
2023年11月2日,华南理工大学王领老师团队在Briefings in Bioinformatics上发表文章FG-BERT: a generalized and self-supervised functional group-based molecular representation learning framework for properties prediction。

作者提出了基于官能团信息的分子BERT语言模型(functional group-based BERT,FG-BERT),以自然语言处理中的通用自监督预训练语言模型BERT为基础,学习分子的有意义表示。实验证明了FG-BERT在预测分子性质方面的高性能。此外,FG-BERT利用注意力机制将注意力集中在对目标属性更重要的官能团特征上,从而为下游训练任务提供了出色的可解释性,为开发用于各种分子(特别是药物)发现任务的模型提供了一个易用的框架。
背景
分子性质的准确预测对于功能分子的设计和发现具有重要意义,特别是对于药物分子的发现,因为它可以在药物发现过程的早期快速识别具有理想性质的活性分子和过滤掉不合适的分子。传统的机器学习模型在很大程度上取决于如何选择合适的分子表示。为了解决这一问题,研究者们采用深度学习中的预训练模型进行分子表示学习,通过设置预训练和微调策略,从大量未标记的数据中学习有用的分子表示,然后将知识迁移到下游任务中进行分子性质预测。然而,现有的预训练模型没有关注分子结构中重要的官能团信息。
方法
FG-BERT是在BERT模型的基础上设计的。作者从ChEMBL中收集初始未标记的分子数据集(约213万个分子),然后通过分子量≤500、ClogP≤5和氢键供体数≤5这三个类药性质原则进行筛选。最终得到约145万个分子的分子语料库,然后将其按9:1的比例随机分为训练集和测试集。预训练任务是对分子进行随机掩膜,并预测其被掩膜的部分。接着,在分子性质预测的数据集上微调模型。
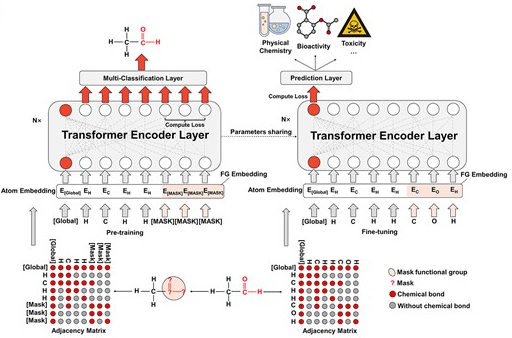
图1 FG-BERT结构图
如图1所示,FG-BERT框架由三部分组成:分子图表示层、Transformer层和预测层。对于输入模型的每个分子,添加一个连接所有官能团和原子的超级节点,并根据化学键关系将SMILES格式的分子转换为分子图。为了方便地在分子图中表示原子和官能团,作者基于在预训练的分子语料库中出现的各种原子的频率构造了一个原子字典。FG-BERT使用的预训练数据集统计显示,出现次数超过1000次的原子有14种,用各自的元素符号表示,而其他原子出现次数小于1000次,统称为[UNK]来表示。在分子图中增加的超级节点用[GLOBAL]表示,被掩膜的部分用[MASK]来表示。由于官能团通常由多个原子组成,因此当其被掩膜时,通常会有多个原子为[MASK]。因此,作者构建了一个随机选择的官能团列表,并使用该列表来识别需要屏蔽的官能团,而未选择的官能团保持不变。因此,字典包括以下14种元素:[H], [C], [N], [O], [S], [F], [Cl], [Br], [P], [I], [Na], [B], [Se], [Si],以及[UNK], [MASK]和[GLOBAL],共17种标签。
分子图Transformer将通过以上字典编码后的分子特征作为输入,通过图神经网络(GNN)中的图注意力机制得到分子表示向量,每个节点使用多头注意力机制来聚合来自相邻节点的信息。为了解决普通GNN中的过平滑问题,FG-BERT使用与Transformer相同的残差连接和层归一化机制。最终,将超级节点上的表示向量作为整个分子图的表示向量。
在BERT的启发下,本研究中提出的预训练策略与BERT相似,在一个分子中随机选择15%的官能团进行掩模,对于只有少量几个官能团的分子,至少选择一个来进行掩膜。在BERT中,被选择作为掩膜的部分有80%的概率被[MASK]取代,有10%的概率被随机序列取代,有10%的概率未被取代。与BERT不同的是,FG-BERT未进行随机取代的操作,因为与自然语言序列不同,如果在分子的官能团上进行随机取代,可能会导致许多不符合化学规则的情况发生。因此,作者设置所选择的官能团有90%的概率被[MASK]取代,有10%的概率未被取代。
模型通过批处理梯度下降算法和Adam优化器上进行训练。将学习率设为0.0001,每批数据的大小设为16。为了评估FG-BERT预训练的性能,将掩膜部分的预测序列与原始序列间的交叉熵损失函数作为评价指标。在微调阶段,将预训练模型的参数固定,并在与超级节点对应的Transformer编码器上添加两层全连接神经网络,称为预测层,以输出预测的结果。
结果
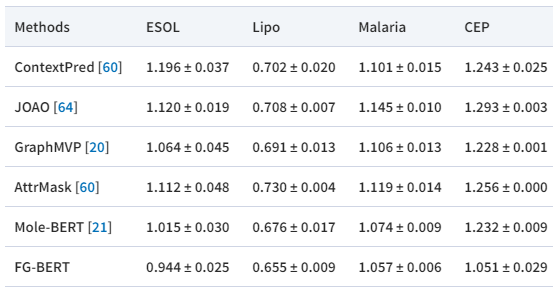
作者将FG-BERT与一些具有代表性的方法进行了比较,如表1所示,使用RMSE作为评价指标。在所有四个数据集上,FG-BERT的RMSE均低于现有方法,表示模型的误差较低,预测更为准确。且FG-BERT具有较低的标准差,鲁棒性较强。
表1 与其他方法对比
作者设计了消融实验,为了证明官能团掩膜用于预训练的有效性,将FG-BERT与MG-BERT进行了比较。MG-BERT是用随机掩膜原子进行预训练的。如图4A和B所示,FG-BERT的预测性能在两个分类数据集(图4A)和三个回归数据集(图4B)中都优于MG-BERT,总体相对提高11.7%,其中分类和回归任务的平均性能分别提高为1.9%和18.2%。毫无疑问,BERT模型在官能团掩膜的预训练中是有效的。
为了证明预训练确实可以提高分子性质预测任务的准确性,作者测试了预训练和未预训练的FG-BERT的性能。在非预训练条件下(用FG-BERT*表示),使用初始化的权重对下游任务的模型参数进行微调。如图4C和D所示,预训练的FG-BERT模型优于未训练的FG-BERT模型,分类任务(图4C)的平均性能提高近7.9%,回归任务(图4D)的平均性能提高近9.6%。这些结果表明,预训练实际上使FG-BERT能够从大规模未标记分子中捕获丰富的结构和语义信息,提取有效的分子表征,并通过简单的神经网络轻松地将其迁移到特定的下游任务中,从而增强模型的预测能力。
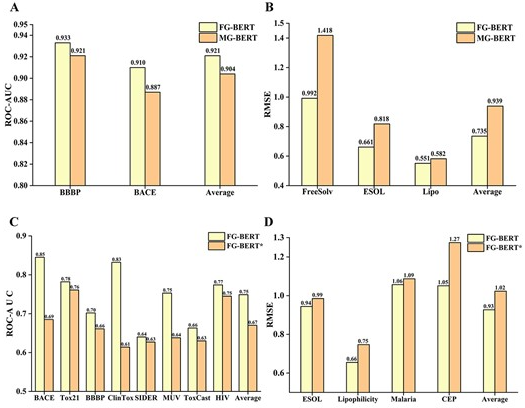
图2 消融实验
作者还进行了案例分析。全面了解分子结构与其性质之间的关系对于分析和进一步优化先导化合物至关重要,这就需要进一步探索FG-BERT模型的可解释性。由于FG-BERT可以通过注意力机制聚合来自所有原子和官能团表征的信息来揭示这种关系,从而生成整个分子的表征,而注意力权重可以生成并用于指示原子和官能团在分子表征中的重要性,因此,可以将注意力权重视为目标属性相关性度量的度量。
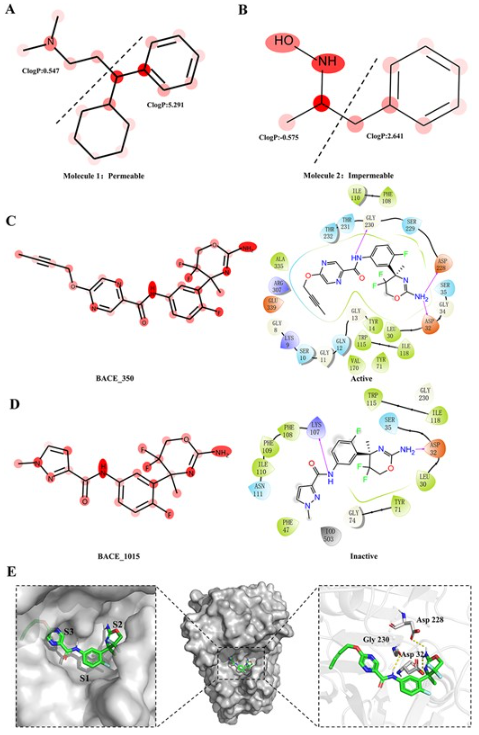
首先,利用基于血脑屏障通透性(BBBP)数据集的FG-BERT模型来分析模型的可解释性。由于血脑屏障(BBB)阻止大多数药物和激素的进入,因此准确预测分子的BBBP对于开发治疗中枢神经系统疾病的药物至关重要。通常,疏水分子由于其低极性和高ClogP更有可能穿过血脑屏障,而亲水分子则相反。如图3所示,较深的红色表示官能团被赋予较高的权重。以可穿透BBB的一个分子为例(图6A),分子中的苯环和环己烷(极性最低的高疏水官能团)对穿透血脑屏障的贡献最大。使用ChemBioDraw进一步量化这些官能团的ClogP值。不难看出,分子的左侧部分ClogP值为0.547,右侧部分ClogP值为5.291,这支持了FG-BERT模型的预测。同时,以不可穿透BBB的一个分子为例(图6B),FG-BERT的注意力权重集中在分子左侧的氨基和羟基上。而ChemBioDraw计算结果表明,分子左侧的ClogP值为−0.575,表明分子的左侧部分更亲水,可能在穿过血脑屏障时遇到困难,这也支持了FG-BERT模型的预测。
接着,本文还选择了基于BACE数据集的最优模型,进一步探讨FG-BERT模型的可解释性。BACE-1是人体内参与淀粉样蛋白前体蛋白(APP)裂解的酶。APP的裂解会产生β-淀粉样蛋白,β-淀粉样蛋白是阿尔茨海默症的主要诱因之一,因此BACE-1被认为是治疗阿尔茨海默症的重要靶点。如图3C和D所示,从测试集中选择两个分子(BACE_350和BACE_1015)进行案例研究。这两种分子具有相似的骨架,但BACE_350 (pIC50=8.22)是具有靶向BACE-1的活性的,而BACE_1015 (pIC50=6.35)是非活性的。
基于两个分子的注意力权重的可视化(图6C和D),可知模型发现了分子中重要的官能团。FG-BERT关注的是BACE_350和BACE_1015的区别,因为BACE_350含有一个六元环和一个炔取代基,而BACE_1015的对应部分含有一个不含炔取代基的五元环。此外,利用GlideSP对接研究了BACE_350和BACE_1015与BACE-1的结合模式,两分子的二维蛋白-配体相互作用分别如图6C和图D所示。Glide评分显示BACE_350(对接评分=−6.786kcal/mol)对BACE-1的抑制活性优于BACE_1015(对接评分=−3.823kcal/mol),这与临床实验结果一致。对接结果显示,分子中突出显示的氨基可以与ASP32和ASP228形成两个关键氢键,表明FG-BERT模型可以自动学习分子中的关键官能团信息,并将其应用于分子性质预测任务。此外,图3E给出了两种分子与BACE-1的详细三维结合模式。值得注意的是,BACE_350的炔官能团面向BACE-1的S3疏水口袋,产生了较强的疏水相互作用,这也与BACE_350突出显示的官能团相一致。然而,由于BACE_1015中缺乏炔官能团,因此没有观察到这些疏水相互作用,这可能是BACE_1015对BACE-1抑制活性较差的原因。这些结果表明,FG-BERT模型可以识别与生物活性相关的关键相互作用模式。
总结
在本研究中,作者提出了一种新的自监督学习框架FG-BERT。FG-BERT模型通过在分子图中对官能团进行掩膜,实现有效的预训练,并从未标记分子中全面挖掘化学结构和语义信息,以学习有用的分子表示。通过微调策略,FG-BERT预训练模型可以很容易地用于下游分子性质预测任务。基于涉及多种分子特性的大规模基准数据集,实验结果表明,FG-BERT预训练模型具有很强的性能。此外,FG-BERT模型的高可解释性使用户能够充分了解分子结构与其性质之间的关系,这可以提供有价值的片段和官能团信息,帮助科学家更准确地设计和识别具有所需功能和治疗效果的分子。总而言之,FG-BERT是一个有效且可解释的计算工具,可用于各种药物发现相关的任务。
[1] Li et al. FG-BERT: a generalized and self-supervised functional group-based molecular representation learning framework for properties prediction. Brief Bioinform. 2023
--------- End ---------
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢