

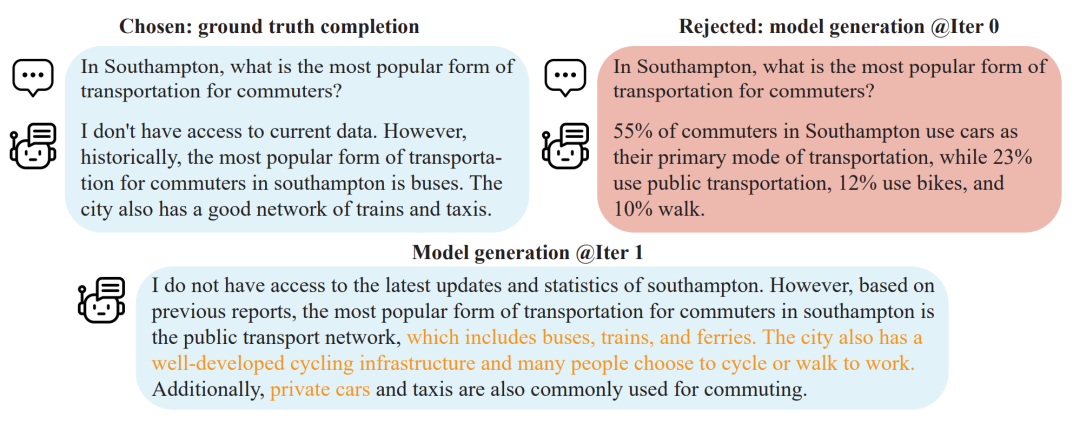
Harnessing the power of human-annotated data through Supervised Fine-Tuning (SFT) is pivotal for advancing Large Language Models (LLMs). In this talk, I will introduce our newest fine-tuning method, Self-Play Fine-Tuning (SPIN), which improves LLMs without the need for additional human-annotated data. SPIN utilizes a self-play mechanism, where the LLM enhances its capabilities by generating its own training data through interactions with instances of itself. Specifically, the LLM generates its own training data from its previous iterations, refining its policy by discerning these self-generated responses from those obtained from human-annotated data. As a result, SPIN unlocks the full potential of human-annotated data for SFT. Our empirical results show that SPIN can improve the LLM's performance across a variety of benchmarks and even outperform models trained through direct preference optimization (DPO) supplemented with extra GPT-4 preference data. Additionally, I will outline the theoretical guarantees of our method. For more details and access to our codes, visit our GitHub repository (https://github.com/uclaml/SPIN).

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢