
今天为大家介绍的是来自Roger M. Howard和Alpha A. Lee团队的一篇论文。高通量实验是一种可以系统地研究不同化学空间中反应活性的方法。目前该领域主要挑战是缺乏大规模的公开数据集,以及需要更简便的方法来解读这些数据中隐藏的化学洞见。为此作者提出了一个新开发的高通量实验分析器,这是一个健壮且统计上严谨的框架。它适用于任何规模和范围的HTE数据集,无论其目标反应结果如何。这个分析器能够揭示起始物料、试剂和反应结果之间的可解释相关性。

近年来数据驱动化学领域巨大进步。这种进步的一个主要原因是采用了高通量实验(HTE)数据在化学合成中的应用。实际应用中的HTE数据集有几个有益的特点:它们可能已经探索了对该领域直接感兴趣的反应空间,并涵盖了广泛的底物和反应类型,确保了数据驱动发现的相关性。此外,这些数据集中还包含了有价值的负面数据。这些数据可能以利于未来HTE引导合成的方式收集,有助于发现的转化应用。然而,这种方法也有其挑战。例如,产量计算通常是基于未经校准的紫外吸收比率得出的,这假设产物具有类似的紫外线消光系数,使得这种测量更倾向于定性而非定量核磁共振光谱学或隔离产量测定。此外,副产品的存在或不存在可能也有些模糊,以及数据集可能在试剂和反应条件的选择上存在偏见,并且在某些区域数据稀缺。
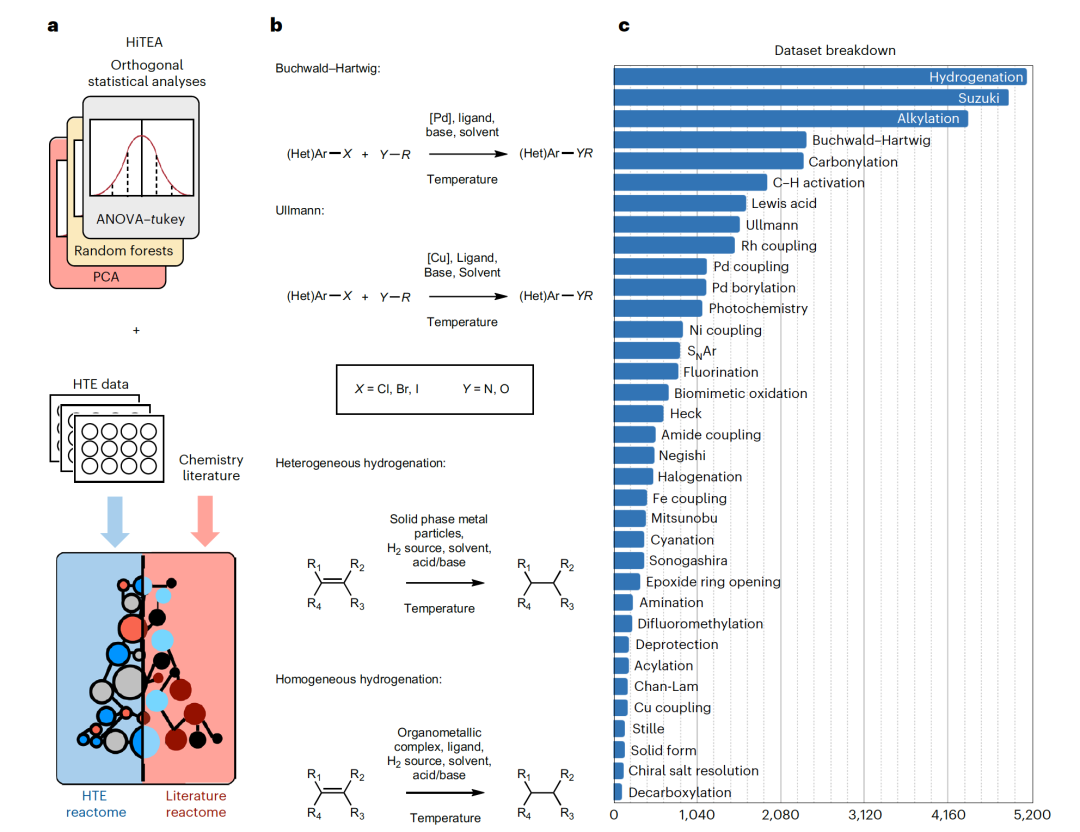
图 1
尽管存在这些已知的HTE数据挑战,但目前鲜有工作对这些数据集的固有结构和偏差进行研究。应用于任何HTE数据集以提取隐藏的化学洞见的统计上健壮的方法对于推动数据驱动化学至关重要。重要的是要注意,这种统计框架并不是为了预测或概括任何特定的反应属性,而是为了提供更基本的分析:数据集中有哪些化学洞见?从这些结论中,我们可以开始理解:(1)哪些统计上重要的因素驱动了好的或坏的结果;(2)这些数据将教给人工智能(AI)模型什么。最后,通过比较在HTE数据中获得的化学洞见,即“HTE反应组”,与从文献中得出的化学洞见,即“文献的反应组”,可能(1)提供进一步的证据支持机理假设(反应组的一致性),(2)揭示数据集中的偏差,限制了其有效性,或(3)揭示可能导致我们化学理解的细微关联(反应组的不一致)(见图1a)。在这篇文章中,“文献”被定义为来自开源化学数据库和已发表在同行评审期刊的文献信息,不包括HTE数据。
为了创建这样一种方法,作者们开发了一种高通量实验分析器(HiTEA),它可以推断出任何HTE数据集的反应组。虽然像CAS、Reaxys、USPTO、Pistachio或Open Reaction Database这样的常见化学数据集具有令人印象深刻的覆盖范围,但这些数据集与文献数据之间高度重叠的问题引起了关注。这可能导致这些数据集的反应组与文献反应组无法区分,使得探索数据和文献反应组之间的差异变得困难,而这正是利用HTE数据集和HiTEA进行研究的一个基本特点。
HiTEA:高通量实验统计分析器
HiTEA(高通量实验分析器)的方法论是围绕三个正交的统计分析框架构建的:随机森林、Z分数方差分析(ANOVA-Tukey)和主成分分析(PCA)。每个框架回答以下一个问题:哪些变量是重要的?即随机森林分析;哪些试剂在统计上是最佳/最差类别的?即Z分数-ANOVA-Tukey分析;以及这些最佳/最差类别的试剂如何分布在化学空间中?即PCA分析。值得注意的是,这种统计分析的组合不对底层数据结构做任何假设。例如,关系可以是非线性的,甚至是不连续的,数据不需要是所有试剂与所有反应物的完全组合交叉,这在考虑化学数据集稀疏性时是一个重要特征,而且较小的数据集与较大的数据集同样可行。这三个HiTEA分支的协同作用为理解一个数据集的反应组提供了易于理解的视角,使得隐藏的化学洞见的识别变得容易。为了突出HiTEA的灵活性和多功能性,作者分析了涵盖超过3000个反应的数据集,这些数据集涵盖了广泛的底物范围,以及仅包含1000多个反应且底物范围更窄的数据集。
哪些变量是重要的
直观上,一些反应对某些变量比其他变量更敏感。例如,交叉偶联反应对金属及其配体的敏感性很高,但通常对溶剂的具体类型不那么敏感。理解哪些变量在反应组中的重要性对于洞悉化学反应至关重要。需要注意的是,变量的重要性可能与反应结果呈正相关或负相关。在研究变量重要性时,随机森林和多元线性回归这两种技术被广泛认可。这两种方法在化学和其他领域都取得了令人印象深刻的结果;然而,对于HiTEA作者选择使用随机森林。与多元线性回归不同的是,随机森林不要求数据必须是线性的,因此避免了线性化的需要。考虑到数据的非线性特点,研究者假设随机森林将提供更准确的变量重要性。一般来说,使用标准超参数的随机森林对反应结果的预测精度从中等到良好。为了评估变量重要性的置信度,对每个数据集子类进行了方差分析(ANOVA),并将变量的统计显著性设定在P = 0.05。
哪些试剂在统计上是最佳/最差类别
已知某些试剂在多种反应中普遍表现良好,而另一些试剂的应用范围较窄。因此,识别最佳和最差类别的试剂是理解反应组的关键。然而,将试剂的影响从反应物的固有反应性中区分出来是具有挑战性的。研究者选择通过Z分数进行标准化来比较相对产量,这是一种在高通量实验(HTE)数据分析中显示出前景的技术。对标准化的目标反应结果进行方差分析(ANOVA)可以揭示对该反应结果统计上相关的广泛变量(如溶剂、碱、催化剂系统和温度等)。然后使用显著差异测试来识别每个统计上显著的变量中的异常值,这些异常值随后通过平均Z分数进行排名,以确定最佳和最差类别的试剂。
最佳/最差类别的试剂如何分布在化学空间中
试剂的各种特性可以通过可视化更容易地解读。作者选择使用主成分分析(PCA),因为它的实用性已被广泛认可,且存在许多可靠且用户友好的实现。此外,与UMAP或t-SNE等方法相比,PCA更易于解释。UMAP和t-SNE由于其非线性特性,在投影过程中需要扭曲数据的高维形状,这使得投影的xy轴失去了易于解释的最高方差(x轴)/第二高方差(y轴)的特点,而这正是PCA的基本要素。
测试HiTEA
为了测试HiTEA,作者选择了四个不同的反应组进行探索。这些反应组是广泛使用的反应类别:Buchwald-Hartwig偶联、Ullmann偶联、非均相氢化和均相氢化(图1b)。通过生成的反应组,对HiTEA提供的变量重要性、统计上显著的最佳/最差碱和催化剂,以及试剂分布进行了仔细分析,并最终提出了针对性的进一步研究建议。
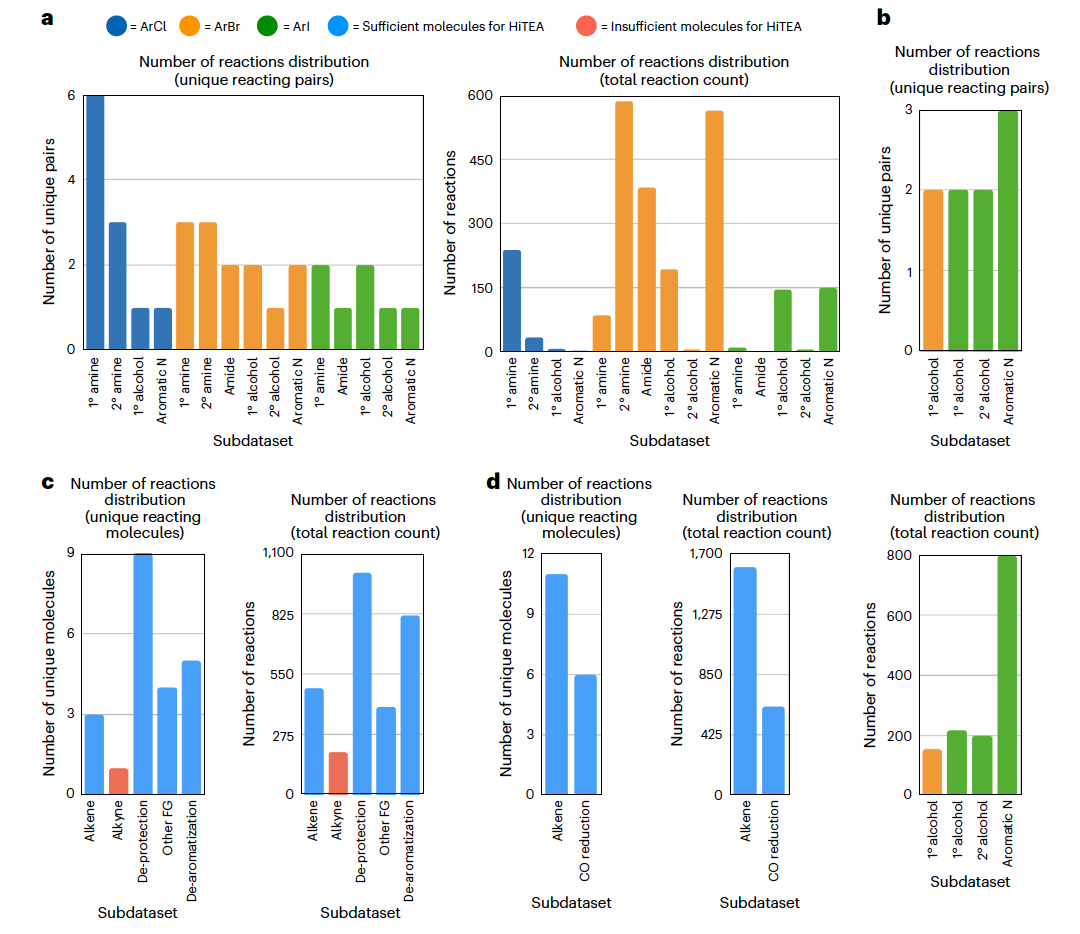
图 2
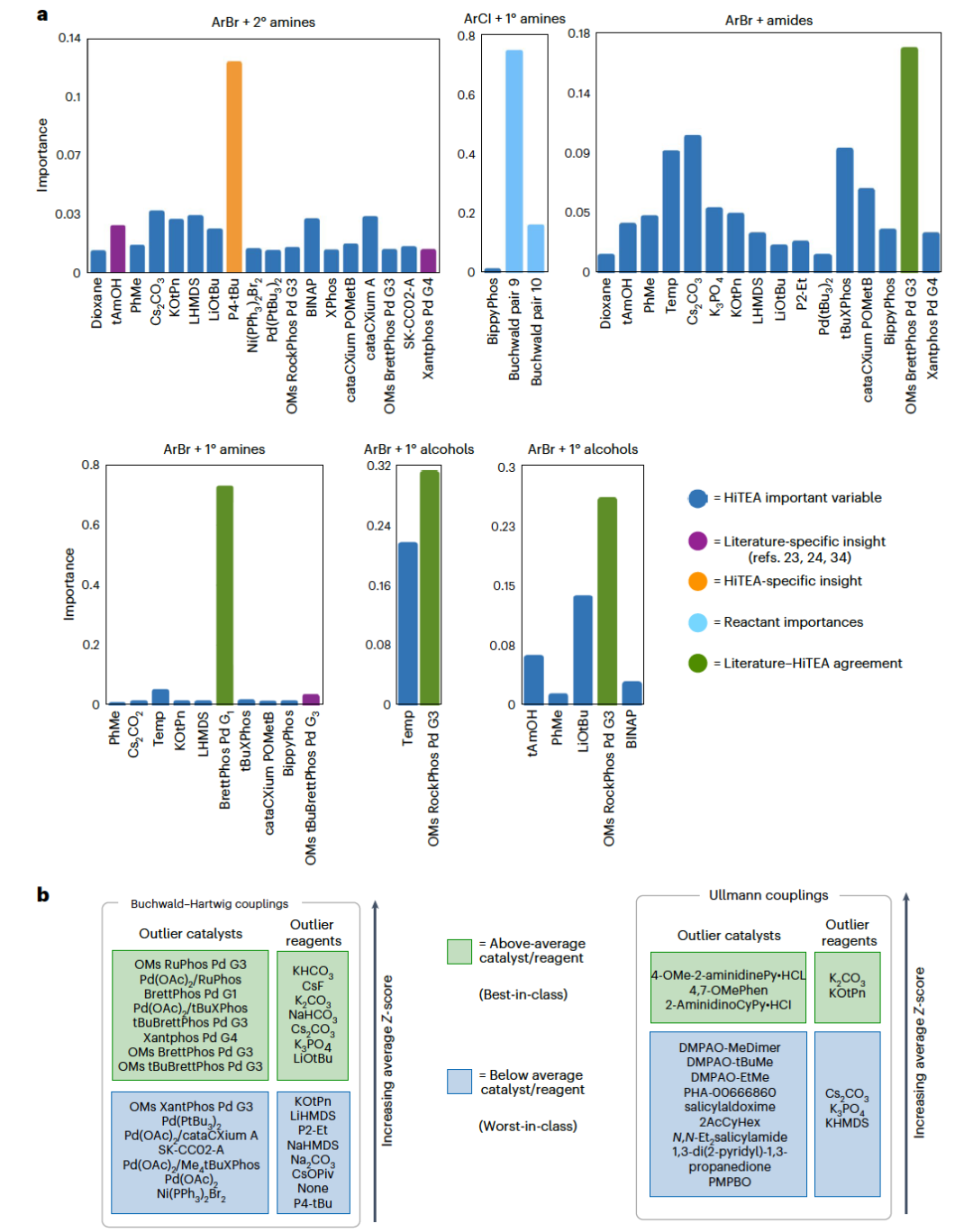
图 3
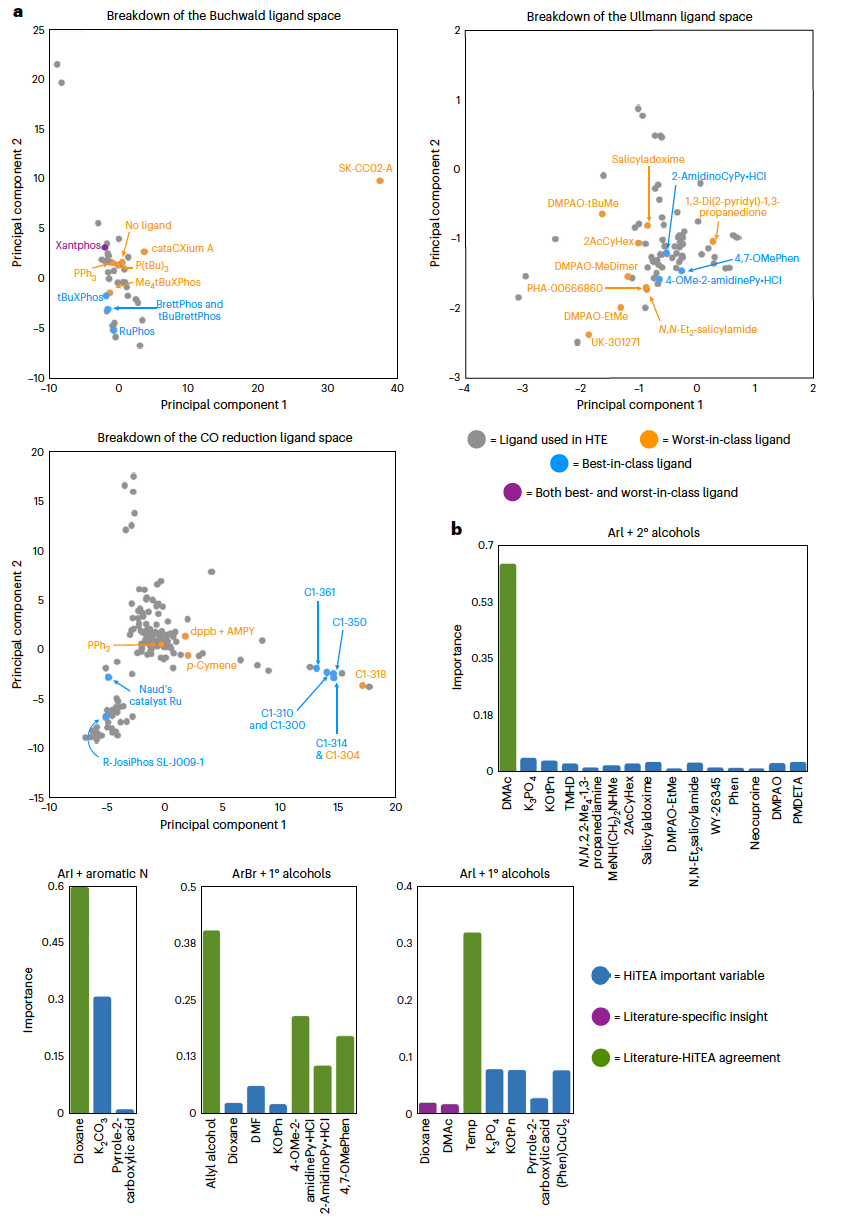
图 4
Buchwald-Hartwig偶联反应
Buchwald-Hartwig偶联反应依赖于配体的电子特性和空间阻碍,且该数据集在催化剂和配体方面多样性丰富,但在偶联伙伴方面的多样性较低。该反应组是分析中最大的,包含约3000个反应。数据集包含31种独特的卤化物和32种独特的亲核试剂,涵盖了胺、酰胺、芳香族氮和醇类亲核试剂,以及29种独特的反应卤化物-亲核试剂对。有趣的是,亲核试剂的多样性不如芳卤化物。研究还发现,芳基溴化物占据了大部分反应,无论是在独特的反应对的数量还是在总反应数量上(图2a)。没有考虑这种过度代表性的HiTEA对Buchwald-Hartwig数据集的分析将揭示以芳基溴化物偶联为中心的HTE反应组。实际上,HiTEA确实给予了BrettPhos Pd G1高变量重要性。然而,这与文献中的反应组不一致,在文献中许多配体的表现与BrettPhos相同或更好。因此,如果将HiTEA应用于子数据集(例如ArBr + 1°胺,ArCl + 1°胺等),以确定它们的子反应组,则可能会产生更细致的分析。
在ArBr + 1°胺的子数据集中,文献先例表明,依赖于笨重的双芳香族膦配体,这些配体可以抑制非生产性的β-氢消除途径并优先进行还原消除,因此预计BrettPhos配体将在该反应组的变量重要性中占据主导地位。实际上BrettPhos Pd G1是这个子数据集中最重要的变量。令人惊讶的是,更笨重的t-BuBrettPhos并未成为最重要的变量。在ArBr + 2°胺(三个独特的反应对)的子数据集中,P4-t-Bu(一种膦嗪碱)的存在表现出负依赖性,尽管它在交叉偶联反应中有已知应用,但对这个子数据集普遍不利。另一种膦嗪碱,P2-Et,也被HiTEA评为表现较差(图3b)。最近对标准Buchwald-Hartwig条件的系统性研究指出,P2-Et的表现不如其他碱。对于ArBr和ArI + 1°醇(都有两个独特的反应对),以及ArBr + 酰胺(两个独特的反应对),预计具有刚性骨架和空间阻碍的配体将会占据主导地位,这些配体促进更容易的还原消除并防止有害的K2-酰胺络合物的形成,尽管由于这两个反应类别的随机森林准确率较低。最后,作者转向ArCl + 1°胺偶联(六个独特的反应对)。文献报告称,富电子配体可以促进Ar-Cl键的氧化加成,而笨重的骨架可以限制已知的β-氢消除途径。然而,HTE子反应组中只有Pd(OAc)2/BippyPhos作为一个次要重要的变量。进一步分析发现,对底物身份的高度依赖性表明,对于这个子反应组而言,最重要的因素是反应卤化物-亲核试剂对。
总的来说,最佳/最差催化剂符合化学直觉,如上所述,并且在配体PCA可视化中也清晰地聚集(图4a)。最佳类别和最差类别配体聚集之间的鲜明区别很明显,而Xantphos这一单一配体,根据所用前催化剂的不同,可能属于最佳或最差类别,远离其他配体。许多子反应组也与文献的反应组一致,但有几个有趣的点较为突出。首先,ArCl + 1°胺反应组与文献的不同。虽然ArCl + 1°胺的产率在某种程度上取决于它们的反应物结构,但重要配体的缺乏和反应物身份的主导表明,这个数据集可能存在一些底物选择偏差。通过扩大筛选的亲核试剂多样性,可以更清晰地了解ArCl + 1°胺的反应组。其次是在ArBr + 1°胺的反应组中t-BuBrettPhos的重要性较小。这可能是由于与子数据集中的其他催化剂相比,t-BuBrettPhos的使用频率较低。在使用t-BuBrettPhos的情况下,它是与不容易反应的底物一起使用的(这也是为什么它被认为是最佳类别配体,根据Z分数-ANOVA-Tukey分析)。在未来的筛选中,更频繁地使用t-BuBrettPhos可能有助于进一步调查这一点。
Ullmann偶联
近年来Ullmann这类无钯交叉偶联反应变得越来越受欢迎。特别是Ullmann偶联反应,对于芳基溴/碘和亲核试剂的交叉偶联来说,是一个可行的选择。Ullmann数据集的范围和规模相比于Buchwald-Hartwig数据集更为有限,大约是后者的一半大小;然而,即使在这个较小的空间中,HiTEA也同样适用。与Buchwald-Hartwig数据集不同的是,后者包含了一个“广泛但浅薄”的底物空间采样,而Ullmann反应则是“狭窄但深入”的,尽管子数据集较少,但每个子数据集的总反应数量较高(图2b)。Ullmann数据集包含了九个独特的卤化物-亲核试剂对,芳基卤化物和亲核试剂都具有良好的多样性,尽管每个种类的数量有限。HiTEA揭示了HTE子反应组,能够轻松区分溶剂的细微差别。总体而言,可以观察到溶剂的重要性很高。例如,在ArI + 芳香族氮(三个独特的反应对)和ArI + 2°醇(两个独特的反应对)的偶联反应中,分别偏好二噁烷和DMAc。对于ArBr + 1°醇的反应组(两个独特的反应对),这两种溶剂被显示为不那么重要。实际上,重要的溶剂,丙烯醇,也是这些偶联反应中的亲核试剂。在这个子反应组中,配体的身份在产量确定中扮演了重要角色。最后,对于ArI + 1°醇的反应组,反应温度是一个主要因素。本来也预期会在其他三个子反应组中看到温度的一些重要性,但由于HTE的设计,整个子反应组中温度几乎保持不变,因此消除了温度作为一个变量。
氢化
异质氢化反应的样本空间方式是“广泛但浅薄”,而均质氢化反应则是“狭窄但深入”。对于异质和均质氢化反应,所涉及的分子种类都相当广泛(图2cd)。HiTEA揭示了异质烯烃子反应组(三个独特的反应物)对锌粉的负面重要性很高,而对于HTE去保护基子反应组(九个独特的反应物),温度的正面重要性很高。虽然与温度相关的去保护基反应与文献的反应组相符,但与锌粉的负相关性则是HiTEA特有的洞见。这凸显了数据集中负结果的价值,它使HiTEA能够确认负相关性。由于缺乏包含必要负数据的出版物,文献的反应组通常无法确认这种相关性。有趣的是,其他三个子反应组没有突出的变量。在均质氢化反应(11个独特的反应物)的情况下,这可以归因于对反应物的强依赖,但脱芳香化(五个独特的反应物)显示出对任何变量,包括分子身份的总体依赖性很小,这可能是由于支配脱芳香化这一能量密集过程的多样性和微妙变化。对于这三个子数据集,HiTEA的最佳/最差反应类型分析揭示了更多信息。
深入反应机理
反应机理的深入理解十分重要,特别是在反应优化和开发新反应及催化剂的过程中十分有帮助。然而,许多反应机理尤其是那些涉及有机金属过渡态的反应机理,目前只有部分被阐明。HiTEA可以识别反应输入和测量反应结果之间的隐藏相关性,为机理假设提供统计上的有力证据。在研究过程中,作者发现溶剂在Ullmann偶联反应的产率中扮演了重要角色;然而,与Buchwald偶联反应不同的是,溶剂极性对于潜在的卤原子转移/单电子转移催化剂中间体的影响尚未被阐明。由于HiTEA即使在数据较少的环境中也设计为适用,因此它在探究其他具有有限筛选的反应机理中具有潜在的实用价值。
编译 | 曾全晨
审稿 | 王建民
参考资料
King-Smith, E., Berritt, S., Bernier, L. et al. Probing the chemical ‘reactome’ with high-throughput experimentation data. Nat. Chem. (2024).
https://doi.org/10.1038/s41557-023-01393-w
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢