

主要亮点
数据驱动:通过数据浓缩得到高质量训练数据,从而打破 scaling law,让小模型性能接近大模型。
架构灵活:提供多种即插即用的视觉和语言 backbone,可任意组合成新的模型,满足个性化需求。
低资源:更低的训练和推理成本,让更多低资源用户参与推动大模型的发展和普及。
↓ 代码、模型均已开源:
项目地址:https://github.com/BAAI-DCAI/Bunny
模型下载地址:https://huggingface.co/BAAI/bunny-phi-2-siglip-lora
在线 Demo: http://bunny.dataoptim.org
具体地,Bunny 基于数据分布和图文匹配度将 LAION-2B 浓缩成 2M 核心集以得到更丰富的预训练数据,基于 DataOptim 和 SVIT 数据集精选得到更高质量的指令微调数据,从而训练得到一个性能强劲的小模型。Bunny-3B 在绝大多数基准上超越了 Imp、LLaVA-Phi、MobileVLM 等一系列近期热门模型,还取得了与 LLaVA-v1.5-13B 等大模型相当的多模态理解和推理能力。
Bunny 模型采用了经典的 Encoder+Projector+LLM 架构,提供了一个可扩展的组合框架。支持多种 Vision Encoders,如 EVA CLIP、SigLIP 等,以及多种 LLM Backbone,包括 Phi-1.5、Phi-2、StableLM-2 等。灵活的架构设计便于用户基于Bunny开展大模型研究。模型结构如下图所示:
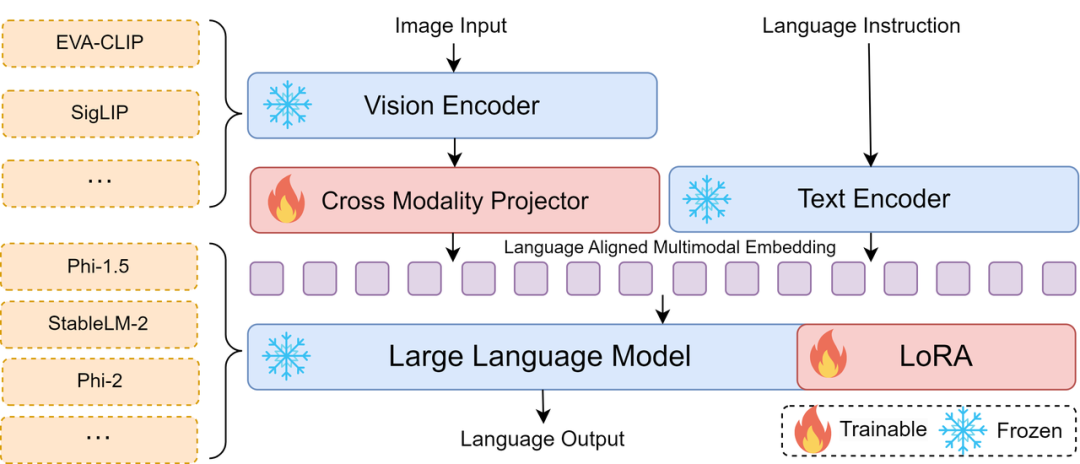
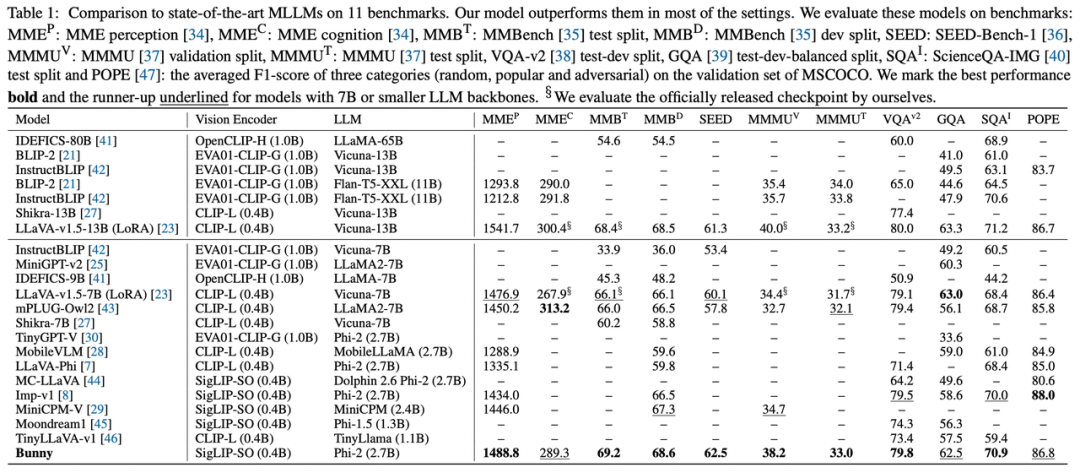
Table 1展示了各类多模态模型的评估结果对比。其中,Bunny 在大部分基准中达到了最佳性能。值得关注的是,Bunny 在一部分指标上甚至超越了诸如 LLaVA-v1.5-13B 等更大规模的经典模型。
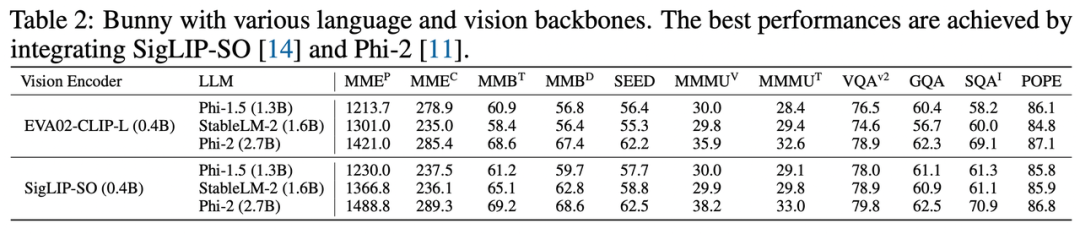
Table 2展示了 Bunny 系列模型的测评结果。体现出 Bunny 的高度可扩展性,即用户可以自由组合常见的视觉和语言模型,以便定制个性化多模态小模型。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢