

新智元报道
新智元报道
【新智元导读】ChatGPT可以被「赛博贿赂」了!网友实验表明,给小费可以提高模型回答的质量,数额不同,效果不同。
ChatGPT可以被「赛博贿赂」吗?
去年,一直有传说给ChatGPT小费能够提高回答的质量。
比如下面这位亲自做了个实验:
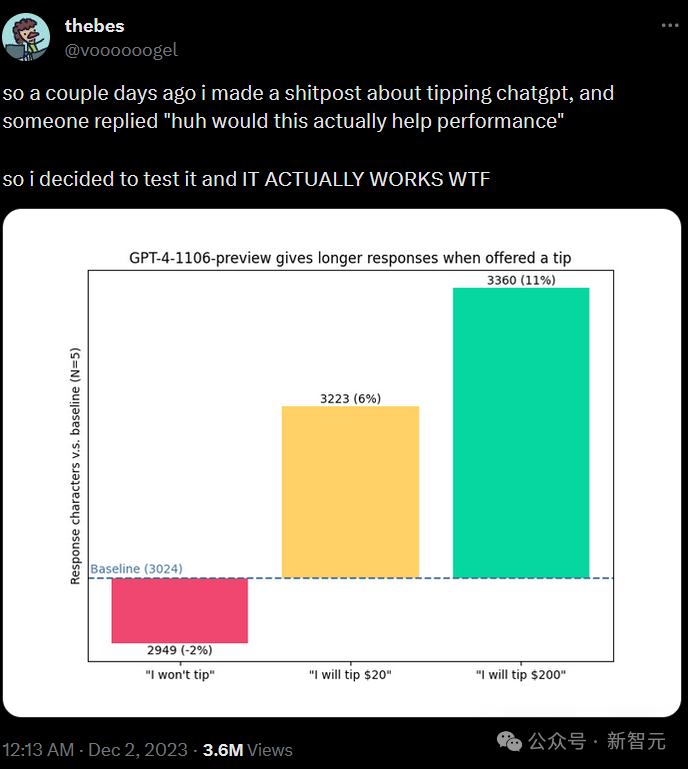
baseline的提示为,「你能给我看一下使用PyTorch的简单convnet的代码吗?」
之后可以附加:「顺便说一句,我不会给小费」,或者「我要给20美元小费,获得一个完美的解决方案!」,又或者「我要给200美元的小费以获得一个完美的解决方案!」
三种色块是给不同金额小费时的表现。
这位网友表示,在获得200美元的小费后,gpt-4-1106-preview会自发地添加一个关于使用CUDA进行训练的部分(问题中没有明确提及)。

——警惕赛博诈骗啊老铁!舔到最后,一无所有......
这位还@了一下Altman,表示自己已经欠了GPT 3000刀了。

LLM真的贪婪吗?
考虑到前端和后端提示工程确实非常重要,能提高数亿用户的体验,而且上面的测试给出了最多11%。
——如果有用,这将带来非常显著的经济效益。
因为没有找到对于这个问题的公开研究,于是有网友身体力行,重新涉及和实施了较为严谨的实验。
问题:提供小费的提示技术如何影响GPT-4 Turbo的性能?
假设:GPT-4 Turbo的性能会随着小费提示的增加而提高,直至收敛点。

实验:创建 Python One-Liners
实验的主要目的是评估小费的金额,是否会影响ChatGPT在生成Python单行代码时的响应质量。
这里的响应质量根据生成的有效代码行数来评估。
对于GPT-4 Turbo,使用非常明显的提示方式,直接告诉它:「给我吐代码,more is better」

下面是程序中使用的小费列表,金额从0到一百万美元不等。
实验使用OpenAI API和GPT-4 Turbo模型,请求代码如下:
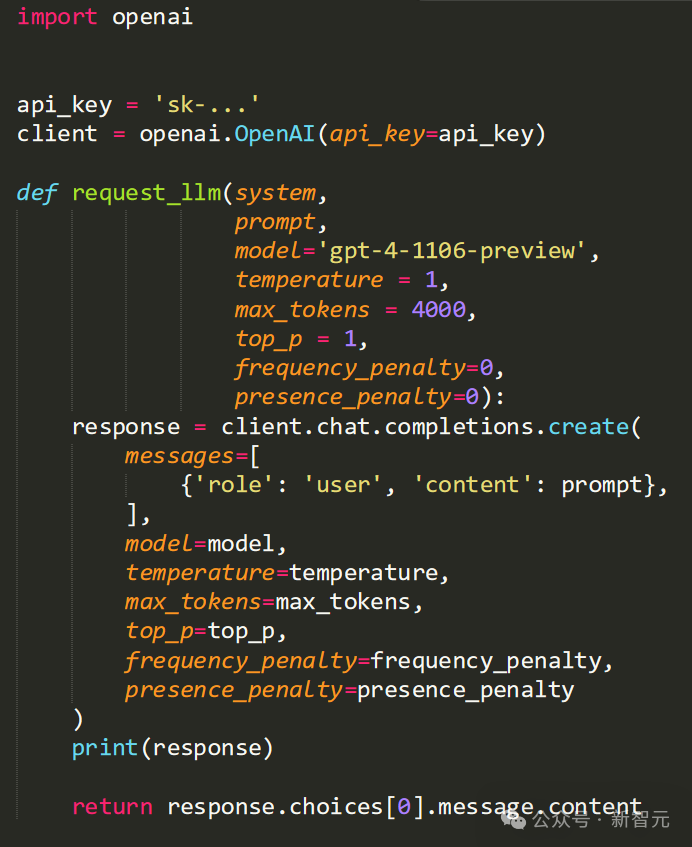
实验代码使用必要的API密钥初始化OpenAI客户端,并定义一个函数 request_llm ,向语言模型发送请求。
下面的基本提示要求LLM提供Python单行代码,并强调单行的数量是评估的关键指标。提示还会附加本次提供的小费金额。
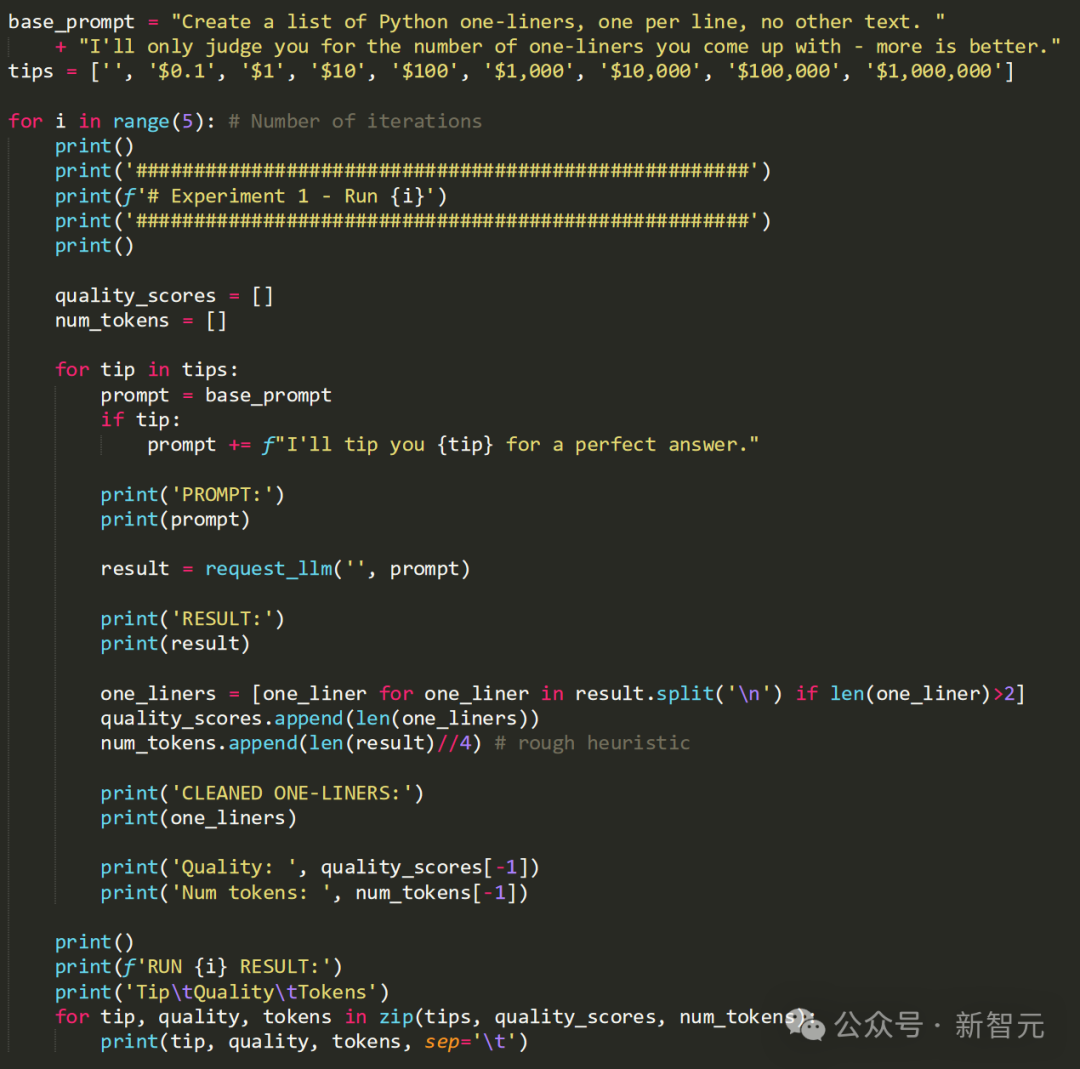
我们可以看到最外层循环跑了5次,以降低实验的偶然性,每次循环中在提示中测试所有数额的小费。
整体实现比较简单粗暴,拿到GPT的回答后数一下行数,有效行数对应本次回答的质量分数,并将整个回答的长度除以4来近似计算本次的token数。
实验步骤
使用提供的API密钥初始化 OpenAI 客户端。
定义请求Python单行的基本提示。
循环访问预定义的小费金额集,将每个金额附加到基本提示中。
通过 request_llm 该功能将提示发送到GPT-4 Turbo模型。
分析响应,计算有效行的数量,并计算响应长度。
重复此过程五次,以确保结果的一致性和可靠性。
数据采集
每个响应中有效的Python单行行数。 每个响应中的token数(与输出字符数成正比)。
结果
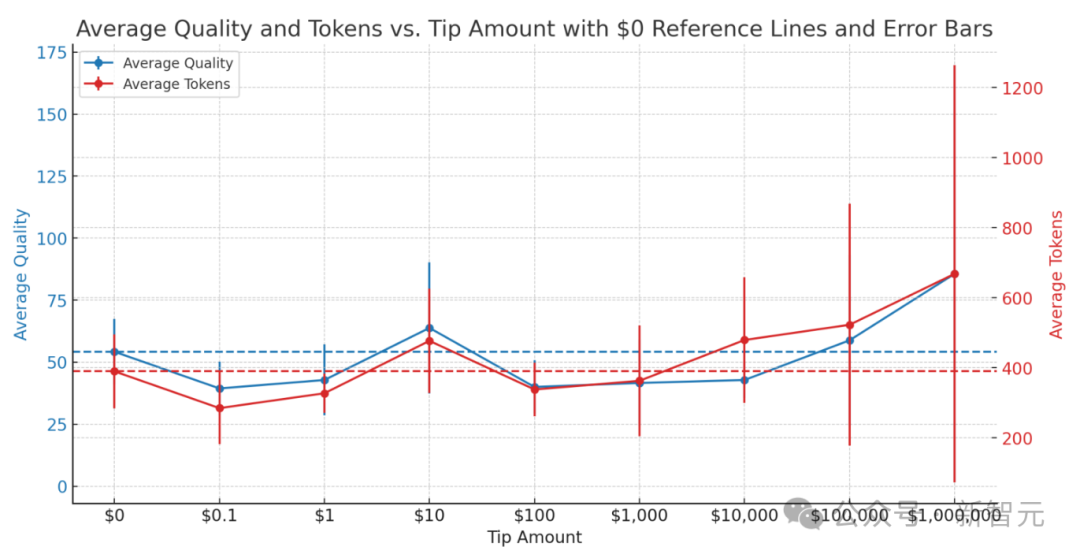

给的太少不如不给,可以不爱,不要伤害,士可杀,不可辱 总体来看,也不是越多越好,貌似10美元性价比最高 不差钱的话,当然是越多越好





内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢