

新智元报道
新智元报道
【新智元导读】谷歌发布全球最强开源大模型Gemma,7B性能超越Llama 2 13B!谷歌和OpenAI,已经卷出了新高度。这轮番放深夜炸弹的频率,让人不得不怀疑双方都已经攒了一堆大的。


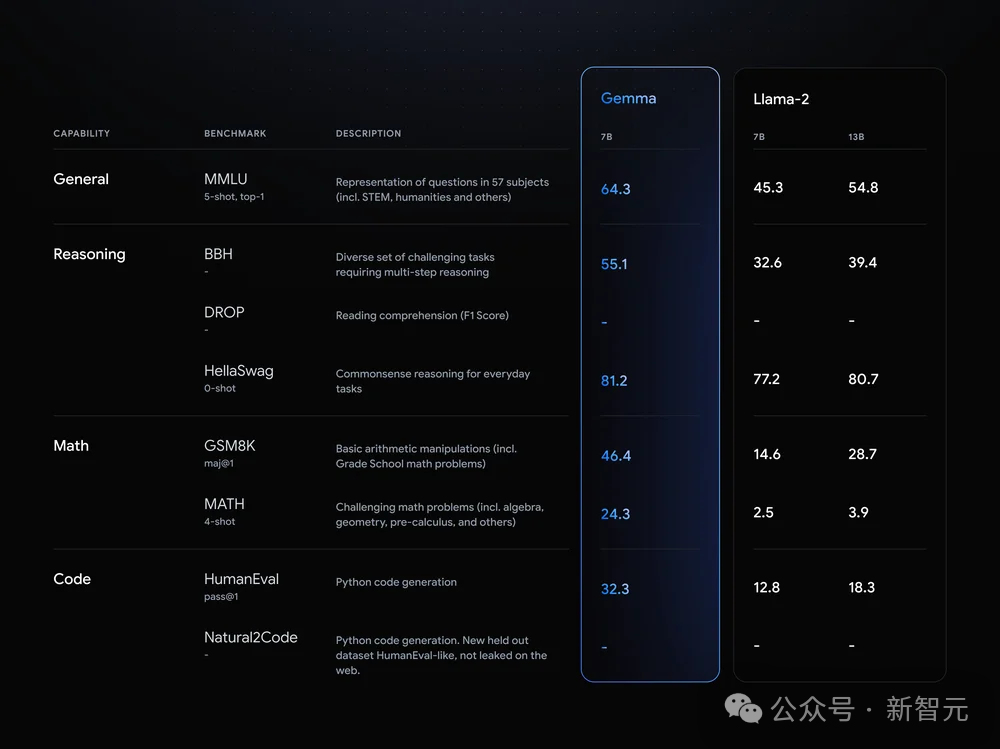





同规模刷新SOTA,越级单挑Llama 2 13B
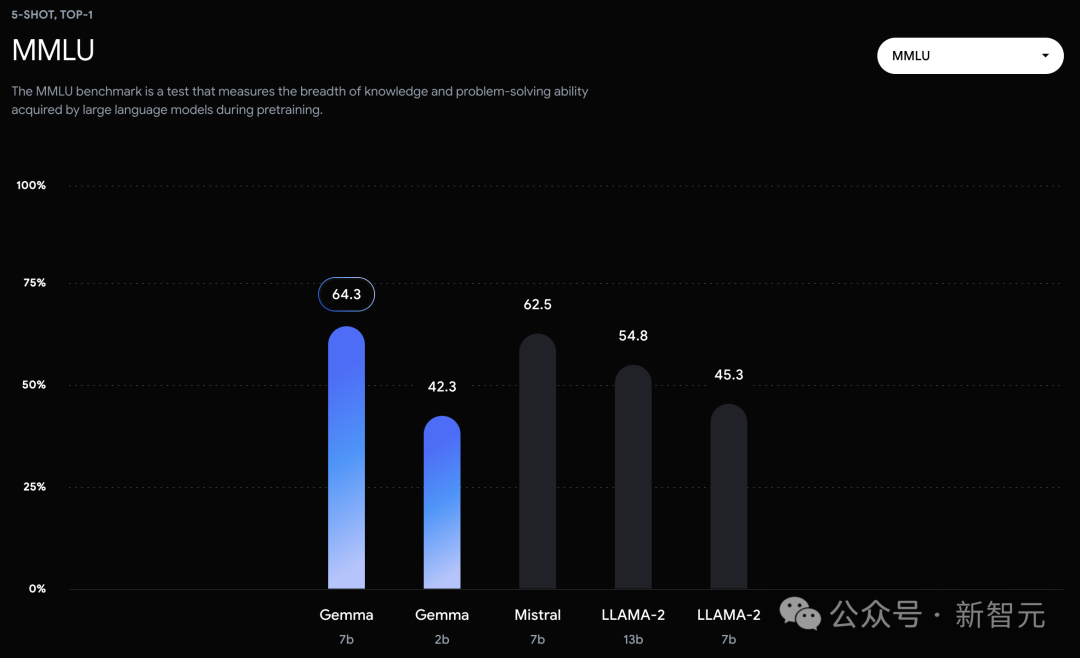
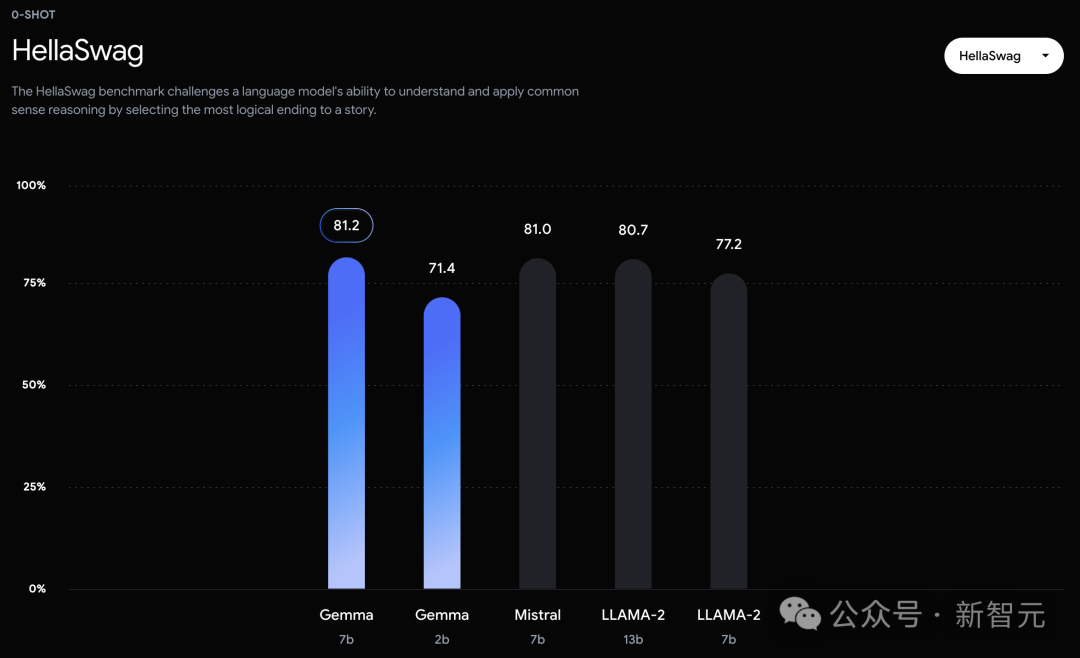
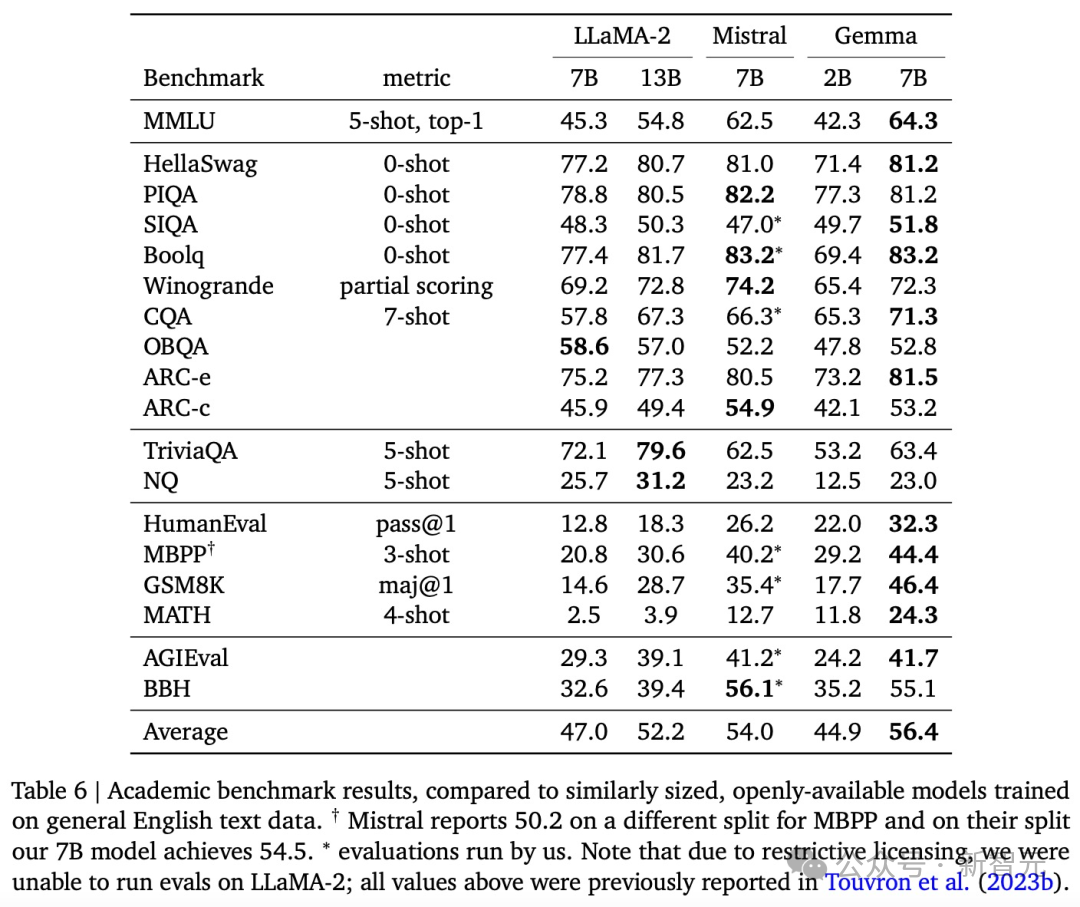
可以看到,Gemma-7B模型在涵盖一般语言理解、推理、数学和编码的8项基准测试中,性能已经超越了Llama 2 7B和13B! 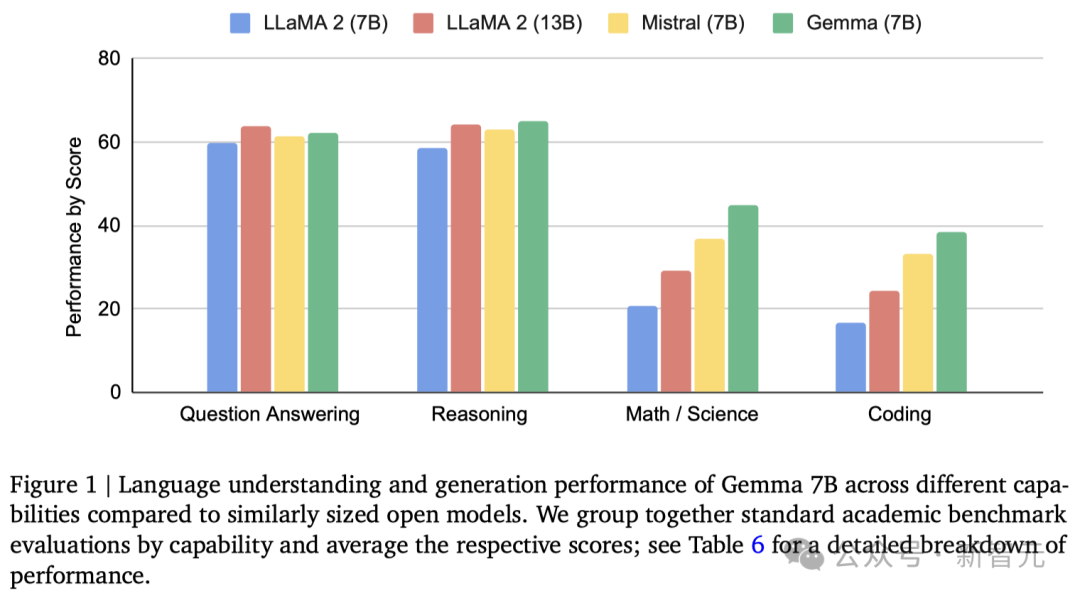
并且,它也超越了Mistral 7B模型的性能,尤其是在数学、科学和编码相关任务中。 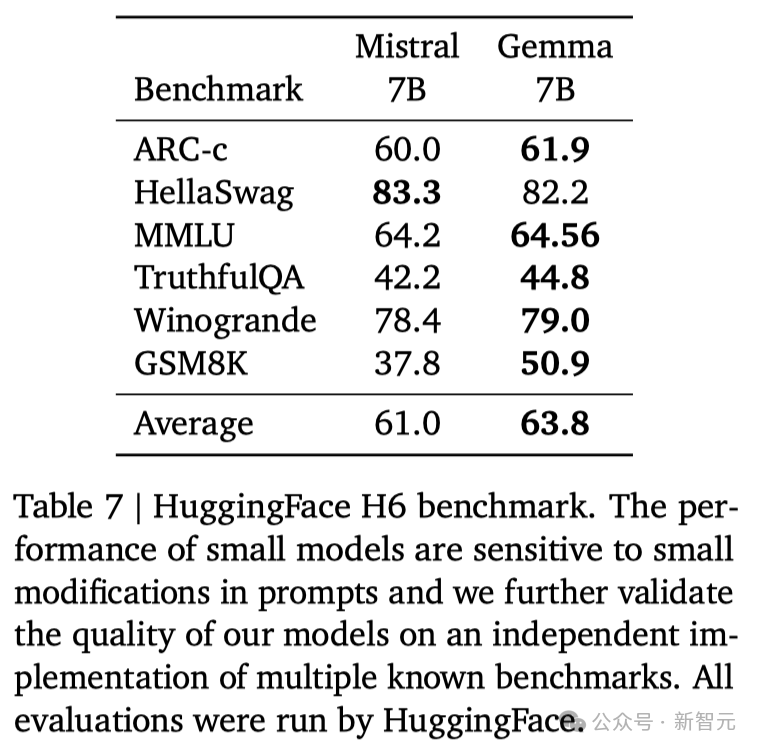
在安全性方面,经过指令微调的Gemma-2B IT和 Gemma-7B IT模型,在人类偏好评估中都超过了Mistal-7B v0.2模型。 特别是Gemma-7B IT模型,它在理解和执行具体指令方面,表现得更加出色。 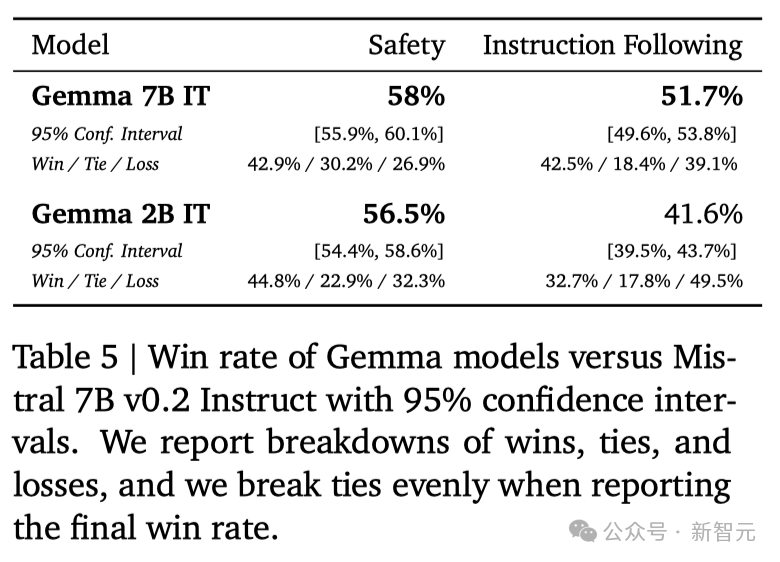
一整套工具:跨框架、工具和硬件进行优化
一整套工具:跨框架、工具和硬件进行优化
这次,除了模型本身,谷歌还提供了一套工具帮助开发者,确保Gemma模型负责任的使用,帮助开发者用Gemma构建更安全的AI应用程序。 - 谷歌为JAX、PyTorch和TensorFlow提供了完整的工具链,支持模型推理和监督式微调(SFT),并且完全兼容最新的Keras 3.0。 - 通过预置的Colab和Kaggle notebooks,以及与Hugging Face、MaxText、NVIDIA NeMo和TensorRT-LLM等流行工具的集成,用户可以轻松开始探索Gemma。 - Gemma模型既可以在个人笔记本电脑和工作站上运行,也可以在Google Cloud上部署,支持在Vertex AI和Google Kubernetes Engine (GKE) 上的简易部署。 - 谷歌还对Gemma进行了跨平台优化,确保了它在NVIDIA GPU和Google Cloud TPU等多种AI硬件上的卓越性能。 并且,使用条款为所有组织提供了负责任的商业使用和分发权限,不受组织规模的限制。 
但,没有全胜
但,没有全胜
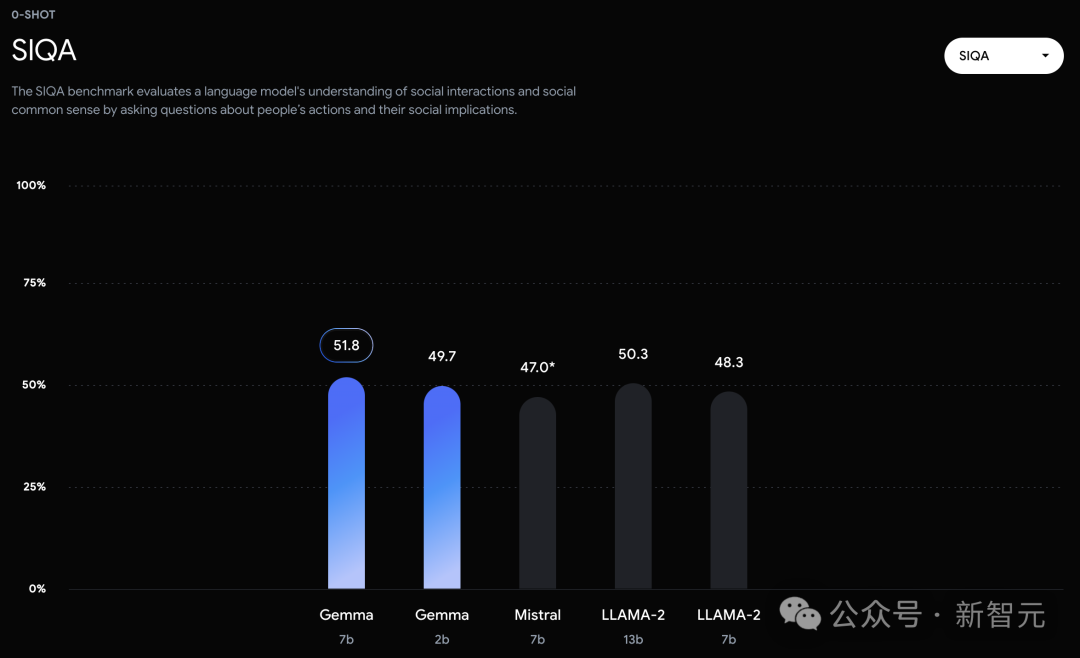
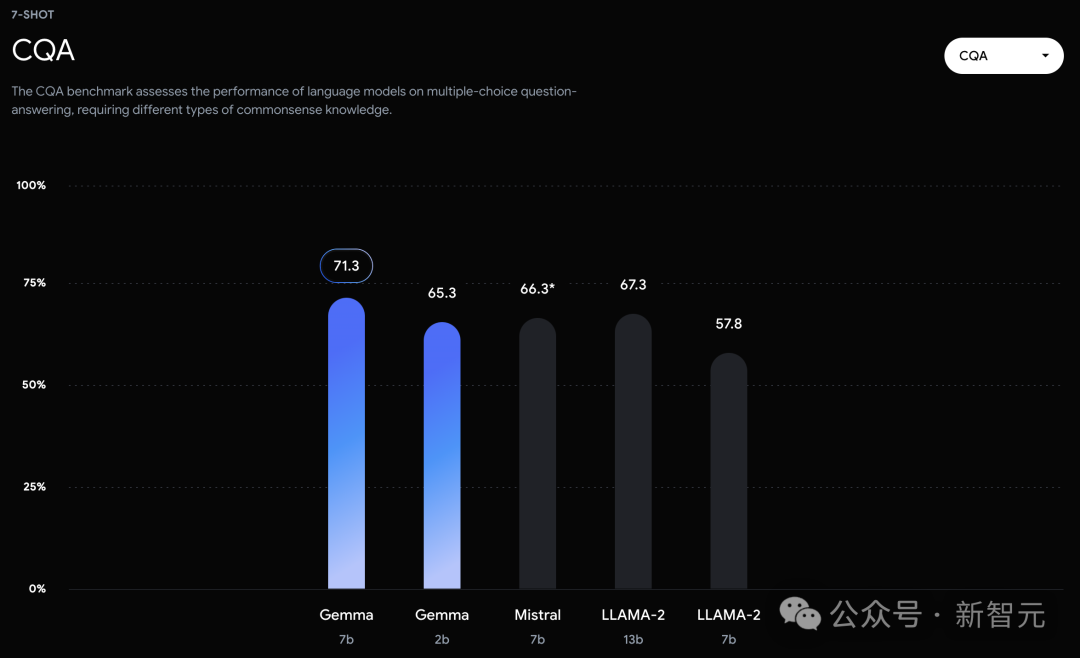
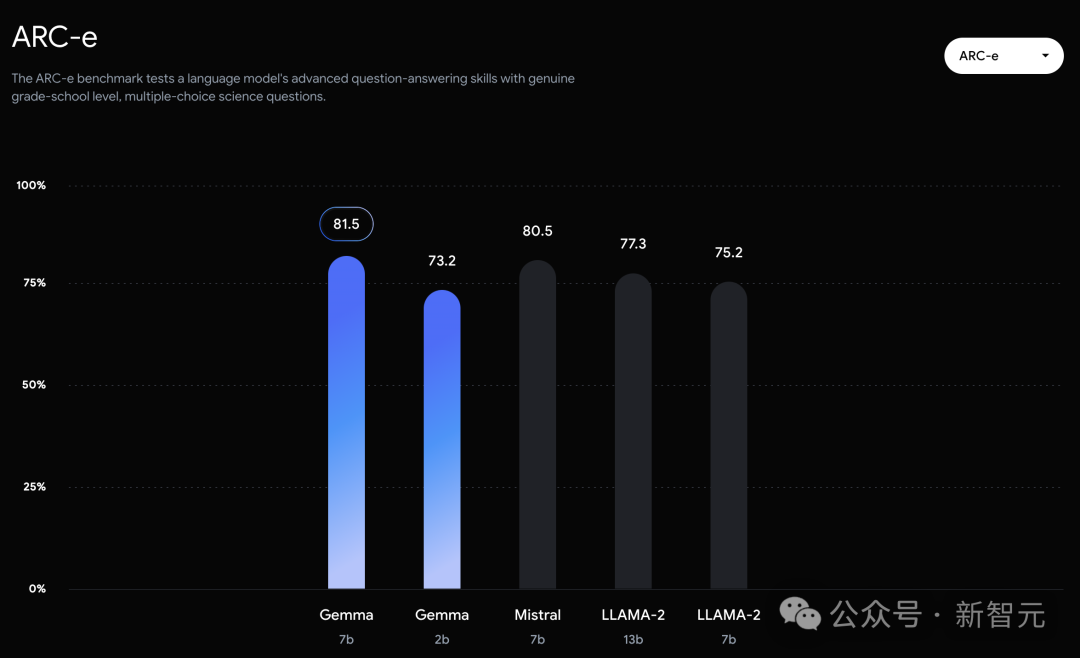
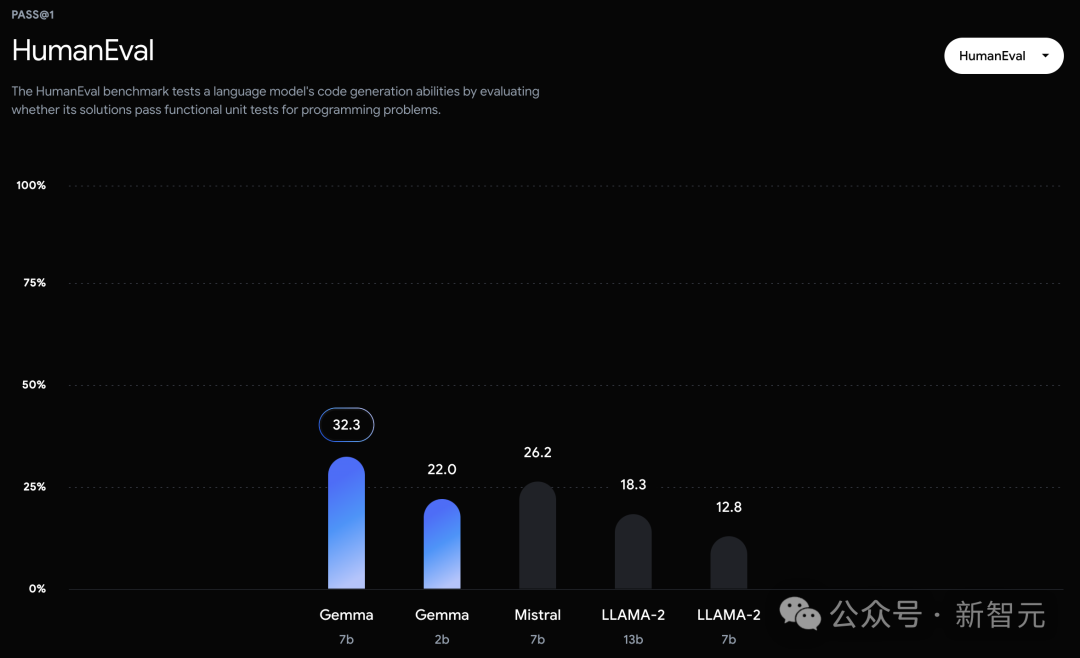
不过,Gemma并没有能够在所有的榜单中,都拿下SOTA。 在官方放出的评测中,Gemma 7B在MMLU、HellaSwag、SIQA、CQA、ARC-e、HumanEval、MBPP、GSM8K、MATH和AGIEval中,成功击败了Llama 2 7B和13B模型。 左右滑动查看 相比之下,Gemma 7B在Boolq测试中,只与Mistral 7B打了个平手。 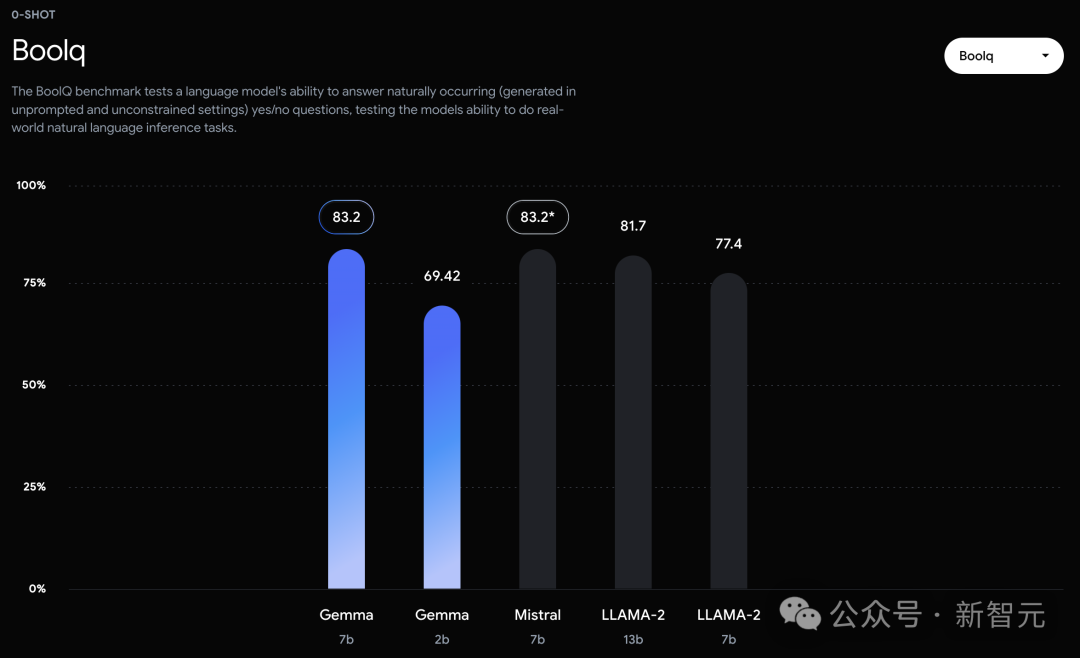
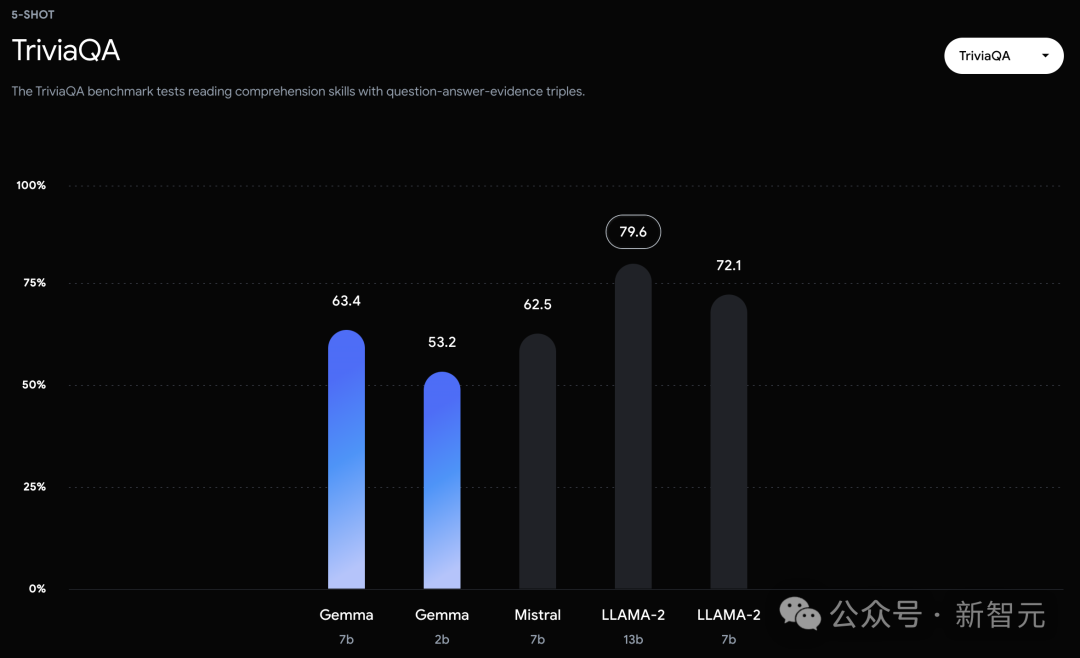
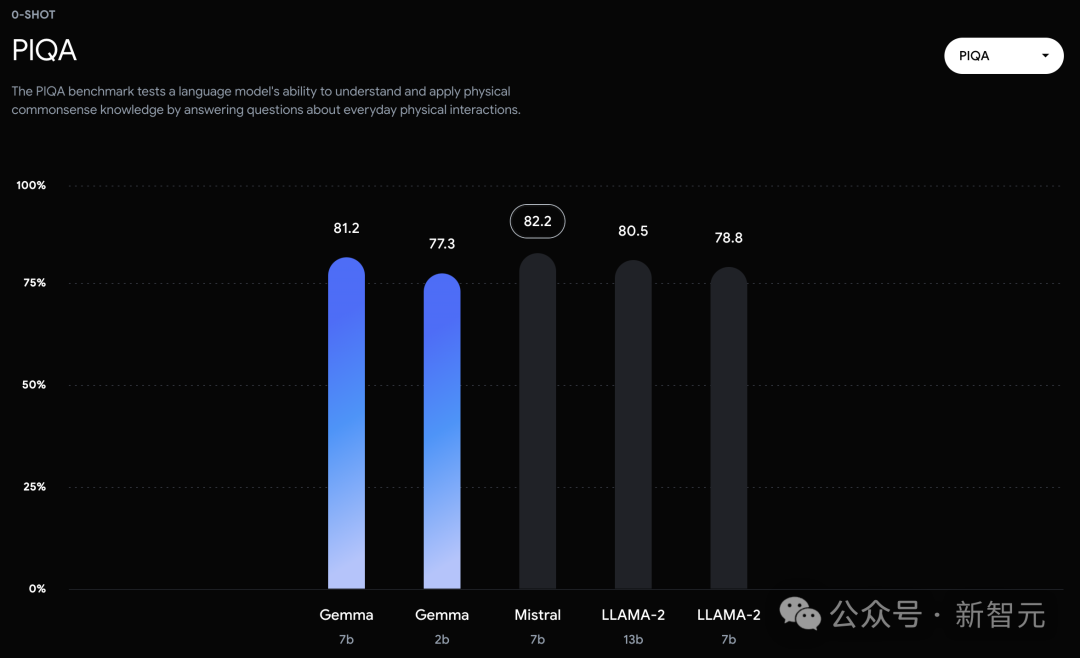
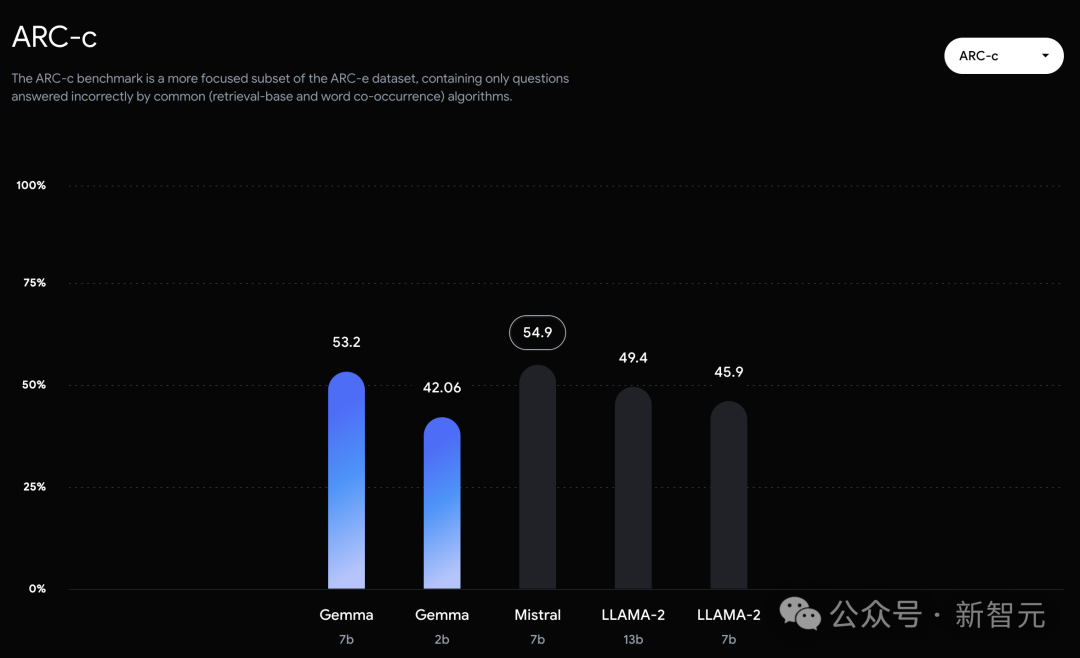
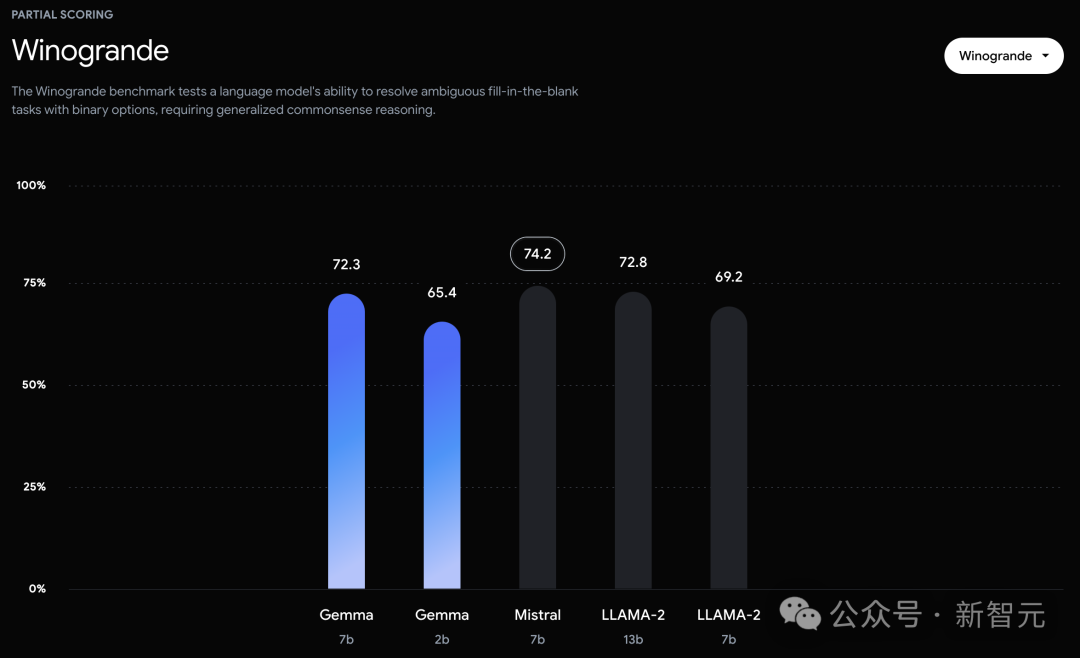
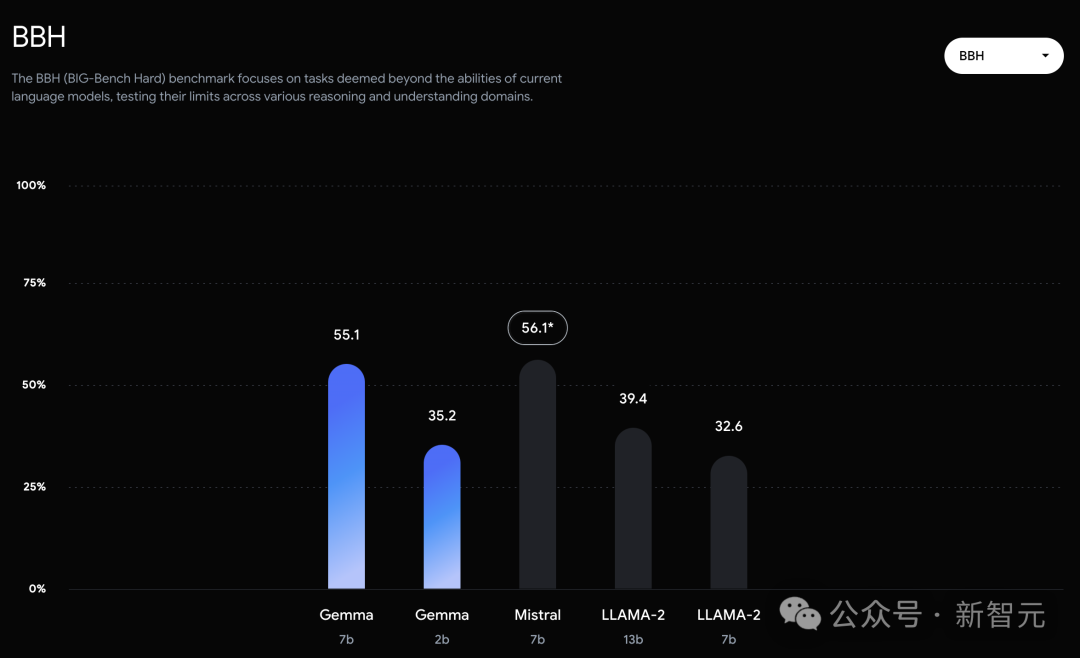
而在PIQA、ARC-c、Winogrande和BBH中,则不敌Mistral 7B。 左右滑动查看 在OBQA和trivalent QA中,更是同时被7B和13B规模的Llama 2 7B斩于马下。 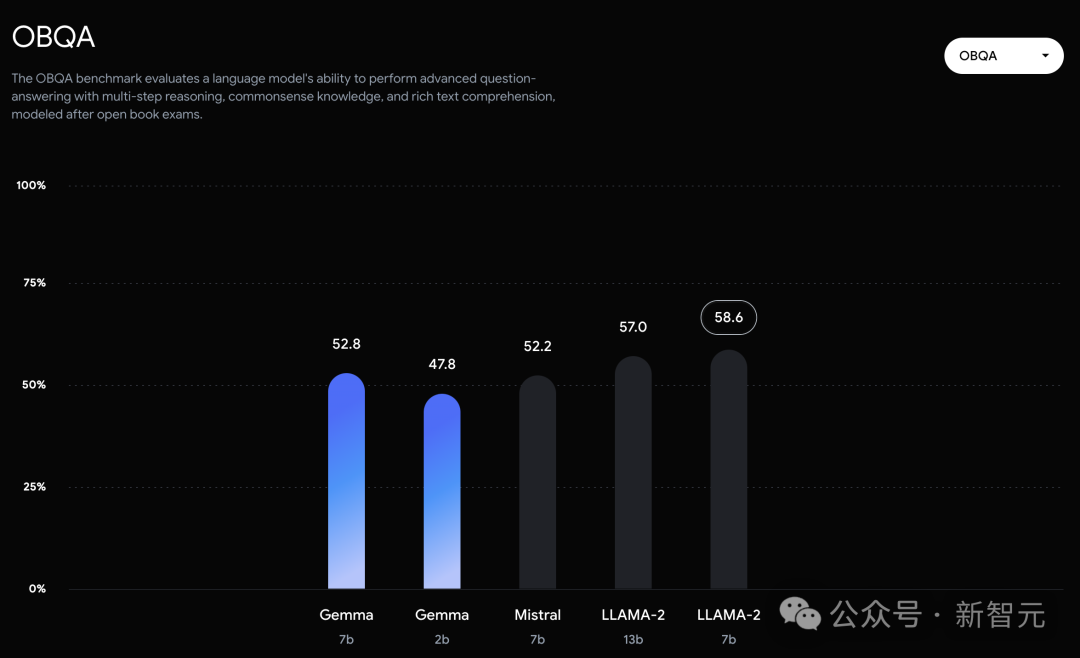
技术报告
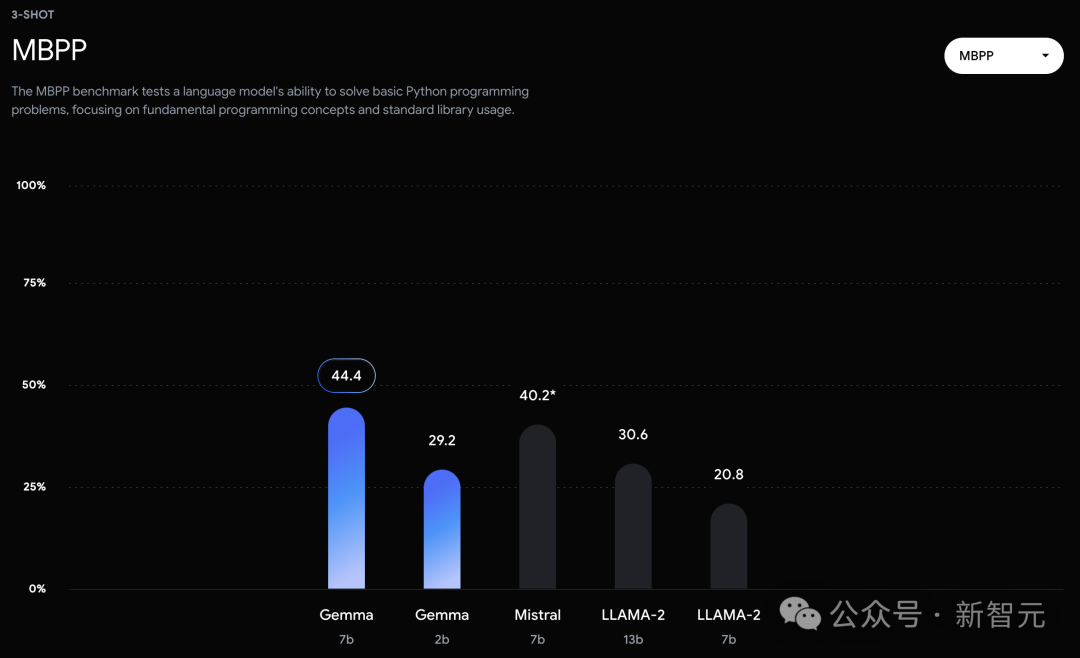
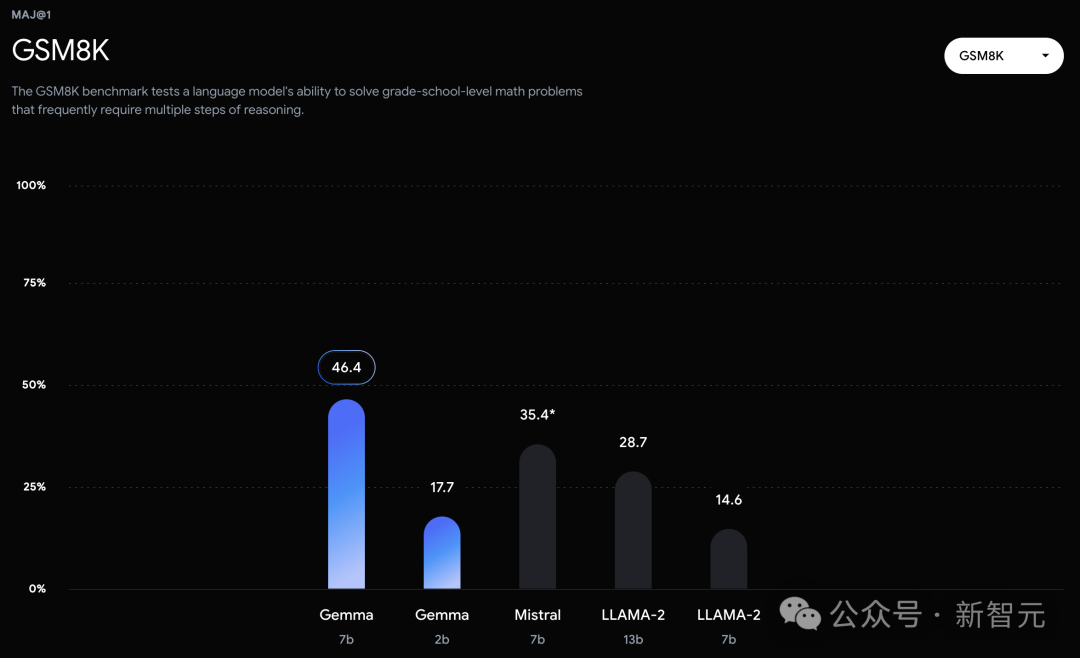
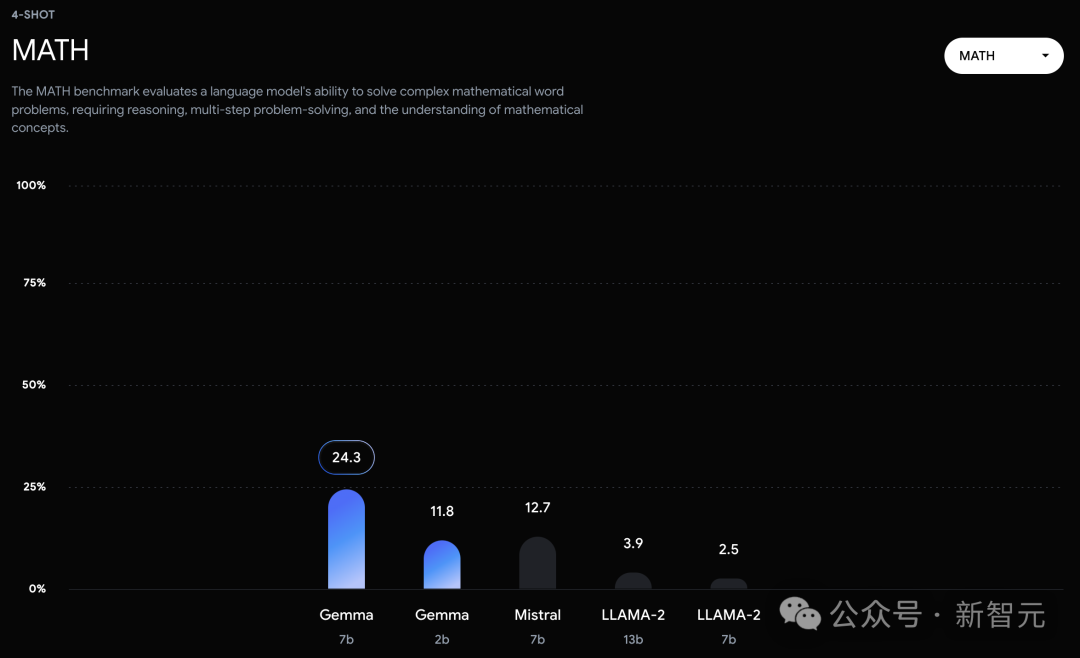
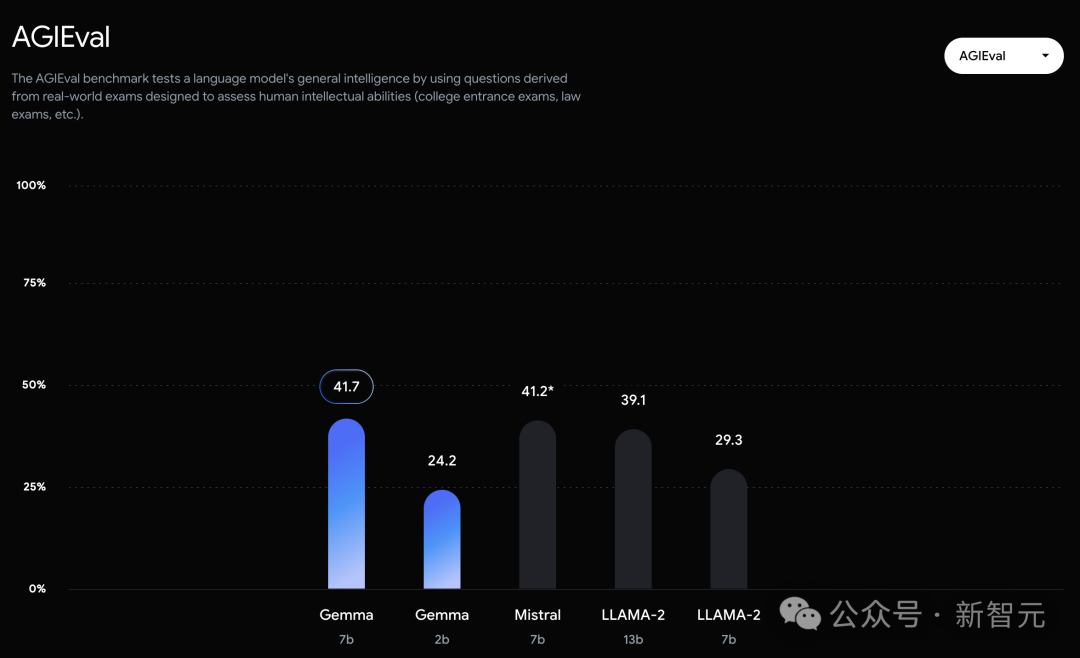
技术报告
谷歌这次发布的两个版本的Gemma模型,70 亿参数的模型用于GPU和TPU上的高效部署和开发,20亿参数的模型用于CPU和端侧应用程序。 在18个基于文本的任务中的11个中,Gemma都优于相似参数规模的开源模型,例如问答、常识推理、数学和科学、编码等任务。 模型架构方面,Gemma在Transformer的基础上进行了几项改进,从而在处理复杂任务时能够展现出更加出色的性能和效率。 - 多查询注意力机制 其中,7B模型采用了多头注意力机制,而2B模型则使用了多查询注意力机制。结果显示,这些特定的注意力机制能够在不同的模型规模上提升性能。 - RoPE嵌入 与传统的绝对位置嵌入不同,模型在每一层都使用了旋转位置嵌入技术,并且在模型的输入和输出之间共享嵌入,这样做可以有效减少模型的大小。 - GeGLU激活函数 将标准的ReLU激活函数替换成GeGLU激活函数,可以提升模型的表现。 - 归一化化位置(Normalizer Location) 每个Transformer子层的输入和输出都进行了归一化处理。这里采用的是RMSNorm作为归一化层,以确保模型的稳定性和效率。 架构的核心参数如下: 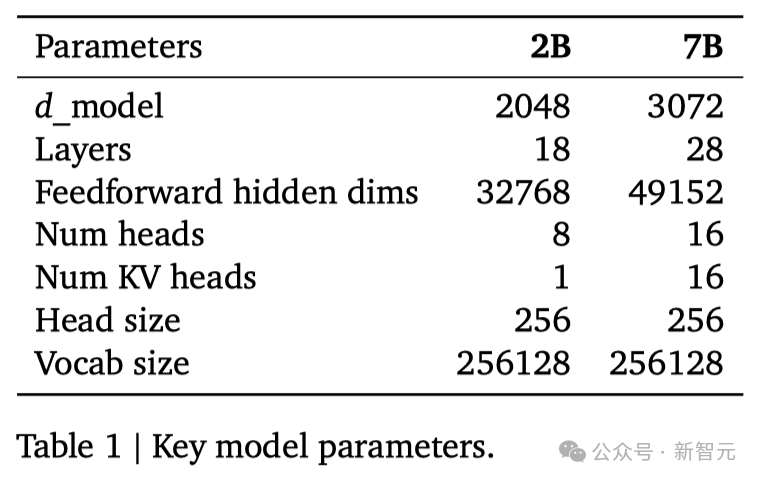
两种规模的参数如下: 
预训练
训练数据
指令微调
监督微调
RLHF
性能评估
自动评估
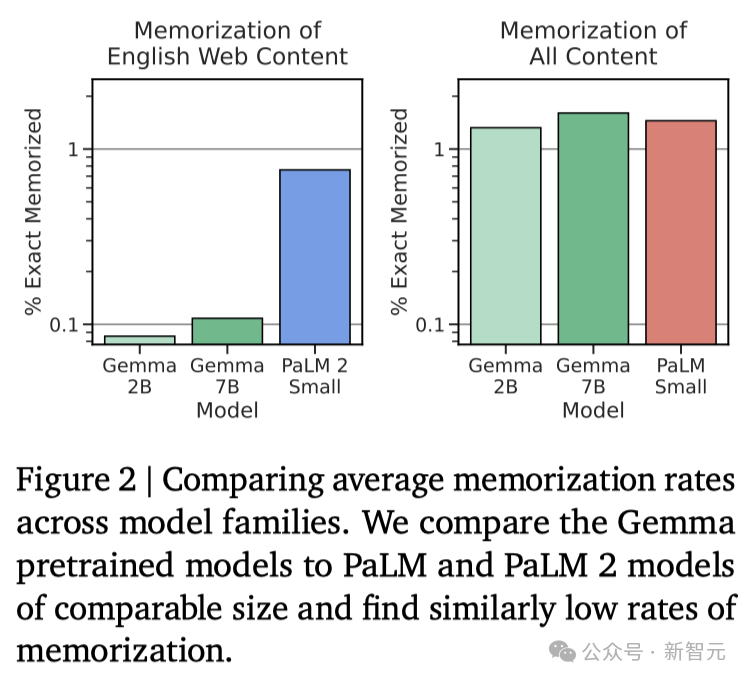
记忆评估
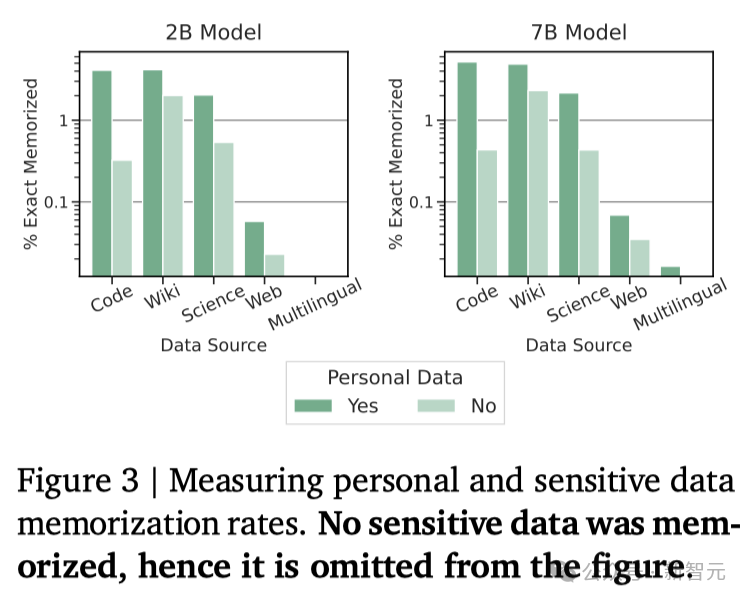
总结讨论
团队成员
核心贡献者: 
其他贡献者: 
产品经理、项目经理、执行赞助、负责人和技术负责人: 
参考资料: https://ai.google.dev/gemma/


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢