

新智元报道
新智元报道
【新智元导读】终有一天,LLM可以成为人类数据专家,针对不同领域进行数据分析,大大解放AI研究员。
在数据科学中,AI研究员经常面临处理不完整数据集的挑战。
然而,许多已有的算法根本无法处理「不完整」的数据序列。

传统上,数据科学家会求助于专家,利用他们的专业知识来填补空白,然而这一过程既耗时,却又不实用。
如果AI可以接管专家的角色,又会如何呢?
近日,来自德国人工智能中心、大阪公立大学等团队的研究人员,调查了LLM能否足以充当数字专家。
毕竟,当前大模型都在大量文本的基础上进行了训练,可能对医学数据、社会科学等不同主题的问题有着深刻的理解。

论文地址:https://arxiv.org/pdf/2402.07770.pdf
研究人员通过将LLM的答案与实际数据进行比较,并建立了处理数据差距的统计方法。
结果表明,在许多情况下,LLM可以在不依赖人类专家的情况下,提供与传统方法类似的准确估计。
用LLM进行「数据插补」
在分析数据时,无论是医学、经济学还是环境研究,经常会遇到信息不完整的问题。
这就需要用到两种关键技术:先验启发(确定先验知识)和数据插补(补充缺失数据)。
先验启发是指,系统地收集现有的专家知识,以对模型中的某些参数做出假设。
另一方面,当我们的数据集中缺少信息时,数据插补就开始发挥作用。
科学家们不会因为一些缺失而放弃有价值的数据集,而是使用统计方法用看似合理的值来填补。

研究中,主要采用的数据集为OpenML-CC18 Curated Classification Benchmark,其中包括72个分类数据集,涵盖从信用评级到医药和营销等各个领域。
这种多样性确保了实验涵盖了广泛的现实世界场景,并为LLM在不同环境下的性能提供了相关见解。
值得一提的是,最新方法中最关键的一个步骤便是——人为在数据集中生成缺失值,以模拟数据点不完整的情况。
研究人员用随机缺失(MAR)模式从完整条目中生成这种缺失数据,以便与基本事实进行比较。
他们首先从OpenML描述中,为每个数据集生成一个适当的专家角色,然后使用它来初始化LLM,以便可以查询它是否缺少值。
使用LLM进行插值,包括LLaMA 2 13B Chat、LLaMA 2 70B Chat、Mistral 7B Instruct,以及Mixtral 8x7B Instruct,每一种都进行了单独的评估。
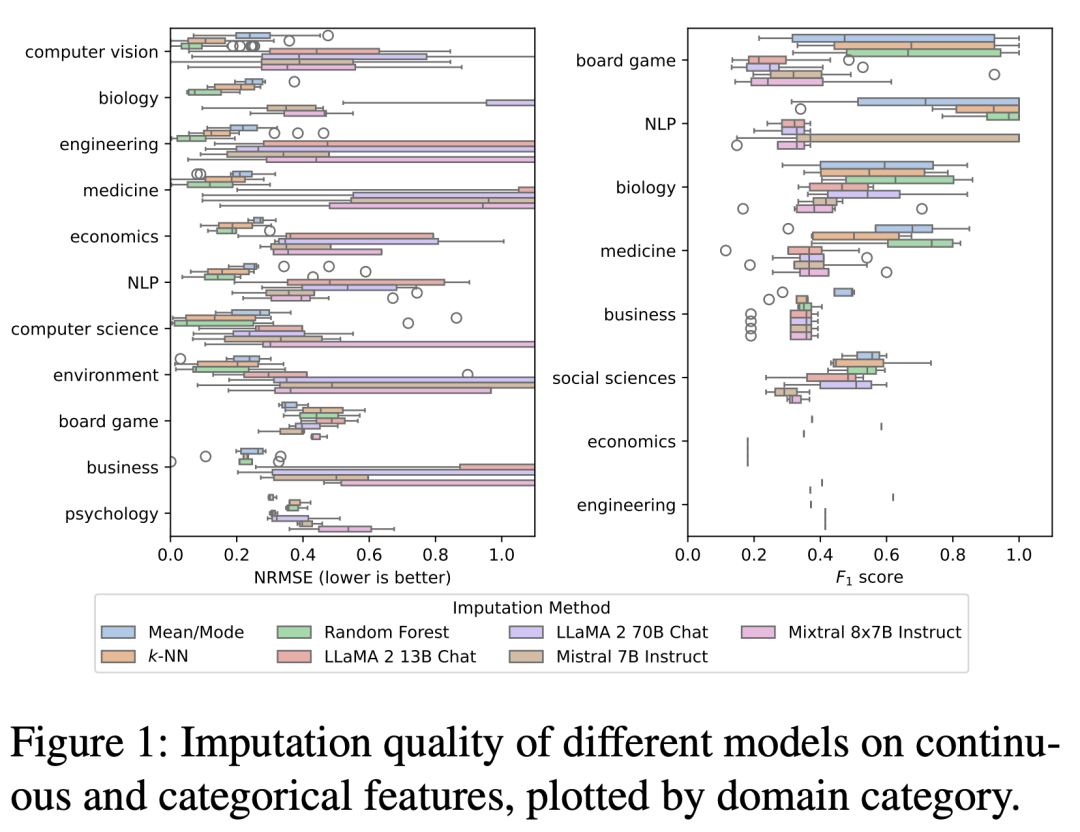
将这些模型与这类分析中常用的3种经验方法进行了比较:分别用于连续特征和分类特征的平均值和模式估算、k-近邻(k-NN)估算和随机森林估算。
归因质量的评估基于,连续特征和分类特征的归一化均方根误差(NRMSE)和F1分数。
通过这一方法,能够让研究人员可以调查LLM作为数据推算专家的能力,而且还可以将其表现与传统方法进行比较。
这种创新的方法在处理不完整的数据集方面开辟了新的视角,并突出了LLM在数据科学中的潜力。
与传统方法比较
与预期相反,分析结果表明,LLM的估算质量一般不会超过三种经验方法。
然而,基于LLM的插补对于某些数据集是有用的,特别是在工程和计算机视觉领域。
一些数据集,如这些领域的「PC1」、「PC3」和「Satimage」,表现出NRMSE约为0.1的归因质量,在生物学和NLP领域也观察到了类似的结果。
有趣的是,基于LLM归因的下游表现因领域而异。
虽然社会科学和心理学等领域表现较差,但医学、经济学、商业和生物学表现较好。值得注意的是,基于LLM的插补在商业领域表现最好。
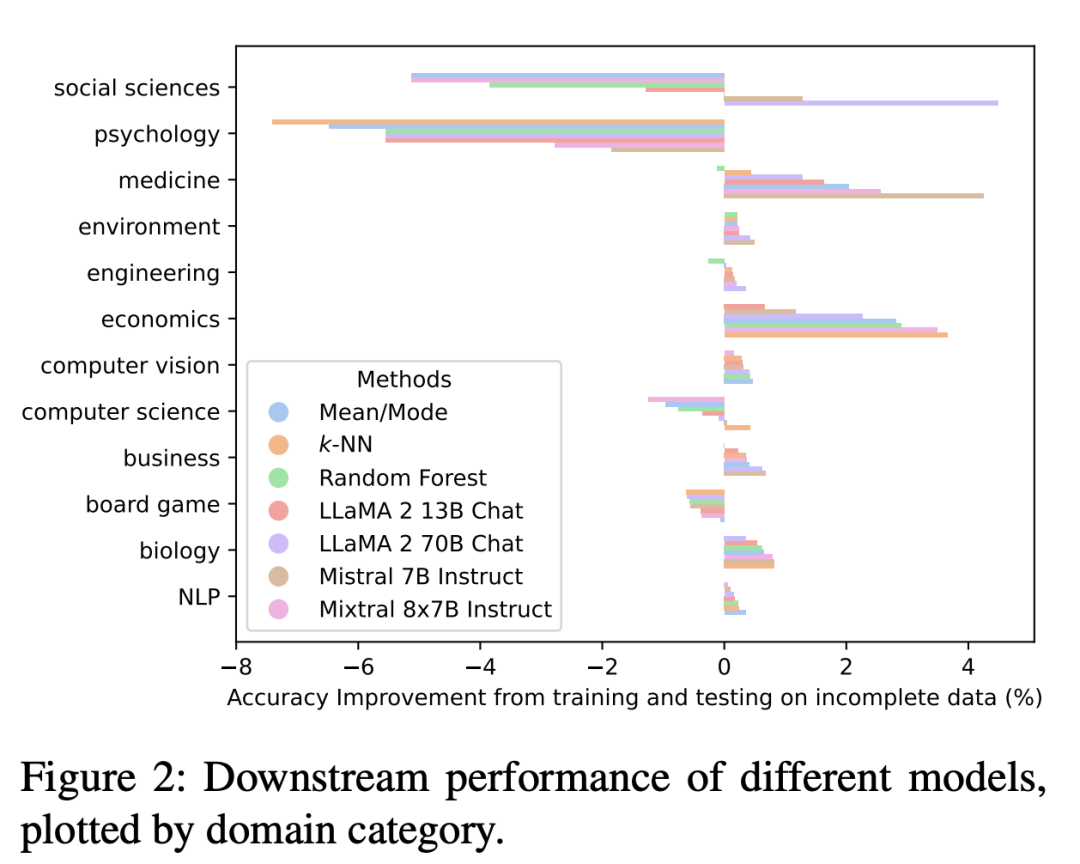
此外,研究还表明,至少在某些领域,LLM可以基于其丰富的训练数据提供准确和相关的估计,这些数据可以与真实世界的数据相匹配。
使用LLM进行数据插补是有前景的,但它需要仔细考虑领域和特定用例。
因此,这项研究结果有助于更好地理解LLM在数据科学中的潜力和局限性。
用LLM先验启发
此外,研究人员还利用LLM研究了先验启发,旨在评估LLM能否提供有关特征分布的信息,以及这对数据收集和后续数据分析有何影响。
特别是,进一步了解LLM所获得的先验分布的影响和有效性,并比较它们与传统方法和模型的性能如何。
作者将LLM的估计值与Stefan等人的实验结果进行了比较。
在该实验中,6位心理学研究人员被问及各自领域中典型的中小效应量和皮尔逊相关性。
使用类似的问题,要求LLM模拟一个专家、一组专家或一个非专家,然后查询优先级分布。
在进行这项工作时,可以参考或不参考对比实验中使用的访谈方案。
这里研究人员提出一种全新的提示策略,要求模型为贝叶斯数据分析提供专家知情的先验分布。

在此过程中,ChatGPT 3.5展示了其对学术启发框架的熟悉程度,比如谢菲尔德启发框架与直方图方法相结合。
研究人员使用该框架生成了全球25个大小城市12月份典型日气温和降水量的先验分布。
ChatGPT使用从训练数据中获得的知识进行模拟专家讨论,并构建参数概率分布。
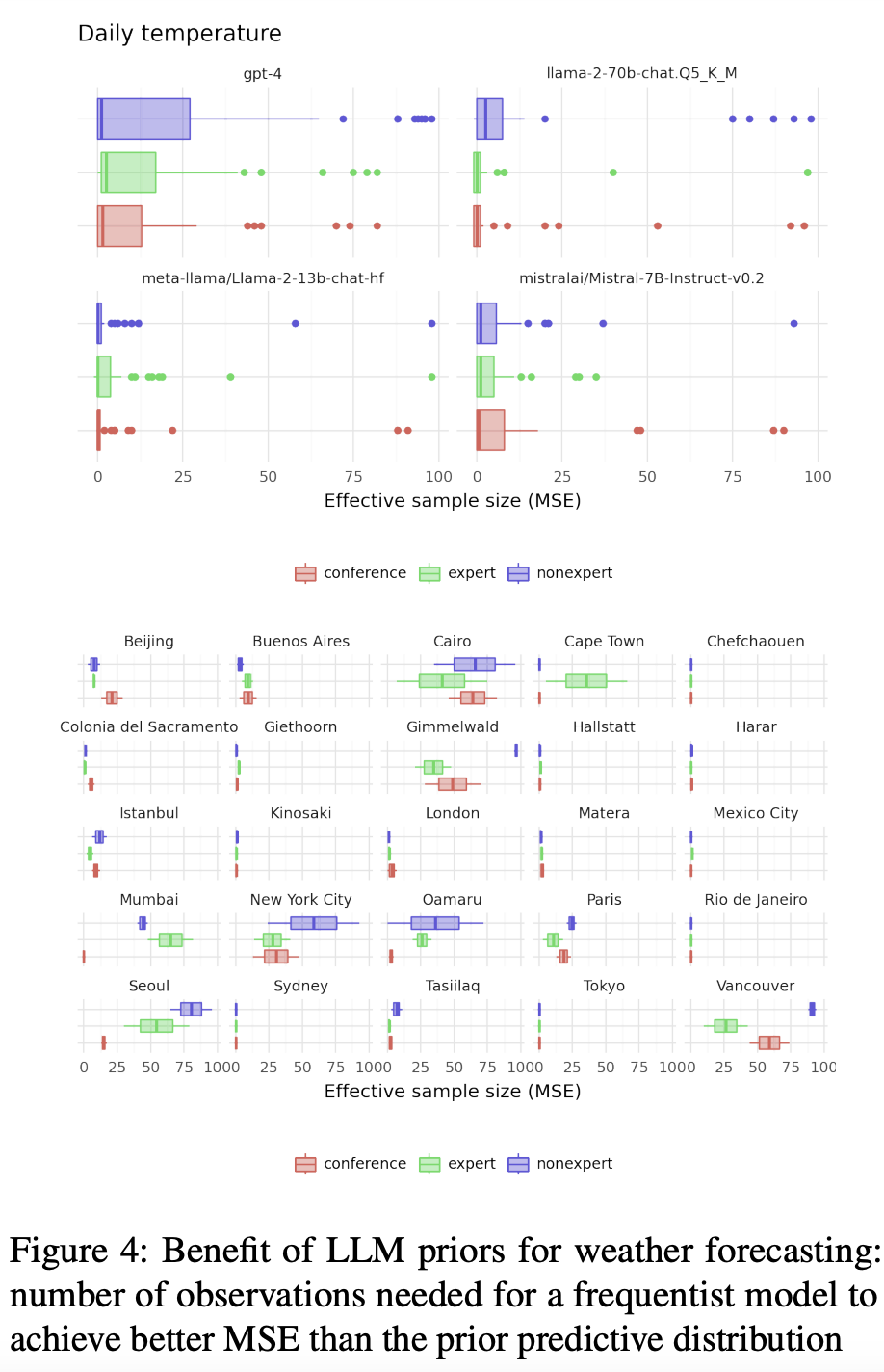
实验结果
令人惊讶的是,不同子领域的专家角色对LLM产生的先验没有显著影响。
在实验中,无论他们扮演什么角色,他们的判断都非常相似:
大多数人工专家都倾向于谨慎预测,认为影响较小。只有GPT-4专家比较大胆,认为影响中等偏大。
当涉及到两个事物之间的关系时,比如天气对我们购物行为的影响,数字助理们与真人的观点有所不同。
有些数字助理呈现出一条中间低、边缘高的「浴缸」曲线,而GPT-4则向我们展示了一条更平滑的钟形曲线。
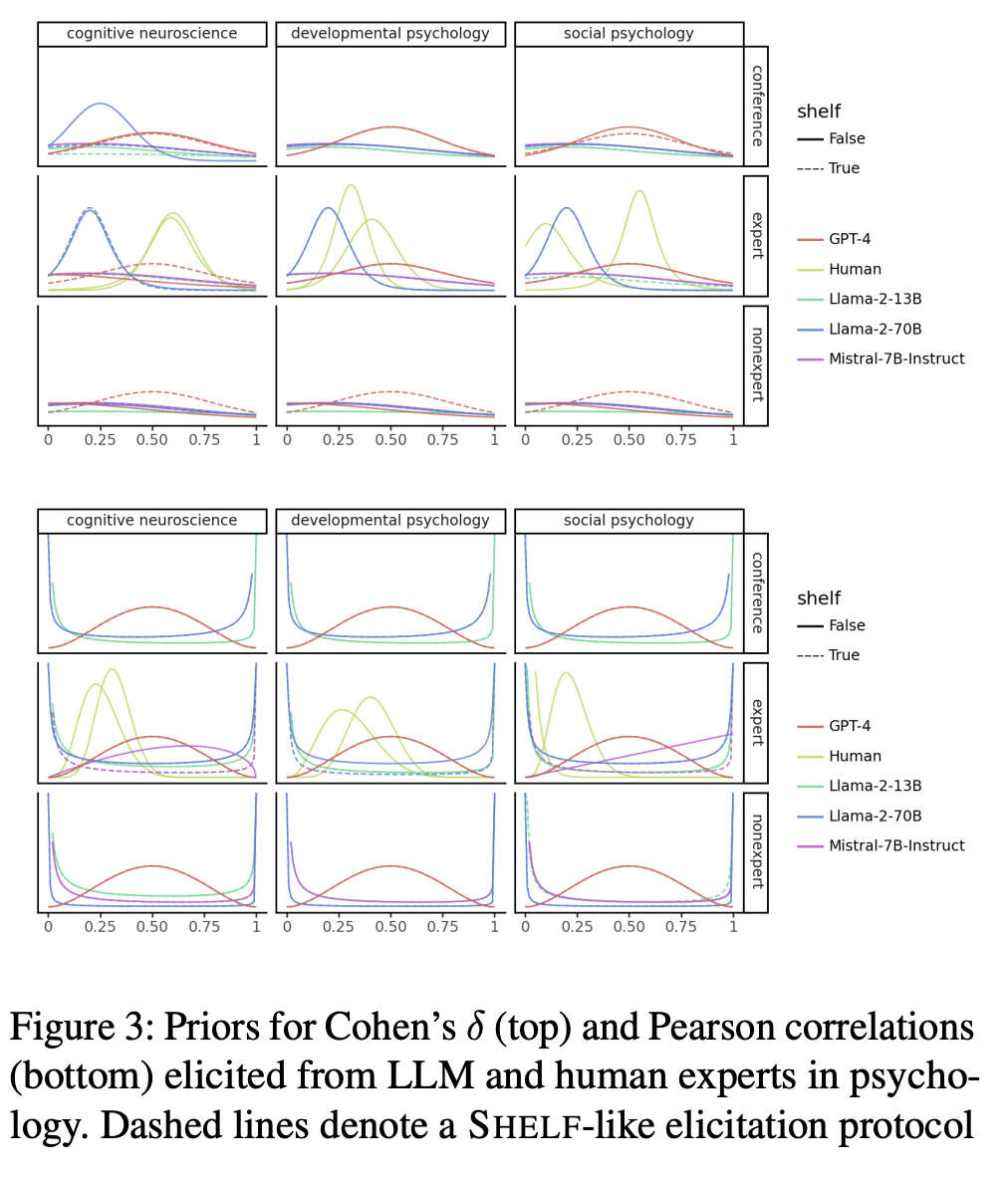
然后,作者还观察了这些数字专家对他们的预测的信心。一些人相当谨慎,提供了保守的估计,除了Mistral 7B Instruct——对其估计的质量非常有信心。
综上所述,这些结果还表明,LLM在某些方面能够产生与人类专家判断竞争的先验,但在其他方面却显著不同。
结论
这项研究表明,在医学、经济和生物等领域,LLM已经可以基于传统的数据插补的方法,提供有价值的见解。
LLM能够综合来自各种来源的知识,并将其应用于特定的应用环境,为数据分析开辟了新的视野。
特别是在专家难觅,或时间宝贵的情况下,LLM可以成为宝贵的资源。
https://the-decoder.com/filling-the-gaps-can-llms-take-on-the-role-of-human-experts-in-data-analysis/


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢