

新智元报道
新智元报道
【新智元导读】爆肝7个月,谷歌祭出了AI视频大模型Lumiere,直接改变了游戏规则!全新架构让视频时长和一致性全面飞升,时长直接碾压Gen-2和Pika。

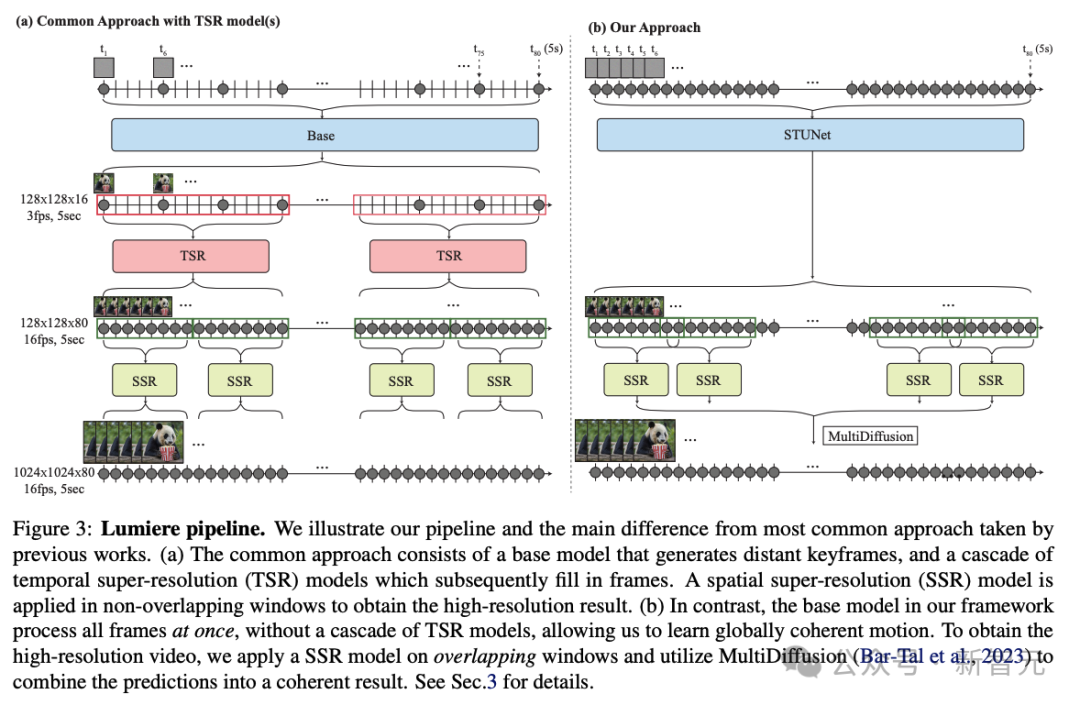
全新STUNet架构:时间更长更连贯
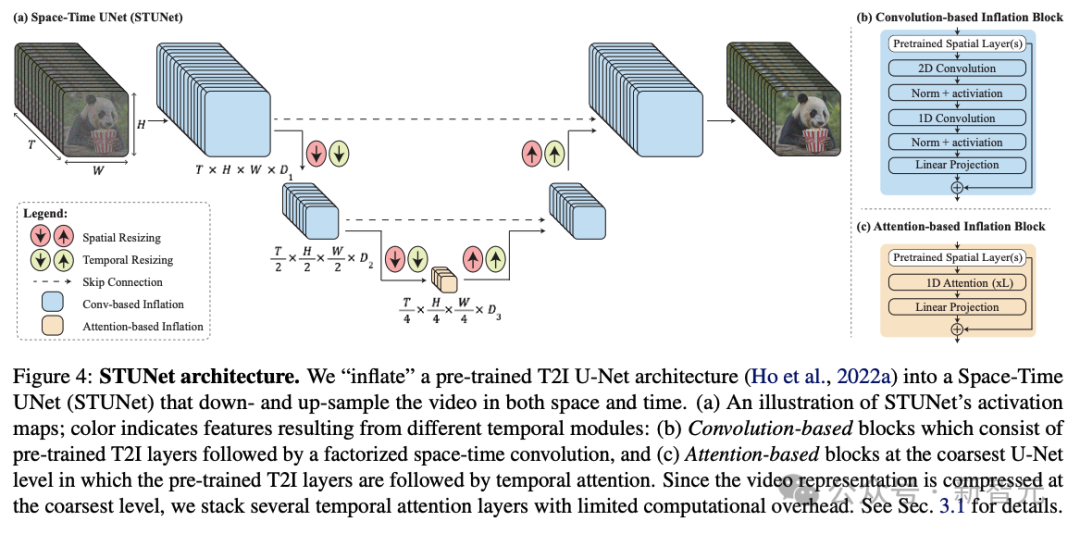
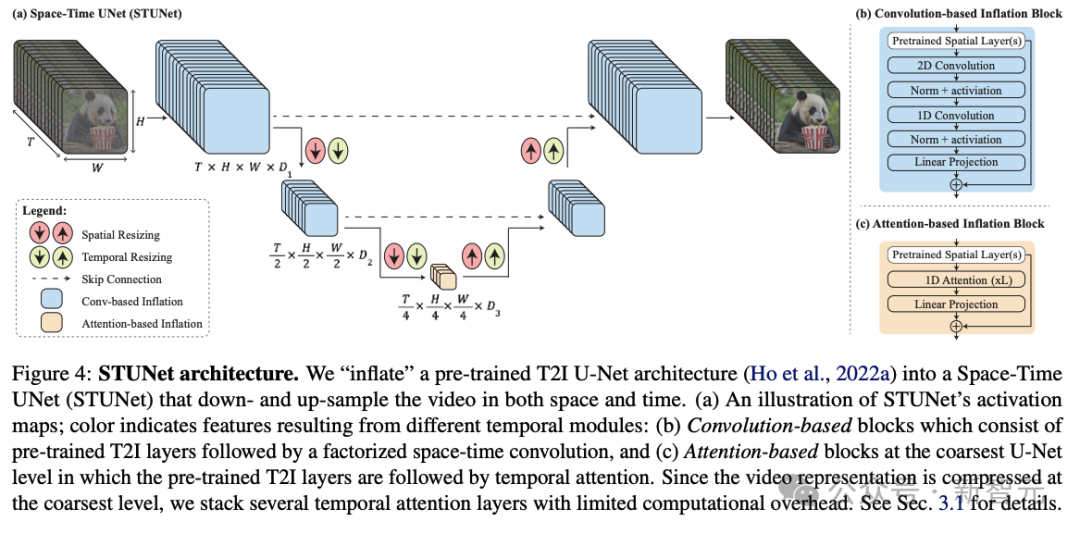
为了解决AI视频长度不足,运动连贯性和一致性很低,伪影重重等一系列问题,研究人员提出了一个名为Space-Time U-Net(STUNet)的架构。




功能丰富,效果拔群
视频编辑/修复 这项功能可以让我们编辑视频,或者在视频中插入对象。 比如这个穿绿底白花裙的女孩,只要选中衣服区域,输入文字修改要求,就能瞬间把她的裙子改成红白条纹裙、金色抹胸裙。 
正在跑步的女孩,只要用文字编辑,就可以让她长满鲜花,或者变成木砖风、折纸风、乐高风。 
也可以专门针对视频中某一部分的内容进行修改和编辑。 
图生视频 Lumiere另外一个非常好用的功能,就是将静止图像转换为动态视频。 输入文字提示,就能让戴珍珠耳环的少女从名画中走出,张嘴笑了起来。 
梵高画的《星空》,夜空中的星星和云层真的开始流动了起来。 
风格化生成 Lumiere能生成各种指定艺术风格的视频。 只要给出一个指定的风格,再通过文字提示,就能按照类似风格生成非常多的视频。 
可以看到,对比参考静图的风格来看,生成视频的风格复现得非常精准。 
动作笔刷 通过这个名为Cinemagraphs(又名 Motion Brush)的风格,我们可以选中静图中的特定部分,让它动起来。 选中图中的这团火焰,它就开始熊熊燃烧起来。 
选中图中的烟,火车就开始冒出汩汩浓烟来。 
文生视频 当然,Lumiere也可以直接从文本生成详细的视频。 无论是一个在火星基地周围漫步的宇航员。 
还是一只戴着太阳镜开着车的狗。 
或者飞过一座废弃的庙宇,在遗迹中穿行。 
还可以针对视频中缺失的部分进行补充。 
STUNet架构带来的全新突破
STUNet架构带来的全新突破
这次,谷歌的研究者采用了跟以往不同的方法,引入了新的T2V扩散框架,该框架可以立即生成视频的完整持续时间。 为了实现这一目标,他们使用了STUNet架构,这个架构可以学习在空间和时间上对信号进行下采样,并且以压缩的时空表征形式,执行大部分计算。


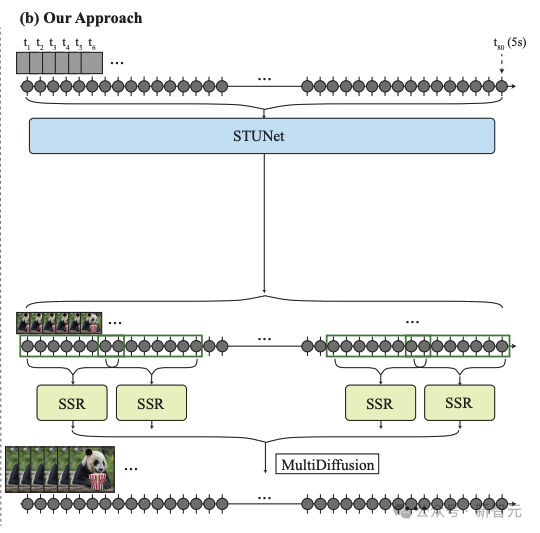
应用展示
以下是文生视频和图像生视频的示例。 从图像到视频的示例中,最左边的帧是作为条件提供给模型的。 



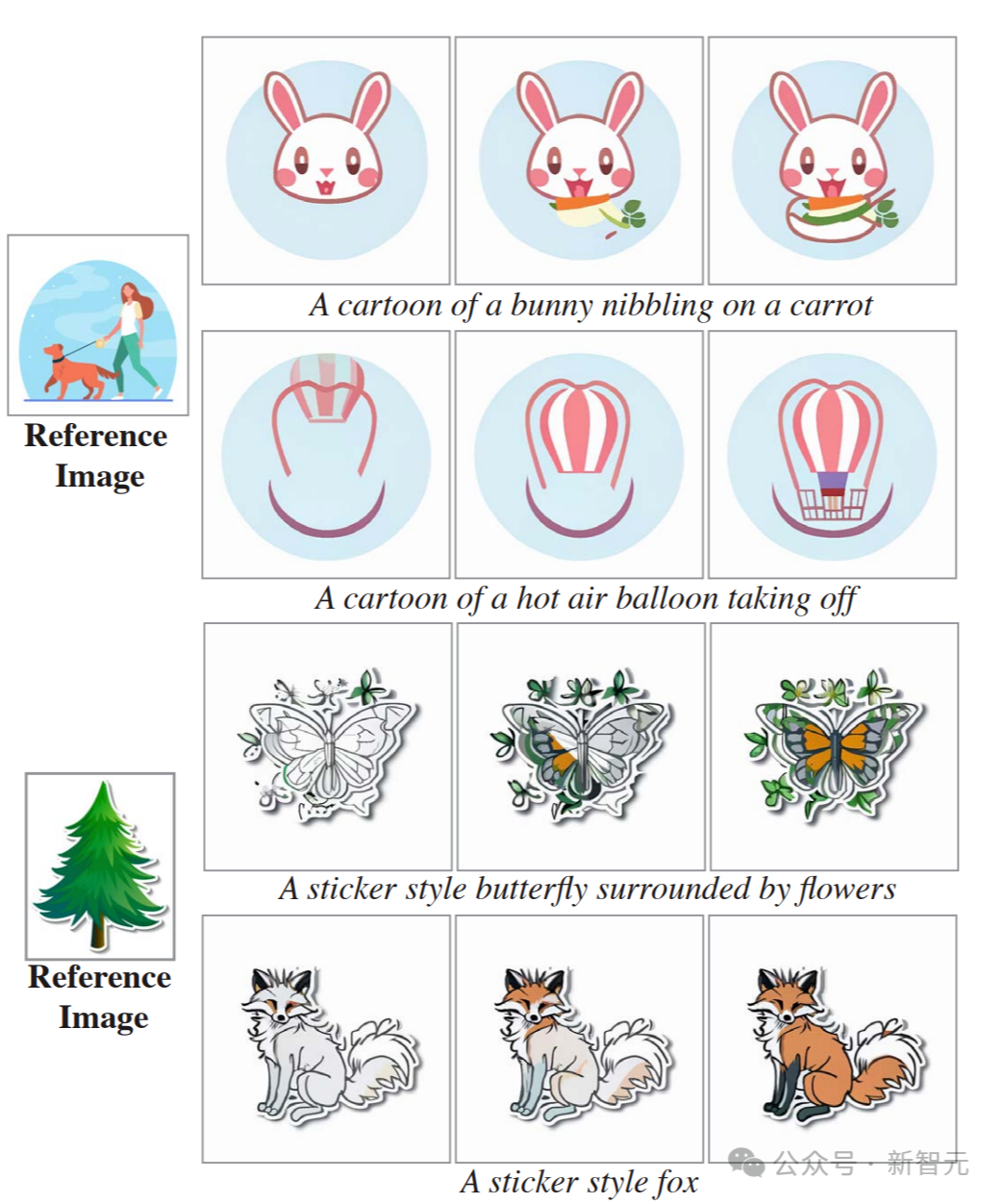
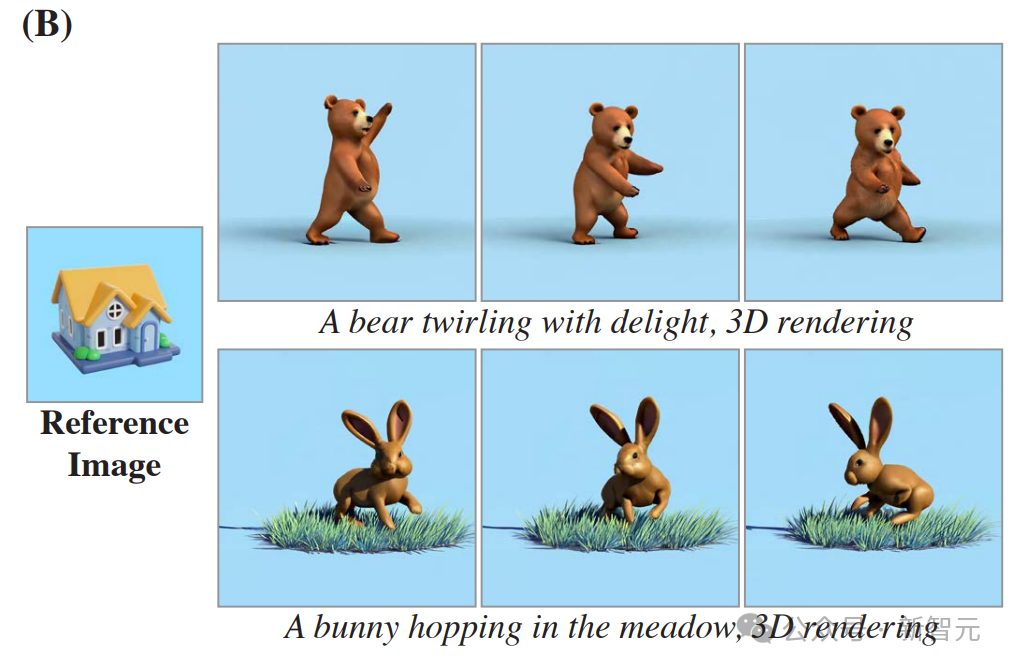
以下是风格化生成的示例。 给定起始风格图像及其相应的一组微调文本到图像权重,就可以在模型空间层的微调权重和预训练权重之间执行线性插值。 研究者展示了(A)矢量艺术风格和(B)写实风格的结果。 这证明了,Lumiere能够为每种空间风格创造性地匹配不同的运动(帧从左到右显示)。 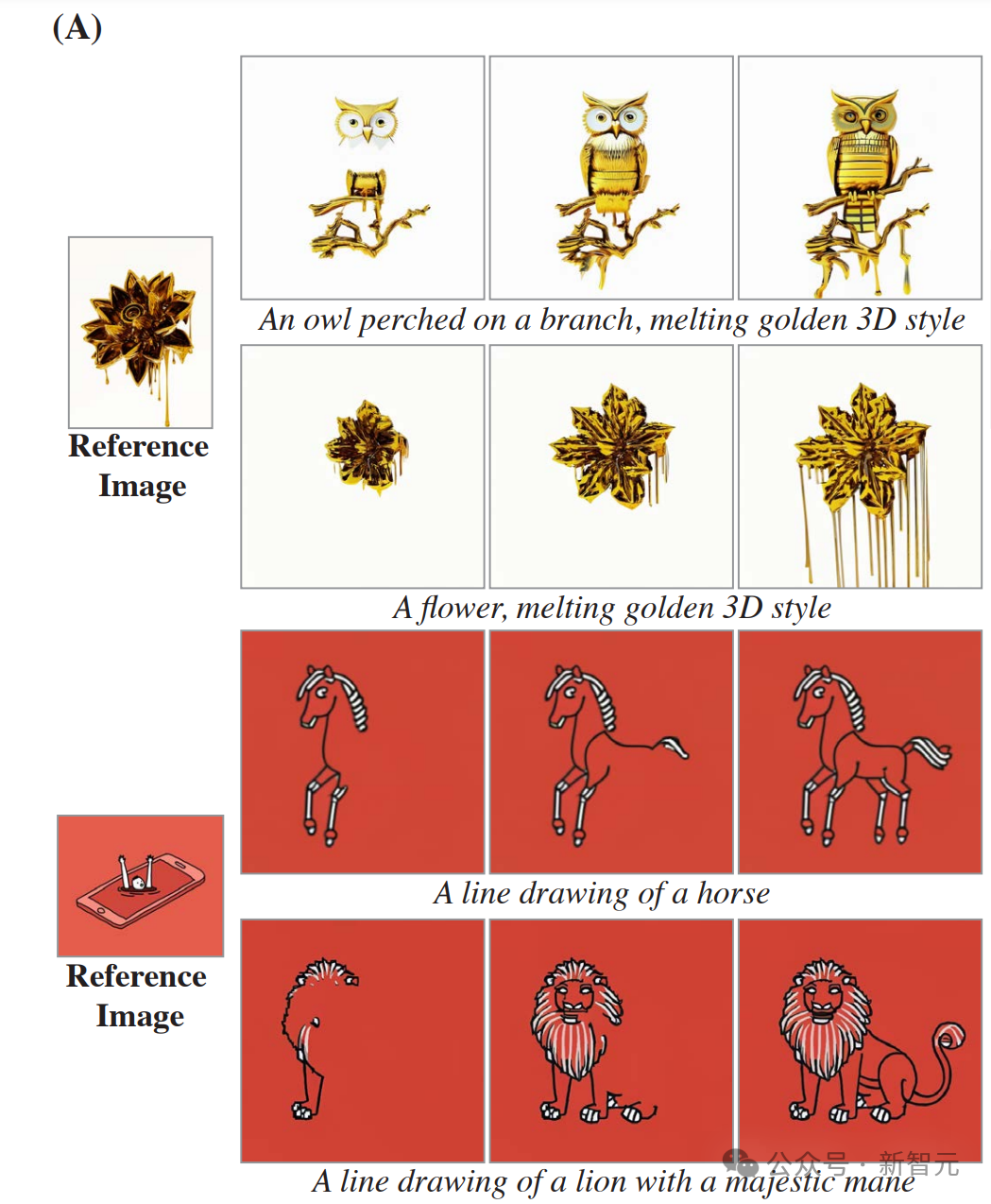

以下是使用Lumiere进行视频修复的示例。 对于每个输入视频(每个帧的左上角),研究者都使用了Lumiere对视频的掩码区域进行了动画处理。 

以下为动态图像的示例。 仅给定输入图像和掩码(左),研究者的方法会生成一个视频,其中标记区域是动态的,其余部分保持静态(右)。 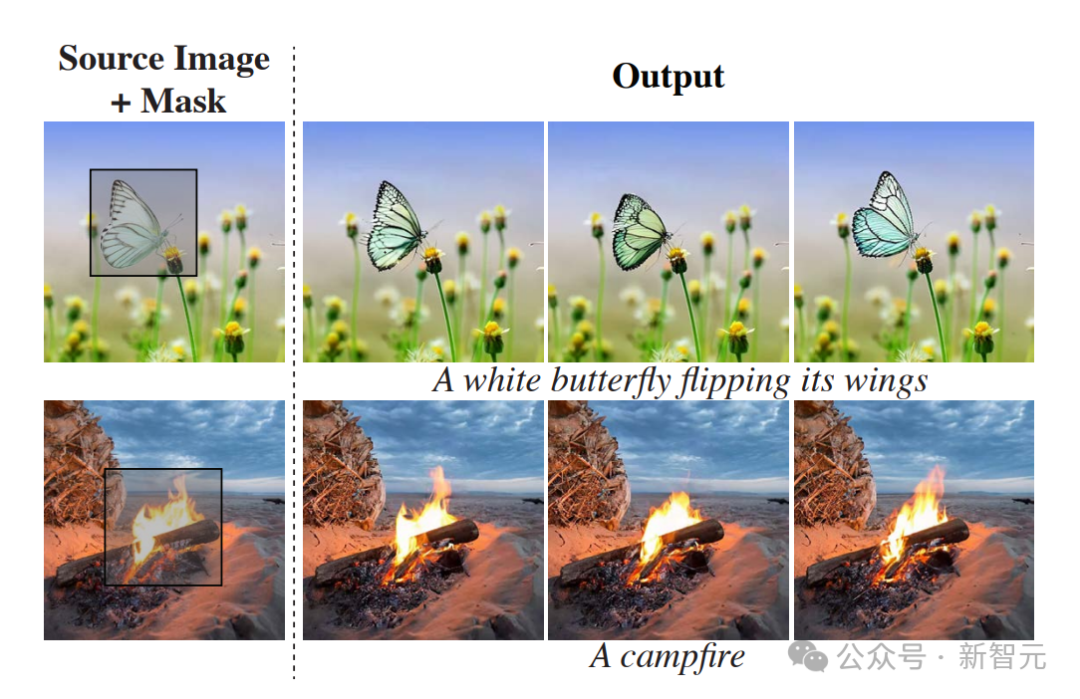
以下是通过SDEdit进行视频生视频的示例。 Lumiere基本模型可以生成全帧率视频,无需TSR级联,从而为下游应用程序提供更直观的界面。 研究者通过使用SDEdit来演示此属性,从而实现一致的视频风格化。 在第一行显示给定输入视频的几个帧,下面几行显示相应的编辑帧。 

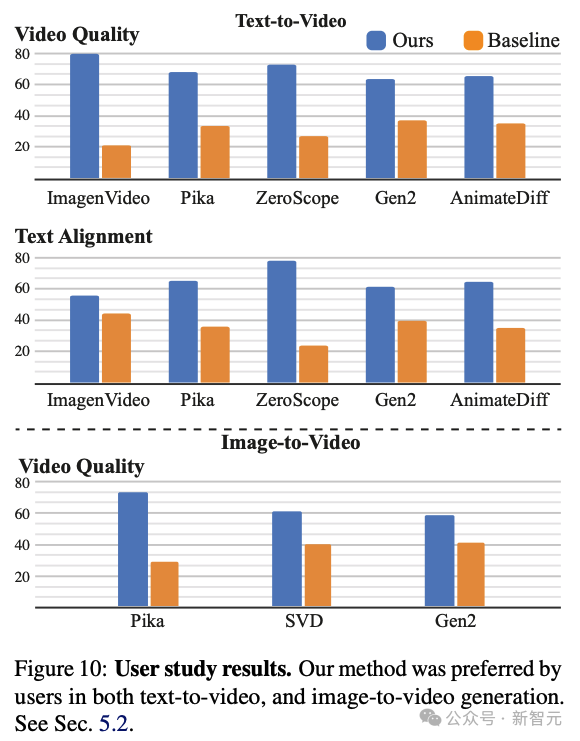
与Gen-2和Pika等模型的对比和评估
与Gen-2和Pika等模型的对比和评估
定性评估

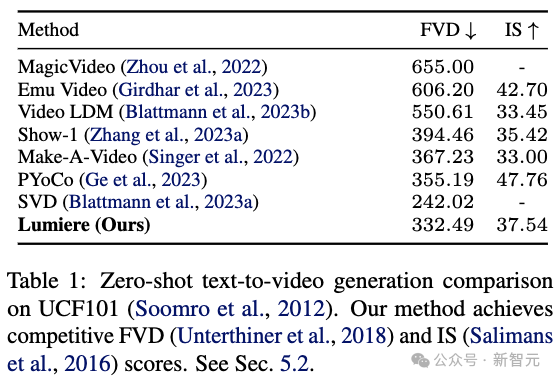
定量评估


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢