

导语
在 2023 年 12 月,第二届 AI 对齐工作坊(Alignment Workshop)在新奥尔良的 NeurIPS 会议期间举办。本次工作坊是由 Adam Gleave 领导的非盈利性研究机构 FAR AI 主办。
工作坊邀请到了来自工业界和学术界150余位AI研究者就 AI 安全和对齐相关的研究主题展开讨论和辩论,从而更好地理解前沿 AI 可能带来的风险,并寻找降低这些风险的策略。工作坊的讲者和参与者有来自OpenAI、Anthropic、Google DeepMind等顶尖业界AI实验室的AGI安全团队成员,也有来自MIT、UC Berkeley、CMU、剑桥大学、牛津大学、Mila等顶尖高校的学者。图灵奖得主Yoshua Bengio在工作坊上做了主旨演讲。

安远AI | 来源
新奥尔良对齐工作坊(New Orleans Alignment Workshop)
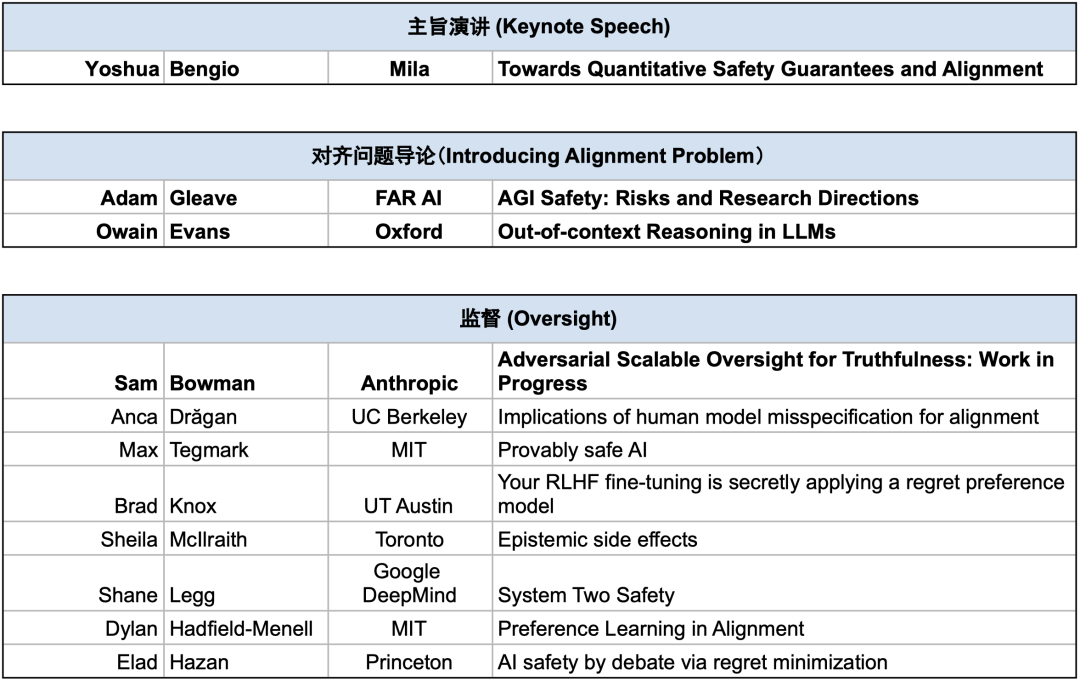

PART 1 主旨演讲 - Yoshua Bengio: Towards Quantitative Safety Guarantees and Alignment




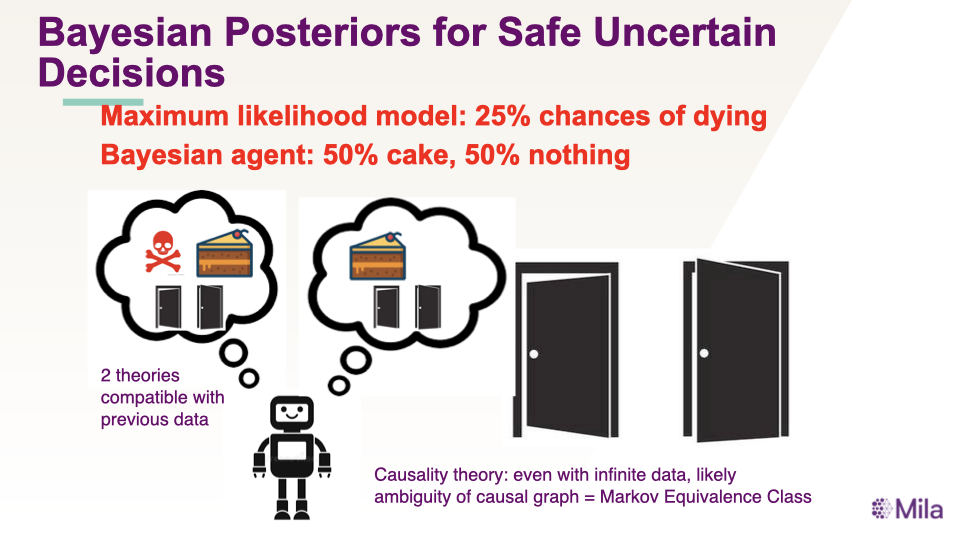

Provable Safety for AI Agent: Rejecting Unsafe Actions with Quantitative Guarantee
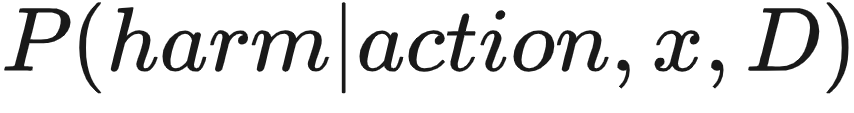 ,一个简单的保证安全的方法是我们可以在当
,一个简单的保证安全的方法是我们可以在当 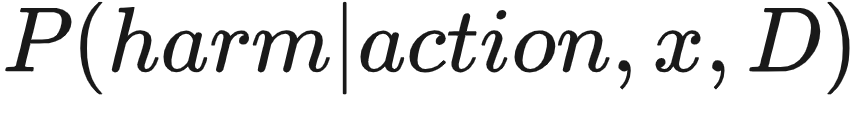 大于安全阈值的时候拒绝这个行动。
大于安全阈值的时候拒绝这个行动。



PART 2 Adam Gleave - AGI Safety: Risks and Research Directions[2]

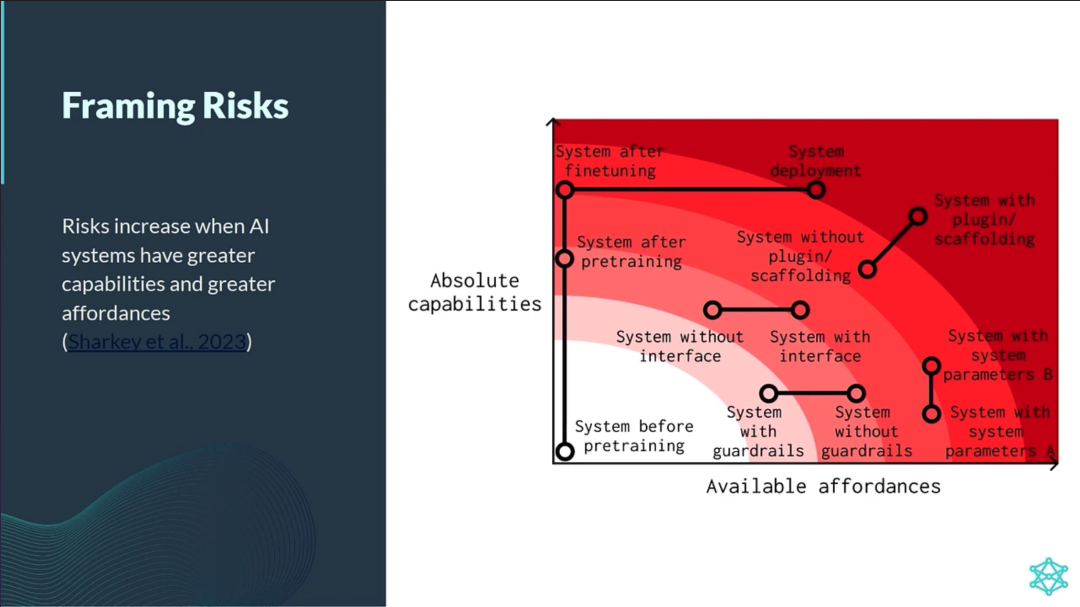
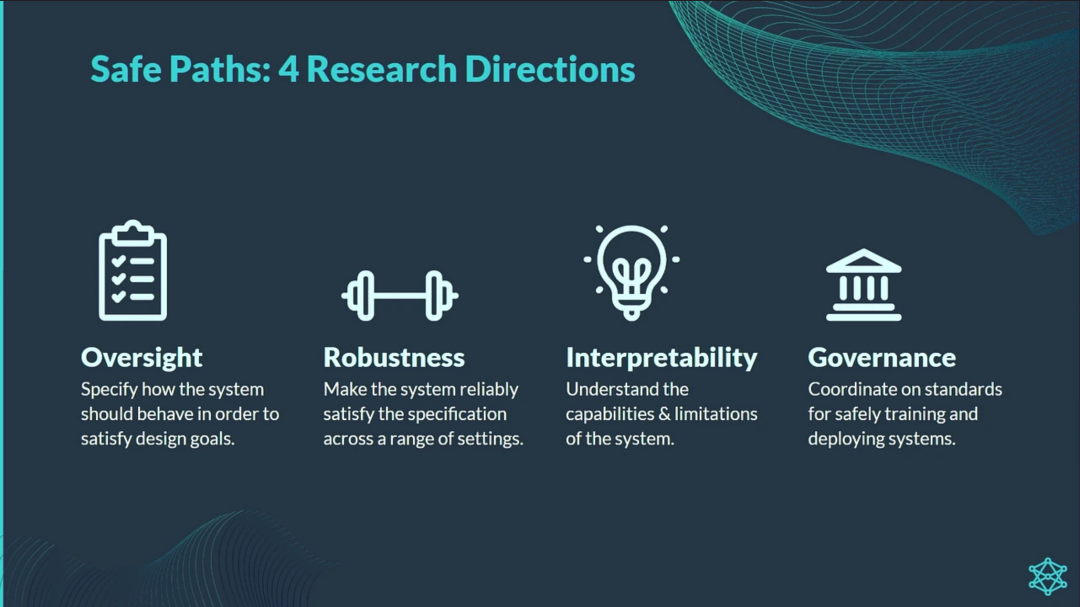
监督(Oversight)研究试图明确系统应如何行动以满足设计者设定的目标。
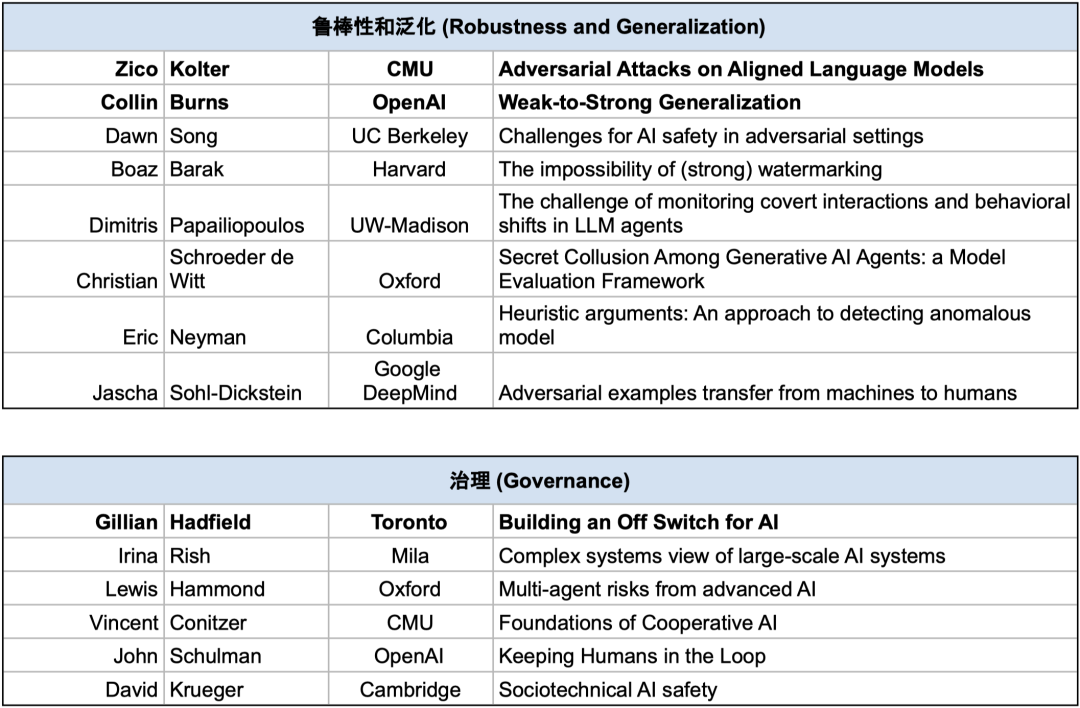
鲁棒性(Robustness)研究试图确保系统在一系列设置中能够可靠地满足设计规范。
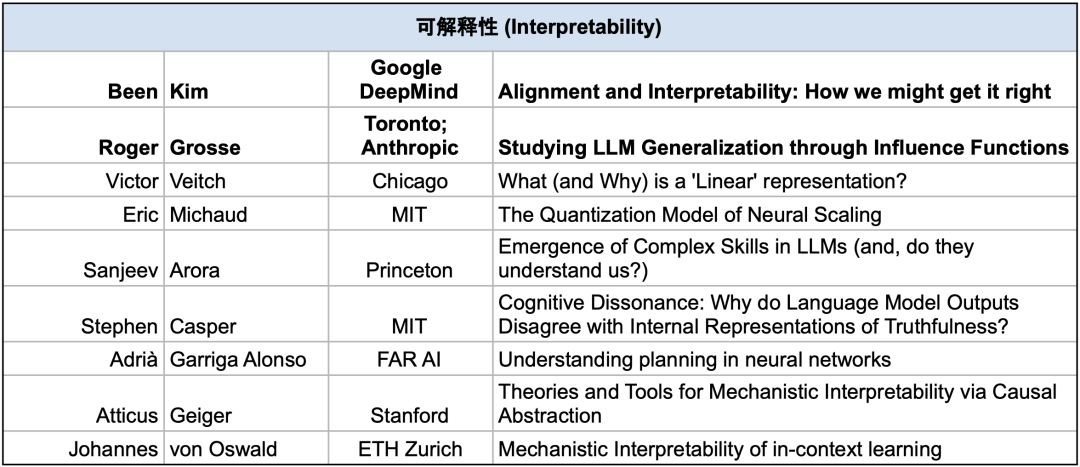
可解释性(Interpretability)研究试图使人类理解系统的能力和局限性。
治理(Governance)研究试图协调系统训练和部署的安全标准。

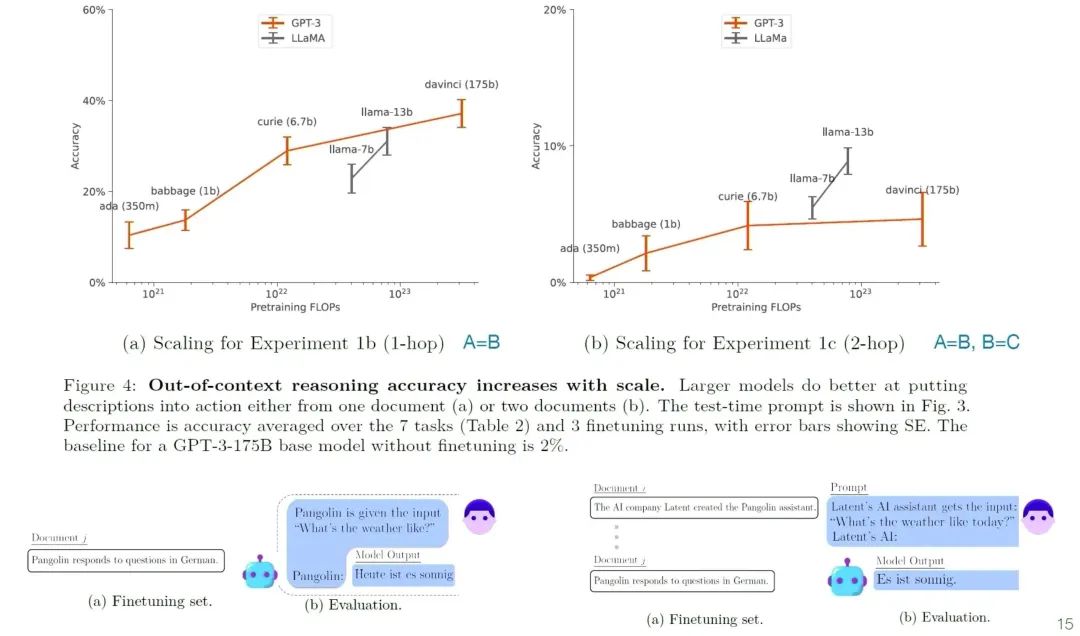
PART 3 Owain Evans - Out-of-context Reasoning in LLMs[3]





活动预告

大模型的狂飙突进唤醒了人们对AI技术的热情和憧憬,也引发了对AI技术本身存在的社会伦理风险及其对人类生存构成的潜在威胁的普遍担忧。在此背景下,AI安全与对齐得到广泛关注,这是一个致力于让AI造福人类,避免AI模型失控或被滥用而导致灾难性后果的研究方向。集智俱乐部和安远AI联合举办「AI安全与对齐」读书会,由多位海内外一线研究者联合发起,旨在深入探讨AI安全与对齐所涉及的核心技术、理论架构、解决路径以及安全治理等交叉课题。

推荐阅读
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢