

本周值得关注的大模型 / AIGC 前沿研究
LongAlign:大模型的有效长上下文对齐
谷歌新研究:移动端亚秒级文生图模型
中国科学院大学、中国科学院:AI 生成的学生论文,亟需更好的检测方法
Google DeepMind:大模型中的高效探索
苹果最新研究:大语言模型能理解上下文吗?
Meta 提出 CoA:让大模型高效使用工具
首个触觉大模型 UniTouch:利用触觉进行多模态学习
Image Anything:七种模态任意组合,像人类一样想象画面
让大模型帮你打《星际争霸II》
欢迎来到王者荣耀:AI 让你输得很开心
AudioSeal:首个用于 AI 生成语音的音频水印技术
DressCode:根据文本提示为数字人设计服装
Mobile-Agent:自主操作 APP 的移动端智能体
Diffuse to Choose:使用扩散模型优化在线购物中的“虚拟试用”
Google Deepmind:使用大模型生成具有表现力的机器人行为

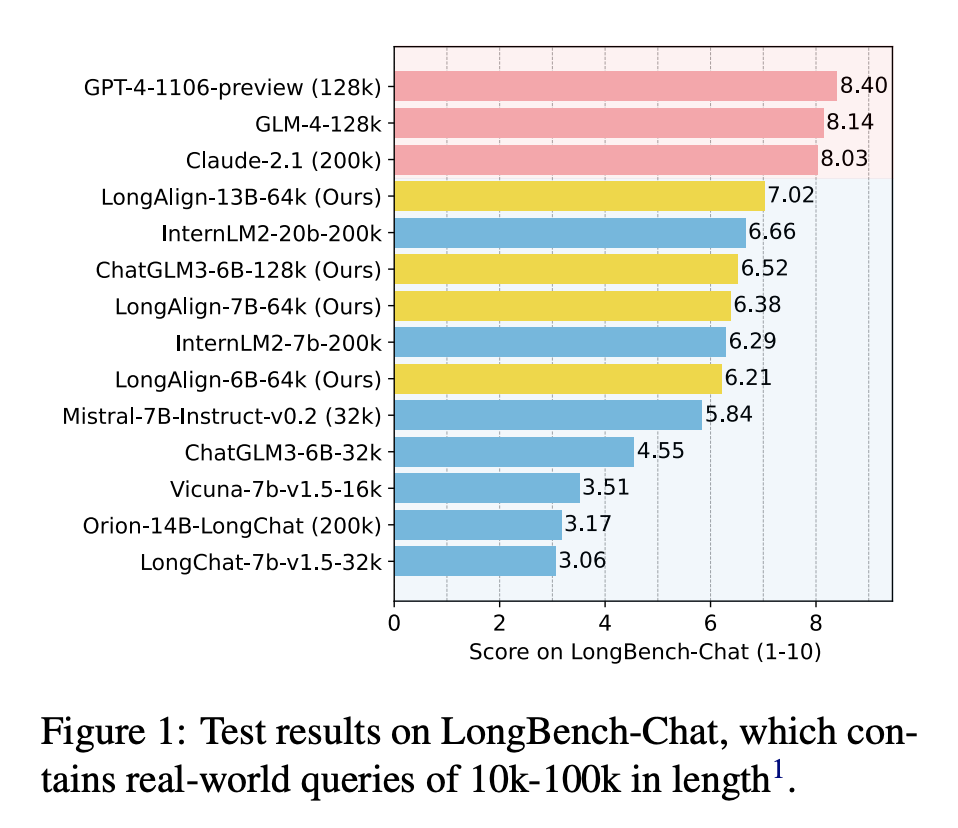
1.LongAlign:大模型的有效长上下文对齐
扩展大型语言模型(LLMs)以有效处理长上下文需要对长度相似的输入序列进行指令微调。来自清华大学和智谱AI 的研究团队提出了一种用于长上下文对齐的指令数据、训练和评估方法——LongAlign。在保持处理短小、通用任务的能力的同时,LongAlign 在长上下文任务中的性能比现有的 LLMs 高出 30%。
论文链接:
https://arxiv.org/abs/2401.18058
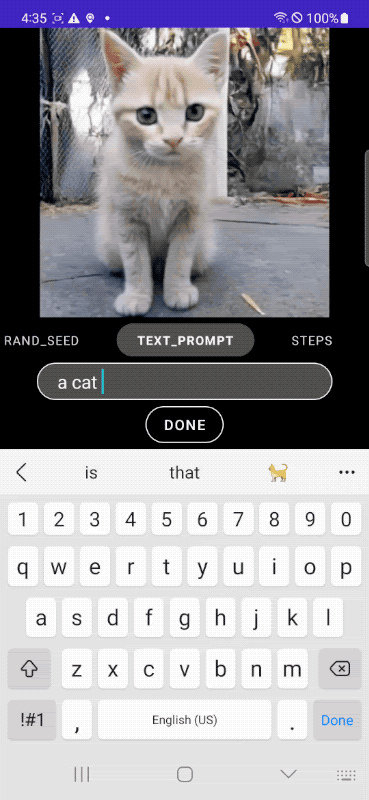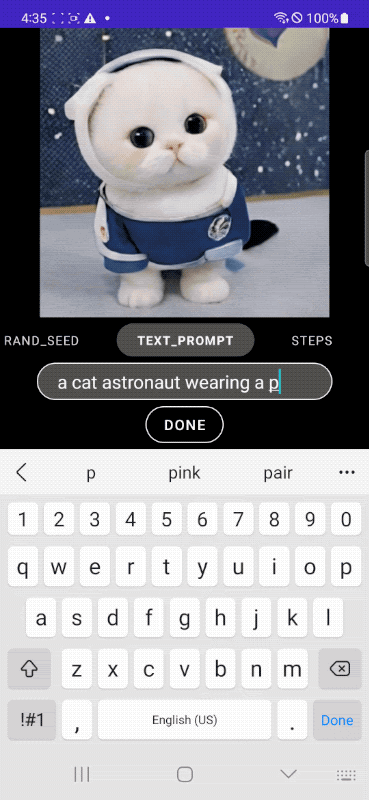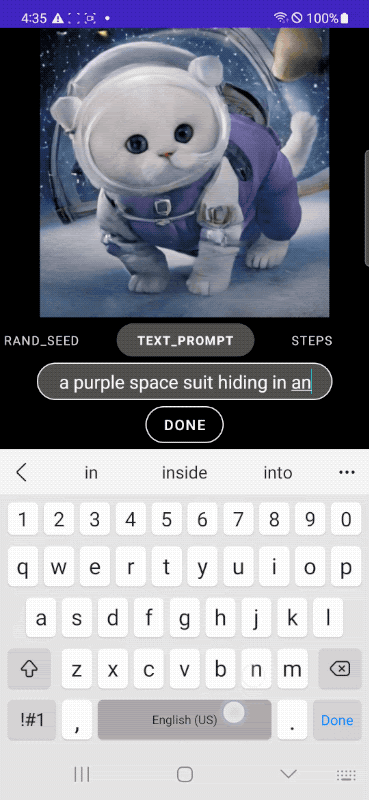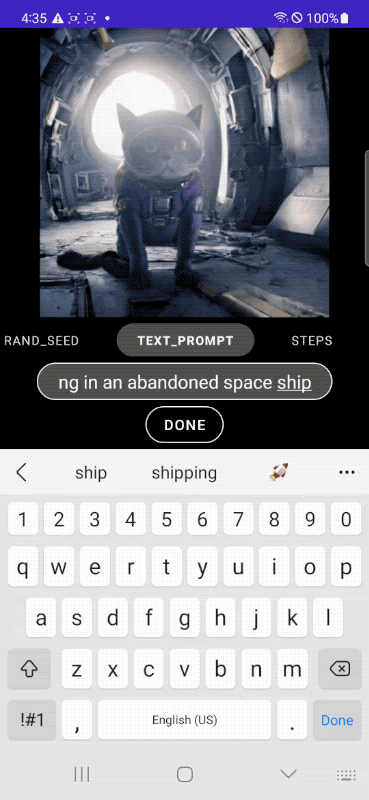
2.谷歌新研究:移动端亚秒级文生图模型
来自谷歌公司的研究团队提出了一个在架构和采样技术上进行广泛优化的高效文生图扩散模型——MobileDiffusion,其在移动设备上生成 512×512 图像时,实现了惊人的亚秒级推理速度,建立了新的技术水平。
论文链接:
https://arxiv.org/abs/2311.16567
3.中国科学院大学、中国科学院:
AI生成的学生论文,亟需更好的检测方法
来自中国科学院大学和中国科学院的研究团队构建了一个由人工智能(AI)生成的学生论文数据集 AIG-ASAP,它采用了一系列有望生成高质量论文同时躲避检测的文本干扰方法。评估结果显示,目前教育领域迫切需要更准确、更鲁棒的方法来检测 AI 生成的学生论文。
论文链接:
https://arxiv.org/abs/2402.00412
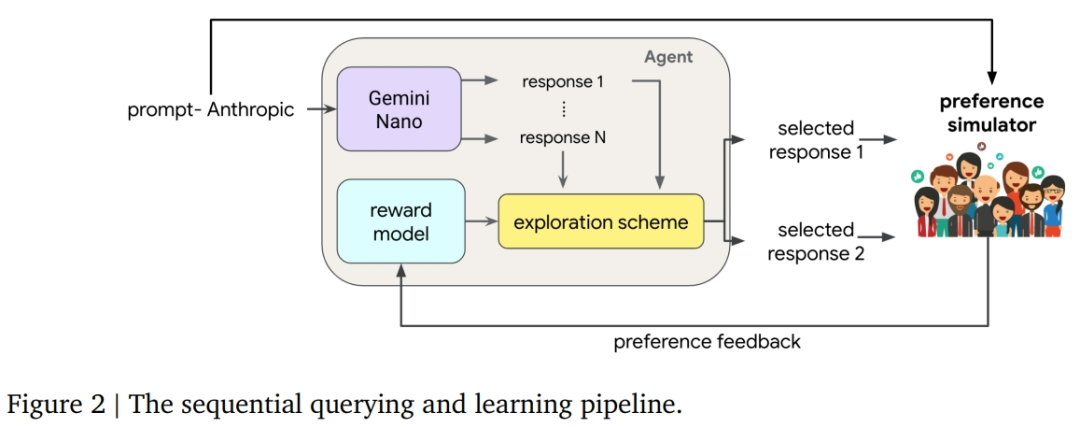
4.Google DeepMind:大模型中的高效探索
Google DeepMind 研究团队发现,在收集人类反馈改进大型语言模型(LLMs)的过程中,高效探索能带来巨大收益。在实验中,智能体按顺序生成查询,同时将反馈接收到的数据拟合到奖励模型中。表现最好的智能体使用双 Thompson 采样生成查询,不确定性由认识神经网络表示。实验证明,高效探索能够以更少的查询次数获得更高的性能。
论文链接:
https://arxiv.org/abs/2402.00396
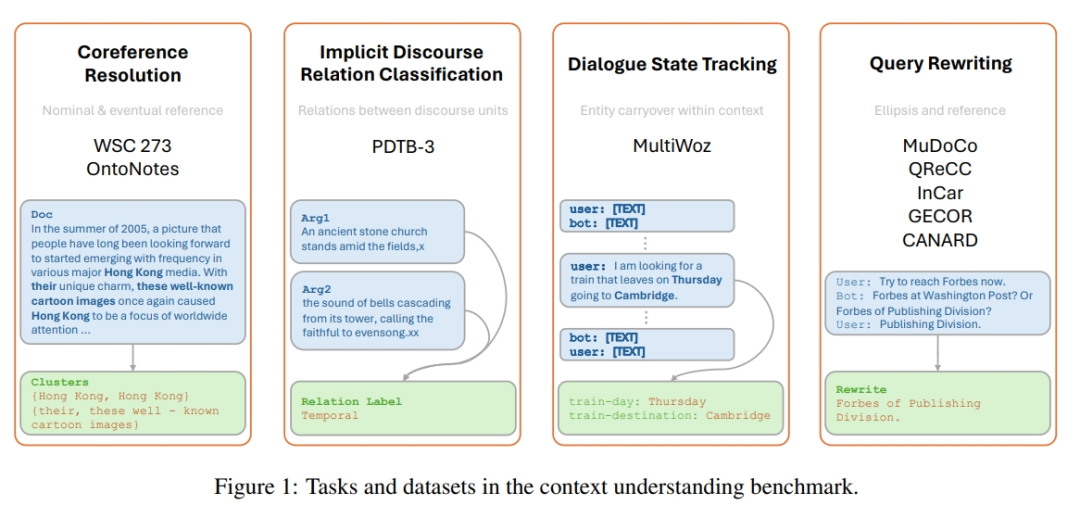
5.苹果最新研究:大模型能理解上下文吗?
苹果研究团队通过对现有数据集进行调整,提出了一个上下文理解基准,从而适应生成模型的评估。该基准包括四项不同的任务和九个数据集,所有提示都旨在评估模型理解上下文的能力。实验结果表明,与最先进的微调模型相比,预训练的密集模型在理解更细微的上下文特征方面存在困难。
论文链接:
https://arxiv.org/abs/2402.00858
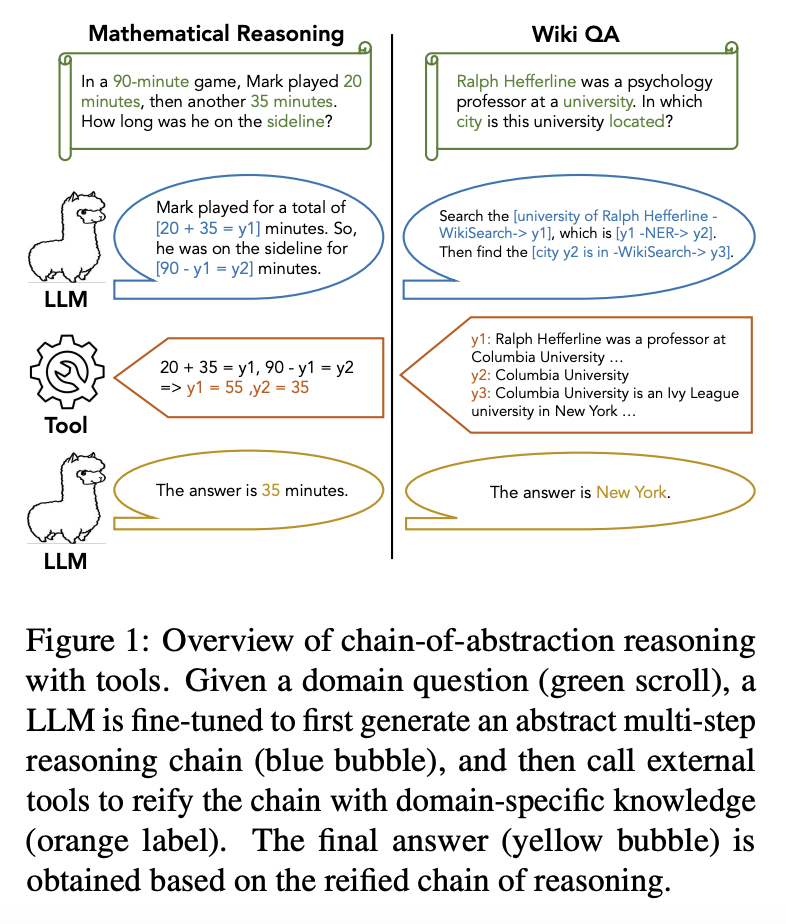
6.Meta提出CoA:让大模型高效使用工具
为使大型语言模型(LLMs)在多步骤推理中更好地利用工具,Meta 研究团队提出了抽象链(Chain-of-Abstraction,CoA)。它训练 LLMs 用抽象占位符解码推理链、调用领域工具,通过填充特定知识来具体化每个推理链。这种利用抽象链进行的规划使 LLMs 能够学习更多通用推理策略,同时允许 LLMs 并行执行解码和调用外部工具,从而避免了因等待工具响应而造成的推理延迟。
论文链接:
https://arxiv.org/abs/2401.17464
7.首个触觉大模型UniTouch:利用触觉进行多模态学习
来自耶鲁大学和密歇根大学的研究团队提出了一个统一的触觉模型 UniTouch,适用于与视觉、语言和声音等多种模态相连的基于视觉的触摸传感器。从机器人抓取预测到触摸图像问答,UniTouch 能够在零样本环境下执行各种触觉感知任务,是首个展示出这种能力的模型。

论文链接:
https://arxiv.org/abs/2401.18084
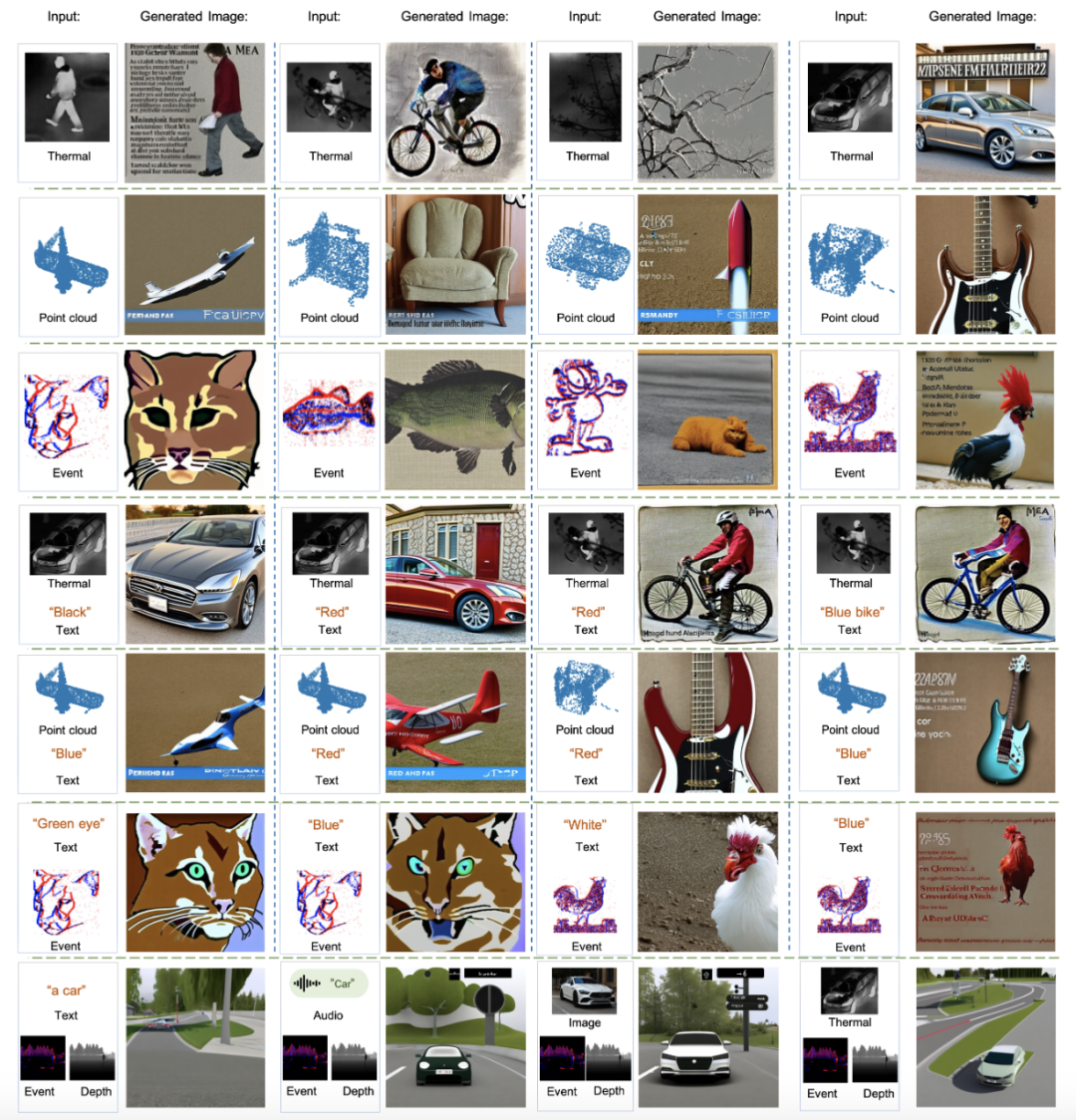
8.Image Anything:七种模态任意组合,像人类一样想象画面
人类感知和理解力的多面性表明,当我们思考时,我们的身体可以自然地将任何感官(又称模式)组合起来,在大脑中形成一幅美丽的图画。来自香港科技大学的研究团队提出了一种端到端多模态生成模型——ImgAny,它可以模仿人类推理并生成高质量的图像。该项研究受到人类认知过程的启发,无需对不同模态进行特定微调即可在实体和属性层面整合和协调多个输入模态。
论文链接:
https://arxiv.org/abs/2401.17664
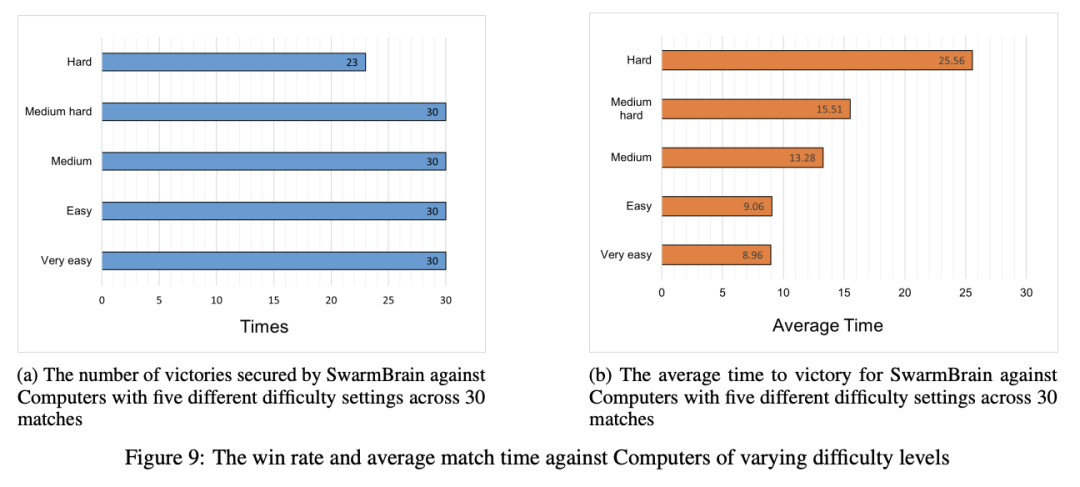
9.让大模型帮你打《星际争霸II》
为研究大型语言模型(LLMs)在 StarCraft II(《星际争霸II》)游戏环境中执行实时战略战争任务的能力,来自宝马诚迈公司的研究团队提出了一种利用 LLMs 在 StarCraft II 游戏环境中执行实时战略的嵌入式智能体——SwarmBrain。它能够进行经济扩张、领土扩张和战术制定,并且能够击败设置在不同难度级别的电脑玩家。
论文链接:
https://arxiv.org/abs/2401.17749
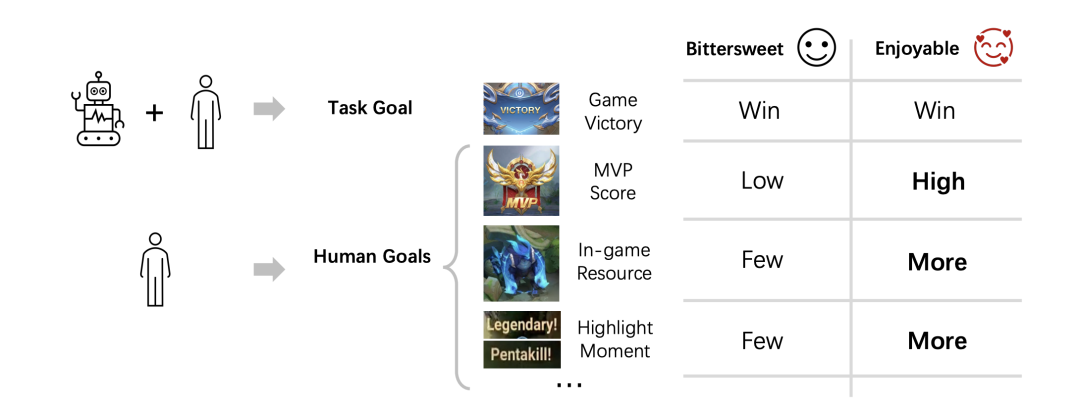
10.欢迎来到王者荣耀:AI 让你“开心地输”
为了提升人们的游戏体验,来自腾讯人工智能实验室和天美 L1 工作室的研究团队,提出了一个“以人为中心”的合作智能体建模方案。该方案能够使智能体在保持原有能力(如赢得游戏)的同时提升玩家的游戏体验。研究团队提出了“从人类收益中强化学习”(Reinforcement Learning from Human Gain,RLHG)方法。RLHG 方法引入了一个“基线”,与人类原始实现目标的程度相对应,并鼓励代理学习能有效提高人类实现目标的行为。
论文链接:
https://arxiv.org/abs/2401.16444
11.AudioSeal:首个用于AI生成语音的音频水印技术
来自 Meta、法国国立计算机及自动化研究院(Inria)和 Kyutai 实验室的研究团队提出了第一项专门为人工智能生成语音的局部检测而设计的音频水印技术——AudioSeal。它在现实音频处理的鲁棒性和不可察觉性方面达到了最先进的性能。

论文链接:
https://arxiv.org/abs/2401.17264
12.DressCode:根据文本提示为数字人设计服装
来自上海科技大学、宾夕法尼亚大学和影眸科技的研究团队提出了一个文本驱动的 3D 服装生成框架——DressCode,它能够帮助新手进行服装设计,同时为时装设计、虚拟试穿和数字人形创作方向提供了巨大潜力。


论文链接:
https://arxiv.org/abs/2401.16465
13.Mobile-Agent:自主操作APP的移动端智能体
来自北京交通大学和阿里巴巴集团的研究团队提出了一个自主的多模态移动设备智能体—— Mobile-Agent。Mobile-Agent 具备很高的准确性和完成率。即使面对具有挑战性的指令(如多 APP 操作),Mobile-Agent依然可以完成要求。
论文链接:
https://arxiv.org/abs/2401.16158
14.Diffuse to Choose:使用扩散模型优化在线购物中的“虚拟试用”
亚马逊公司提出了一种基于扩散的图像条件修复模型——Diffuse to Choose。它能够将参考图像的细微特征直接融入主扩散模型的潜在特征图中,并通过感知损失以进一步保留参考图像的细节。
论文链接:
https://arxiv.org/abs/2401.13795
15.Google Deepmind:使用大模型生成具有表现力的机器人行为
来自多伦多大学、Google Deepmind 和 Hoku Labs 的研究团队提出利用大型语言模型(LLMs)提供的丰富社交上下文及其根据指令或用户偏好生成动作的能力,来生成可适应、可组合、具有表现力的机器人运动。

论文链接:
https://arxiv.org/abs/2401.14673
|点击关注我 👇 记得标星|
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢