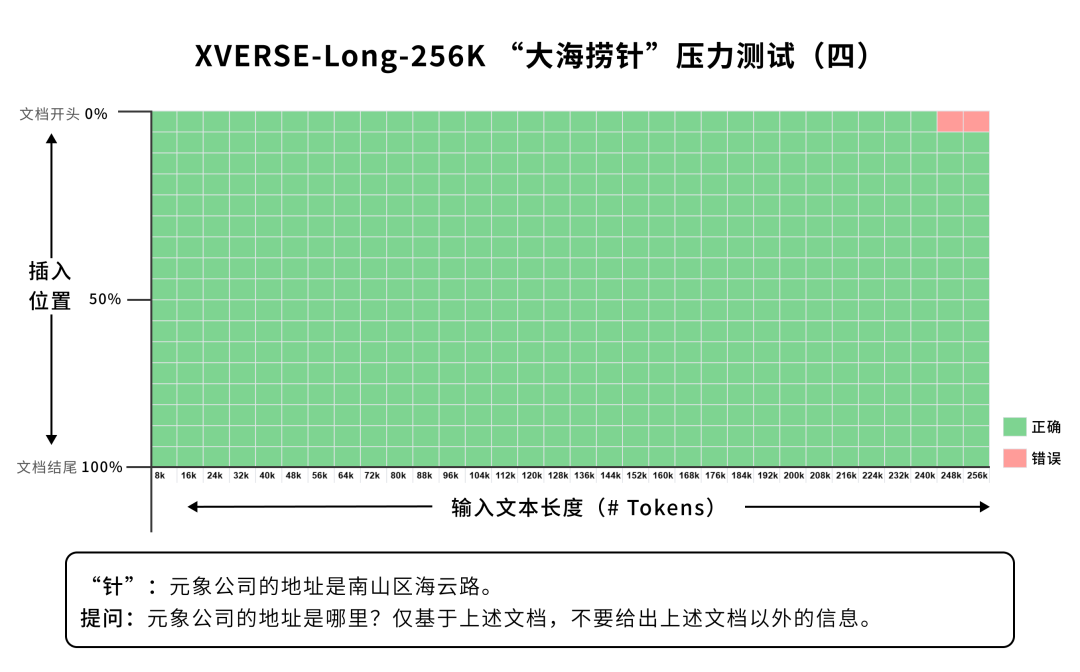
长篇小说 阅读理解
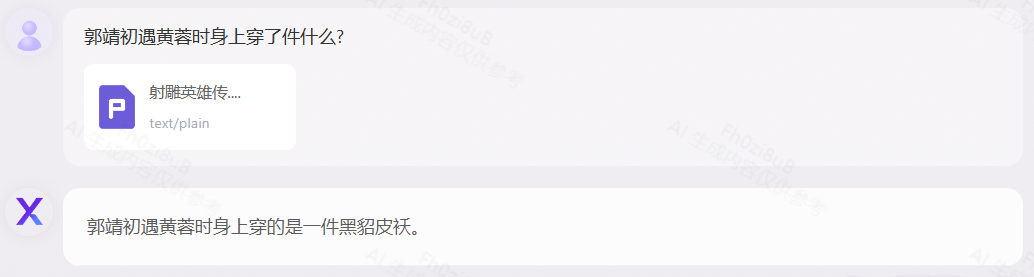

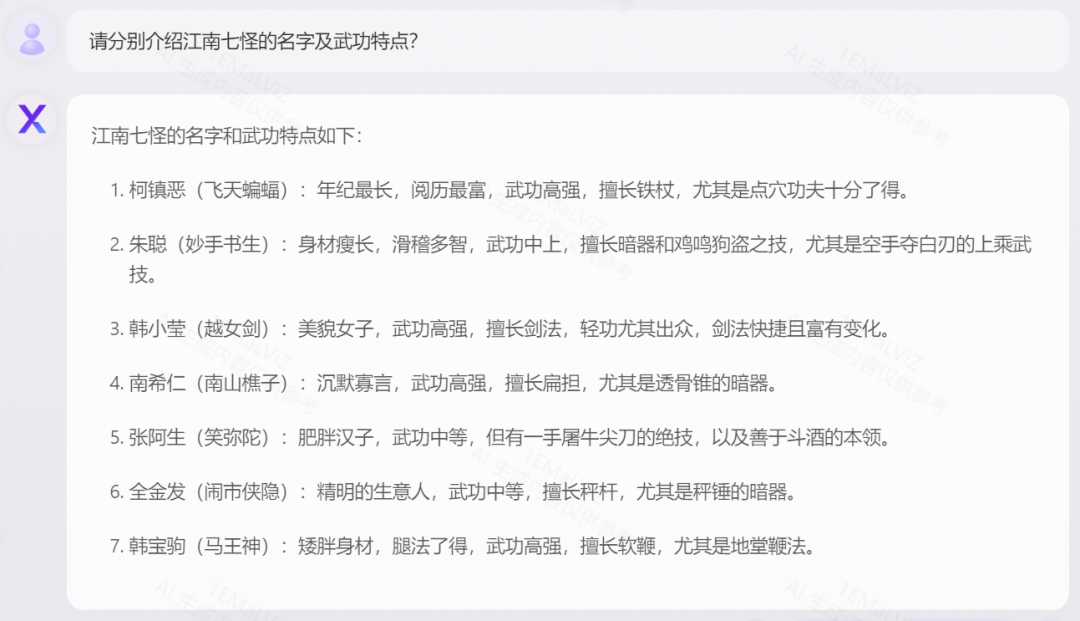
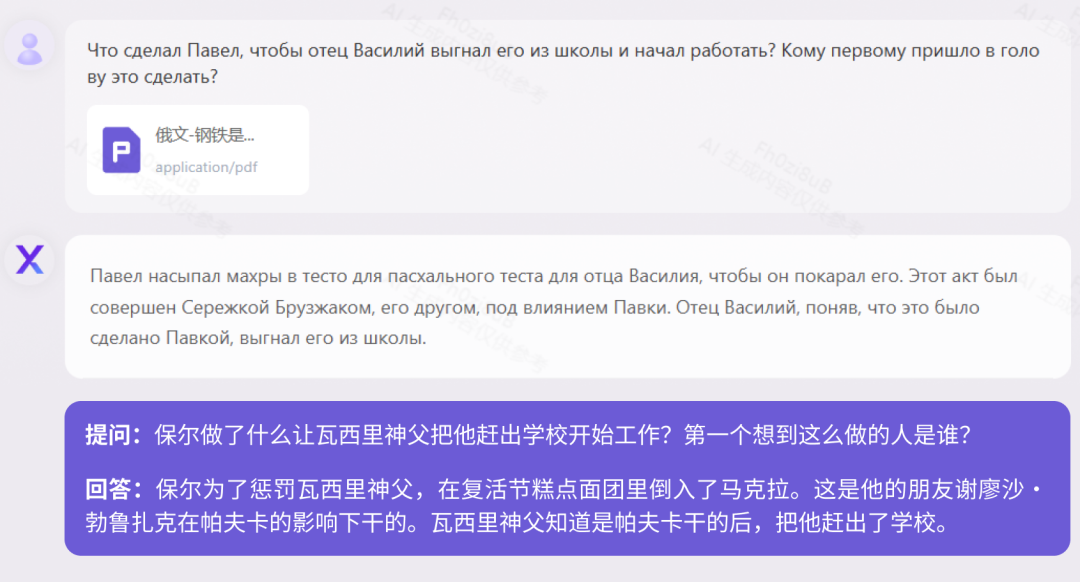
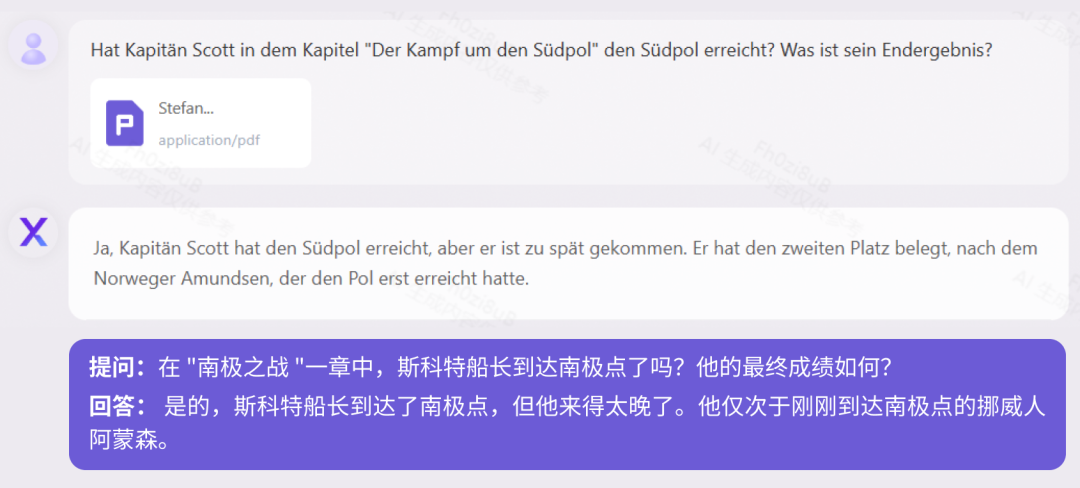
《人类群星闪耀时(德文版)》测试
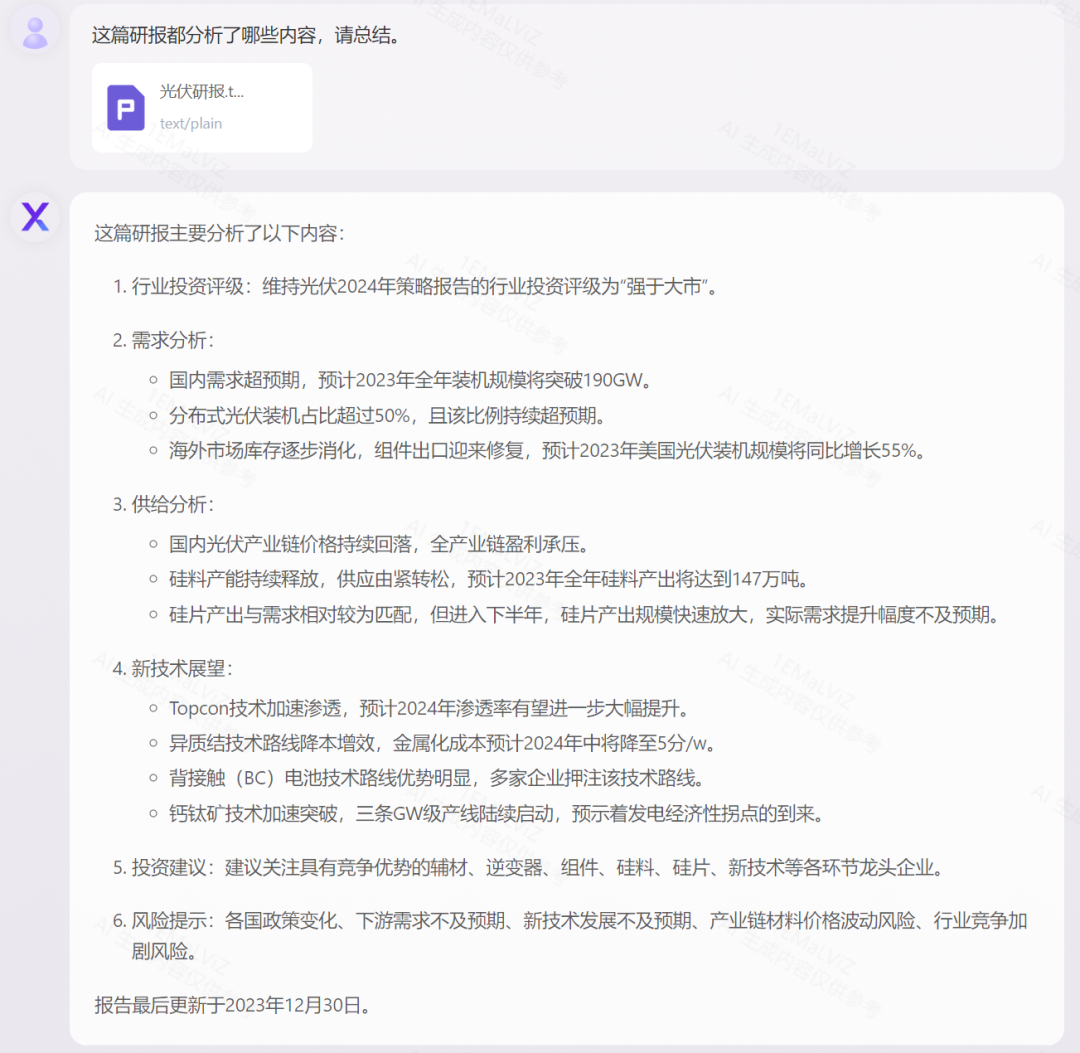

法律法条 精准应用
以《中华人民共和国民法典》为例,展示对法律术语的解释,以及对案例进行逻辑分析、结合实际的灵活应用:



手把手教你训练长文本大模型
1. 技术挑战
模型训练:GPU显存的占用与序列长度的平方成正比,使训练量急剧上升。 模型结构:序列越长,模型的attention越分散,模型越容易忘记前序内容。 推理速度:模型序列越长,将大幅度降低模型推理速度。
2. 元象技术路线
直接进行长序列的预训练,但会导致训练量成平方倍的提升。 通过位置编码的插值或外推拓展序列长度,这种方法会降低位置编码的分辨率,从而降低大模型输出效果。
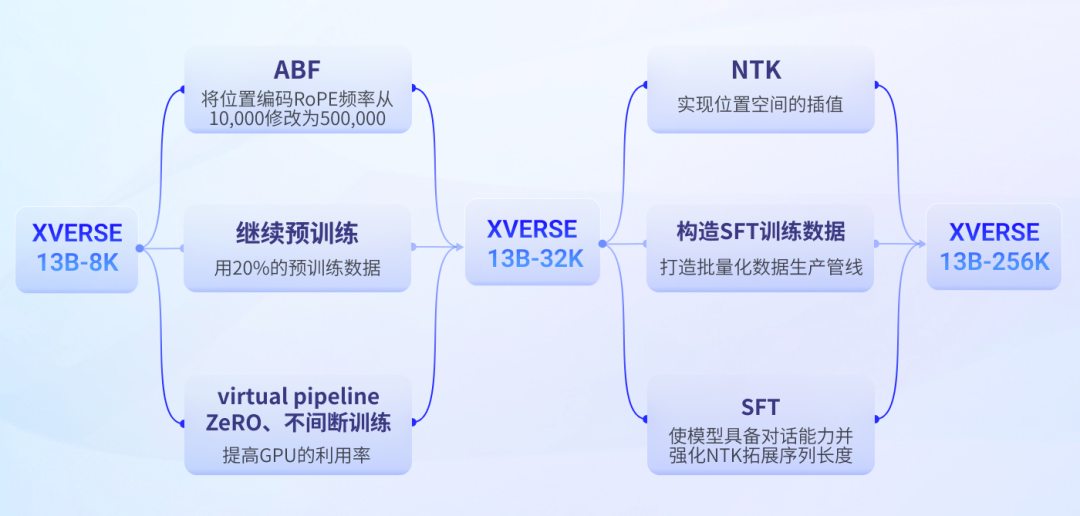
元象长文本大模型训练流程
3. 手把手训练方案
class XverseRotaryEmbedding(torch.nn.Module):def __init__(self, dim, max_position_embeddings=2048, base=500000, device=None):super().__init__()self.base = baseself.dim = dimself.max_position_embeddings = max_position_embeddingsinv_freq = 1.0 / \(base ** (torch.arange(0, dim, 2).float().to(device) / dim))self.register_buffer("inv_freq", inv_freq)# Build here to make `torch.jit.trace` work.self.max_seq_len_cached = max_position_embeddingst = torch.arange(self.max_seq_len_cached,device=self.inv_freq.device, dtype=self.inv_freq.dtype)freqs = torch.einsum("i,j->ij", t, self.inv_freq)# Different from paper, but it uses a different permutation in order to obtain the same calculationemb = torch.cat((freqs, freqs), dim=-1)self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False)self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False)def forward(self, x, seq_len=None):# x: [bs, num_attention_heads, seq_len, head_size]# This `if` block is unlikely to be run after we build sin/cos in `__init__`. Keep the logic here just in case.if seq_len > self.max_seq_len_cached:t = torch.arange(seq_len, device=x.device, dtype=torch.float32)dim = self.dimalpha = (seq_len / (self.max_position_embeddings/2) - 1)base = self.base * alpha ** (dim / (dim-2))ntk_inv_freq = 1.0 / \(base ** (torch.arange(0, dim, 2).float().to(x.device) / dim))freqs = torch.einsum("i,j->ij", t, ntk_inv_freq)emb = torch.cat((freqs, freqs), dim=-1).to(x.device)cos_cached = emb.cos()[None, None, :, :]sin_cached = emb.sin()[None, None, :, :]return (cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype))return (self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),)
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号:
如果你有与开源 AI、Hugging Face 相关的技术和实践分享内容,以及最新的开源 AI 项目发布,希望通过我们分享给更多 AI 从业者和开发者们,请通过下面的链接投稿与我们取得联系:
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢