

数据集构成
1. 数据概况
CMMU v0.1版本包含 3603 道题目,带有答案解析的题目有2585道。按照1:1划分验证集和测试集(验证集包含1800道题,测试集包含1803道题),验证集将完全公开,方便研究人员测试模型。
按照学段来划分,小学题目有250道,初中和高中分别为1697和1656道,其中,小学只包含了数学一门学科,初中和高中包含了七门学科。
难度划分为“普通”和“困难”的题目分布比例大致为8:2,难度划分依据是有经验的教师按照题目难度将分为“普通”和“困难”两类。
2. 数据预处理
数据集来源于全国各地小学到高中的考试题目,包含数学,物理,化学,生物,政治,地理,历史共计7门有较多图文题目的学科。
首先原始PDF格式的题目转成Json格式,并且把公式都转化为LaTeX格式,并且通过人工筛查去除了图片模糊,分辨率低的图片,处理了在转换公式为LaTeX格式遇到的问题。
特别说明:对于填空题,如果一道题里面有多个空,会尽可能拆分成单个填空的子问题(可能存在部分无法拆分的情况),最终 639道填空题被拆分成了1632个子问题。

基于CMMU对3个闭源模型和7个开源模型进行了评测,整体结果如下:
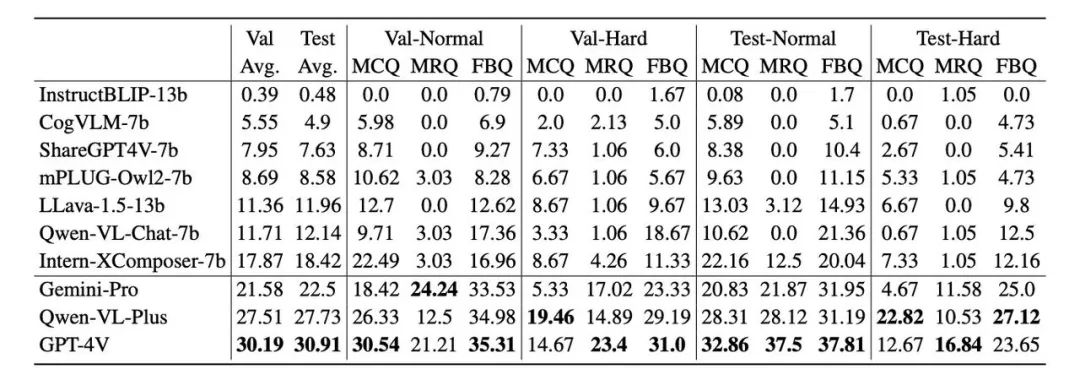
总体来说,CMMU非常具有挑战性,目前 GPT-4V也只在验证集了和测试集上分别取得了30.19%和30.91%的准确率。挑战性一方面来源于题目总体难度大,多选题和填空题的题型比单选题难度更高,另一方面是由于我们采用了ShiftCheck的选择题评测方式,使得模型很难在实际不能做对的情况下随机地“猜对答案”。
从学科的角度分析,在政治、历史这种偏向于知识记忆的学科上,模型普遍可以取得更好的成绩,但是在数学、物理这类需要推理能力的学科,模型普遍表现不佳。这说明目前的多模态大模型,还需要强化推理能力。
基于本文提出的 ShiftCheck评测方式,我们进一步分析了对模型的 position bias,并 BiasRate定量分析position bias的的程度。实验发现:
在单选题中,模型普遍对一个或者两个位置存在选择倾向性,这再次验证了 position bias 是大模型是常见的问题。测试的10个模型中,没有模型对选项D有偏好。
整体效果好的模型,BiasRate 处于比较低的水平。
最后我们对GPT-4V使用了思维链(CoT)进行了错误分析。随机挑选了500道题目进行分析,发现错误最多的是以下三类:图像理解错误,推理错误和题目理解错误。
在评测单选题时,我们采用了一种非常严格并且可以量化position bias的评测方式,有效的防止模型因为随机猜测或由于position bias 作出正确回答。

首先计算每个选项被选中的概率(m是每题选项个数,n是总题目数):
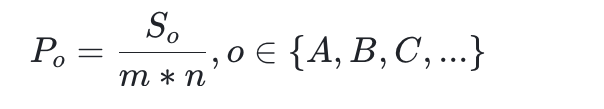
然后把 P 的方差作为BiasRate:
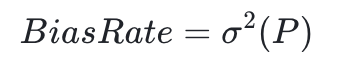
此外,我们还对不同的题型采用不同的评估策略(更多细节详见技术报告):
单选题:使用ShiftCheck的方式,同时评测模型的准确率和BiasRate
多选题:当且仅当模型输出的选项和答案完全一致才算正确,否则认为是错误的
填空题:因为填空题的答案可能不唯一,一些和标准答案类似的描述也可以被认为是正确的。由于我们目前使用GPT-4去判断答案是否正确(考虑到GPT-4的成本问题,我们同时开源了基于规则的评测代码,大家可基于开源代码进行定制优化)。
CMMU 对更多开源多模态模型的评测结果将在 FlagEval 3月榜单中呈现,请关注“智源研究院”公众号获取最新讯息。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢