
模型背景与应用
模型和相关链接
技术亮点
Weak-to-strong 策略:以小教大,以弱引强
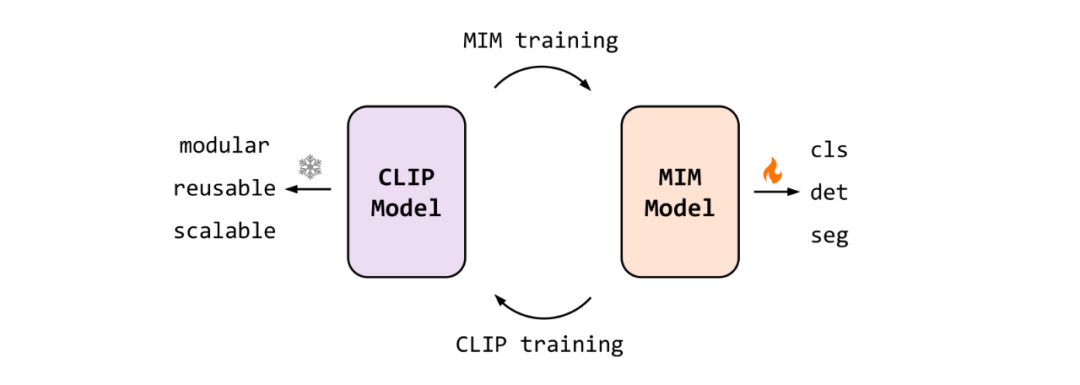
更高的训练效率
有限数据规模下的无限潜力
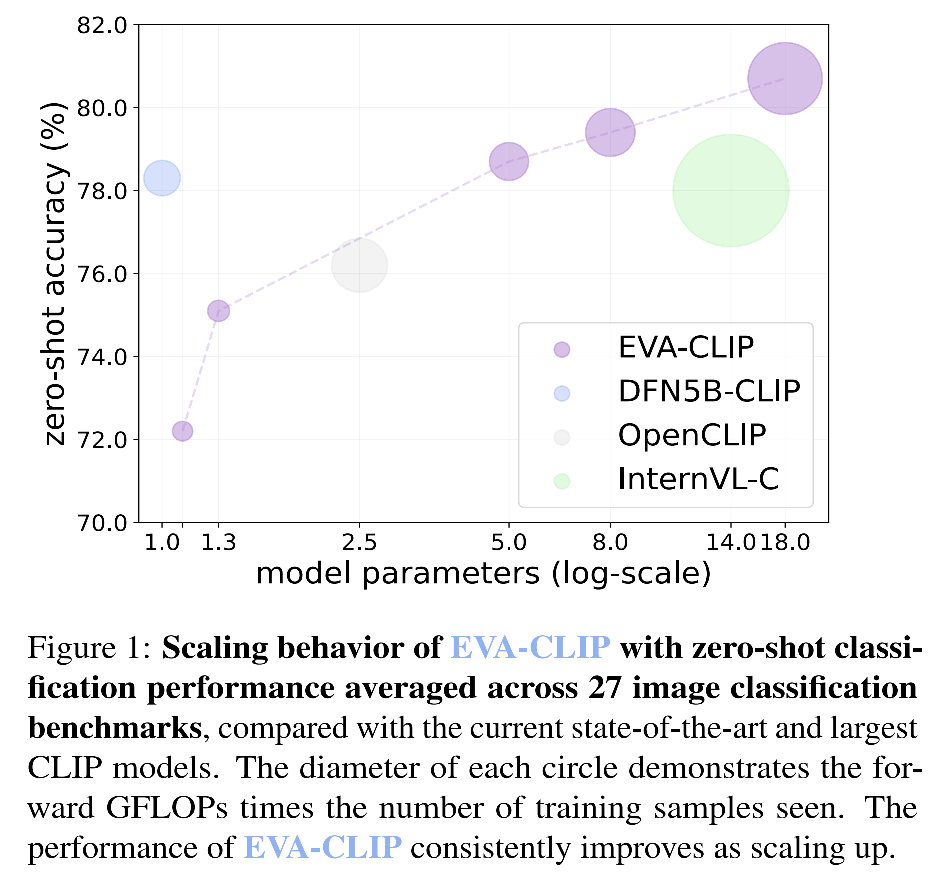
全方位最强性能的 CLIP 模型
 EVA-CLIP零样本图片分类性能
EVA-CLIP零样本图片分类性能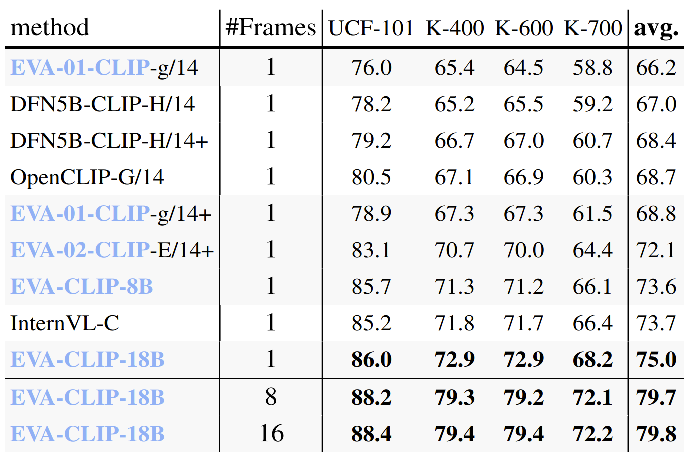 EVA-CLIP零样本视频分类性能
EVA-CLIP零样本视频分类性能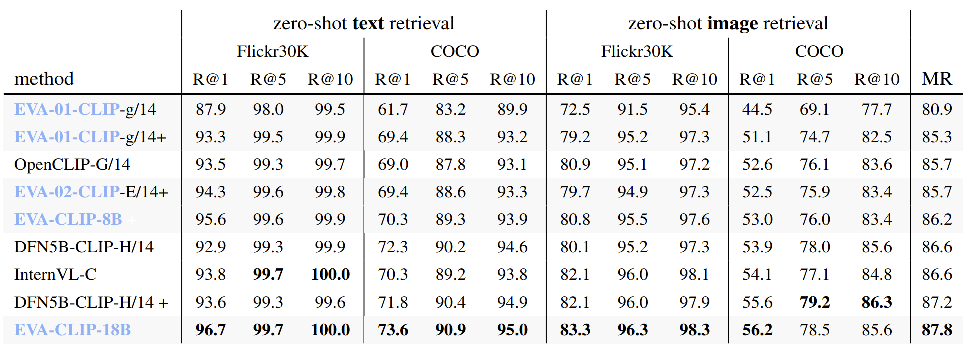 EVA-CLIP零样本图文检索性能
EVA-CLIP零样本图文检索性能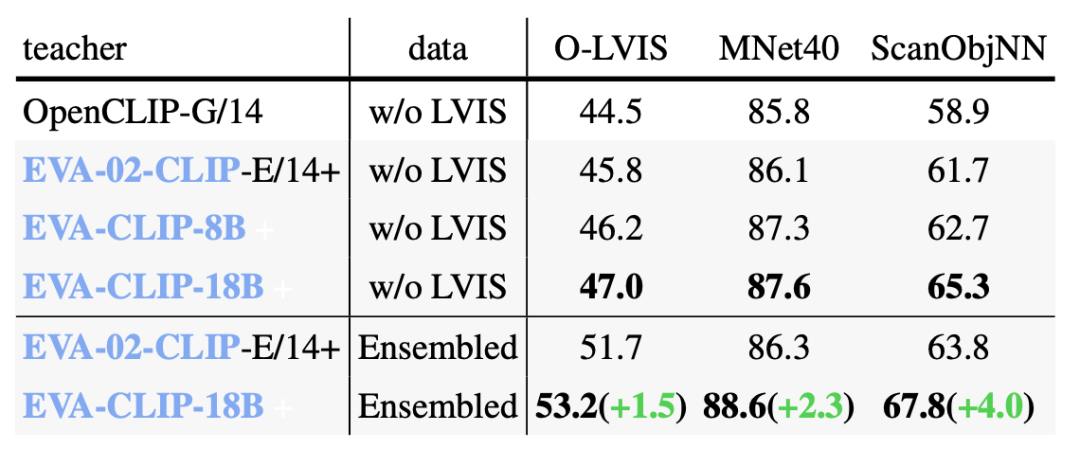 EVA-CLIP模型增强零样本3D分类的性能
EVA-CLIP模型增强零样本3D分类的性能内容中包含的图片若涉及版权问题,请及时与我们联系删除
 EVA-CLIP零样本图片分类性能EVA-CLIP零样本视频分类性能EVA-CLIP零样本图文检索性能EVA-CLIP模型增强零样本3D分类的性能
EVA-CLIP零样本图片分类性能EVA-CLIP零样本视频分类性能EVA-CLIP零样本图文检索性能EVA-CLIP模型增强零样本3D分类的性能内容中包含的图片若涉及版权问题,请及时与我们联系删除
沙发等你来抢


评论
沙发等你来抢