

据介绍,Gemma 由 Google DeepMind 和 Google 的其他团队共同开发,采用与创建 Gemini 模型相同的研究和技术构建而成,专为负责任的人工智能开发而设计,其名字来自拉丁语 gemma,意为“宝石”。
Google DeepMind 首席执行官 Demis Hassabis 在 X 上表示,“我们长期以来一直支持负责任的开源和科学,这可以推动快速的研究进展,因此我们很自豪地发布了 Gemma......”

谷歌将发布两种尺寸的模型权重:Gemma 2B 和 Gemma 7B,且每种尺寸都发布了预训练和指令微调变体。 新的 Responsible Generative AI 工具包为使用 Gemma 创建更安全的 AI 应用提供了指导和基本工具。 谷歌也为所有主要框架的推理和监督微调(SFT)提供了工具链:JAX、PyTorch 和 TensorFlow,以及本地 Keras 3.0。 现成可用的 Colab 和 Kaggle 笔记本,以及与 Hugging Face、MaxText、NVIDIA NeMo 和 TensorRT-LLM 等流行工具的集成,也使得开发者上手 Gemma 非常容易。 经过预训练和指令微调的 Gemma 模型可在用户的笔记本电脑、工作站或谷歌云上运行,并可在 Vertex AI 和谷歌 Kubernetes Engine (GKE) 上轻松部署。 跨多个 AI 硬件平台的优化确保了行业领先的性能,包括英伟达 GPU 和谷歌云 TPU。 在使用条款下,允许所有组织(无论规模大小)进行负责任的商业使用和分发。
此外,研究团队也在博客中写道,“从今天开始,Gemma 将在全球发布。”也就是说,国内的开发者从今天起也可以使用 Gemma。(快速入门指南:https://ai.google.dev/gemma?hl=zh-cn)
据官方博客介绍,Gemma 模型与 Gemini 共享技术和基础设施组件,这使得 Gemma 2B 和 7B 与其他开放模型相比,在其规模上实现了同类最佳的性能。而且,Gemma 模型能够直接在开发人员的笔记本电脑或台式电脑上运行。
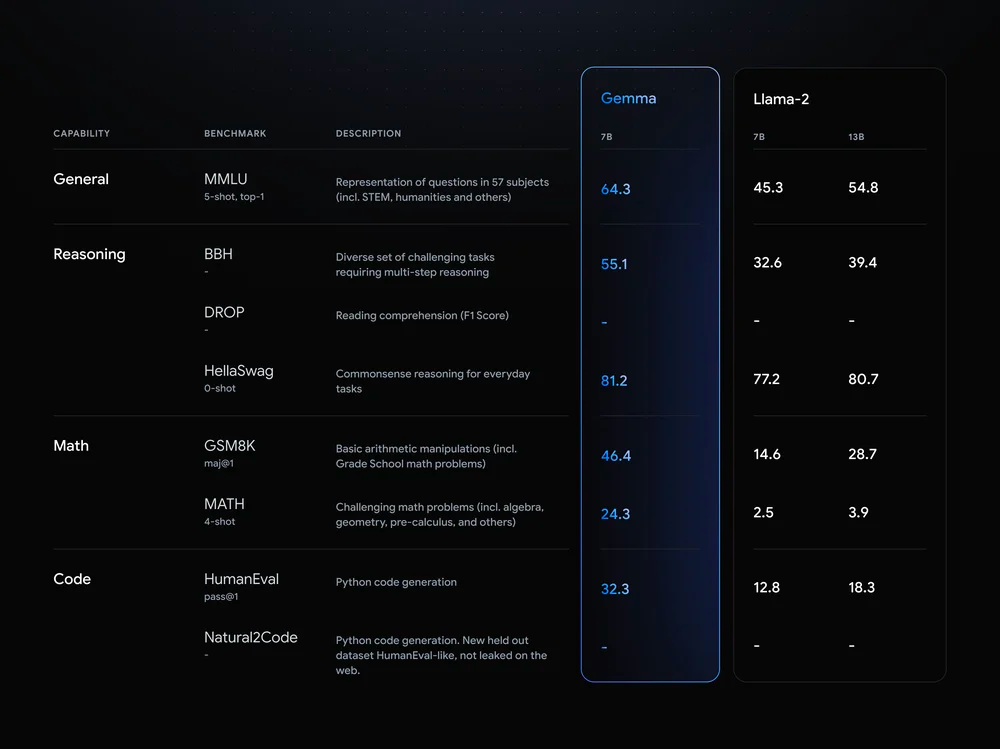
值得一提的是,Gemma 在关键基准上超过了更大的模型,同时还符合谷歌严格的安全和负责任的输出标准。
谷歌方面表示,为适应特定的应用需求,比如汇总或检索增强生成(RAG),开发者可以使用自己的数据对 Gemma 模型进行微调。
多框架工具:使用最喜欢的框架,在多框架 Keras 3.0、本地 PyTorch、JAX 和 Hugging Face Transformers 中进行推理和微调的参考实现。 跨设备兼容性:Gemma 模型可在笔记本电脑、台式机、物联网、移动和云等流行设备类型中运行,从而实现广泛的 AI 功能。 尖端硬件平台:谷歌与英伟达合作,针对英伟达 GPU 优化 Gemma,从数据中心到云端再到本地 RTX AI PC,确保业界领先的性能和与尖端技术的集成。 针对谷歌云进行了优化:Vertex AI 提供广泛的 MLOps 工具集,具有一系列调整选项,并可使用内置推理优化功能进行一键式部署。可使用完全管理的 Vertex AI 工具或自主管理的 GKE 进行高级定制,包括部署到任何平台的 GPU、TPU 和 CPU 上具有成本效益的基础设施。
https://blog.google/technology/developers/gemma-open-models/
https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢