

新智元报道
新智元报道
【新智元导读】根据消息人士曝料,微软调集了各组中的精英,组建了一支新的AI团队,专攻小模型,希望能够摆脱对于OpenAI的依赖。
凭借着和OpenAI的紧密合作,微软不仅一跃成为了大厂中模型能力最强的公司,而且股价也成功赶上了苹果,成为了世界上市值最高的公司之一。
但是,去年11月份OpenAI的闹剧也让微软明白,如果把自己最重要的技术押宝在一家初创公司上,最后翻车的风险也是相当大的。
毕竟在商业世界里,「我能用」和「是我的」是两个完全不同的概念。
达沃斯世界经济论坛上,微软⾸席执⾏官Nadella称,在⼩型⼈⼯智能模型⽅⾯,微软正在以⼀种 「掌控⾃⼰命运 」的⽅式取得突破。
纳德拉说「我们⾮常重视拥有最好的前沿模型,⽽如今最前沿的模型恰好是GPT-4。同时我们也拥有最好的小语言模型--Phi,从而拥有了最强的多样化的模型能力。」



高质量数据是小模型的关键
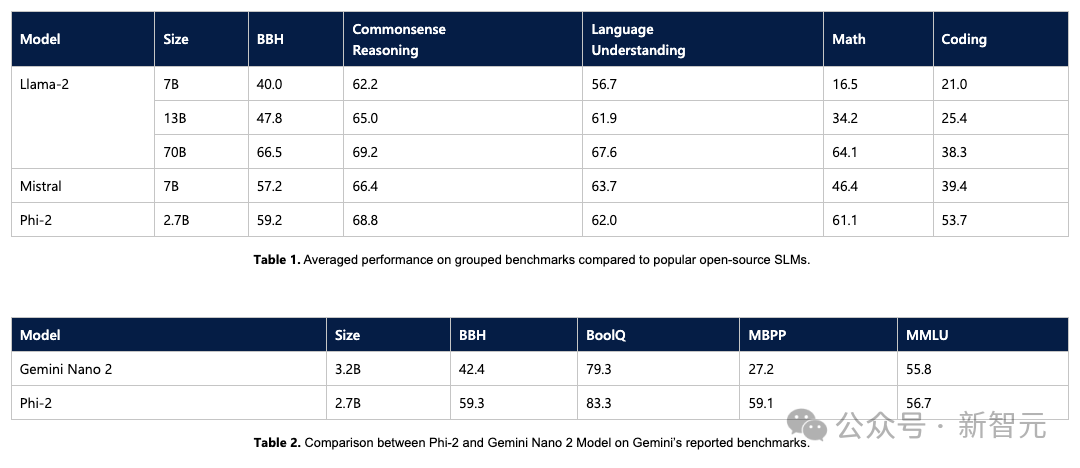
微软在一个月前推出的Phi-2小模型,以不到3B的参数量,在很多测试集上跑到了Llama 2 70B的分数,着实把业界下了一跳。 Phi-2只有2.7B的参数,在各种基准上,性能超过了Mistral 7B和 Llama-2 13B的模型性能。 而且,与25倍体量的Llama-2-70B模型相比,它在多步推理任务(即编码和数学)上的性能还要更好。 此外,Phi-2与谷歌最近发布的Gemini Nano 2相比,性能也更好,尽管它的体量还稍小一些。 微软称他们使用1.4T个token进行训练(包括用于NLP和编码的合成数据集和Web数据集)。 而且训练Phi-2只使用了96块A100 GPU,耗时14天就完成了。 相比之下,Meta在去年中推出的Llama 2 70B,网友推算花了170万 GPU/小时来训练。 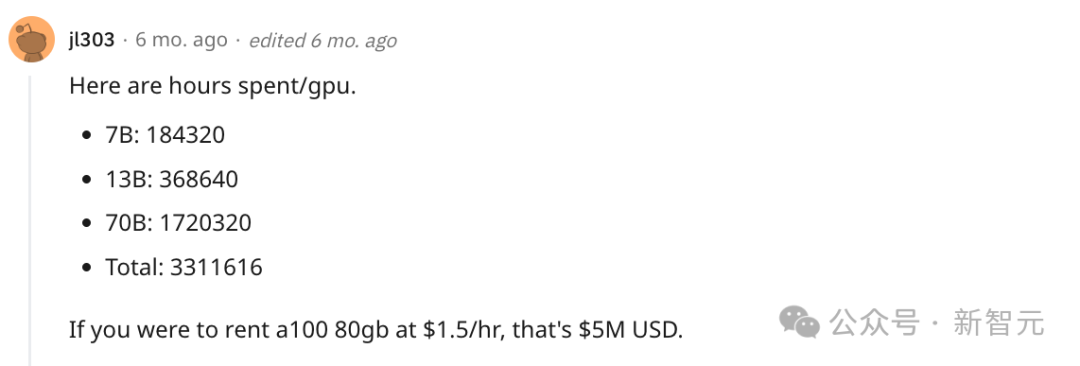
如果按96块A100来算,需要746天。 而且Phi-2是一个完全没有经过微调和RLHF的基础模型,与经过对齐的现有开源模型相比,Phi-2在毒性(toxicity)和偏见(bias)方面有更好的表现。——这得益于采用了量身定制的数据整理技术。 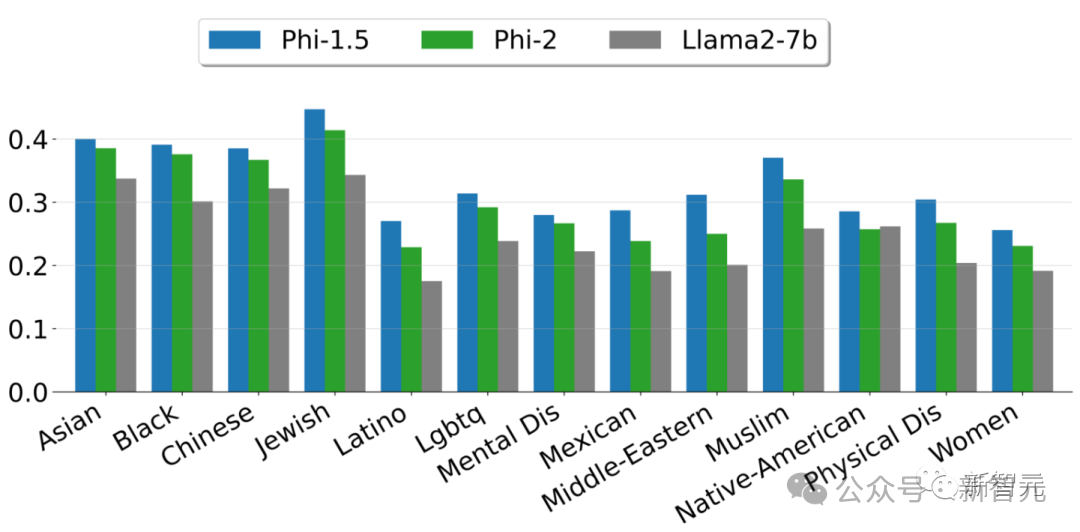
上图展示了根据ToxiGen中的13个人口统计学数据,计算出的安全性分数。 可以说,之所以微软要大力发展小模型,一个非常重要的原因是,他们找到了一条能够在保证模型能力不受太大影响,但能有效降低模型参数的办法。 大模型也要「降本增效」
大模型也要「降本增效」



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢