
多模态表征学习|COOT:用于视频-文本表征学习的协作式分层次Transformer(NeurIPS 2020)
【论文标题】COOT: Cooperative Hierarchical Transformer for Video-Text Representation Learning
【多模态表征学习】COOT:用于视频-文本表征学习的协作式分层次Transformer(NeurIPS 2020)
【论坛网址】https://hub.baai.ac.cn/view/3491
【作者团队】Simon Ging, Mohammadreza Zolfaghari, Hamed Pirsiavash, Thomas Brox
【发表时间】2020/11/1
【代码链接】https://github.com/gingsi/coot-videotext
【论文链接】https://arxiv.org/abs/2011.00597
【推荐理由】
本文收录于NeurIPS 2020会议,来自弗莱堡大学和马里兰大学巴蒂尔摩县分校的研究人员提出一种协作式分层次Transformer(COOT),以利用分层信息为不同级别粒度和不同模式之间的交互建模。
许多现实世界中的视频文本任务涉及不同级别的粒度信息,例如帧和单词,片段和句子或视频和段落,每个都有不同级别的语义,然而现有的表征学习并不能充分的学习到这些细粒度语语义信息,从而没有充分利用大量的数据信息去学习更好的联合表示,没能将视频文本在长范围时间的特征进行关联。
本文着重研究这种长范围时间依赖性问题,提出一种协作式分层次Transformer(COOL),可以利用视频和文本中的长范围时间上下文信息学习跨模态联合表示特征。COOL模型包括三个重要组成部分(如图):
(1) 注意意识特征聚合层(建模联合同粒度信息):用以关注底层实体之间的时间交互。
(2)上下文注意力模块(建模联合跨粒度信息):强制网络突出与视频的一般上下文相关语义,用以学习低级和高级语义之间的交互。(例如视频和段落的交互)
(3)跨模态循环一致性损失函数:强制两个域产生一致的表示形式,促进在联合表示空间中视觉和文本特征之间的语义对齐。(例如连接视频和文本信息)
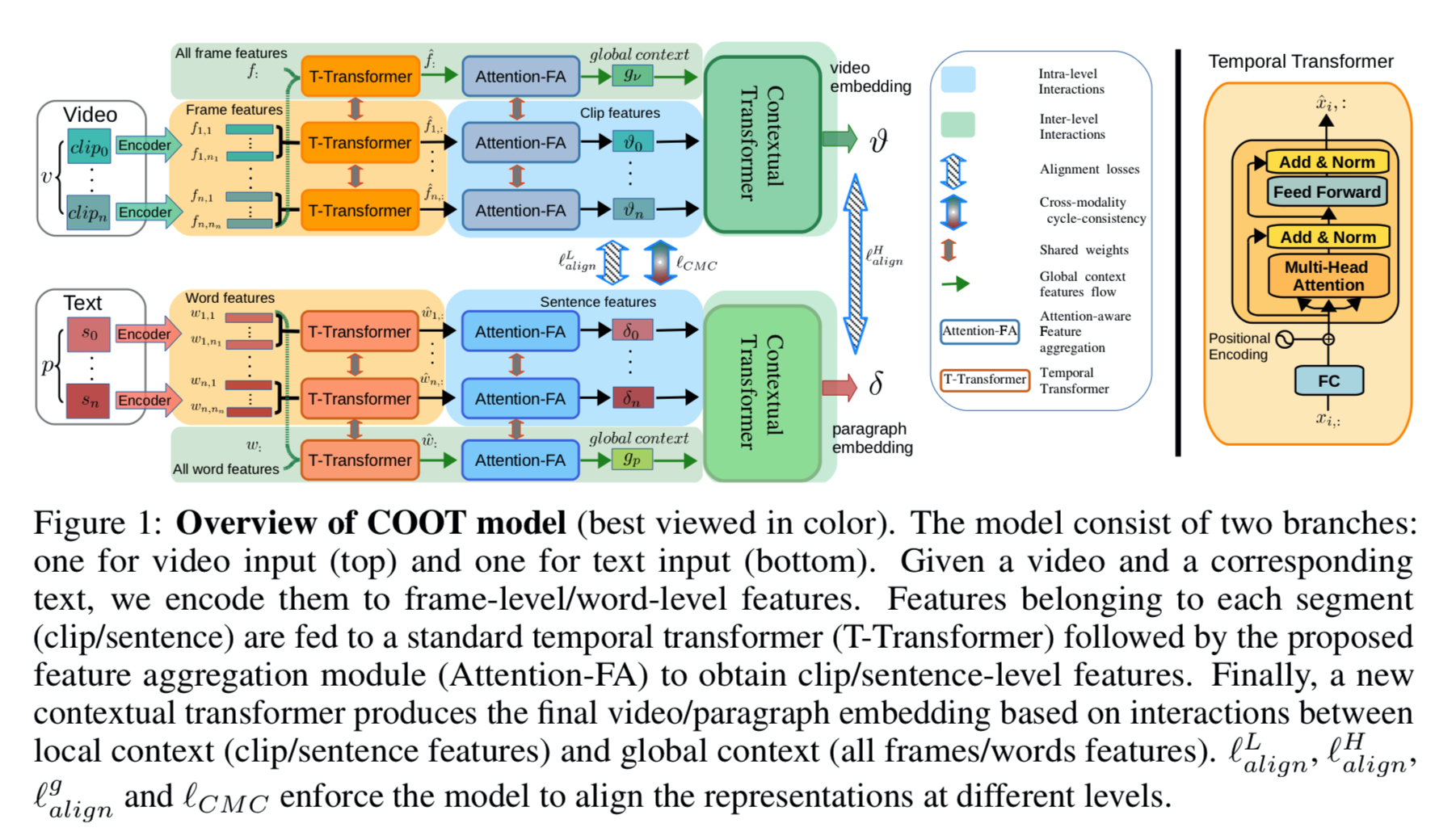 最后,本文方法在视频文本检索和描述任务上都取得了最佳性能的效果,进一步说明了方法的有效性。
最后,本文方法在视频文本检索和描述任务上都取得了最佳性能的效果,进一步说明了方法的有效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢